यह यूनिट, क्वासी-रैंडम सर्च पर फ़ोकस करती है.
क्वासी-रैंडम सर्च का इस्तेमाल क्यों करना चाहिए?
जब बार-बार ट्यून करने की प्रोसेस के हिस्से के तौर पर इस्तेमाल किया जाता है, तो हमारी प्राथमिकता, कम अंतर वाले सीक्वेंस पर आधारित क्वॉज़ी-रैंडम सर्च (कुछ हद तक रैंडम) होती है. इसका मकसद, ट्यूनिंग की समस्या के बारे में ज़्यादा से ज़्यादा जानकारी हासिल करना होता है. इसे हम "एक्सप्लोरेशन फ़ेज़" कहते हैं. बेज़ियन ऑप्टिमाइज़ेशन और मिलते-जुलते टूल, एक्सप्लॉइटेशन फ़ेज़ के लिए ज़्यादा सही हैं. रैंडम तौर पर बदले गए कम अंतर वाले क्रम के आधार पर, क्वॉज़ी-रैंडम सर्च को "जिटर्ड, शफ़ल की गई ग्रिड सर्च" माना जा सकता है. ऐसा इसलिए, क्योंकि यह किसी दिए गए सर्च स्पेस को एक जैसा, लेकिन रैंडम तौर पर एक्सप्लोर करता है और रैंडम सर्च की तुलना में सर्च पॉइंट को ज़्यादा फैलाता है.
ज़्यादा बेहतर ब्लैकबॉक्स ऑप्टिमाइज़ेशन टूल (जैसे, बेयसियन ऑप्टिमाइज़ेशन, इवोल्यूशनरी एल्गोरिदम) के मुकाबले, क्वॉज़ी-रैंडम सर्च के फ़ायदे ये हैं:
- सर्च स्पेस को बिना अडैप्टिव तरीके से सैंपल करने पर, पोस्ट होक विश्लेषण में ट्यूनिंग के मकसद को बदला जा सकता है. इसके लिए, प्रयोगों को फिर से चलाने की ज़रूरत नहीं होती. उदाहरण के लिए, आम तौर पर हम ट्रेनिंग के किसी भी समय हुई पुष्टि की गड़बड़ी के हिसाब से, सबसे अच्छा ट्रायल ढूंढना चाहते हैं. हालांकि, क्वॉज़ी-रैंडम सर्च के अडैप्टिव न होने की वजह से, किसी भी प्रयोग को फिर से चलाए बिना, पुष्टि करने से जुड़ी फ़ाइनल गड़बड़ी, ट्रेनिंग गड़बड़ी या किसी अन्य वैकल्पिक मेट्रिक के आधार पर, सबसे अच्छा ट्रायल ढूंढा जा सकता है.
- क्वॉज़ी-रैंडम सर्च, एक जैसा और आंकड़ों के हिसाब से दोबारा इस्तेमाल किया जा सकने वाला तरीका अपनाती है. खोज के एल्गोरिदम में बदलाव होने के बावजूद, छह महीने पहले की स्टडी को फिर से बनाया जा सकता है. हालांकि, इसके लिए ज़रूरी है कि स्टडी में एक जैसी प्रॉपर्टी बनी रहें. अगर बेहतर बेयसियन ऑप्टिमाइज़ेशन सॉफ़्टवेयर का इस्तेमाल किया जा रहा है, तो वर्शन के बीच लागू करने का तरीका काफ़ी अहम तरीके से बदल सकता है. इससे, पुरानी खोज को फिर से दिखाना काफ़ी मुश्किल हो जाता है. हमेशा किसी पुराने वर्शन पर वापस नहीं जाया जा सकता. उदाहरण के लिए, अगर ऑप्टिमाइज़ेशन टूल को सेवा के तौर पर चलाया जाता है.
- खोज स्पेस को एक जैसा एक्सप्लोर करने की सुविधा की मदद से, नतीजों के बारे में आसानी से अनुमान लगाया जा सकता है. साथ ही, यह भी पता लगाया जा सकता है कि खोज स्पेस के बारे में वे क्या सुझाव दे सकते हैं. उदाहरण के लिए, अगर क्वॉज़ी-रैंडम सर्च के दौरान सबसे अच्छा पॉइंट, खोज स्पेस की सीमा पर है, तो यह एक अच्छा संकेत है कि खोज स्पेस की सीमाओं को बदला जाना चाहिए. हालांकि, यह 100% सही नहीं है. हालांकि, हो सकता है कि अडैप्टिव ब्लैकबॉक्स ऑप्टिमाइज़ेशन एल्गोरिदम ने शुरुआती कुछ कोशिशों में खराब नतीजे मिलने की वजह से, खोज स्पेस के बीच में मौजूद पॉइंट को अनदेखा किया हो. भले ही, उसमें उतने ही अच्छे पॉइंट हों, क्योंकि खोज की प्रोसेस को तेज़ करने के लिए, अच्छे ऑप्टिमाइज़ेशन एल्गोरिदम को इसी तरह की गड़बड़ी का इस्तेमाल करना होता है.
- अडैप्टिव एल्गोरिदम के उलट, क्वॉज़ी-रैंडम सर्च (या अन्य नॉन-अडैप्टिव सर्च एल्गोरिदम) का इस्तेमाल करने पर, एक साथ या क्रम से अलग-अलग संख्या में ट्रायल चलाने से, आंकड़ों के हिसाब से अलग-अलग नतीजे नहीं मिलते.
- ज़्यादा बेहतर सर्च एल्गोरिद्म, शायद हमेशा असंभव बिंदुओं को सही तरीके से मैनेज न कर पाएं. ऐसा खास तौर पर तब होता है, जब उन्हें न्यूरल नेटवर्क के लिए, बेहतर तरीके से ट्यून किए गए हाइपरपैरामीटर के साथ डिज़ाइन न किया गया हो.
- क्वॉज़ी-रैंडम सर्च आसान है और यह तब बेहतर तरीके से काम करती है, जब कई ट्यूनिंग ट्रायल एक साथ चल रहे हों. आम तौर पर1, अडैप्टिव एल्गोरिदम के लिए, अपने बजट से दोगुनी रकम वाले क्वाज़ी-रैंडम सर्च को हराना बहुत मुश्किल होता है. खास तौर पर, जब कई ट्रायल को एक साथ चलाना ज़रूरी हो. इसलिए, नए ट्रायल लॉन्च करते समय, पिछले ट्रायल के नतीजों का इस्तेमाल करने की संभावनाएं बहुत कम होती हैं. बेज़ियन ऑप्टिमाइज़ेशन और ब्लैकबॉक्स ऑप्टिमाइज़ेशन के अन्य बेहतर तरीकों के बारे में विशेषज्ञता के बिना, हो सकता है कि आपको वे फ़ायदे न मिलें जो सिद्धांत रूप से, ये तरीके दे सकते हैं. असल डीप लर्निंग ट्यूनिंग की स्थितियों में, बेहतर ब्लैकबॉक्स ऑप्टिमाइज़ेशन एल्गोरिदम को बेंचमार्क करना मुश्किल होता है. फ़िलहाल, इन पर काफ़ी रिसर्च की जा रही है. साथ ही, ज़्यादा बेहतर एल्गोरिदम का इस्तेमाल करने पर, अनुभवहीन उपयोगकर्ताओं को कई समस्याएं आ सकती हैं. इन तरीकों के विशेषज्ञों को अच्छे नतीजे मिलते हैं, लेकिन ज़्यादा पैरलल प्रोसेसिंग की स्थितियों में, खोज स्पेस और बजट का ज़्यादा फ़ायदा होता है.
हालांकि, अगर आपके कंप्यूटेशनल संसाधनों की वजह से, एक साथ सिर्फ़ कुछ ट्रायल चलाए जा सकते हैं और आपके पास क्रम से कई ट्रायल चलाने का विकल्प है, तो ट्यूनिंग के नतीजों को समझना मुश्किल होने के बावजूद, बेयसियन ऑप्टिमाइज़ेशन काफ़ी आकर्षक हो जाता है.
मुझे क्वॉज़ी-रैंडम सर्च को लागू करने का तरीका कहां मिलेगा?
ओपन-सोर्स Vizier में, कुछ हद तक यादृच्छिक खोज की सुविधा है.
Vizier के इस्तेमाल के इस उदाहरण में algorithm="QUASI_RANDOM_SEARCH" सेट करें.
इस हाइपरपैरामीटर स्वीप के उदाहरण में, लागू करने का एक अन्य तरीका मौजूद है.
इन दोनों तरीकों से, किसी दिए गए सर्च स्पेस के लिए एक हैल्टन क्रम जनरेट होता है. इसका मकसद, ज़रूरी हाइपर-पैरामीटर: कोई रैंडम, कोई क्राई में सुझाए गए तरीके के मुताबिक, बदला गया और क्रम से लगाया गया हैल्टन क्रम लागू करना है.
अगर कम अंतर वाले क्रम के आधार पर, क्वॉज़ी-रैंडम सर्च एल्गोरिदम उपलब्ध नहीं है, तो इसके बजाय, स्यूडो रैंडम यूनिफ़ॉर्म सर्च का इस्तेमाल किया जा सकता है. हालांकि, इसकी परफ़ॉर्मेंस थोड़ी कम हो सकती है. एक से दो डाइमेंशन में, ग्रिड सर्च का इस्तेमाल किया जा सकता है. हालांकि, ज़्यादा डाइमेंशन में ऐसा नहीं किया जा सकता. (Bergstra & Bengio, 2012 देखें).
क्वासी-रैंडम सर्च की मदद से अच्छे नतीजे पाने के लिए, कितनी बार आज़माना ज़रूरी है?
आम तौर पर, क्वाज़ी-रैंडम सर्च से नतीजे पाने के लिए, कितने ट्रायल की ज़रूरत होगी, यह तय नहीं किया जा सकता. हालांकि, कुछ खास उदाहरणों को देखा जा सकता है. जैसा कि तीसरे चित्र में दिखाया गया है, किसी स्टडी में ट्रायल की संख्या का नतीजों पर काफ़ी असर पड़ सकता है:
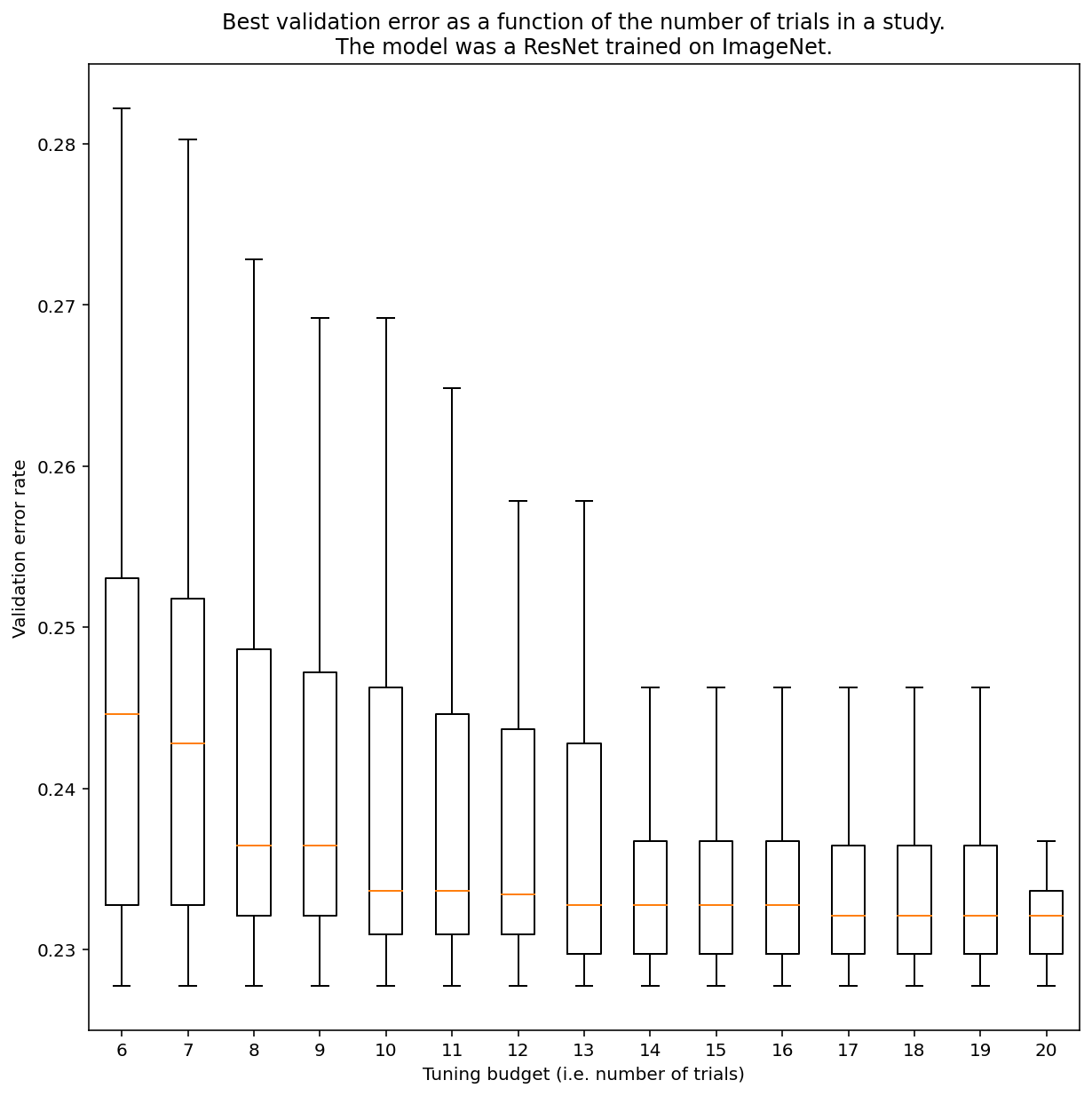
तीसरी इमेज: ResNet-50 को ImageNet पर 100 ट्रायल के साथ ट्यून किया गया. बूटस्ट्रैपिंग का इस्तेमाल करके, ट्यूनिंग बजट की अलग-अलग रकम को सिम्युलेट किया गया. हर ट्रायल बजट के लिए, सबसे अच्छी परफ़ॉर्मेंस के बॉक्स प्लॉट प्लॉट किए जाते हैं.
तीसरे चित्र के बारे में इन बातों पर ध्यान दें:
- छह ट्रायल के सैंपल लेने पर, इंटरक्वार्टील रेंज, 20 ट्रायल के सैंपल लेने पर मिलने वाली इंटरक्वार्टील रेंज से काफ़ी ज़्यादा होती है.
- 20 ट्रायल के बाद भी, खास तौर पर अच्छी और खराब परफ़ॉर्मेंस वाले अध्ययनों के बीच का अंतर, तय किए गए हाइपरपैरामीटर के साथ, अलग-अलग रैंडम सीड पर इस मॉडल को फिर से ट्रेन करने के बीच के सामान्य अंतर से ज़्यादा हो सकता है. इस वर्कलोड के लिए, पुष्टि करने में हुई गड़बड़ी का दर ~23% होने पर, यह अंतर +/- 0.1% हो सकता है.
-
बेन रेक्ट और केविन जैमिसन ने इस बात पर ज़ोर दिया कि बेसलाइन के तौर पर, 2X बजट वाली रैंडम सर्च कितनी असरदार है. Hyperband पेपर में भी इसी तरह के तर्क दिए गए हैं. हालांकि, ऐसे सर्च स्पेस और समस्याएं ढूंढना मुमकिन है जहां बेज़ियन ऑप्टिमाइज़ेशन की आधुनिक तकनीकें, 2X बजट वाली रैंडम सर्च को पीछे छोड़ देती हैं. हालांकि, हमारे अनुभव के मुताबिक, ज़्यादा पैरलल प्रोसेस वाले सिस्टम में, 2X बजट वाली रैंडम सर्च को बेहतर बनाना काफ़ी मुश्किल हो जाता है. इसकी वजह यह है कि बेयसियन ऑप्टिमाइज़ेशन के पास, पिछले ट्रायल के नतीजों को देखने का कोई मौका नहीं होता. ↩