หน่วยนี้มุ่งเน้นที่การค้นหาแบบเกือบสุ่ม
เหตุผลที่ควรใช้การค้นหาแบบเกือบสุ่ม
เราเลือกใช้การค้นหาแบบเกือบสุ่ม (ตามลําดับความคลาดเคลื่อนต่ำ) มากกว่าเครื่องมือเพิ่มประสิทธิภาพแบบกล่องดำที่ดูล้ำสมัยกว่า เมื่อใช้เป็นส่วนหนึ่งของกระบวนการปรับแต่งแบบวนซ้ำโดยมีจุดประสงค์เพื่อเพิ่มข้อมูลเชิงลึกเกี่ยวกับปัญหาการปรับแต่งให้ได้สูงสุด (สิ่งที่เราเรียกว่า "ระยะการสํารวจ") การเพิ่มประสิทธิภาพแบบเบย์เซียนและเครื่องมือที่คล้ายกันเหมาะสําหรับระยะการใช้ประโยชน์มากกว่า การค้นหาแบบเกือบสุ่มซึ่งอิงตามลำดับความคลาดเคลื่อนต่ำแบบสุ่มสามารถอธิบายได้ว่าเป็น "การค้นหาตารางกริดแบบสุ่มและกระจัดกระจาย" เนื่องจากจะสุ่มสำรวจพื้นที่การค้นหาหนึ่งๆ และกระจายจุดค้นหามากกว่าการค้นหาแบบสุ่ม
ข้อดีของการค้นหาแบบเกือบสุ่มเหนือเครื่องมือเพิ่มประสิทธิภาพแบบกล่องดำที่ซับซ้อนกว่า (เช่น การเพิ่มประสิทธิภาพแบบเบย์เซียน อัลกอริทึมวิวัฒนาการ) ประกอบด้วย
- การสุ่มตัวอย่างพื้นที่การค้นหาแบบไม่ปรับเปลี่ยนช่วยให้คุณเปลี่ยนวัตถุประสงค์ในการปรับแต่งในการวิเคราะห์ผลการตรวจสอบย้อนหลังได้โดยไม่ต้องทำการทดสอบอีกครั้ง ตัวอย่างเช่น โดยทั่วไปเราต้องการค้นหาการทดสอบที่ดีที่สุดในแง่ของข้อผิดพลาดในการตรวจสอบที่ทำได้ ณ จุดใดก็ได้ในการฝึก อย่างไรก็ตาม ลักษณะการค้นหาแบบไม่ปรับเปลี่ยนตามข้อมูลที่มีอยู่ของการค้นหาแบบเกือบสุ่มช่วยให้ค้นหาการทดสอบที่ดีที่สุดได้ โดยอิงตามข้อผิดพลาดในการตรวจสอบขั้นสุดท้าย ข้อผิดพลาดในการฝึก หรือเมตริกการประเมินทางเลือกบางอย่างโดยไม่ต้องทำการทดสอบซ้ำ
- การค้นหาแบบเกือบสุ่มจะทํางานอย่างสม่ำเสมอและทําซ้ำได้ทางสถิติ คุณควรทําซ้ำการศึกษาจาก 6 เดือนที่ผ่านมาได้แม้ว่าจะมีการเปลี่ยนแปลงการใช้งานอัลกอริทึมการค้นหา ตราบใดที่ยังคงรักษาพร็อพเพอร์ตี้แบบเดียวกันไว้ หากใช้ซอฟต์แวร์การเพิ่มประสิทธิภาพแบบเบย์เซียนที่ซับซ้อน การใช้งานอาจเปลี่ยนแปลงในลักษณะที่สําคัญระหว่างเวอร์ชันต่างๆ ซึ่งทําให้สร้างการค้นหาแบบเก่าได้ยากขึ้นมาก บางครั้งคุณอาจไม่สามารถเปลี่ยนกลับไปใช้การติดตั้งใช้งานเวอร์ชันเก่าได้ (เช่น หากเครื่องมือเพิ่มประสิทธิภาพทํางานเป็นบริการ)
- การสำรวจพื้นที่การค้นหาอย่างสม่ำเสมอช่วยให้เราอนุมานเกี่ยวกับผลการค้นหาและสิ่งที่ผลการค้นหาอาจแนะนำเกี่ยวกับพื้นที่การค้นหาได้ง่ายขึ้น เช่น หากจุดที่ดีที่สุดในการเข้าชมการค้นหาแบบเกือบสุ่มอยู่ตรงขอบเขตของพื้นที่การค้นหา นี่เป็นสัญญาณที่ดี (แต่ไม่ใช่สัญญาณที่เชื่อถือได้เสมอไป) ที่ควรเปลี่ยนขอบเขตของพื้นที่การค้นหา อย่างไรก็ตาม อัลกอริทึมการเพิ่มประสิทธิภาพแบบกล่องดำแบบปรับเปลี่ยนได้อาจไม่ได้คำนึงถึงช่วงกลางของพื้นที่การค้นหาเนื่องจากช่วงทดลองช่วงแรกๆ ที่ไม่ประสบความสำเร็จ แม้ว่าพื้นที่ดังกล่าวจะมีจุดที่มีประสิทธิภาพเท่ากันก็ตาม เนื่องจากความไม่สม่ำเสมอแบบนี้เองที่อัลกอริทึมการเพิ่มประสิทธิภาพที่ดีต้องใช้เพื่อเร่งความเร็วการค้นหา
- การใช้การทดสอบจํานวนต่างกันแบบขนานกับแบบตามลําดับไม่ได้ให้ผลลัพธ์ทางสถิติที่แตกต่างกันเมื่อใช้การค้นหาแบบเกือบสุ่ม (หรืออัลกอริทึมการค้นหาอื่นๆ ที่ไม่ปรับเปลี่ยน) ซึ่งต่างจากอัลกอริทึมแบบปรับเปลี่ยน
- อัลกอริทึมการค้นหาที่ซับซ้อนมากขึ้นอาจจัดการจุดที่ไม่สามารถทำได้อย่างไม่ถูกต้องเสมอไป โดยเฉพาะหากไม่ได้ออกแบบมาโดยคำนึงถึงการปรับแต่งไฮเปอร์พารามิเตอร์ของเครือข่ายประสาท
- การค้นหาแบบเกือบสุ่มนั้นใช้งานง่ายและมีประสิทธิภาพดีเมื่อการทดสอบการปรับแต่งหลายรายการทํางานพร้อมกัน จากประสบการณ์1 อัลกอริทึมแบบปรับเปลี่ยนได้นั้นทํางานได้ยากมากเมื่อเทียบกับการค้นหาแบบเกือบสุ่มที่มีงบประมาณ 2 เท่า โดยเฉพาะเมื่อต้องทำการทดสอบหลายรายการพร้อมกัน (และโอกาสที่จะใช้ผลการทดสอบก่อนหน้าเมื่อเริ่มการทดสอบใหม่มีน้อยมาก) หากไม่มีความเชี่ยวชาญด้านการเพิ่มประสิทธิภาพแบบเบย์เซียนและวิธีการเพิ่มประสิทธิภาพแบบกล่องดำขั้นสูงอื่นๆ คุณอาจไม่ได้รับประโยชน์ที่ควรจะได้รับ การเปรียบเทียบอัลกอริทึมการเพิ่มประสิทธิภาพแบบขั้นสูงซึ่งทำงานแบบไม่เปิดเผยข้อมูลในสภาพการปรับแต่งการเรียนรู้เชิงลึกที่สมจริงนั้นเป็นเรื่องยาก อัลกอริทึมเหล่านี้เป็นหัวข้อการวิจัยที่ได้รับความนิยมในปัจจุบัน และอัลกอริทึมที่ซับซ้อนมากขึ้นก็อาจก่อให้เกิดปัญหาสำหรับผู้ใช้ที่ไม่มีประสบการณ์ ผู้เชี่ยวชาญด้านวิธีการเหล่านี้สามารถได้ผลลัพธ์ที่ดี แต่ในกรณีที่มีการขนานกันสูง พื้นที่การค้นหาและงบประมาณมักจะมีความสำคัญมากกว่า
อย่างไรก็ตาม หากทรัพยากรการประมวลผลของคุณอนุญาตให้ทำการทดสอบแบบขนานได้เพียงไม่กี่รายการ และคุณมีเวลาทำการทดสอบหลายรายการตามลำดับได้ การเพิ่มประสิทธิภาพแบบเบย์เซียนจะน่าสนใจกว่ามาก แม้ว่าจะทำให้การตีความผลลัพธ์การปรับแต่งยากขึ้นก็ตาม
ฉันจะดูการใช้งานการค้นหาแบบเกือบสุ่มได้จากที่ใด
Vizier แบบโอเพนซอร์สมีการใช้งานการค้นหาแบบเกือบสุ่ม
ตั้งค่า algorithm="QUASI_RANDOM_SEARCH" ในตัวอย่างการใช้งาน Vizier นี้
การใช้งานทางเลือกมีอยู่ในตัวอย่างการสํารวจไฮเปอร์พารามิเตอร์นี้
การใช้งานทั้ง 2 รูปแบบนี้จะสร้างลําดับ Halton สําหรับพื้นที่การค้นหาหนึ่งๆ (มีไว้เพื่อใช้ลําดับ Halton ที่เลื่อนและสลับที่ตามที่แนะนําในไฮเปอร์พารามิเตอร์สําคัญ: ไม่สุ่ม ไม่ร้องไห้)
หากไม่มีอัลกอริทึมการค้นหาแบบกึ่งสุ่มที่อิงตามลําดับความคลาดเคลื่อนต่ำ คุณอาจใช้การค้นหาแบบสุ่มเทียมแทนได้ แม้ว่าวิธีนี้อาจมีประสิทธิภาพน้อยกว่าเล็กน้อย ในมิติข้อมูล 1-2 รายการ ระบบจะยอมรับการค้นหาตารางกริดด้วย แต่ไม่ยอมรับในมิติข้อมูลระดับสูงขึ้น (ดู Bergstra & Bengio, 2012)
ต้องทำการทดสอบกี่ครั้งจึงจะได้ผลลัพธ์ที่ดีจากการค้นหาแบบเกือบสุ่ม
โดยทั่วไปแล้ว คุณจะไม่สามารถระบุจํานวนการทดสอบที่จําเป็นเพื่อให้ได้ผลลัพธ์จากการค้นหาแบบเกือบสุ่ม แต่คุณสามารถดูตัวอย่างที่เฉพาะเจาะจงได้ ดังที่รูปที่ 3 แสดง จำนวนการทดสอบในการศึกษาอาจมีผลอย่างมากต่อผลลัพธ์
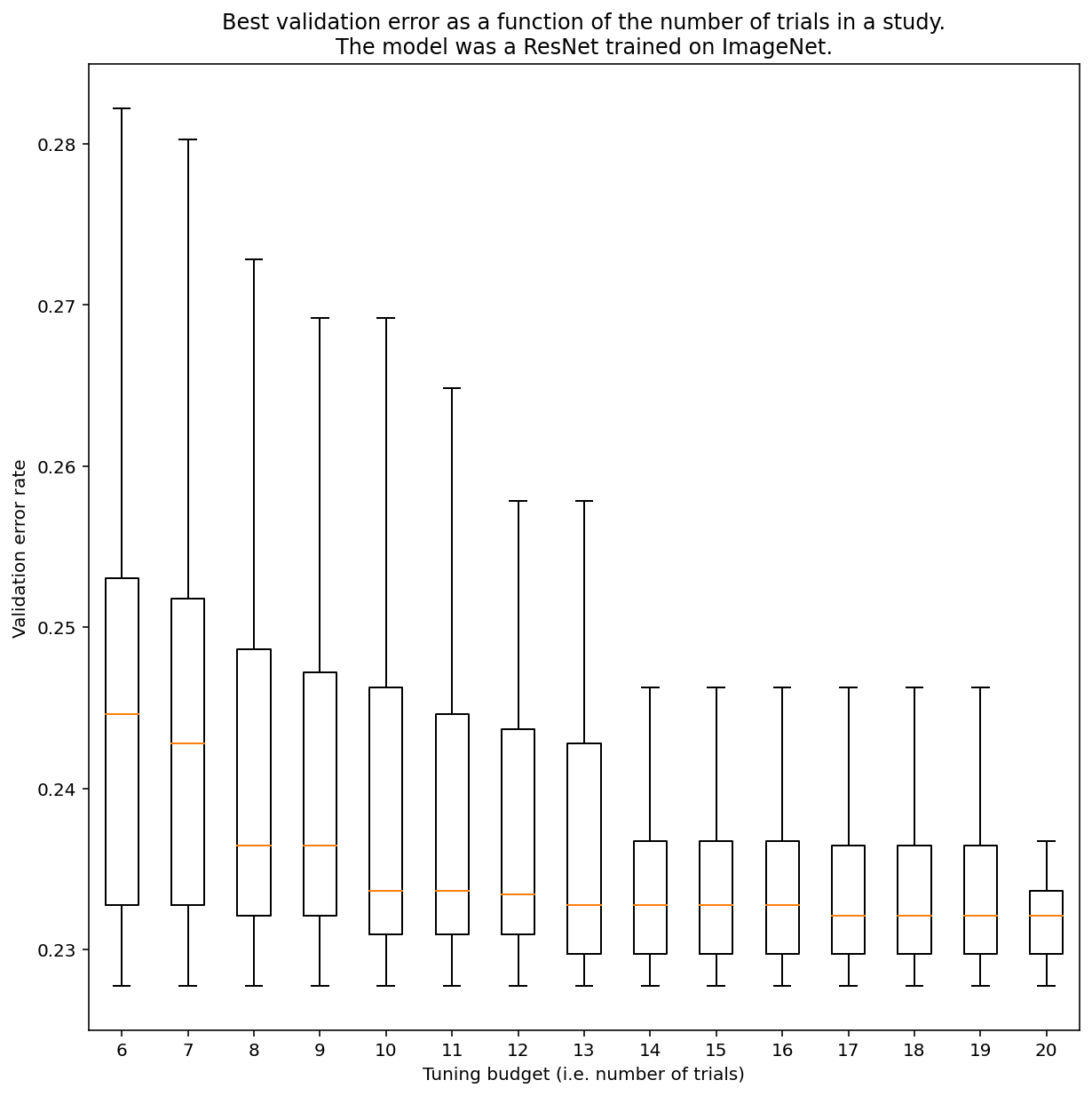
รูปที่ 3: ResNet-50 ที่ปรับแต่งใน ImageNet ด้วยการทดสอบ 100 ครั้ง โดยใช้การบูตสแ trapping ระบบจะจําลองงบประมาณการปรับแต่งจํานวนต่างๆ ระบบจะแสดงผังกล่องของประสิทธิภาพที่ดีที่สุดสําหรับงบประมาณการทดสอบแต่ละรายการ
โปรดสังเกตสิ่งต่อไปนี้เกี่ยวกับรูปที่ 3
- ช่วงระหว่างกลุ่มกลางเมื่อสุ่มตัวอย่าง 6 ครั้งจะใหญ่กว่ามากเมื่อสุ่มตัวอย่าง 20 ครั้ง
- แม้จะมีการทดสอบ 20 ครั้ง แต่ความแตกต่างระหว่างการศึกษาที่โชคดีและโชคร้ายมากก็อาจมากกว่าความผันผวนทั่วไประหว่างการฝึกโมเดลนี้ซ้ำด้วยข้อมูลสุ่มเริ่มต้นที่แตกต่างกัน โดยมีไฮเปอร์พารามิเตอร์แบบคงที่ ซึ่งสำหรับปริมาณงานนี้อาจอยู่ที่ประมาณ +/- 0.1% ในอัตราข้อผิดพลาดในการทดสอบ ~23%
-
Ben Recht และ Kevin Jamieson ได้ชี้ให้เห็นว่าวิธีการค้นหาแบบสุ่มที่มีงบประมาณ 2 เท่ามีประสิทธิภาพเพียงใดเมื่อเทียบกับฐานบรรทัด (บทความ Hyperband มีการโต้แย้งที่คล้ายกัน) แต่คุณก็อาจพบพื้นที่การค้นหาและปัญหาที่เทคนิคการเพิ่มประสิทธิภาพแบบเบย์เซียนล้ำสมัยทำงานได้ดีกว่าการค้นหาแบบสุ่มที่มีงบประมาณ 2 เท่า อย่างไรก็ตาม จากประสบการณ์ของเรา การเอาชนะการค้นหาแบบสุ่มที่มีงบประมาณ 2 เท่านั้นทําได้ยากขึ้นมากในโหมดการทำงานแบบขนานสูง เนื่องจากการเพิ่มประสิทธิภาพแบบเบย์เซียนไม่มีโอกาสที่จะสังเกตผลลัพธ์ของการทดสอบก่อนหน้านี้ ↩