این واحد بر جستجوی شبه تصادفی تمرکز دارد.
چرا از جستجوی شبه تصادفی استفاده کنیم؟
جستجوی شبه تصادفی (بر اساس دنبالههای با اختلاف کم) ترجیح ما نسبت به ابزارهای بهینهسازی جعبه سیاه جذابتر زمانی است که به عنوان بخشی از فرآیند تنظیم تکراری استفاده میشود که هدف آن به حداکثر رساندن بینش نسبت به مشکل تنظیم است (آنچه ما به عنوان "مرحله کاوش" از آن یاد میکنیم). بهینه سازی بیزی و ابزارهای مشابه برای مرحله بهره برداری مناسب تر هستند. جستجوی شبه تصادفی مبتنی بر توالیهای کماختلاف کم جابهجا شده بهطور تصادفی را میتوان به عنوان «جستجوی شبکهای آشفته و به هم ریخته» در نظر گرفت، زیرا بهطور یکنواخت، اما تصادفی، یک فضای جستجوی معین را کاوش میکند و نقاط جستجو را بیشتر از جستجوی تصادفی پخش میکند.
مزایای جستجوی شبه تصادفی نسبت به ابزارهای پیچیده تر بهینه سازی جعبه سیاه (مانند بهینه سازی بیزی، الگوریتم های تکاملی) عبارتند از:
- نمونه برداری از فضای جستجو به صورت غیر تطبیقی امکان تغییر هدف تنظیم را در تجزیه و تحلیل post hoc بدون اجرای مجدد آزمایش ها ممکن می سازد. به عنوان مثال، ما معمولاً میخواهیم بهترین آزمایش را از نظر خطای اعتبارسنجی بدست آمده در هر نقطه از آموزش پیدا کنیم. با این حال، ماهیت غیر تطبیقی جستجوی شبه تصادفی، یافتن بهترین آزمایش را بر اساس خطای اعتبار سنجی نهایی، خطای آموزشی، یا برخی معیارهای ارزیابی جایگزین بدون اجرای مجدد هیچ آزمایشی ممکن می سازد.
- جستجوی شبه تصادفی به روشی ثابت و قابل تکرار آماری عمل می کند. حتی اگر پیادهسازی الگوریتم جستجو تغییر کند، تا زمانی که ویژگیهای یکنواختی یکسانی داشته باشد، باید بتوان یک مطالعه از شش ماه پیش را بازتولید کرد. اگر از نرمافزار بهینهسازی بیزی پیچیده استفاده کنید، ممکن است پیادهسازی بین نسخهها به طرز مهمی تغییر کند و بازتولید جستجوی قدیمی را بسیار سختتر کند. بازگشت به یک پیاده سازی قدیمی همیشه امکان پذیر نیست (مثلاً اگر ابزار بهینه سازی به عنوان یک سرویس اجرا شود).
- کاوش یکنواخت آن در فضای جستجو، استدلال در مورد نتایج و آنچه ممکن است در مورد فضای جستجو پیشنهاد کند را آسان تر می کند. به عنوان مثال، اگر بهترین نقطه در پیمایش جستجوی شبه تصادفی در مرز فضای جستجو باشد، این یک سیگنال خوب (اما نه بدون خطا) است که کران های فضای جستجو باید تغییر کند. با این حال، یک الگوریتم بهینهسازی جعبه سیاه تطبیقی ممکن است به دلیل برخی آزمایشهای اولیه بدشانسی، وسط فضای جستجو را نادیده گرفته باشد، حتی اگر اتفاقاً حاوی نکات به همان اندازه خوب باشد، زیرا دقیقاً این نوع عدم یکنواختی است که یک الگوریتم بهینهسازی خوب باید به کار گیرد. برای سرعت بخشیدن به جستجو
- بر خلاف الگوریتمهای تطبیقی، اجرای تعداد متفاوت آزمایشها به صورت موازی در مقابل متوالی نتایج آماری متفاوتی را هنگام استفاده از جستجوی شبه تصادفی (یا سایر الگوریتمهای جستجوی غیرتطبیقی) ایجاد نمیکند.
- الگوریتمهای جستجوی پیچیدهتر ممکن است همیشه نقاط غیرقابل اجرا را به درستی مدیریت نکنند، به خصوص اگر با تنظیم فراپارامتر شبکه عصبی طراحی نشده باشند.
- جستجوی شبه تصادفی ساده است و بهویژه زمانی که بسیاری از آزمایشهای تنظیم به صورت موازی اجرا میشوند، به خوبی کار میکند. به طور حکایتی 1 ، برای یک الگوریتم تطبیقی بسیار سخت است که یک جستجوی شبه تصادفی که 2 برابر بودجه خود را دارد، شکست دهد، به خصوص زمانی که بسیاری از آزمایشها باید به صورت موازی اجرا شوند (و در نتیجه شانس بسیار کمی برای استفاده از نتایج آزمایشی قبلی وجود دارد. راه اندازی آزمایش های جدید). بدون تخصص در بهینهسازی بیزی و سایر روشهای پیشرفته بهینهسازی جعبه سیاه، ممکن است به مزایایی که اصولاً قادر به ارائه آن هستند نتوانید دست یابید. محک زدن الگوریتم های بهینه سازی جعبه سیاه پیشرفته در شرایط تنظیم واقعی یادگیری عمیق دشوار است. آنها منطقه بسیار فعالی از تحقیقات فعلی هستند و الگوریتم های پیچیده تر با مشکلات خاص خود برای کاربران بی تجربه همراه هستند. متخصصان در این روشها میتوانند نتایج خوبی به دست آورند، اما در شرایط موازی بالا، فضای جستجو و بودجه اهمیت بیشتری دارد.
گفته میشود، اگر منابع محاسباتی شما فقط به تعداد کمی از آزمایشها اجازه میدهند که به صورت موازی اجرا شوند و بتوانید بسیاری از آزمایشها را به ترتیب انجام دهید، بهینهسازی بیزی با وجود سختتر کردن تفسیر نتایج تنظیم شما جذابتر میشود.
از کجا می توانم پیاده سازی جستجوی شبه تصادفی را پیدا کنم؟
Open-Source Vizier پیاده سازی جستجوی شبه تصادفی دارد. algorithm="QUASI_RANDOM_SEARCH" در این مثال استفاده از وزیر تنظیم کنید. یک پیادهسازی جایگزین در این مثال فراپارامتر وجود دارد. هر دوی این پیادهسازیها یک دنباله هالتون را برای یک فضای جستجوی معین ایجاد میکنند (در نظر گرفته شده برای پیادهسازی یک دنباله هالتون تغییر یافته و درهم، همانطور که در Critical Hyper-Parameters توصیه میشود: بدون تصادفی، بدون فریاد ).
اگر یک الگوریتم جستجوی شبه تصادفی مبتنی بر دنبالهای با اختلاف کم در دسترس نباشد، میتوان به جای آن جستجوی یکنواخت شبه تصادفی را جایگزین کرد، اگرچه احتمالاً کارایی آن کمی کمتر است. در ابعاد 1-2 نیز جستجوی شبکه ای قابل قبول است، البته نه در ابعاد بالاتر. (نگاه کنید به Bergstra & Bengio، 2012 ).
برای به دست آوردن نتایج خوب با جستجوی شبه تصادفی چند آزمایش لازم است؟
هیچ راهی برای تعیین تعداد آزمایش برای به دست آوردن نتایج با جستجوی شبه تصادفی به طور کلی وجود ندارد، اما می توانید به نمونه های خاص نگاه کنید. همانطور که شکل 3 نشان می دهد، تعداد کارآزمایی ها در یک مطالعه می تواند تأثیر قابل توجهی بر نتایج داشته باشد:
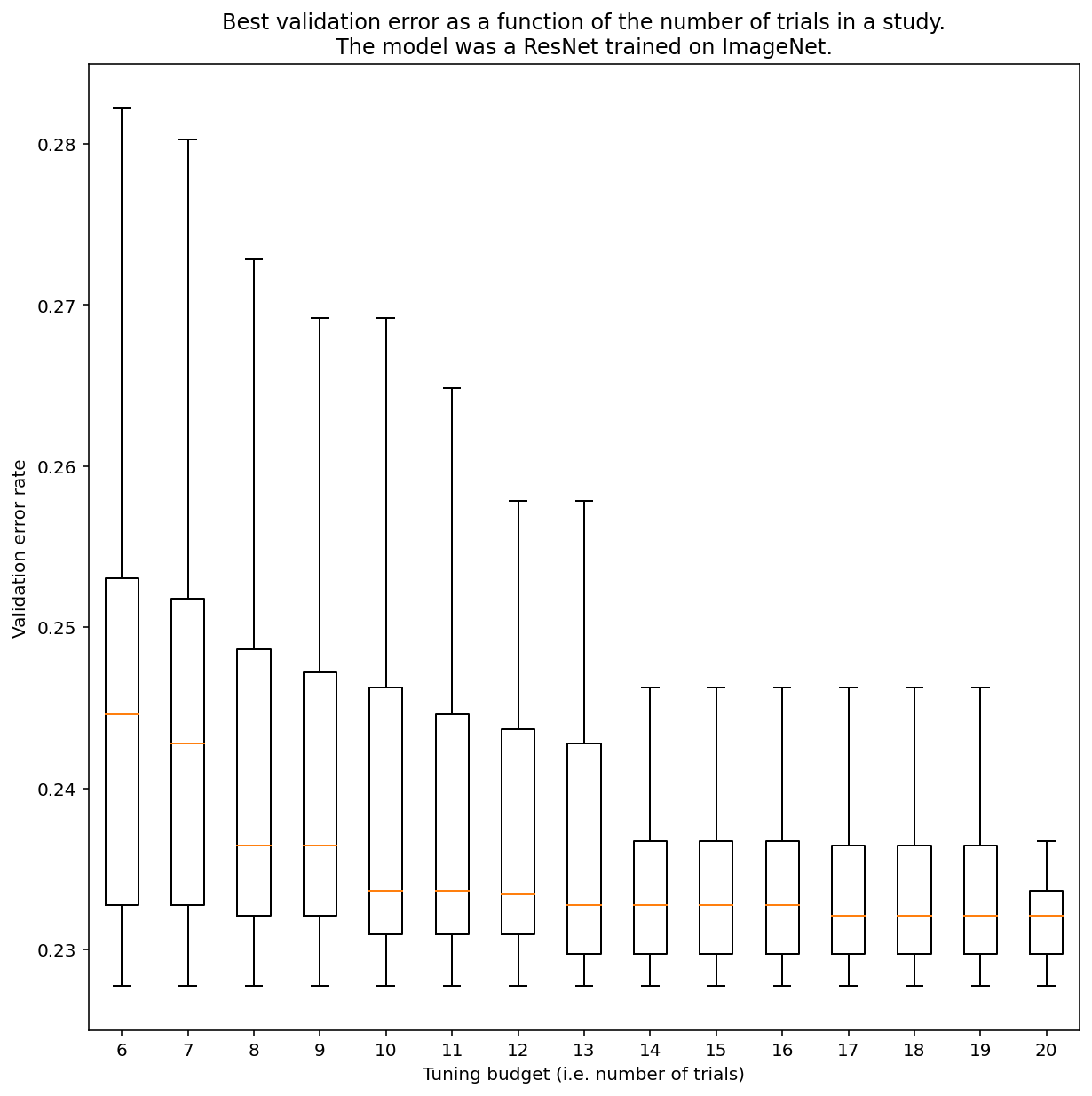
شکل 3: ResNet-50 تنظیم شده در ImageNet با 100 آزمایش. با استفاده از بوت استرپینگ، مقادیر مختلفی از بودجه تنظیم شبیه سازی شد. نمودارهای جعبه ای از بهترین اجراها برای هر بودجه آزمایشی ترسیم شده است.
در مورد شکل 3 به موارد زیر توجه کنید:
- محدوده بین چارکی زمانی که 6 کارآزمایی نمونه برداری شد بسیار بزرگتر از زمانی است که 20 کارآزمایی نمونه برداری شد.
- حتی با 20 آزمایش، تفاوت بین مطالعات مخصوصاً خوش شانس و بدشانس احتمالاً بزرگتر از تغییرات معمولی بین بازآموزی های این مدل در دانه های تصادفی مختلف، با فراپارامترهای ثابت است که برای این حجم کاری ممکن است حدود +/- 0.1٪ در یک خطای اعتبارسنجی باشد. نرخ ~ 23٪.
بن رشت و کوین جیمیسون اشاره کردند که جستجوی تصادفی با بودجه 2X به عنوان یک خط پایه چقدر قوی است ( مقاله Hyperband استدلال های مشابهی ارائه می کند)، اما مطمئناً می توان فضاهای جستجو و مشکلاتی را پیدا کرد که تکنیک های بهینه سازی پیشرفته بیزی در آنها شکست می خورد. جستجوی تصادفی که دو برابر بودجه دارد. با این حال، در تجربه ما شکست دادن جستجوی تصادفی با بودجه 2X در رژیم موازی بالا بسیار سخت تر می شود زیرا بهینه سازی بیزی فرصتی برای مشاهده نتایج آزمایش های قبلی ندارد. ↩