In diesem Modul liegt der Schwerpunkt auf der quasi-zufälligen Suche.
Warum sollte ich die quasi-zufällige Suche verwenden?
Die quasi-zufällige Suche (basierend auf Sequenzen mit geringer Abweichung) ist unserer Meinung nach besser als ausgefeiltere Blackbox-Optimierungstools, wenn sie im Rahmen eines iterativen Optimierungsprozesses verwendet wird, der die Erkenntnisse über das Optimierungsproblem maximieren soll (diese Phase nennen wir „Explorationsphase“). Bayessche Optimierung und ähnliche Tools eignen sich besser für die Ausschöpfungsphase. Die quasi-zufällige Suche, die auf zufällig verschobenen Sequenzen mit geringer Abweichung basiert, kann als „gemischte, gemischte Rastersuche“ betrachtet werden, da sie einen bestimmten Suchraum gleichmäßig, aber zufällig durchsucht und die Suchpunkte stärker als bei der Zufallssuche verteilt.
Die Vorteile der quasi-zufälligen Suche gegenüber ausgefeilteren Black-Box-Optimierungstools (z.B. Bayes'sche Optimierung, Evolutionsalgorithmen) sind:
- Wenn Sie den Suchraum nicht adaptiv stichprobenartig auswählen, können Sie das Optimierungsziel in der Post-hoc-Analyse ändern, ohne die Tests noch einmal auszuführen. Beispielsweise möchten wir in der Regel den Test mit dem niedrigsten Validierungsfehler ermitteln, der zu einem beliebigen Zeitpunkt während des Trainings erreicht wird. Aufgrund der nicht adaptiven Natur der quasi-zufälligen Suche können Sie jedoch den besten Test anhand des endgültigen Validierungsfehlers, des Trainingsfehlers oder eines alternativen Bewertungsmesswerts ermitteln, ohne Tests noch einmal auszuführen.
- Die quasi-zufällige Suche verhält sich konsistent und statistisch reproduzierbar. Eine Studie von vor sechs Monaten sollte auch dann reproduzierbar sein, wenn sich die Implementierung des Suchalgorithmus ändert, solange dieselben Einheitlichkeitseigenschaften beibehalten werden. Bei der Verwendung ausgefeilter bayesianischer Optimierungssoftware kann sich die Implementierung zwischen den Versionen erheblich ändern, was die Reproduktion einer alten Suche erheblich erschwert. Es ist nicht immer möglich, zu einer alten Implementierung zurückzukehren, z.B. wenn das Optimierungstool als Dienst ausgeführt wird.
- Durch die einheitliche Erkundung des Suchraums lässt sich leichter nachvollziehen, was die Ergebnisse über den Suchraum aussagen könnten. Wenn sich der beste Punkt bei der Durchsuchung der quasi-zufälligen Suche beispielsweise an der Grenze des Suchraums befindet, ist dies ein gutes (aber kein hundertprozentig zuverlässiges) Signal dafür, dass die Grenzen des Suchraums geändert werden sollten. Ein adaptiver Black-Box-Optimierungsalgorithmus kann jedoch die Mitte des Suchraums aufgrund einiger unglücklicher früher Tests vernachlässigt haben, auch wenn sie zufällig ebenso gute Punkte enthält. Genau diese Art von Nichtuniformität muss ein guter Optimierungsalgorithmus nutzen, um die Suche zu beschleunigen.
- Wenn Sie bei der Verwendung einer quasi-zufälligen Suche (oder anderer nicht adaptiver Suchalgorithmen) eine unterschiedliche Anzahl von Tests parallel oder nacheinander ausführen, führen diese Tests nicht zu statistisch unterschiedlichen Ergebnissen, im Gegensatz zu adaptiven Algorithmen.
- Komplexere Suchalgorithmen können nicht immer richtig mit nicht realisierbaren Punkten umgehen, insbesondere wenn sie nicht für die Hyperparameter-Abstimmung von neuronalen Netzwerken entwickelt wurden.
- Die quasi-zufällige Suche ist einfach und funktioniert besonders gut, wenn viele Optimierungstests parallel ausgeführt werden. Erfahrungsgemäß1 ist es für einen adaptiven Algorithmus sehr schwierig, eine quasi-zufällige Suche zu schlagen, die das doppelte Budget hat, insbesondere wenn viele Tests parallel ausgeführt werden müssen. Es gibt also nur wenige Möglichkeiten, bei der Einführung neuer Tests die Ergebnisse früherer Tests zu nutzen. Ohne Fachwissen in bayesscher Optimierung und anderen fortschrittlichen Black-Box-Optimierungsmethoden können Sie die Vorteile, die diese im Prinzip bieten, möglicherweise nicht nutzen. Es ist schwierig, erweiterte Black-Box-Optimierungsalgorithmen unter realistischen Bedingungen für die Deep-Learning-Optimierung zu vergleichen. Sie sind ein sehr aktives Forschungsgebiet und die ausgefeilteren Algorithmen bergen für unerfahrene Nutzer eigene Fallstricke. Experten für diese Methoden können gute Ergebnisse erzielen, aber bei hoher Parallelität spielen der Suchraum und das Budget in der Regel eine viel größere Rolle.
Wenn Ihre Rechenressourcen jedoch nur eine kleine Anzahl von Tests parallel zulassen und Sie sich viele Tests nacheinander leisten können, wird die bayesianische Optimierung viel attraktiver, auch wenn die Ergebnisse der Optimierung schwieriger zu interpretieren sind.
Wo finde ich eine Implementierung der quasi-zufälligen Suche?
Open-Source-Vizier bietet eine Implementierung der quasi-zufälligen Suche.
algorithm="QUASI_RANDOM_SEARCH" in diesem Beispiel für die Verwendung von Vizier festlegen
Eine alternative Implementierung finden Sie in diesem Beispiel für Hyperparameter-Sweeps.
Bei beiden Implementierungen wird eine Halton-Folge für einen bestimmten Suchraum generiert. Dabei soll eine verschobene, verschlüsselte Halton-Folge implementiert werden, wie in Critical Hyper-Parameters: No Random, No Cry empfohlen.
Wenn kein quasi-zufälliger Suchalgorithmus auf der Grundlage einer Sequenz mit geringer Abweichung verfügbar ist, kann stattdessen eine pseudozufällige einheitliche Suche verwendet werden. Diese ist jedoch wahrscheinlich etwas weniger effizient. In 1 bis 2 Dimensionen ist auch eine Rastersuche akzeptabel, jedoch nicht in höheren Dimensionen. (Siehe Bergstra und Bengio, 2012).
Wie viele Versuche sind erforderlich, um mit der quasi-zufälligen Suche gute Ergebnisse zu erzielen?
Es gibt keine Möglichkeit zu bestimmen, wie viele Tests erforderlich sind, um mit der quasi-zufälligen Suche allgemein Ergebnisse zu erzielen. Sie können sich jedoch bestimmte Beispiele ansehen. Wie Abbildung 3 zeigt, kann die Anzahl der Tests in einer Studie einen erheblichen Einfluss auf die Ergebnisse haben:
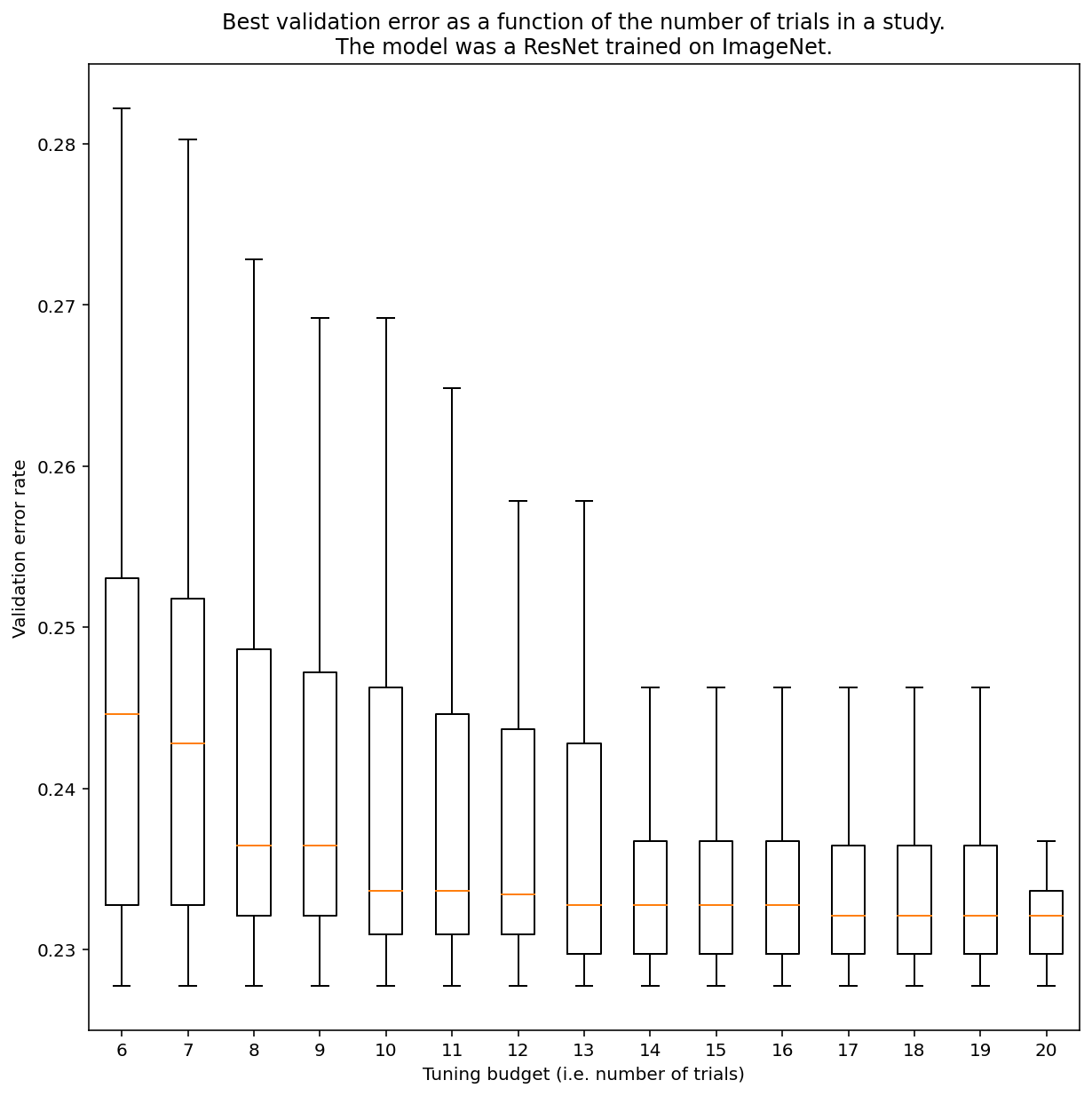
Abbildung 3:ResNet-50, optimiert auf ImageNet mit 100 Tests. Mithilfe von Bootstrapping wurden verschiedene Tuning-Budgets simuliert. Für jedes Testbudget werden Boxplots der besten Leistung dargestellt.
Beachten Sie Folgendes in Abbildung 3:
- Die Quartilabstände bei 6 Tests sind viel größer als bei 20 Tests.
- Selbst bei 20 Tests ist der Unterschied zwischen besonders glücklichen und unglücklichen Studien wahrscheinlich größer als die typische Abweichung zwischen Neuschulungen dieses Modells mit verschiedenen Zufallszahlen und festen Hyperparametern, die für diese Arbeitslast bei einer Validierungsfehlerrate von etwa 23% etwa +/- 0,1 % betragen kann.
-
Ben Recht und Kevin Jamieson haben darauf hingewiesen, wie leistungsstark die zufällige Suche mit dem doppelten Budget als Baseline ist (im Hyperband-Artikel werden ähnliche Argumente vorgebracht). Es ist jedoch durchaus möglich, Suchräume und Probleme zu finden, bei denen moderne Bayes-Optimierungstechniken die zufällige Suche mit dem doppelten Budget übertreffen. Unserer Erfahrung nach ist es jedoch bei hoher Parallelität viel schwieriger, eine zufällige Suche mit dem Zweifachen des Budgets zu übertreffen, da die bayesianische Optimierung keine Möglichkeit hat, die Ergebnisse früherer Tests zu beobachten. ↩