Ten moduł dotyczy quasi-losowego wyszukiwania.
Dlaczego warto korzystać z quasi-losowego wyszukiwania?
W ramach powtarzalnego procesu dostrajania, którego celem jest maksymalizacja informacji o problemie dostrajania (co nazywamy „fazą eksploracji”), preferujemy quasi-losowe wyszukiwanie (oparte na sekwencjach o małej rozbieżności) niż bardziej zaawansowane narzędzia optymalizacji typu czarna skrzynka. Optymalizacja bayesowska i podobne narzędzia są bardziej odpowiednie na etapie eksploatacji. Wyszukiwanie quasi-losowe oparte na losowo przesuniętych sekwencjach o niskiej rozbieżności można uznać za „rozproszony, losowy skan siatki”, ponieważ równomiernie, ale losowo przeszukuje ono daną przestrzeń wyszukiwania i rozprasza punkty wyszukiwania bardziej niż wyszukiwanie losowe.
Zalety quasi-losowego wyszukiwania w porównaniu z bardziej zaawansowanymi narzędziami optymalizacji typu czarna skrzynka (np. optymalizacja bayesowska, algorytmy ewolucyjne) to:
- Próbkowanie przestrzeni wyszukiwania w sposób nieadaptacyjny umożliwia zmianę celu dostrajania w ramach analizy wstecznej bez ponownego przeprowadzania eksperymentów. Zwykle chcemy na przykład znaleźć najlepszy próbny wynik w terminie weryfikacji błędu osiągniętego w dowolnym momencie treningu. Jednak nieadaptacyjna natura quasilosowego wyszukiwania umożliwia znalezienie najlepszej próby na podstawie końcowego błędu weryfikacji, błędu uczenia lub jakiegoś alternatywnego wskaźnika oceny bez ponownego przeprowadzania eksperymentów.
- Wyszukiwanie quasi-losowe działa w sposób spójny i powtarzalny statystycznie. Powtórne przeprowadzenie badania sprzed 6 miesięcy powinno być możliwe nawet wtedy, gdy implementacja algorytmu wyszukiwania ulegnie zmianie, o ile zachowa ona te same właściwości jednorodności. Jeśli używasz zaawansowanego oprogramowania do optymalizacji bayesowskiej, implementacja może się istotnie zmienić między wersjami, co znacznie utrudnia odtworzenie starego wyszukiwania. Nie zawsze można przywrócić starą implementację (np. jeśli narzędzie optymalizacyjne działa jako usługa).
- Jednolite eksplorowanie przestrzeni wyszukiwania ułatwia analizowanie wyników i ich interpretację. Jeśli na przykład najlepszy punkt w przeszukiwaniu quasi-losowym znajduje się na granicy przestrzeni wyszukiwania, jest to dobry (choć nie niezawodny) sygnał, że należy zmienić granice przestrzeni wyszukiwania. Jednak adaptacyjny algorytm optymalizacji typu czarna skrzynka może pominąć środkową część przestrzeni wyszukiwania z powodu niefortunnych wczesnych prób, nawet jeśli zawiera ona równie dobre punkty, ponieważ to właśnie tego rodzaju niejednorodność musi wykorzystać dobry algorytm optymalizacji, aby przyspieszyć wyszukiwanie.
- Przeprowadzanie różnych liczb prób równolegle lub sekwencyjnie nie daje statystycznie istotnych wyników w przypadku quasi-losowego wyszukiwania (lub innych nieadaptacyjnych algorytmów wyszukiwania), w przeciwieństwie do algorytmów adaptacyjnych.
- Bardziej zaawansowane algorytmy wyszukiwania nie zawsze poprawnie obsługują punkty nieosiągalne, zwłaszcza jeśli nie zostały zaprojektowane z myślą o dostrajaniu hiperparametrów sieci neuronowej.
- Wyszukiwanie quasi-losowe jest proste i działa szczególnie dobrze, gdy wiele prób dostrajania jest uruchamianych równolegle. Z doświadczeń1 wynika, że algorytm adaptacyjny bardzo rzadko wygrywa z quasilosowym algorytmem, który ma 2 razy większy budżet, zwłaszcza gdy wiele prób trzeba przeprowadzać równolegle (a więc przy uruchamianiu nowych prób jest bardzo mało szans na wykorzystanie wyników poprzednich prób). Bez doświadczenia w optymalizacji bayesowskiej i innych zaawansowanych metodach optymalizacji typu czarna skrzynka możesz nie osiągnąć korzyści, które w zasadzie są możliwe do uzyskania. Trudno jest porównywać zaawansowane algorytmy optymalizacji typu czarna skrzynka w realistycznych warunkach dostosowania deep learningu. Jest to bardzo aktywny obszar obecnych badań, a bardziej zaawansowane algorytmy mają swoje pułapki dla niedoświadczonych użytkowników. Eksperci w zakresie tych metod są w stanie uzyskać dobre wyniki, ale w warunkach wysokiego równoległości przestrzeń wyszukiwania i budżet mają zwykle większe znaczenie.
Jeśli jednak Twoje zasoby obliczeniowe pozwalają na prowadzenie tylko niewielkiej liczby prób równolegle, a możesz sobie pozwolić na prowadzenie wielu prób sekwencyjnie, optymalizacja bayesowska stanie się znacznie bardziej atrakcyjna, mimo że utrudni to interpretację wyników dostrajania.
Gdzie mogę znaleźć implementację quasi-losowego wyszukiwania?
Open-Source Vizier zawiera implementację quasi-losowego wyszukiwania.
Ustaw algorithm="QUASI_RANDOM_SEARCH" w tym przykładzie użycia Vizier.
Alternatywną implementację znajdziesz w tym przykładzie przeszukań hiperparametrów.
Obie te implementacje generują sekwencję Haltona dla danej przestrzeni wyszukiwania (zaprojektowanej w celu implementacji przesuniętej, zaszyfrowanej sekwencji Haltona zgodnie z zaleceniami w Critical Hyper-Parameters: No Random, No Cry).
Jeśli algorytm quasi-losowego wyszukiwania oparty na sekwencji o małej rozbieżności jest niedostępny, można zastąpić go pseudolosowym wyszukiwaniem równomiernym, które jest jednak prawdopodobnie nieco mniej wydajne. W przypadku 1–2 wymiarów dopuszczalna jest też wyszukiwanie w siatce, ale nie w przypadku większej liczby wymiarów. (patrz Bergstra & Bengio, 2012).
Ile prób jest potrzebnych do uzyskania dobrych wyników w przypadku quasi-losowego wyszukiwania?
Nie ma możliwości określenia, ile prób jest potrzebnych do uzyskania wyników z wyszukiwaniem quasi-losowym, ale możesz zapoznać się z konkretnymi przykładami. Jak widać na rysunku 3, liczba prób w badaniu może mieć znaczący wpływ na wyniki:
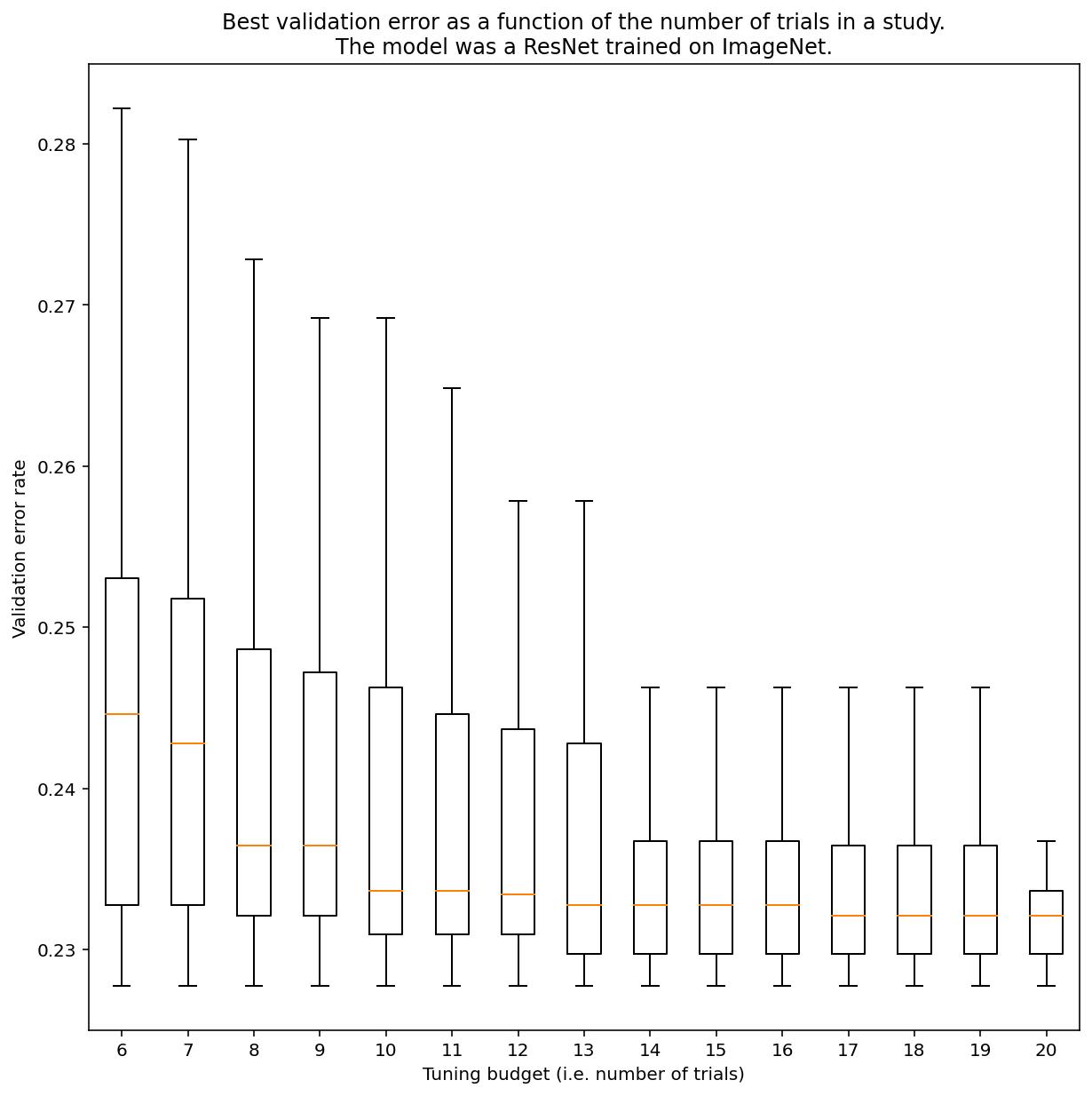
Rysunek 3: sieć ResNet-50 dostrojona na podstawie ImageNet za pomocą 100 prób. Za pomocą metody bootstrapping symulowano różne kwoty budżetu dostosowania. Wyświetlane są wykresy osi Y dla najlepszych wyników w przypadku każdego testowanego budżetu.
Zwróć uwagę na poniższe informacje dotyczące rysunku 3:
- Interkwartyle w przypadku 6 prób są znacznie większe niż w przypadku 20 prób.
- Nawet przy 20 próbach różnica między szczególnie szczęśliwymi a nieszczęśliwymi badaniami jest prawdopodobnie większa niż typowa zmienność między ponownymi trenowaniami tego modelu z różnymi losowymi ziarnami przy stałych parametrach hiperparametrów, która w przypadku tego zbioru zadań może wynosić około ±0,1% przy współczynniku błędów walidacji wynoszącym około 23%.
-
Ben Recht i Kevin Jamieson wskazali, że losowe wyszukiwanie z podwójnym budżetem jest bardzo skuteczne (w artykule o Hyperband można znaleźć podobne argumenty), ale można też znaleźć przestrzenie wyszukiwania i problemy, w których najnowocześniejsze techniki optymalizacji bayesowskiej znacznie przewyższają losowe wyszukiwanie z podwójnym budżetem. Z naszych doświadczeń wynika jednak, że w reżimie wysokiej równoległości trudniej jest uzyskać lepszy wynik niż w przypadku losowego wyszukiwania z podwójnym budżetem, ponieważ optymalizacja bayesowska nie ma możliwości obserwowania wyników poprzednich prób. ↩