Im Zusammenhang mit diesem Dokument gilt:
Das ultimative Ziel der Entwicklung von Machine Learning ist es, den Nutzen des bereitgestellten Modells zu maximieren.
Die grundlegenden Schritte und Prinzipien in diesem Abschnitt können in der Regel für jedes ML-Problem verwendet werden.
In diesem Abschnitt wird von folgenden Annahmen ausgegangen:
- Sie haben bereits eine vollständig funktionierende Trainingspipeline mit einer Konfiguration, die ein angemessenes Ergebnis liefert.
- Sie haben genügend Rechenressourcen, um aussagekräftige Tuning-Tests durchzuführen und mindestens mehrere Trainingsjobs parallel auszuführen.
Die inkrementelle Optimierungsstrategie
Empfehlung: Beginnen Sie mit einer einfachen Konfiguration. Nehmen Sie dann schrittweise Verbesserungen vor, während Sie sich ein besseres Bild vom Problem machen. Achten Sie darauf, dass jede Verbesserung auf stichhaltigen Beweisen beruht.
Wir gehen davon aus, dass Sie eine Konfiguration finden möchten, mit der die Leistung Ihres Modells maximiert wird. Manchmal besteht Ihr Ziel darin, die Modellverbesserung bis zu einem bestimmten Termin zu maximieren. In anderen Fällen können Sie das Modell unbegrenzt weiter verbessern, z. B. ein Modell, das in der Produktion verwendet wird.
Grundsätzlich könnten Sie die Leistung maximieren, indem Sie einen Algorithmus verwenden, um den gesamten Raum möglicher Konfigurationen automatisch zu durchsuchen. Dies ist jedoch keine praktikable Option. Der Raum möglicher Konfigurationen ist extrem groß und es gibt noch keine Algorithmen, die ausgefeilt genug sind, um diesen Raum ohne menschliche Anleitung effizient zu durchsuchen. Die meisten automatisierten Suchalgorithmen basieren auf einem manuell entwickelten Suchbereich, der die Menge der zu durchsuchenden Konfigurationen definiert. Diese Suchbereiche können sehr wichtig sein.
Die effektivste Methode, die Leistung zu maximieren, besteht darin, mit einer einfachen Konfiguration zu beginnen und nach und nach Funktionen hinzuzufügen und Verbesserungen vorzunehmen, während Sie sich ein besseres Bild vom Problem machen.
Wir empfehlen, in jeder Optimierungsrunde automatisierte Suchalgorithmen zu verwenden und die Suchbereiche fortlaufend zu aktualisieren, wenn Sie mehr Informationen erhalten. Im Laufe der Zeit werden Sie immer bessere Konfigurationen finden und Ihr „bestes“ Modell wird sich kontinuierlich verbessern.
Der Begriff „Einführung“ bezieht sich auf eine Aktualisierung unserer besten Konfiguration (die möglicherweise nicht mit der tatsächlichen Einführung eines Produktionsmodells übereinstimmt). Bei jedem „Launch“ müssen Sie dafür sorgen, dass die Änderung auf fundierten Beweisen beruht und nicht nur auf dem Zufall einer glücklichen Konfiguration. So vermeiden Sie unnötige Komplexität in der Trainingspipeline.
Auf übergeordneter Ebene umfasst unsere Strategie zur inkrementellen Optimierung die Wiederholung der folgenden vier Schritte:
- Wählen Sie ein Ziel für die nächste Testrunde aus. Achten Sie darauf, dass das Ziel angemessen formuliert ist.
- Nächste Testrunde planen: Entwerfen und führen Sie eine Reihe von Tests durch, die auf dieses Ziel hinarbeiten.
- Aus den Testergebnissen lernen: Test anhand einer Checkliste auswerten
- Entscheiden, ob die vorgeschlagene Änderung übernommen werden soll:
Im Rest dieses Abschnitts wird diese Strategie näher beschrieben.
Ziel für die nächste Testrunde auswählen
Wenn Sie mehrere Funktionen hinzufügen oder mehrere Fragen gleichzeitig beantworten möchten, können Sie die einzelnen Auswirkungen auf die Ergebnisse möglicherweise nicht mehr nachvollziehen. Beispiele für Ziele:
- Probieren Sie eine mögliche Verbesserung der Pipeline aus, z. B. einen neuen Regularizer oder eine neue Vorverarbeitungsoption.
- Auswirkungen eines bestimmten Modell-Hyperparameters (z. B. der Aktivierungsfunktion) ermitteln
- Validierungsfehler minimieren
Langfristige Fortschritte wichtiger als kurzfristige Verbesserungen bei Validierungsfehlern
Zusammenfassung: In den meisten Fällen besteht Ihr primäres Ziel darin, Einblicke in das Optimierungsproblem zu erhalten.
Wir empfehlen, den Großteil Ihrer Zeit damit zu verbringen, das Problem zu analysieren, und vergleichsweise wenig Zeit damit, die Leistung im Validierungsset zu maximieren. Das bedeutet, dass Sie die meiste Zeit mit der „Exploration“ verbringen und nur einen kleinen Teil mit der „Exploitation“. Wenn Sie das Problem verstehen, können Sie die endgültige Leistung maximieren. Wenn Sie Statistiken gegenüber kurzfristigen Vorteilen priorisieren, können Sie:
- Vermeiden Sie es, unnötige Änderungen einzuführen, die nur zufällig in leistungsstarken Läufen vorhanden waren.
- Ermitteln Sie, auf welche Hyperparameter der Validierungsfehler am empfindlichsten reagiert, welche Hyperparameter am stärksten interagieren und daher gemeinsam neu abgestimmt werden müssen und welche Hyperparameter relativ unempfindlich gegenüber anderen Änderungen sind und daher in zukünftigen Tests festgelegt werden können.
- Vorschläge für potenzielle neue Funktionen, die Sie ausprobieren können, z. B. neue Regularisierungen, wenn Overfitting ein Problem ist.
- Funktionen identifizieren, die nicht hilfreich sind und daher entfernt werden können, um die Komplexität zukünftiger Tests zu verringern.
- Erkennen, wann die Verbesserungen durch die Hyperparameter-Abstimmung wahrscheinlich gesättigt sind.
- Wir können die Suchbereiche um den optimalen Wert eingrenzen, um die Effizienz der Abstimmung zu verbessern.
Irgendwann werden Sie das Problem verstehen. Anschließend können Sie sich ganz auf den Validierungsfehler konzentrieren, auch wenn die Tests nicht maximal informativ in Bezug auf die Struktur des Optimierungsproblems sind.
Nächste Testrunde planen
Zusammenfassung: Ermitteln Sie, welche Hyperparameter wissenschaftliche, Stör- und feste Hyperparameter für das experimentelle Ziel sind. Erstellen Sie eine Reihe von Studien, um verschiedene Werte der wissenschaftlichen Hyperparameter zu vergleichen und gleichzeitig die Störparameter zu optimieren. Wählen Sie den Suchbereich der Störparameter so aus, dass die Ressourcenkosten und der wissenschaftliche Wert im Gleichgewicht sind.
Wissenschaftliche, Stör- und feste Hyperparameter identifizieren
Für ein bestimmtes Ziel fallen alle Hyperparameter in eine der folgenden Kategorien:
- Wissenschaftliche Hyperparameter sind diejenigen, deren Auswirkungen auf die Leistung des Modells Sie messen möchten.
- Störparameter müssen optimiert werden, um verschiedene Werte der wissenschaftlichen Hyperparameter fair vergleichen zu können. Stör-Hyperparameter ähneln Störparametern in der Statistik.
- Feste Hyperparameter haben in der aktuellen Experimentierrunde konstante Werte. Die Werte von festen Hyperparametern sollten sich nicht ändern, wenn Sie verschiedene Werte von wissenschaftlichen Hyperparametern vergleichen. Wenn Sie bestimmte Hyperparameter für eine Reihe von Tests festlegen, müssen Sie akzeptieren, dass die aus den Tests abgeleiteten Schlussfolgerungen möglicherweise nicht für andere Einstellungen der festen Hyperparameter gelten. Mit anderen Worten: Feste Hyperparameter schränken die Schlussfolgerungen ein, die Sie aus den Tests ziehen können.
Angenommen, Ihr Ziel sieht so aus:
Ermitteln, ob ein Modell mit mehr verborgenen Schichten einen geringeren Validierungsfehler aufweist.
In diesem Fall gilt:
- Die Lernrate ist ein störender Hyperparameter, da Sie Modelle mit unterschiedlicher Anzahl verborgener Ebenen nur dann fair vergleichen können, wenn die Lernrate für jede Anzahl verborgener Ebenen separat optimiert wird. Die optimale Lernrate hängt im Allgemeinen von der Modellarchitektur ab.
- Die Aktivierungsfunktion kann ein fester Hyperparameter sein, wenn Sie in früheren Tests festgestellt haben, dass die beste Aktivierungsfunktion nicht von der Tiefe des Modells abhängt. Oder Sie sind bereit, Ihre Schlussfolgerungen zur Anzahl der verborgenen Ebenen zu begrenzen, um diese Aktivierungsfunktion abzudecken. Alternativ kann es sich um einen Störparameter handeln, wenn Sie bereit sind, ihn für jede Anzahl von verborgenen Ebenen separat zu optimieren.
Ein bestimmter Hyperparameter kann ein wissenschaftlicher Hyperparameter, ein Störparameter oder ein fester Hyperparameter sein. Die Bezeichnung des Hyperparameters ändert sich je nach experimentellem Ziel. Die Aktivierungsfunktion kann beispielsweise eine der folgenden sein:
- Wissenschaftlicher Hyperparameter: Ist ReLU oder tanh die bessere Wahl für unser Problem?
- Störparameter-Hyperparameter: Ist das beste Modell mit fünf Ebenen besser als das beste Modell mit sechs Ebenen, wenn mehrere verschiedene mögliche Aktivierungsfunktionen zulässig sind?
- Fester Hyperparameter: Hilft es bei ReLU-Netzwerken, an einer bestimmten Position die Batch-Normalisierung hinzuzufügen?
Beim Konzipieren einer neuen Testrunde:
- Identifizieren Sie die wissenschaftlichen Hyperparameter für das Testziel. In dieser Phase können alle anderen Hyperparameter als Störparameter betrachtet werden.
- Wandeln Sie einige Störparameter in feste Hyperparameter um.
Bei unbegrenzten Ressourcen würden Sie alle nicht wissenschaftlichen Hyperparameter als Störparameter belassen, damit die Schlussfolgerungen, die Sie aus Ihren Experimenten ziehen, nicht durch Einschränkungen aufgrund fester Hyperparameterwerte beeinträchtigt werden. Je mehr Störparameter Sie jedoch abstimmen möchten, desto größer ist das Risiko, dass Sie sie für jede Einstellung der wissenschaftlichen Hyperparameter nicht ausreichend abstimmen und am Ende die falschen Schlussfolgerungen aus Ihren Tests ziehen. Wie in einem späteren Abschnitt beschrieben, können Sie diesem Risiko entgegenwirken, indem Sie das Rechenbudget erhöhen. Ihr maximales Ressourcenbudget ist jedoch oft geringer als das, was für die Optimierung aller nicht wissenschaftlichen Hyperparameter erforderlich wäre.
Wir empfehlen, einen Störparameter in einen festen Hyperparameter zu konvertieren, wenn die Nachteile, die durch die Fixierung entstehen, weniger schwerwiegend sind als die Kosten, die durch die Einbeziehung als Störparameter entstehen. Je stärker ein Störparameter mit den wissenschaftlichen Hyperparametern interagiert, desto schädlicher ist es, seinen Wert zu korrigieren. Der beste Wert für die Stärke des Gewichtsverfalls hängt beispielsweise in der Regel von der Modellgröße ab. Daher wäre ein Vergleich verschiedener Modellgrößen unter Annahme eines einzelnen spezifischen Werts für den Gewichtsverfall nicht sehr aufschlussreich.
Einige Optimierungsparameter
Als Faustregel gilt, dass einige Hyperparameter des Optimierungstools (z.B. die Lernrate, das Momentum, die Parameter des Lernratenplans, die Adam-Betas usw.) Störhyperparameter sind, da sie am ehesten mit anderen Änderungen interagieren. Diese Optimizer-Hyperparameter sind selten wissenschaftliche Hyperparameter, da ein Ziel wie „Was ist die beste Lernrate für die aktuelle Pipeline?“ nicht viel Aufschluss gibt. Die beste Einstellung könnte sich mit der nächsten Pipeline-Änderung ohnehin ändern.
Möglicherweise müssen Sie einige Optimierer-Hyperparameter gelegentlich aufgrund von Ressourcenbeschränkungen oder besonders stichhaltigen Beweisen dafür korrigieren, dass sie nicht mit den wissenschaftlichen Parametern interagieren. Im Allgemeinen sollten Sie jedoch davon ausgehen, dass Sie die Hyperparameter des Optimierungstools separat abstimmen müssen, um faire Vergleiche zwischen verschiedenen Einstellungen der wissenschaftlichen Hyperparameter zu ermöglichen. Sie sollten daher nicht festgelegt werden. Außerdem gibt es keinen a priori-Grund, einen Hyperparameterwert für den Optimierer einem anderen vorzuziehen. Hyperparameterwerte für den Optimierer wirken sich in der Regel nicht auf die Rechenkosten von Forward Passes oder Gradienten aus.
Die Wahl des Optimierers
Die Auswahl des Optimierungstools ist in der Regel eine der folgenden:
- ein wissenschaftlicher Hyperparameter
- einem festen Hyperparameter
Ein Optimierer ist ein wissenschaftlicher Hyperparameter, wenn Ihr experimentelles Ziel darin besteht, faire Vergleiche zwischen zwei oder mehr verschiedenen Optimierern anzustellen. Beispiel:
Ermitteln Sie, welcher Optimierer in einer bestimmten Anzahl von Schritten den niedrigsten Validierungsfehler erzeugt.
Alternativ können Sie den Optimierer aus verschiedenen Gründen als festen Hyperparameter festlegen, z. B.:
- Frühere Tests haben ergeben, dass der beste Optimierer für Ihr Abstimmungsproblem nicht empfindlich gegenüber aktuellen wissenschaftlichen Hyperparametern ist.
- Sie möchten die Werte der wissenschaftlichen Hyperparameter lieber mit diesem Optimierer vergleichen, da seine Trainingskurven leichter nachzuvollziehen sind.
- Sie bevorzugen diesen Optimierer, weil er weniger Arbeitsspeicher als die Alternativen benötigt.
Regularisierungshyperparameter
Hyperparameter, die durch eine Regularisierungstechnik eingeführt werden, sind in der Regel Störhyperparameter. Die Entscheidung, ob die Regularisierungstechnik überhaupt einbezogen werden soll, ist jedoch entweder ein wissenschaftlicher oder ein fester Hyperparameter.
Die Dropout-Regularisierung erhöht beispielsweise die Komplexität des Codes. Wenn Sie entscheiden, ob Sie Dropout-Regularisierung einbeziehen möchten, könnten Sie „kein Dropout“ im Vergleich zu „Dropout“ als wissenschaftlichen Hyperparameter und die Dropout-Rate als Störparameter betrachten. Wenn Sie sich entscheiden, der Pipeline basierend auf diesem Test Dropout-Regularisierung hinzuzufügen, ist die Dropout-Rate in zukünftigen Tests ein Störparameter.
Architektur-Hyperparameter
Architektur-Hyperparameter sind oft wissenschaftliche oder feste Hyperparameter, da sich Änderungen an der Architektur auf die Kosten für die Bereitstellung und das Training, die Latenz und den Speicherbedarf auswirken können. Die Anzahl der Ebenen ist beispielsweise in der Regel ein wissenschaftlicher oder fester Hyperparameter, da sie sich erheblich auf die Trainingsgeschwindigkeit und die Speichernutzung auswirkt.
Abhängigkeiten von wissenschaftlichen Hyperparametern
In einigen Fällen hängen die Mengen der Stör- und festen Hyperparameter von den Werten der wissenschaftlichen Hyperparameter ab. Angenommen, Sie möchten herausfinden, welcher Optimierer in Nesterov-Momentum und Adam den niedrigsten Validierungsfehler erzeugt. In diesem Fall gilt:
- Der wissenschaftliche Hyperparameter ist der Optimierer, der die Werte
{"Nesterov_momentum", "Adam"}annimmt. - Mit dem Wert
optimizer="Nesterov_momentum"werden die Hyperparameter{learning_rate, momentum}eingeführt, die entweder Stör- oder feste Hyperparameter sein können. - Mit dem Wert
optimizer="Adam"werden die Hyperparameter{learning_rate, beta1, beta2, epsilon}eingeführt, die entweder Stör- oder feste Hyperparameter sein können.
Hyperparameter, die nur für bestimmte Werte der wissenschaftlichen Hyperparameter vorhanden sind, werden als bedingte Hyperparameter bezeichnet.
Gehen Sie nicht davon aus, dass zwei bedingte Hyperparameter identisch sind, nur weil sie denselben Namen haben. Im vorherigen Beispiel ist der bedingte Hyperparameter learning_rate ein anderer Hyperparameter für optimizer="Nesterov_momentum" als für optimizer="Adam". Die Rolle ist in den beiden Algorithmen ähnlich (aber nicht identisch), aber der Wertebereich, der in den einzelnen Optimierern gut funktioniert, unterscheidet sich in der Regel um mehrere Größenordnungen.
Studien erstellen
Nachdem Sie die wissenschaftlichen und Störparameter identifiziert haben, sollten Sie eine Studie oder eine Reihe von Studien entwerfen, um das experimentelle Ziel zu erreichen. In einer Studie wird eine Reihe von Hyperparameterkonfigurationen angegeben, die für die nachfolgende Analyse ausgeführt werden sollen. Jede Konfiguration wird als Testlauf bezeichnet. Beim Erstellen einer Studie müssen Sie in der Regel Folgendes auswählen:
- Die Hyperparameter, die sich zwischen den Tests unterscheiden.
- Die Werte, die diese Hyperparameter annehmen können (der Suchbereich).
- Die Anzahl der Tests.
- Ein automatisierter Suchalgorithmus, um so viele Testläufe aus dem Suchbereich zu ziehen.
Alternativ können Sie eine Studie erstellen, indem Sie die Menge der Hyperparameterkonfigurationen manuell angeben.
Die Studien haben folgende Ziele:
- Führen Sie die Pipeline mit verschiedenen Werten der wissenschaftlichen Hyperparameter aus.
- Die Störhyperparameter werden „wegoptimiert“ oder „überoptimiert“, damit Vergleiche zwischen verschiedenen Werten der wissenschaftlichen Hyperparameter so fair wie möglich sind.
Im einfachsten Fall erstellen Sie für jede Konfiguration der wissenschaftlichen Parameter eine separate Studie, in der jeweils die Störparameter-Hyperparameter optimiert werden. Wenn Sie beispielsweise den besten Optimierer aus Nesterov-Momentum und Adam auswählen möchten, können Sie zwei Studien erstellen:
- Eine Studie, in der
optimizer="Nesterov_momentum"und die Störparameter-Hyperparameter{learning_rate, momentum}sind. - Eine weitere Studie, in der
optimizer="Adam"und die Störparameter-Hyperparameter{learning_rate, beta1, beta2, epsilon}sind.
Sie vergleichen die beiden Optimierer, indem Sie den leistungsstärksten Testlauf aus jeder Studie auswählen.
Sie können einen beliebigen gradientenfreien Optimierungsalgorithmus verwenden, einschließlich Methoden wie der Bayes'schen Optimierung oder evolutionären Algorithmen, um die Störparameter zu optimieren. Wir bevorzugen jedoch die Verwendung der quasi-zufälligen Suche in der Explorationsphase der Optimierung, da sie in diesem Kontext eine Reihe von Vorteilen bietet. Nach Abschluss der explorativen Phase empfehlen wir, die modernste Software für die bayessche Optimierung zu verwenden (sofern verfügbar).
Stellen Sie sich einen komplizierteren Fall vor, in dem Sie eine große Anzahl von Werten der wissenschaftlichen Hyperparameter vergleichen möchten, es aber nicht praktikabel ist, so viele unabhängige Studien durchzuführen. In diesem Fall haben Sie folgende Möglichkeiten:
- Nehmen Sie die wissenschaftlichen Parameter in denselben Suchbereich wie die Störparameter auf.
- Verwenden Sie einen Suchalgorithmus, um Werte für die wissenschaftlichen und die Störparameter-Hyperparameter in einer einzigen Studie zu ermitteln.
Bei diesem Ansatz können bedingte Hyperparameter Probleme verursachen. Es ist schwierig, einen Suchbereich anzugeben, wenn die Menge der Störparameter nicht für alle Werte der wissenschaftlichen Hyperparameter gleich ist. In diesem Fall ist unsere Präferenz für die Verwendung der quasi-zufälligen Suche gegenüber ausgefeilteren Blackbox-Optimierungstools noch stärker, da sie garantiert, dass verschiedene Werte der wissenschaftlichen Hyperparameter gleichmäßig ausgewählt werden. Unabhängig vom Suchalgorithmus muss sichergestellt werden, dass die wissenschaftlichen Parameter einheitlich durchsucht werden.
Ausgewogenheit zwischen informativen und kostengünstigen Tests finden
Wenn Sie eine Studie oder eine Reihe von Studien planen, sollten Sie ein begrenztes Budget zuweisen, um die folgenden drei Ziele angemessen zu erreichen:
- Vergleich von genügend unterschiedlichen Werten der wissenschaftlichen Hyperparameter.
- Abstimmung der Störparameter-Hyperparameter über einen ausreichend großen Suchbereich.
- Der Suchbereich der Störparameter-Hyperparameter muss ausreichend dicht abgetastet werden.
Je besser Sie diese drei Ziele erreichen, desto mehr Erkenntnisse können Sie aus dem Test ziehen. Wenn Sie so viele Werte der wissenschaftlichen Hyperparameter wie möglich vergleichen, erweitern Sie den Umfang der Erkenntnisse, die Sie aus dem Test gewinnen.
Wenn Sie so viele Störhyperparameter wie möglich einbeziehen und jeder Störhyperparameter über einen möglichst großen Bereich variieren kann, steigt die Wahrscheinlichkeit, dass für jede Konfiguration der wissenschaftlichen Hyperparameter ein „guter“ Wert der Störhyperparameter im Suchbereich vorhanden ist. Andernfalls vergleichen Sie möglicherweise Werte der wissenschaftlichen Hyperparameter auf unfaire Weise, da Sie nicht nach möglichen Bereichen des Störparameter-Hyperparameterraums suchen, in denen für einige Werte der wissenschaftlichen Parameter bessere Werte liegen könnten.
Stichproben des Suchbereichs der Störparameter sollten so dicht wie möglich sein. Dadurch wird die Wahrscheinlichkeit erhöht, dass bei der Suche gute Einstellungen für die Störparameter gefunden werden, die in Ihrem Suchbereich vorhanden sind. Andernfalls könnten Sie unfaire Vergleiche zwischen den Werten der wissenschaftlichen Parameter anstellen, da einige Werte bei der Stichprobenerhebung der Störparameter Glück haben.
Leider erfordern Verbesserungen in einer dieser drei Dimensionen entweder das Folgende:
- Die Anzahl der Tests wird erhöht, was zu höheren Ressourcenkosten führt.
- Eine Möglichkeit finden, Ressourcen in einer der anderen Dimensionen zu sparen.
Jedes Problem hat seine eigenen Besonderheiten und Rechenbeschränkungen. Daher ist für die Zuweisung von Ressourcen für diese drei Ziele ein gewisses Maß an Fachwissen erforderlich. Nachdem Sie eine Studie ausgeführt haben, sollten Sie immer prüfen, ob die Störparameter ausreichend abgestimmt wurden. Das bedeutet, dass in der Studie ein ausreichend großer Raum ausreichend gründlich durchsucht wurde, um die wissenschaftlichen Hyperparameter fair zu vergleichen (wie im nächsten Abschnitt genauer beschrieben).
Aus den Testergebnissen lernen
Empfehlung: Versuchen Sie nicht nur, das ursprüngliche wissenschaftliche Ziel jeder Gruppe von Tests zu erreichen, sondern gehen Sie auch eine Checkliste mit zusätzlichen Fragen durch. Wenn Probleme auftreten, überarbeiten Sie die Tests und führen Sie sie noch einmal aus.
Jede Gruppe von Tests hat ein bestimmtes Ziel. Sie sollten die Ergebnisse der Tests im Hinblick auf dieses Ziel auswerten. Wenn Sie jedoch die richtigen Fragen stellen, können Sie oft Probleme finden, die behoben werden müssen, bevor eine bestimmte Reihe von Tests ihr ursprüngliches Ziel erreichen kann. Wenn Sie diese Fragen nicht stellen, ziehen Sie möglicherweise falsche Schlüsse.
Da Tests teuer sein können, sollten Sie auch andere nützliche Statistiken aus jeder Testgruppe ableiten, auch wenn diese nicht sofort für das aktuelle Ziel relevant sind.
Bevor Sie eine bestimmte Gruppe von Tests analysieren, um das ursprüngliche Ziel zu erreichen, sollten Sie sich die folgenden zusätzlichen Fragen stellen:
- Ist der Suchbereich groß genug? Wenn der optimale Punkt einer Studie in einer oder mehreren Dimensionen nahe der Grenze des Suchbereichs liegt, ist die Suche wahrscheinlich nicht breit genug. Führen Sie in diesem Fall eine weitere Studie mit einem erweiterten Suchbereich durch.
- Haben Sie genügend Punkte aus dem Suchbereich als Stichprobe genommen? Falls nicht, sollten Sie mehr Punkte ausführen oder die Optimierungsziele weniger ehrgeizig gestalten.
- Welcher Anteil der Tests in jeder Studie ist nicht durchführbar? Welche Testläufe weichen ab, weisen sehr schlechte Verlustwerte auf oder können gar nicht ausgeführt werden, weil sie gegen eine implizite Einschränkung verstoßen? Wenn ein sehr großer Teil der Punkte in einer Studie nicht realisierbar ist, passen Sie den Suchbereich an, um das Sampling solcher Punkte zu vermeiden. Dazu ist manchmal eine Reparametrisierung des Suchbereichs erforderlich. In einigen Fällen kann eine große Anzahl nicht realisierbarer Punkte auf einen Fehler im Trainingscode hinweisen.
- Gibt es Optimierungsprobleme beim Modell?
- Was können Sie aus den Trainingskurven der besten Testläufe lernen? Haben die besten Testläufe beispielsweise Trainingskurven, die auf ein problematisches Overfitting hindeuten?
Verfeinern Sie bei Bedarf anhand der Antworten auf die vorherigen Fragen die letzte Studie oder Gruppe von Studien, um den Suchraum zu verbessern und/oder mehr Tests durchzuführen oder andere Korrekturmaßnahmen zu ergreifen.
Nachdem Sie die vorherigen Fragen beantwortet haben, können Sie die durch die Tests gewonnenen Daten im Hinblick auf Ihr ursprüngliches Ziel auswerten, z. B. beurteilen, ob eine Änderung sinnvoll ist.
Falsche Suchbereichsgrenzen erkennen
Ein Suchbereich ist verdächtig, wenn der beste daraus abgerufene Punkt nahe an seiner Grenze liegt. Möglicherweise finden Sie einen noch besseren Punkt, wenn Sie den Suchbereich in dieser Richtung erweitern.
Um die Grenzen des Suchbereichs zu prüfen, empfehlen wir, abgeschlossene Tests in sogenannten Achsendiagrammen für grundlegende Hyperparameter darzustellen. Darin wird der Validierungszielwert im Vergleich zu einem der Hyperparameter (z. B. Lernrate) dargestellt. Jeder Punkt im Diagramm entspricht einem einzelnen Testlauf.
Der Validierungszielwert für jeden Testlauf sollte in der Regel der beste Wert sein, der im Laufe des Trainings erreicht wurde.
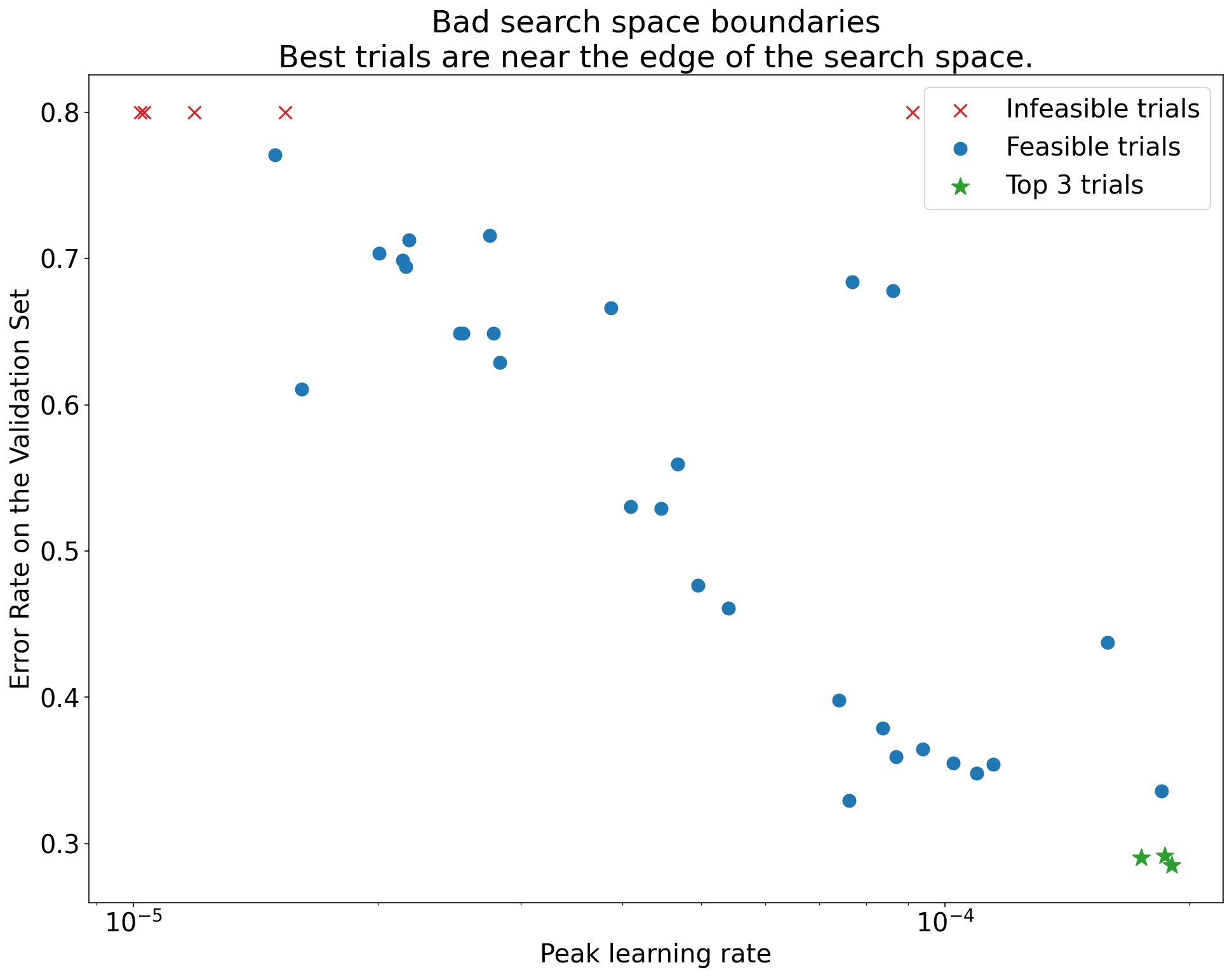
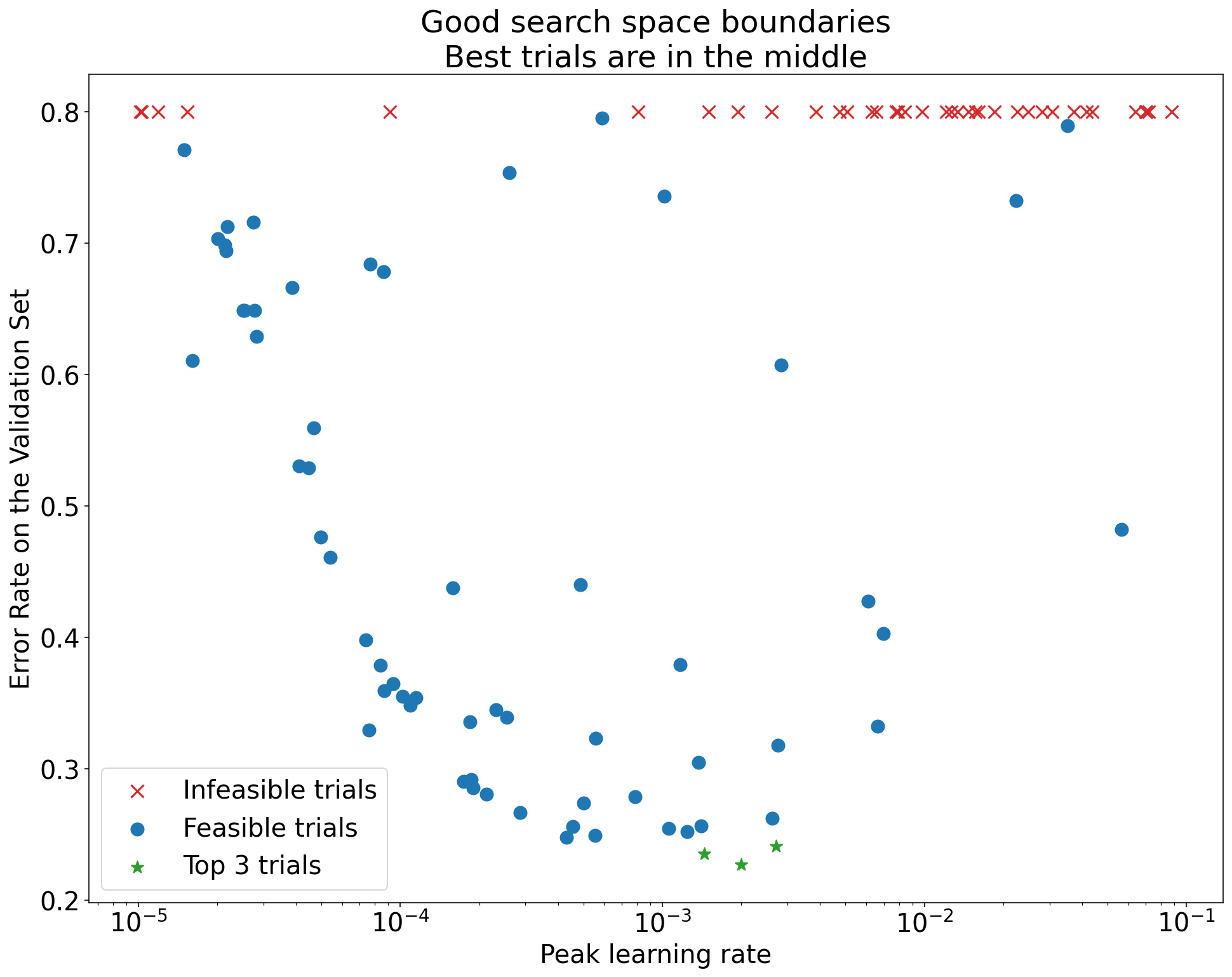
Abbildung 1:Beispiele für schlechte und akzeptable Suchbereichsgrenzen.
Die Diagramme in Abbildung 1 zeigen die Fehlerrate (niedriger ist besser) im Vergleich zur anfänglichen Lernrate. Wenn die besten Punkte in einer Dimension in Richtung des Rands eines Suchbereichs tendieren, müssen Sie die Grenzen des Suchbereichs möglicherweise erweitern, bis der beste beobachtete Punkt nicht mehr in der Nähe der Grenze liegt.
Häufig enthält eine Studie „nicht durchführbare“ Testläufe, die abweichen oder sehr schlechte Ergebnisse liefern (in Abbildung 1 mit roten Kreuzen gekennzeichnet). Wenn alle Tests für Lernraten über einem bestimmten Schwellenwert nicht durchführbar sind und die leistungsstärksten Tests Lernraten am Rand dieses Bereichs aufweisen, kann das Modell Stabilitätsprobleme haben, die den Zugriff auf höhere Lernraten verhindern.
Nicht genügend Punkte im Suchbereich werden berücksichtigt
Im Allgemeinen ist es sehr schwierig zu wissen, ob der Suchbereich ausreichend dicht abgetastet wurde. 🤖 Mehr Läufe sind besser als weniger, aber mehr Läufe verursachen offensichtlich zusätzliche Kosten.
Da es so schwierig ist, zu wissen, wann Sie genügend Stichproben genommen haben, empfehlen wir Folgendes:
- Proben, die Sie sich leisten können.
- Sie können Ihr intuitives Vertrauen kalibrieren, indem Sie sich wiederholt verschiedene Diagramme mit Hyperparameterachsen ansehen und versuchen, ein Gefühl dafür zu bekommen, wie viele Punkte sich im „guten“ Bereich des Suchraums befinden.
Trainingskurven untersuchen
Zusammenfassung: Die Verlustkurven sind ein guter Ausgangspunkt, um häufige Fehlermuster zu erkennen und potenzielle nächste Schritte zu priorisieren.
In vielen Fällen müssen Sie für das primäre Ziel Ihrer Tests nur den Validierungsfehler der einzelnen Testläufe berücksichtigen. Seien Sie jedoch vorsichtig, wenn Sie jeden Test auf eine einzelne Zahl reduzieren, da dadurch wichtige Details verborgen werden können. Wir empfehlen dringend, für jede Studie die Verlustkurven von mindestens den besten Versuchen zu betrachten. Auch wenn dies nicht erforderlich ist, um das primäre Ziel des A/B-Tests zu erreichen, ist es sinnvoll, die Verlustkurven (einschließlich Trainings- und Validierungsverlust) zu untersuchen, um häufige Fehler zu erkennen und die nächsten Schritte zu priorisieren.
Konzentrieren Sie sich bei der Analyse der Verlustkurven auf die folgenden Fragen:
Weisen einige der Tests ein problematisches Overfitting auf? Problematisches Overfitting tritt auf, wenn der Validierungsfehler während des Trainings zu steigen beginnt. In experimentellen Einstellungen, in denen Sie Störhyperparameter optimieren, indem Sie den „besten“ Test für jede Einstellung der wissenschaftlichen Hyperparameter auswählen, sollten Sie mindestens in jedem der besten Tests, die den Einstellungen der wissenschaftlichen Hyperparameter entsprechen, die Sie vergleichen, auf problematisches Overfitting prüfen. Wenn bei einem der besten Testläufe ein problematisches Overfitting auftritt, führen Sie einen oder beide der folgenden Schritte aus:
- Test mit zusätzlichen Regularisierungstechniken wiederholen
- Stimmen Sie die vorhandenen Regularisierungsparameter neu ab, bevor Sie die Werte der wissenschaftlichen Hyperparameter vergleichen. Dies gilt möglicherweise nicht, wenn die wissenschaftlichen Hyperparameter Regularisierungsparameter enthalten, da es dann nicht überraschend wäre, wenn Einstellungen mit geringer Stärke dieser Regularisierungsparameter zu problematischem Overfitting führen.
Eine Überanpassung lässt sich oft ganz einfach mit gängigen Regularisierungstechniken reduzieren, die nur wenig zusätzlichen Code oder zusätzliche Berechnungen erfordern (z. B. Dropout-Regularisierung, Label-Glättung, Gewichtsverfall). Daher ist es in der Regel ganz einfach, einen oder mehrere davon in die nächste Testrunde aufzunehmen. Wenn der wissenschaftliche Hyperparameter beispielsweise „Anzahl der verborgenen Ebenen“ ist und der beste Testlauf mit der größten Anzahl von verborgenen Ebenen problematische Überanpassung aufweist, empfehlen wir, es mit zusätzlicher Regularisierung noch einmal zu versuchen, anstatt sofort die kleinere Anzahl von verborgenen Ebenen auszuwählen.
Auch wenn bei keinem der „besten“ Tests ein problematisches Overfitting auftritt, kann es trotzdem ein Problem geben, wenn es bei einem der Tests auftritt. Durch die Auswahl des besten Testlaufs werden Konfigurationen mit problematischem Overfitting unterdrückt und Konfigurationen ohne Overfitting bevorzugt. Mit anderen Worten: Wenn Sie den besten Testlauf auswählen, werden Konfigurationen mit mehr Regularisierung bevorzugt. Alles, was das Training verschlechtert, kann jedoch als Regularisierung dienen, auch wenn das nicht beabsichtigt war. Wenn Sie beispielsweise eine kleinere Lernrate auswählen, kann das Training durch Einschränkung des Optimierungsprozesses regularisiert werden. Normalerweise möchten wir die Lernrate jedoch nicht auf diese Weise auswählen. Der „beste“ Testlauf für jede Einstellung der wissenschaftlichen Hyperparameter wird möglicherweise so ausgewählt, dass „schlechte“ Werte einiger wissenschaftlicher oder Störparameter bevorzugt werden.
Gibt es im späteren Verlauf des Trainings eine hohe Schritt-zu-Schritt-Varianz beim Trainings- oder Validierungsfehler? Wenn das der Fall ist, kann dies folgende Probleme verursachen:
- Sie können verschiedene Werte der wissenschaftlichen Hyperparameter vergleichen. Das liegt daran, dass jeder Testlauf zufällig mit einem „Glücksschritt“ oder einem „Unglücksschritt“ endet.
- Ihre Fähigkeit, das Ergebnis des besten Tests in der Produktion zu reproduzieren. Das liegt daran, dass das Produktionsmodell möglicherweise nicht mit demselben „glücklichen“ Schritt wie in der Studie endet.
Die wahrscheinlichsten Ursachen für Abweichungen zwischen den Schritten sind:
- Batch-Varianz aufgrund von zufälligen Stichproben von Beispielen aus dem Trainingssatz für jeden Batch.
- Kleine Validierungs-Datasets
- Verwendung einer zu hohen Lernrate gegen Ende des Trainings.
Mögliche Abhilfemaßnahmen:
- Die Batchgröße erhöhen.
- Mehr Validierungsdaten erhalten
- Verwendung des Lernratenverfalls.
- Polyak-Mittelwertbildung verwenden.
Verbessern sich die Testläufe am Ende des Trainings noch? Wenn ja, befinden Sie sich im „Compute-bound“-Regime und können die Anzahl der Trainingsschritte erhöhen oder den Lernratenplan ändern.
Hat sich die Leistung der Trainings- und Validierungs-Datasets lange vor dem letzten Trainingsschritt stabilisiert? Wenn das der Fall ist, befinden Sie sich im „nicht rechengebundenen“ Regime und können möglicherweise die Anzahl der Trainingsschritte verringern.
Neben dieser Liste können durch die Untersuchung der Verlustkurven viele zusätzliche Verhaltensweisen deutlich werden. Wenn beispielsweise der Trainingsverlust während des Trainings zunimmt, deutet das in der Regel auf einen Fehler in der Trainingspipeline hin.
Mithilfe von Isolationsdiagrammen feststellen, ob eine Änderung sinnvoll ist
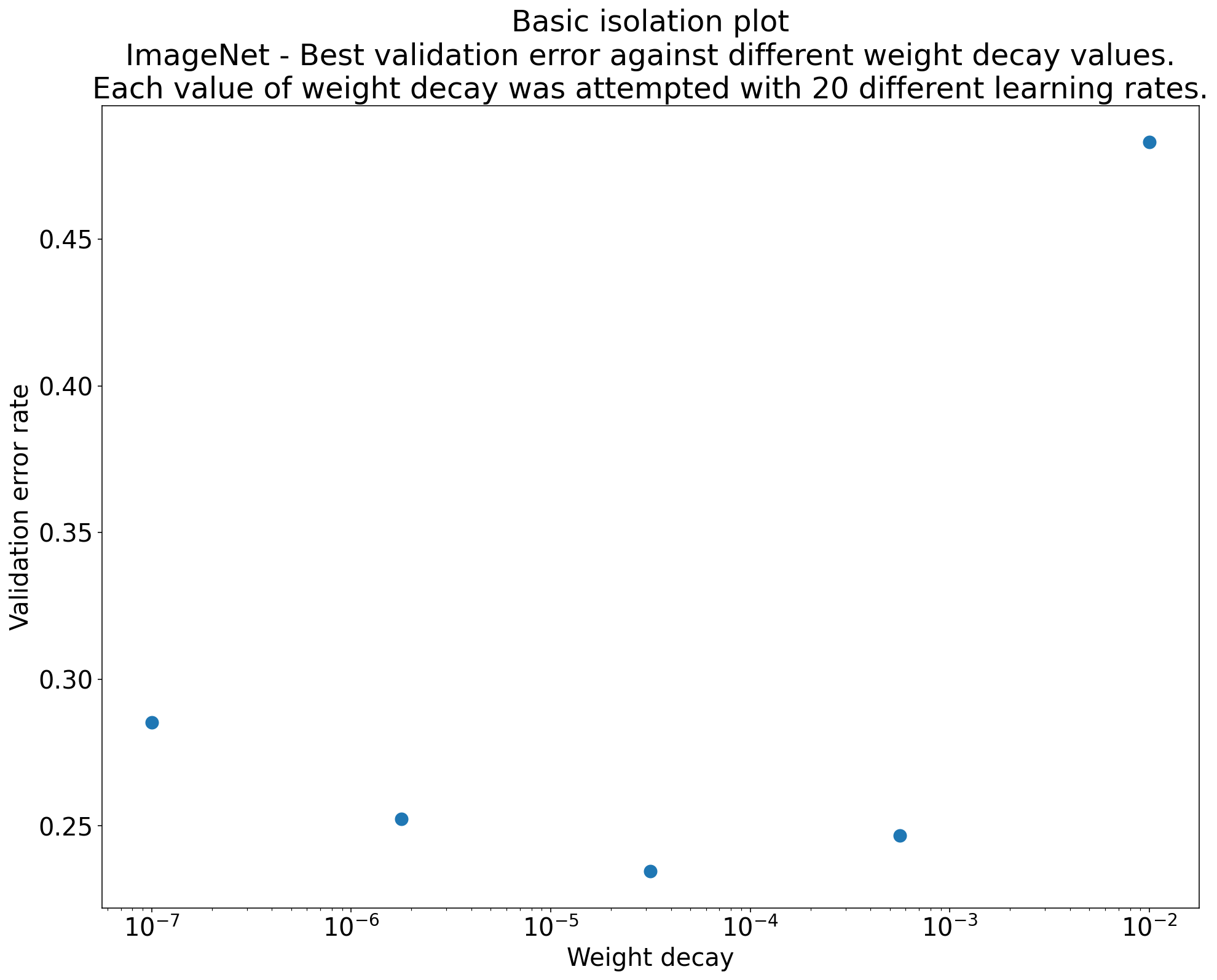
Abbildung 2:Isolationsdiagramm zur Ermittlung des optimalen Werts für den Gewichtsverfall für ResNet-50, das mit ImageNet trainiert wurde.
Häufig besteht das Ziel einer Reihe von Experimenten darin, verschiedene Werte eines wissenschaftlichen Hyperparameters zu vergleichen. Angenommen, Sie möchten den Wert für den Gewichtsverfall ermitteln, der zum besten Validierungsfehler führt. Ein Isolationsdiagramm ist ein Sonderfall des grundlegenden Diagramms für Hyperparameterachsen. Jeder Punkt in einem Isolationsdiagramm entspricht der Leistung des besten Versuchs für einige oder alle der Störparameter. Mit anderen Worten: Stellen Sie die Modellleistung dar, nachdem die Störparameter optimiert wurden.
Ein Isolationsdiagramm vereinfacht den direkten Vergleich verschiedener Werte des wissenschaftlichen Hyperparameters. Das Isolationsdiagramm in Abbildung 2 zeigt beispielsweise den Wert für den Gewichtsverfall, der die beste Validierungsleistung für eine bestimmte Konfiguration von ResNet-50 ergibt, die auf ImageNet trainiert wurde.
Wenn Sie feststellen möchten, ob überhaupt ein Gewichtungsabfall berücksichtigt werden soll, vergleichen Sie den besten Punkt aus diesem Diagramm mit der Baseline ohne Gewichtungsabfall. Für einen fairen Vergleich sollte die Lernrate der Baseline ebenfalls optimal abgestimmt sein.
Wenn Sie Daten haben, die durch (quasi)zufällige Suche generiert wurden, und einen kontinuierlichen Hyperparameter für ein Isolationsdiagramm in Betracht ziehen, können Sie das Isolationsdiagramm näherungsweise erstellen, indem Sie die X-Achsenwerte des grundlegenden Hyperparameter-Achsendiagramms in Klassen einteilen und den besten Test in jedem vertikalen Bereich, der durch die Klassen definiert wird, verwenden.
Allgemein nützliche Diagramme automatisieren
Je mehr Aufwand für die Erstellung von Diagrammen erforderlich ist, desto unwahrscheinlicher ist es, dass Sie sie so oft ansehen, wie Sie sollten. Wir empfehlen daher, Ihre Infrastruktur so einzurichten, dass automatisch so viele Diagramme wie möglich erstellt werden. Wir empfehlen, mindestens automatisch grundlegende Achsendiagramme für alle Hyperparameter zu erstellen, die Sie in einem Experiment variieren.
Außerdem empfehlen wir, automatisch Verlustkurven für alle Testläufe zu erstellen. Außerdem empfehlen wir, es so einfach wie möglich zu machen, die besten Versuche jeder Studie zu finden und ihre Verlustkurven zu untersuchen.
Sie können viele weitere nützliche potenzielle Diagramme und Visualisierungen hinzufügen. Geoffrey Hinton hat es so formuliert:
Jedes Mal, wenn Sie etwas Neues darstellen, lernen Sie etwas Neues.
Entscheiden, ob die vorgeschlagene Änderung übernommen werden soll
Zusammenfassung: Wenn Sie entscheiden, ob Sie Änderungen an unserem Modell oder Trainingsverfahren vornehmen oder eine neue Hyperparameterkonfiguration übernehmen, sollten Sie die verschiedenen Quellen für Abweichungen in Ihren Ergebnissen berücksichtigen.
Wenn Sie versuchen, ein Modell zu verbessern, kann es sein, dass eine bestimmte Änderung des Kandidatenmodells anfangs einen geringeren Validierungsfehler als die aktuelle Konfiguration aufweist. Bei einer Wiederholung des Tests kann es jedoch sein, dass kein konsistenter Vorteil festgestellt wird. Die wichtigsten Quellen für inkonsistente Ergebnisse lassen sich in die folgenden allgemeinen Kategorien einteilen:
- Varianz des Trainingsverfahrens, der erneuten Trainings oder der Tests: Die Variation zwischen Trainingsläufen, bei denen dieselben Hyperparameter, aber unterschiedliche zufällige Ausgangswerte verwendet werden. Beispiele für potenzielle Quellen für die Varianz von Testläufen sind unterschiedliche zufällige Initialisierungen, das Mischen von Trainingsdaten, Dropout-Masken, Muster von Datenaugmentierungsvorgängen und die Reihenfolge paralleler arithmetischer Operationen.
- Varianz der Hyperparameter-Suche oder Studienvarianz: Die Variation der Ergebnisse, die durch unser Verfahren zur Auswahl der Hyperparameter verursacht wird. Sie führen beispielsweise dasselbe Experiment mit einem bestimmten Suchbereich, aber mit zwei verschiedenen Seeds für die quasi-zufällige Suche aus und wählen am Ende unterschiedliche Hyperparameterwerte aus.
- Varianz bei Datenerhebung und Stichprobenziehung: Die Varianz, die durch eine zufällige Aufteilung in Trainings-, Validierungs- und Testdaten entsteht, oder die Varianz, die durch den Prozess zur Generierung von Trainingsdaten im Allgemeinen entsteht.
Ja, Sie können die auf einem endlichen Validierungsset geschätzten Validierungsfehlerraten mithilfe von sorgfältigen statistischen Tests vergleichen. Oft kann jedoch allein die Testvarianz statistisch signifikante Unterschiede zwischen zwei verschiedenen trainierten Modellen mit denselben Hyperparametereinstellungen verursachen.
Die Varianz von Studien ist vor allem dann ein Problem, wenn wir versuchen, Schlussfolgerungen zu ziehen, die über die Ebene eines einzelnen Punkts im Hyperparameterraum hinausgehen. Die Varianz der Studie hängt von der Anzahl der Tests und dem Suchbereich ab. Es gibt Fälle, in denen die Varianz der Studie größer als die der Testgruppe ist, und Fälle, in denen sie viel kleiner ist. Bevor Sie eine Änderung übernehmen, sollten Sie den besten Test N-mal ausführen, um die Varianz zwischen den Testläufen zu ermitteln. Normalerweise reicht es aus, die Testvarianz nach größeren Änderungen an der Pipeline neu zu charakterisieren. In einigen Fällen sind jedoch neuere Schätzungen erforderlich. In anderen Anwendungen ist die Charakterisierung der Testvarianz zu kostspielig.
Sie möchten zwar nur Änderungen (einschließlich neuer Hyperparameterkonfigurationen) übernehmen, die zu echten Verbesserungen führen, aber es ist auch nicht richtig, absolute Sicherheit zu verlangen, dass eine bestimmte Änderung hilft. Wenn ein neuer Hyperparameter-Punkt (oder eine andere Änderung) ein besseres Ergebnis als die Baseline erzielt (unter Berücksichtigung der Retrain-Varianz sowohl des neuen Punkts als auch der Baseline), sollten Sie ihn wahrscheinlich als neue Baseline für zukünftige Vergleiche übernehmen. Wir empfehlen jedoch, nur Änderungen vorzunehmen, die Verbesserungen bringen, die die zusätzliche Komplexität überwiegen.
Nach Abschluss der explorativen Analyse
Zusammenfassung: Tools für die Bayes'sche Optimierung sind eine gute Option, wenn Sie die Suche nach geeigneten Suchbereichen abgeschlossen und entschieden haben, welche Hyperparameter optimiert werden sollen.
Irgendwann werden Sie sich nicht mehr so sehr auf das Tuning-Problem konzentrieren, sondern eher auf die Erstellung einer einzelnen optimalen Konfiguration für den Start oder die anderweitige Verwendung. Zu diesem Zeitpunkt sollte ein verfeinerter Suchraum vorhanden sein, der die lokale Region um den besten beobachteten Testlauf umfasst und ausreichend abgetastet wurde. Bei der explorativen Analyse sollten Sie die wichtigsten Hyperparameter für die Optimierung und die entsprechenden Bereiche ermittelt haben. Diese können Sie verwenden, um einen Suchbereich für eine endgültige automatische Optimierungsstudie mit einem möglichst großen Optimierungsbudget zu erstellen.
Da Sie nicht mehr daran interessiert sind, die Erkenntnisse über das Optimierungsproblem zu maximieren, gelten viele Vorteile der quasi-zufälligen Suche nicht mehr. Daher sollten Sie Tools zur Bayes'schen Optimierung verwenden, um automatisch die beste Hyperparameterkonfiguration zu finden. Open-Source Vizier implementiert eine Vielzahl von ausgefeilten Algorithmen zum Optimieren von ML-Modellen, einschließlich Algorithmen für die bayessche Optimierung.
Angenommen, der Suchbereich enthält ein nicht triviales Volumen an abweichenden Punkten, d. h. Punkten, die einen NaN-Trainingsverlust oder sogar einen Trainingsverlust aufweisen, der um viele Standardabweichungen schlechter ist als der Mittelwert. In diesem Fall empfehlen wir die Verwendung von Blackbox-Optimierungstools, die Abweichungen bei Tests richtig berücksichtigen. Eine hervorragende Möglichkeit, dieses Problem zu beheben, finden Sie hier. Open-Source-Vizier unterstützt das Markieren von abweichenden Punkten, indem Versuche als nicht durchführbar markiert werden. Je nach Konfiguration wird jedoch möglicherweise nicht der von uns bevorzugte Ansatz aus Gelbart et al. verwendet.
Nach Abschluss der explorativen Datenanalyse sollten Sie die Leistung anhand des Test-Datasets prüfen. Grundsätzlich könnten Sie sogar den Validierungssatz in den Trainingssatz einfügen und die mit der bayesschen Optimierung gefundene beste Konfiguration neu trainieren. Dies ist jedoch nur dann sinnvoll, wenn es keine zukünftigen Launches mit dieser spezifischen Arbeitslast geben wird (z. B. bei einem einmaligen Kaggle-Wettbewerb).