Bài này tập trung vào tìm kiếm gần như ngẫu nhiên.
Tại sao nên sử dụng phương thức tìm kiếm gần như ngẫu nhiên?
Chúng tôi ưu tiên sử dụng phương thức tìm kiếm gần như ngẫu nhiên (dựa trên các trình tự có độ chênh lệch thấp) hơn các công cụ tối ưu hoá hộp đen phức tạp hơn khi được sử dụng trong quy trình điều chỉnh lặp lại nhằm tối đa hoá thông tin chi tiết về vấn đề điều chỉnh (chúng tôi gọi là "giai đoạn khám phá"). Tối ưu hoá Bayesian và các công cụ tương tự phù hợp hơn với giai đoạn khai thác. Phương thức tìm kiếm gần như ngẫu nhiên dựa trên các trình tự có độ chênh lệch thấp được dịch chuyển ngẫu nhiên có thể được coi là "tìm kiếm lưới bị giật, bị xáo trộn", vì phương thức này khám phá một không gian tìm kiếm nhất định một cách đồng nhất nhưng ngẫu nhiên và trải rộng các điểm tìm kiếm nhiều hơn so với phương thức tìm kiếm ngẫu nhiên.
Các ưu điểm của phương pháp tìm kiếm gần như ngẫu nhiên so với các công cụ tối ưu hoá hộp đen phức tạp hơn (ví dụ: tối ưu hoá Bayesian, thuật toán tiến hoá) bao gồm:
- Việc lấy mẫu không thích ứng không gian tìm kiếm cho phép thay đổi mục tiêu điều chỉnh trong phân tích sau thử nghiệm mà không cần chạy lại các thử nghiệm. Ví dụ: chúng ta thường muốn tìm thử nghiệm tốt nhất về lỗi xác thực đạt được tại bất kỳ thời điểm nào trong quá trình huấn luyện. Tuy nhiên, bản chất không thích ứng của tính năng tìm kiếm gần như ngẫu nhiên cho phép tìm thử nghiệm tốt nhất dựa trên lỗi xác thực cuối cùng, lỗi huấn luyện hoặc một số chỉ số đánh giá thay thế mà không cần chạy lại bất kỳ thử nghiệm nào.
- Tìm kiếm gần như ngẫu nhiên hoạt động một cách nhất quán và có thể tái tạo thống kê. Bạn có thể tái tạo một nghiên cứu từ 6 tháng trước ngay cả khi cách triển khai thuật toán tìm kiếm thay đổi, miễn là thuật toán đó vẫn duy trì các thuộc tính đồng nhất. Nếu sử dụng phần mềm tối ưu hoá Bayesian phức tạp, thì cách triển khai có thể thay đổi theo một cách quan trọng giữa các phiên bản, khiến việc tái tạo một nội dung tìm kiếm cũ trở nên khó khăn hơn nhiều. Không phải lúc nào bạn cũng có thể quay lại cách triển khai cũ (ví dụ: nếu công cụ tối ưu hoá được chạy dưới dạng dịch vụ).
- Việc khám phá không gian tìm kiếm một cách đồng nhất giúp dễ dàng suy luận về kết quả và những gì kết quả có thể gợi ý về không gian tìm kiếm. Ví dụ: nếu điểm tốt nhất trong quá trình truy cập tìm kiếm gần như ngẫu nhiên nằm ở ranh giới của không gian tìm kiếm, thì đây là tín hiệu tốt (nhưng không hoàn toàn chính xác) cho thấy bạn nên thay đổi ranh giới không gian tìm kiếm. Tuy nhiên, thuật toán tối ưu hoá hộp đen thích ứng có thể đã bỏ qua phần giữa không gian tìm kiếm do một số thử nghiệm ban đầu không may mắn, ngay cả khi không gian tìm kiếm đó chứa các điểm tốt như nhau, vì đây chính xác là loại không đồng nhất mà thuật toán tối ưu hoá tốt cần sử dụng để tăng tốc độ tìm kiếm.
- Việc chạy song song nhiều số lần thử nghiệm so với chạy tuần tự không tạo ra kết quả khác biệt về mặt thống kê khi sử dụng phương thức tìm kiếm gần như ngẫu nhiên (hoặc các thuật toán tìm kiếm không thích ứng khác), không giống như với các thuật toán thích ứng.
- Các thuật toán tìm kiếm phức tạp hơn không phải lúc nào cũng xử lý chính xác các điểm không thể thực hiện được, đặc biệt là nếu các thuật toán đó không được thiết kế để điều chỉnh tham số siêu dữ liệu của mạng nơron.
- Tìm kiếm gần như ngẫu nhiên rất đơn giản và hoạt động đặc biệt hiệu quả khi nhiều thử nghiệm điều chỉnh chạy song song. Theo kinh nghiệm1, rất khó để một thuật toán thích ứng đánh bại một phương thức tìm kiếm gần như ngẫu nhiên có ngân sách gấp đôi, đặc biệt là khi cần chạy nhiều thử nghiệm song song (và do đó, có rất ít cơ hội để sử dụng kết quả thử nghiệm trước đó khi chạy thử nghiệm mới). Nếu không có chuyên môn về phương pháp tối ưu hoá Bayesian và các phương pháp tối ưu hoá hộp đen nâng cao khác, về nguyên tắc, bạn có thể không đạt được những lợi ích mà các phương pháp này có thể mang lại. Rất khó để đo điểm chuẩn các thuật toán tối ưu hoá hộp đen nâng cao trong điều kiện điều chỉnh học sâu thực tế. Đây là một lĩnh vực nghiên cứu rất tích cực hiện nay và các thuật toán phức tạp hơn cũng có những cạm bẫy riêng đối với người dùng chưa có kinh nghiệm. Các chuyên gia về các phương thức này có thể nhận được kết quả tốt, nhưng trong điều kiện song song cao, không gian tìm kiếm và ngân sách có xu hướng quan trọng hơn nhiều.
Tuy nhiên, nếu tài nguyên điện toán của bạn chỉ cho phép một số ít thử nghiệm chạy song song và bạn có thể chạy nhiều thử nghiệm theo trình tự, thì phương pháp tối ưu hoá Bayesian sẽ trở nên hấp dẫn hơn nhiều mặc dù khiến kết quả điều chỉnh khó diễn giải hơn.
Tôi có thể tìm thấy cách triển khai tìm kiếm gần như ngẫu nhiên ở đâu?
Open-Source Vizier có cách triển khai tìm kiếm gần như ngẫu nhiên.
Đặt algorithm="QUASI_RANDOM_SEARCH" trong ví dụ về cách sử dụng Vizier này.
Có một phương thức triển khai thay thế trong ví dụ về quy trình quét tham số siêu dữ liệu này.
Cả hai phương thức triển khai này đều tạo một trình tự Halton cho một không gian tìm kiếm nhất định (dùng để triển khai một trình tự Halton đã chuyển đổi, xáo trộn như đề xuất trong Thông số siêu quan trọng: Không ngẫu nhiên, không khóc.
Nếu không có thuật toán tìm kiếm gần như ngẫu nhiên dựa trên trình tự có độ chênh lệch thấp, bạn có thể thay thế bằng thuật toán tìm kiếm đồng nhất giả ngẫu nhiên, mặc dù thuật toán này có thể kém hiệu quả hơn một chút. Trong 1-2 chiều, bạn cũng có thể sử dụng tính năng tìm kiếm theo lưới, mặc dù không thể sử dụng trong các chiều cao hơn. (Xem bài viết của Bergstra và Bengio, 2012).
Cần bao nhiêu lần thử nghiệm để có được kết quả tốt với phương thức tìm kiếm gần như ngẫu nhiên?
Nói chung, không có cách nào để xác định số lần thử nghiệm cần thiết để có được kết quả với tính năng tìm kiếm gần như ngẫu nhiên, nhưng bạn có thể xem các ví dụ cụ thể. Như Hình 3 cho thấy, số lượng thử nghiệm trong một nghiên cứu có thể ảnh hưởng đáng kể đến kết quả:
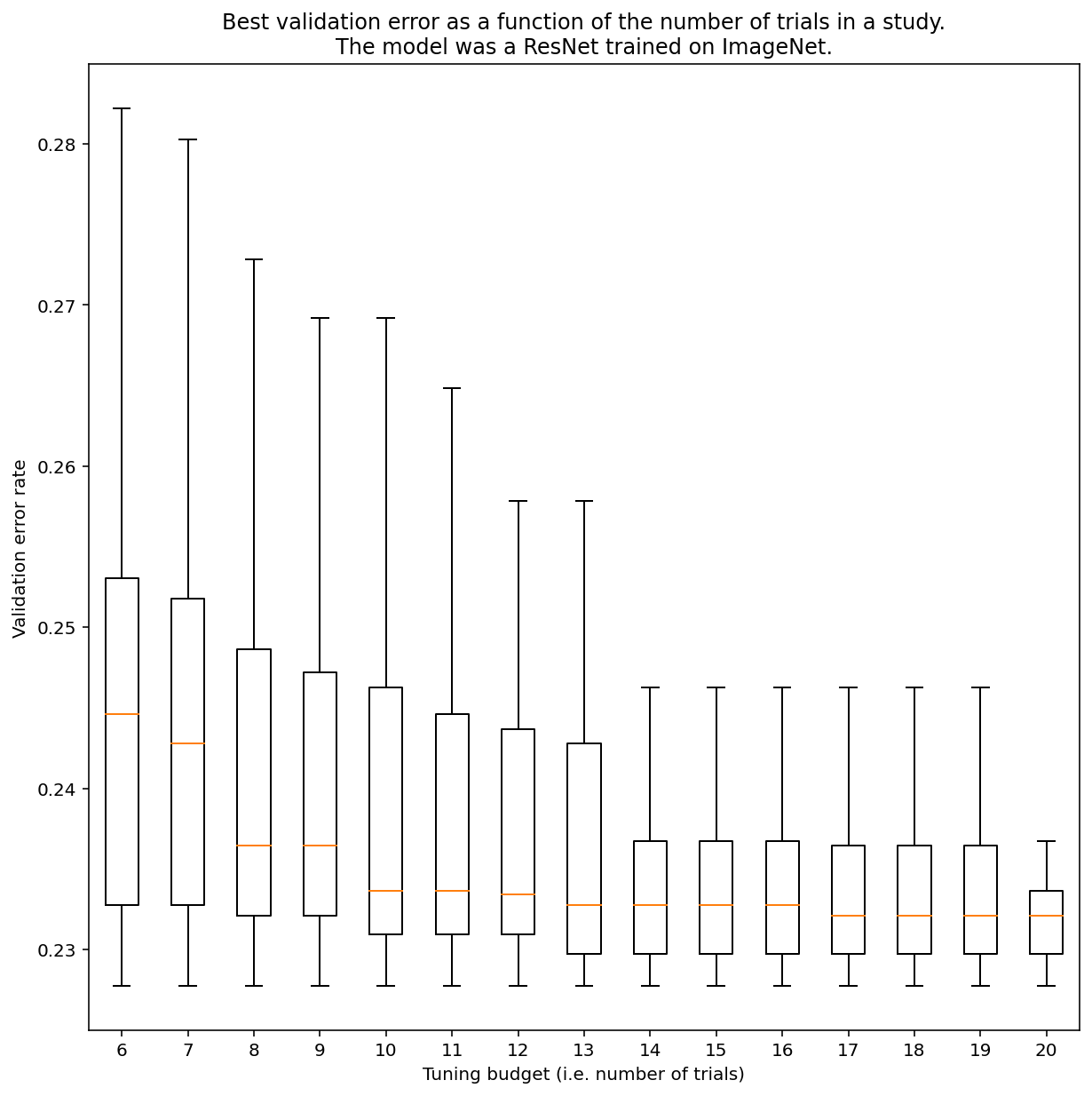
Hình 3: ResNet-50 được điều chỉnh trên ImageNet với 100 lần thử nghiệm. Bằng cách sử dụng tính năng tự khởi động, chúng tôi đã mô phỏng nhiều mức ngân sách điều chỉnh. Biểu đồ hộp về hiệu suất tốt nhất cho mỗi ngân sách thử nghiệm được lập biểu đồ.
Hãy lưu ý những điều sau đây về Hình 3:
- Phạm vi tứ phân vị khi lấy mẫu 6 thử nghiệm lớn hơn nhiều so với khi lấy mẫu 20 thử nghiệm.
- Ngay cả với 20 lần thử nghiệm, sự khác biệt giữa các nghiên cứu đặc biệt may mắn và không may mắn có thể lớn hơn sự khác biệt thông thường giữa các lần huấn luyện lại của mô hình này trên các hạt ngẫu nhiên khác nhau, với các tham số siêu dữ liệu cố định, đối với khối lượng công việc này có thể là khoảng +/- 0,1% với tỷ lệ lỗi xác thực là ~23%.
-
Ben Recht và Kevin Jamieson đã chỉ ra mức độ hiệu quả của phương pháp tìm kiếm ngẫu nhiên có ngân sách gấp đôi làm đường cơ sở (bài báo về Hyperband đưa ra các lập luận tương tự), nhưng chắc chắn có thể tìm thấy không gian tìm kiếm và các vấn đề mà các kỹ thuật tối ưu hoá Bayesian hiện đại sẽ đánh bại phương pháp tìm kiếm ngẫu nhiên có ngân sách gấp đôi. Tuy nhiên, theo kinh nghiệm của chúng tôi, việc đánh bại phương thức tìm kiếm ngẫu nhiên theo ngân sách gấp 2 lần sẽ khó khăn hơn nhiều trong chế độ song song cao vì phương pháp tối ưu hoá Bayesian không có cơ hội quan sát kết quả của các thử nghiệm trước đó. ↩