このユニットでは、準ランダム検索について説明します。
準ランダム検索を使用する理由
チューニングの問題に関する分析情報を最大限に引き出すことを目的とした反復的なチューニング プロセス(「探索フェーズ」)の一部として使用する場合は、(低分散シーケンスに基づく)準ランダム検索が、より高度なブラックボックス最適化ツールよりも優れています。ベイズ最適化などのツールは、エクスプロイト フェーズに適しています。ランダムにシフトされた低不一致シーケンスに基づく準ランダム検索は、「ジッタリングされたシャッフル グリッド検索」と見なすことができます。これは、特定の検索空間を均一にランダムに探索し、ランダム検索よりも検索ポイントを広げるためです。
より高度なブラックボックス最適化ツール(ベイズ最適化、進化アルゴリズムなど)と比較して、準ランダム検索には次のような利点があります。
- 検索空間を非適応的にサンプリングすると、テストを再実行せずに事後分析でチューニング目標を変更できます。たとえば、通常は、トレーニングの任意の時点で達成された検証エラーに関して最適なトライアルを見つけます。ただし、準ランダム検索は適応的ではないため、テストを再実行しなくても、最終的な検証エラー、トレーニング エラー、またはその他の代替の評価指標に基づいて最適なトライアルを見つけることができます。
- 準ランダム検索は、一貫した方法で統計的に再現可能な方法で動作します。検索アルゴリズムの実装が変更された場合でも、同じ均一性プロパティが維持されていれば、6 か月前の調査を再現できます。高度なベイジアン最適化ソフトウェアを使用している場合、バージョン間で実装が重要な点において変更される可能性があり、古い検索を再現するのがはるかに難しくなります。古い実装にロールバックできない場合があります(最適化ツールがサービスとして実行されている場合など)。
- 検索空間を均一に探索することで、結果と、検索空間に関する結果の推奨事項を簡単に推論できます。たとえば、準ランダム検索の走査で最適なポイントが検索空間の境界にある場合、これは検索空間の境界を変更する必要があることを示す良いシグナルです(ただし、絶対的なシグナルではありません)。ただし、適応型ブラックボックス最適化アルゴリズムでは、初期のトライアルで不運な結果が得られた場合、探索空間の中央に同等の優れたポイントが含まれていても、そのポイントが探索されなくなる可能性があります。これは、優れた最適化アルゴリズムが検索を高速化するために採用する必要があるまさにこの種の不均一性であるためです。
- 適応型アルゴリズムとは異なり、準ランダム検索(または他の適応型以外の検索アルゴリズム)を使用する場合、並列で実行するトライアルの数と順番に従って実行するトライアルの数を変更しても、統計的に有意な差は生じません。
- より高度な検索アルゴリズムでは、特にニューラル ネットワークのハイパーパラメータ チューニングを念頭に設計されていない場合、実現不可能なポイントを正しく処理できないことがあります。
- 準ランダム検索はシンプルで、多くのチューニング トライアルを並行して実行する場合に特に効果的です。経験則として1、特に多くのテストを並行して実行する必要がある場合、適応型アルゴリズムが予算の 2 倍の準ランダム検索に勝つのは非常に困難です(新しいテストを開始するときに、以前のテスト結果を利用できる機会がほとんどありません)。ベイズ最適化やその他の高度なブラックボックス最適化手法に関する専門知識がないと、原則として得られるメリットを享受できない可能性があります。現実的なディープラーニング チューニング条件で高度なブラックボックス最適化アルゴリズムをベンチマークすることは困難です。これらのアルゴリズムは現在、研究が非常に活発な分野であり、高度なアルゴリズムには、経験の浅いユーザーにとって独自の落とし穴があります。これらの方法の専門家は優れた結果を得ることができますが、並列処理が高度な状況では、検索スペースと予算が重要になります。
ただし、計算リソースで並列実行できるトライアルが少数で、多くのトライアルを順番に実行できる場合は、チューニング結果の解釈が難しくなるものの、ベイズ最適化がはるかに魅力的になります。
準ランダム検索の実装はどこで確認できますか?
オープンソースの Vizier には、準ランダム検索の実装があります。この Vizier の使用例で algorithm="QUASI_RANDOM_SEARCH" を設定します。別の実装は、このハイパーパラメータ スイープの例にあります。どちらの実装でも、特定の検索空間の Halton シーケンスが生成されます(重要なハイパーパラメータ: ランダムなし、クワイなしで推奨されているように、シフトされたスクランブルされた Halton シーケンスを実装することを目的としています)。
低分散シーケンスに基づく準ランダム検索アルゴリズムを使用できない場合は、代わりに疑似ランダム均一検索を使用できますが、効率は若干低下する可能性があります。1 ~ 2 次元では、グリッド検索も使用できますが、それ以上の次元では使用できません。(Bergstra & Bengio, 2012 を参照)。
準ランダム検索で良い結果を得るには、何回トライアルを行う必要がありますか?
準ランダム検索で結果を得るために必要な試行回数を一般に決定する方法はありませんが、特定の例を確認することはできます。図 3 に示すように、調査の試行回数は結果に大きな影響を与える可能性があります。
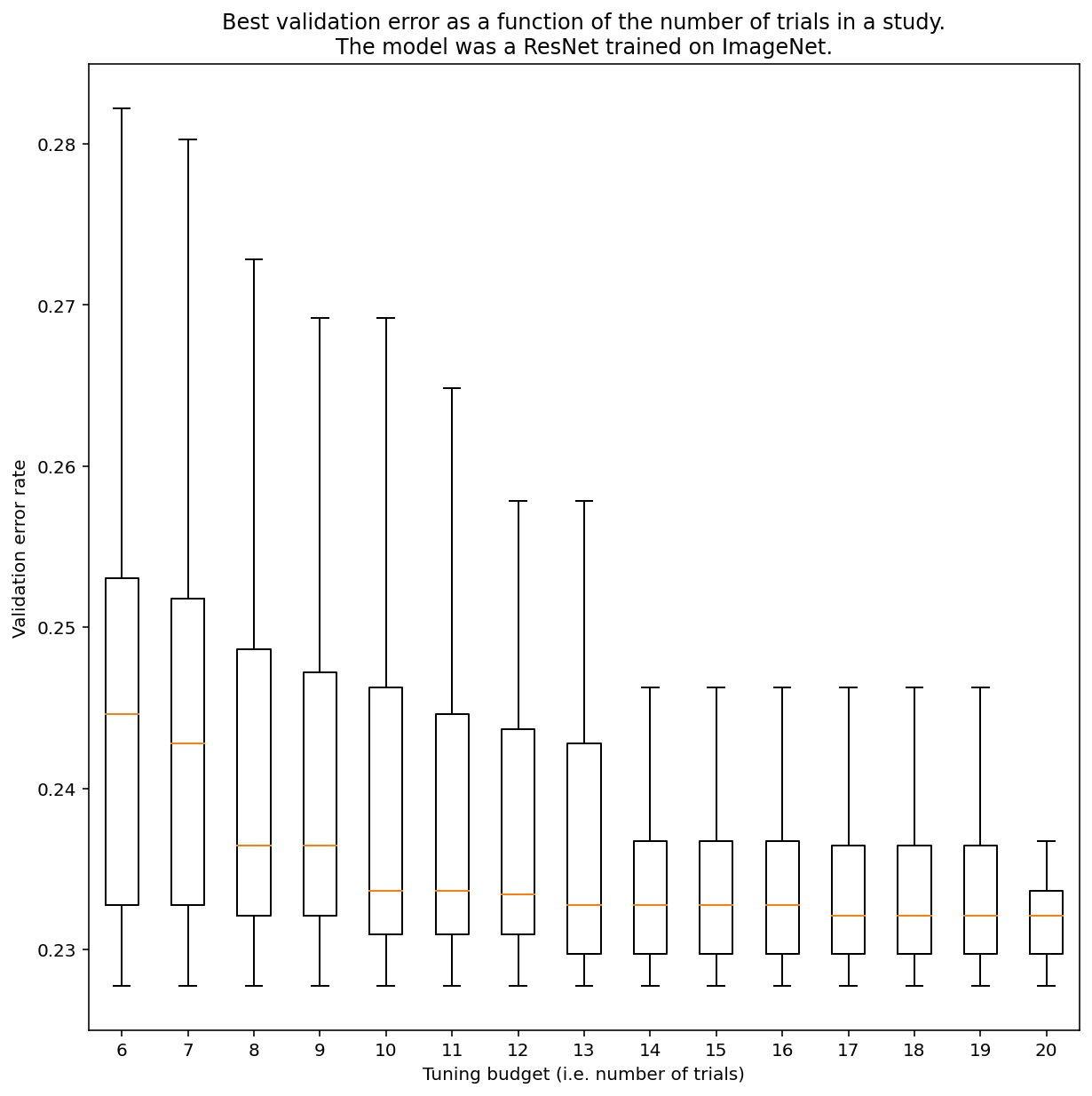
図 3: ImageNet で 100 回試行してチューニングされた ResNet-50。ブートストラップを使用して、さまざまな量のチューニング バジェットをシミュレートしました。各トライアル予算の最適なパフォーマンスの箱ひげ図がプロットされます。
図 3 について、次の点に注意してください。
- 6 件のトライアルをサンプリングした場合の四分位範囲は、20 件のトライアルをサンプリングした場合よりもはるかに大きくなります。
- 20 回の試行でも、特に幸運なケースと不運なケースの差は、固定のハイパーパラメータを使用して異なる乱数シードでこのモデルを再トレーニングした場合の一般的な変動よりも大きくなります。このワークロードでは、検証エラー率が約 23% の場合、この変動は約 +/- 0.1% になります。
-
Ben Recht と Kevin Jamieson は、2 倍の予算で行うランダム検索がベースラインとしてどれほど優れているかを指摘しています(Hyperband の論文でも同様の議論がされています)。しかし、最先端のベイズ最適化手法が、予算が 2 倍のランダム検索を圧倒するような探索空間や問題を見つけることは確かに可能です。ただし、ベイズ最適化では過去の試行の結果を確認できないため、経験上、高並列性の場合、2 倍の予算でランダム検索を凌駕することは難しくなります。 ↩