Unit ini berfokus pada penelusuran kuasi-acak.
Mengapa menggunakan penelusuran kuasi-acak?
Penelusuran kuasi-acak (berdasarkan urutan perbedaan rendah) adalah preferensi kami dibandingkan alat pengoptimalan blackbox yang lebih canggih saat digunakan sebagai bagian dari proses penyesuaian iteratif yang dimaksudkan untuk memaksimalkan insight tentang masalah penyesuaian (yang kami sebut sebagai "fase eksplorasi"). Pengoptimalan Bayesian dan alat serupa lebih sesuai untuk fase eksploitasi. Penelusuran kuasi-acak berdasarkan urutan perbedaan rendah yang bergeser secara acak dapat dianggap sebagai "penelusuran petak yang diacak dan di-jittered", karena secara merata, tetapi secara acak, menjelajahi ruang penelusuran tertentu dan menyebarkan titik penelusuran lebih dari penelusuran acak.
Keunggulan penelusuran kuasi-acak dibandingkan alat pengoptimalan blackbox yang lebih canggih (misalnya, pengoptimalan Bayesian, algoritma evolusioner) meliputi:
- Mengambil sampel ruang penelusuran secara non-adaptif memungkinkan perubahan tujuan penyesuaian dalam analisis post hoc tanpa menjalankan ulang eksperimen. Misalnya, kita biasanya ingin menemukan uji coba terbaik dalam hal error validasi yang dicapai pada titik mana pun dalam pelatihan. Namun, sifat non-adaptif penelusuran kuasi-acak memungkinkan penemuan uji coba terbaik berdasarkan error validasi akhir, error pelatihan, atau beberapa metrik evaluasi alternatif tanpa menjalankan ulang eksperimen apa pun.
- Penelusuran kuasi-acak berperilaku secara konsisten dan dapat direproduksi secara statistik. Anda seharusnya dapat mereproduksi studi dari enam bulan lalu meskipun implementasi algoritma penelusuran berubah, selama studi tersebut mempertahankan properti keseragaman yang sama. Jika menggunakan software pengoptimalan Bayesian yang canggih, penerapannya mungkin berubah secara signifikan di antara versi, sehingga mempersulit reproduksi penelusuran lama. Anda tidak selalu dapat melakukan rollback ke penerapan lama (misalnya, jika alat pengoptimalan dijalankan sebagai layanan).
- Eksplorasi ruang penelusuran yang seragam memudahkan untuk memahami hasil dan apa yang mungkin disarankannya tentang ruang penelusuran. Misalnya, jika titik terbaik dalam penelusuran quasi-random berada di batas ruang penelusuran, ini adalah sinyal yang baik (tetapi tidak sepenuhnya aman) bahwa batas ruang penelusuran harus diubah. Namun, algoritma pengoptimalan blackbox adaptif mungkin telah mengabaikan bagian tengah ruang penelusuran karena beberapa uji coba awal yang tidak beruntung meskipun kebetulan berisi titik yang sama baiknya, karena inilah jenis ketidaksetaraan yang harus digunakan algoritma pengoptimalan yang baik untuk mempercepat penelusuran.
- Menjalankan jumlah percobaan yang berbeda secara paralel versus berurutan tidak menghasilkan hasil yang berbeda secara statistik saat menggunakan penelusuran quasi-random (atau algoritma penelusuran non-adaptif lainnya), tidak seperti algoritma adaptif.
- Algoritme penelusuran yang lebih canggih mungkin tidak selalu menangani titik yang tidak dapat dilakukan dengan benar, terutama jika tidak dirancang dengan mempertimbangkan penyesuaian hyperparameter jaringan neural.
- Penelusuran kuasi-acak bersifat sederhana dan berfungsi sangat baik saat banyak uji coba penyesuaian berjalan secara paralel. Secara anekdotal1, sangat sulit bagi algoritma adaptif untuk mengalahkan penelusuran kuasi-acak yang memiliki anggaran 2X lipat, terutama saat banyak uji coba perlu dijalankan secara paralel (sehingga sangat sedikit peluang untuk menggunakan hasil uji coba sebelumnya saat meluncurkan uji coba baru). Tanpa keahlian dalam pengoptimalan Bayesian dan metode pengoptimalan blackbox lanjutan lainnya, Anda mungkin tidak akan mendapatkan manfaat yang, pada prinsipnya, dapat diberikan oleh metode tersebut. Sulit untuk menjalankan benchmark pada algoritma pengoptimalan blackbox lanjutan dalam kondisi penyesuaian deep learning yang realistis. Ini adalah area riset yang sangat aktif saat ini, dan algoritma yang lebih canggih memiliki kekurangannya sendiri bagi pengguna yang tidak berpengalaman. Pakar dalam metode ini dapat memperoleh hasil yang baik, tetapi dalam kondisi paralelisme tinggi, ruang penelusuran dan anggaran cenderung lebih penting.
Meskipun demikian, jika resource komputasi Anda hanya memungkinkan sejumlah kecil uji coba berjalan secara paralel dan Anda dapat menjalankan banyak uji coba secara berurutan, pengoptimalan Bayesian menjadi jauh lebih menarik meskipun membuat hasil penyesuaian Anda lebih sulit ditafsirkan.
Di mana saya dapat menemukan implementasi penelusuran kuasi-acak?
Vizier Open Source memiliki
implementasi penelusuran quasi-random.
Tetapkan algorithm="QUASI_RANDOM_SEARCH" di contoh penggunaan Vizier
ini.
Implementasi alternatif ada dalam contoh sapuan hyperparameter
ini.
Kedua implementasi ini menghasilkan urutan Halton untuk ruang penelusuran
tertentu (dimaksudkan untuk menerapkan urutan Halton yang digeser dan diacak seperti
yang direkomendasikan dalam
Hyper-Parameter Kritis: Tidak Acak, Tidak
Menangis.
Jika algoritma penelusuran kuasi-acak berdasarkan urutan perbedaan rendah tidak tersedia, Anda dapat menggantinya dengan penelusuran seragam pseudo acak, meskipun hal ini mungkin sedikit kurang efisien. Dalam 1-2 dimensi, penelusuran petak juga dapat diterima, meskipun tidak dalam dimensi yang lebih tinggi. (Lihat Bergstra & Bengio, 2012).
Berapa banyak percobaan yang diperlukan untuk mendapatkan hasil yang baik dengan penelusuran kuasi-acak?
Tidak ada cara untuk menentukan jumlah percobaan yang diperlukan untuk mendapatkan hasil dengan penelusuran kuasi-acak secara umum, tetapi Anda dapat melihat contoh tertentu. Seperti yang ditunjukkan Gambar 3, jumlah uji coba dalam sebuah studi dapat memiliki dampak yang signifikan terhadap hasilnya:
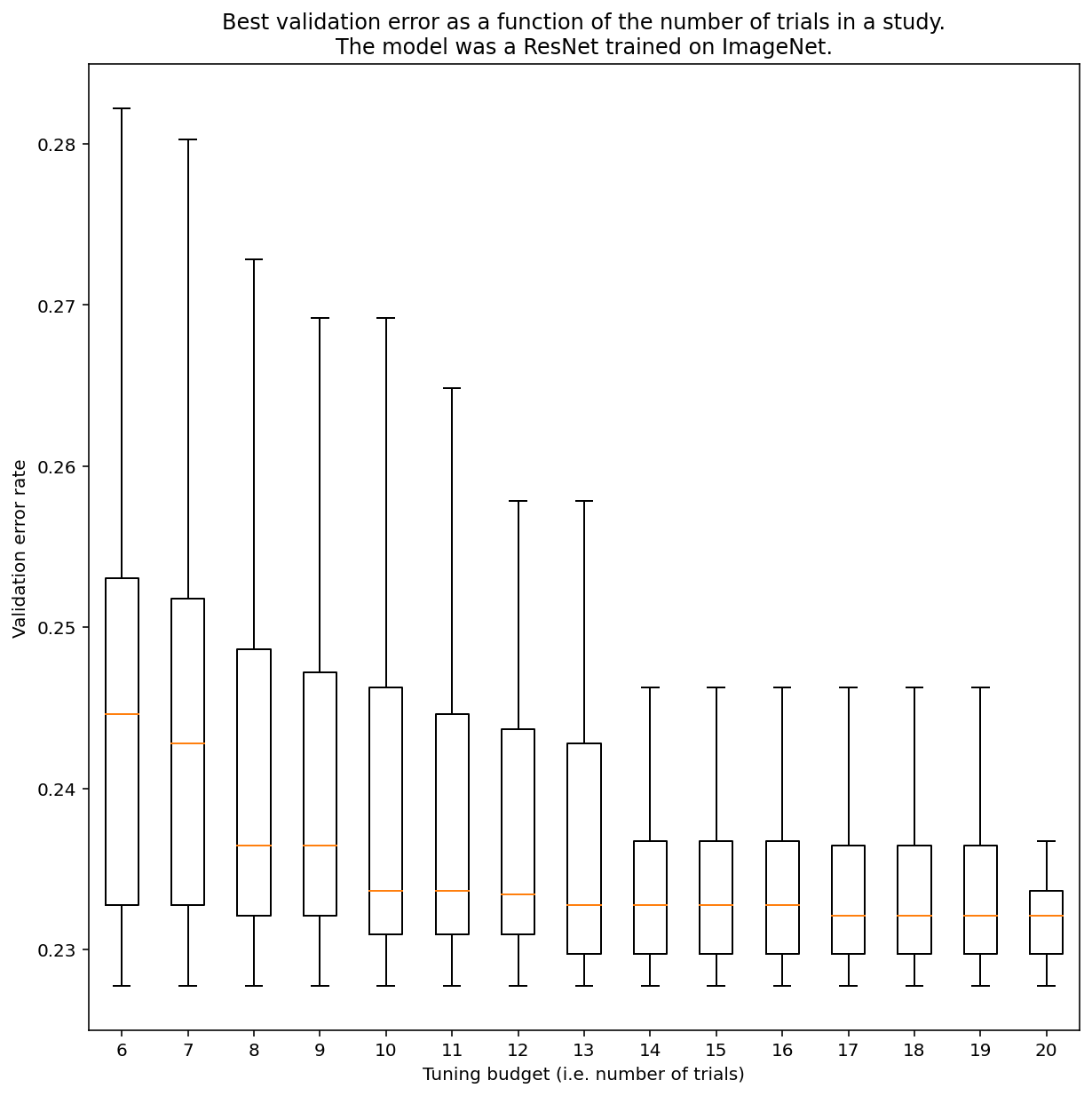
Gambar 3: ResNet-50 yang disesuaikan di ImageNet dengan 100 percobaan. Dengan bootstrapping, berbagai jumlah anggaran penyesuaian disimulasikan. Plot kotak performa terbaik untuk setiap anggaran uji coba akan diplot.
Perhatikan hal berikut tentang Gambar 3:
- Rentang kuartil saat 6 uji coba diambil sampelnya jauh lebih besar daripada saat 20 uji coba diambil sampelnya.
- Meskipun dengan 20 percobaan, perbedaan antara studi yang beruntung dan tidak beruntung mungkin lebih besar daripada variasi umum antara pelatihan ulang model ini pada seed acak yang berbeda, dengan hyperparameter tetap, yang untuk beban kerja ini mungkin sekitar +/- 0,1% pada tingkat error validasi ~23%.
-
Ben Recht dan Kevin Jamieson menunjukkan betapa kuatnya penelusuran acak dengan anggaran 2X lipat sebagai dasar pengukuran (makalah Hyperband memiliki argumen serupa), tetapi tentu saja Anda dapat menemukan ruang penelusuran dan masalah yang menggunakan teknik pengoptimalan Bayesian tercanggih yang mengalahkan penelusuran acak dengan anggaran 2X lipat. Namun, berdasarkan pengalaman kami, meningkatkan penelusuran acak dengan anggaran 2X menjadi jauh lebih sulit dalam rezim paralelisme tinggi karena pengoptimalan Bayesian tidak memiliki peluang untuk mengamati hasil percobaan sebelumnya. ↩