このドキュメントでは、次の定義が使用されます。
機械学習開発の最終的な目標は、デプロイされたモデルの有用性を最大化することです。
通常、このセクションの基本的な手順と原則は、あらゆる ML 問題に適用できます。
このセクションでは、次のことを前提としています。
- すでに、妥当な結果が得られる構成とともに、完全に実行されているトレーニング パイプラインが存在する。
- 有意義なチューニング実験を実施し、少なくとも複数のトレーニング ジョブを並行して実行するのに十分なコンピューティング リソースがある。
増分チューニング戦略
推奨事項: シンプルな構成から始めます。次に、問題に関する洞察を深めながら、段階的に改善を行います。改善は確かな証拠に基づいて行うようにしてください。
ここでは、モデルのパフォーマンスを最大化する構成を見つけることを目標とします。場合によっては、固定の期限までにモデルの改善を最大化することが目標になります。それ以外の場合は、モデルを無期限に改善できます。たとえば、本番環境で使用されるモデルを継続的に改善します。
原則として、アルゴリズムを使用して可能な構成の全空間を自動的に検索することで、パフォーマンスを最大化できますが、これは実用的なオプションではありません。可能な構成の空間は非常に大きく、人間のガイダンスなしでこの空間を効率的に検索できるほど高度なアルゴリズムはまだありません。ほとんどの自動検索アルゴリズムは、検索する構成のセットを定義する手動設計の検索スペースに依存しており、これらの検索スペースは非常に重要です。
パフォーマンスを最大化する最も効果的な方法は、シンプルな構成から始めて、問題に関する分析情報を構築しながら、機能を段階的に追加して改善していくことです。
チューニングの各ラウンドで自動検索アルゴリズムを使用し、理解が深まるにつれて検索スペースを継続的に更新することをおすすめします。探索を進めるにつれて、より優れた構成が自然に見つかるため、「最適な」モデルは継続的に改善されます。
「リリース」とは、最適な構成の更新を指します(本番環境モデルの実際のリリースに対応する場合としない場合があります)。各「リリース」では、変更が強力な証拠に基づいていることを確認する必要があります。幸運な構成に基づくランダムなチャンスだけでは、トレーニング パイプラインに不要な複雑さを加えることになります。
大まかに言うと、増分チューニング戦略では、次の 4 つのステップを繰り返します。
- 次のテストの目標を選択します。 目標の範囲が適切であることを確認します。
- 次のテストを設計します。 この目標に向けて進む一連のテストを設計して実施します。
- テスト結果から学びます。チェックリストに沿ってテストを評価します。
- 候補の変更を採用するかどうかを判断します。
このセクションの残りの部分では、この戦略について詳しく説明します。
次のテストの目標を選択する
複数の特徴を追加したり、複数の質問に一度に回答したりすると、結果に対する個々の影響を分離できないことがあります。目標の例を以下に示します。
- パイプラインの改善案(新しい正則化、前処理の選択など)を試します。
- 特定のモデル ハイパーパラメータ(アクティベーション関数など)の影響を理解する
- 検証エラーを最小限に抑えます。
短期的な検証エラーの改善よりも長期的な進捗を優先する
概要: ほとんどの場合、主な目標はチューニングの問題に関する分析情報を取得することです。
時間の大部分を問題の分析に費やし、検証セットのパフォーマンスの最大化に貪欲に集中する時間は比較的少なくすることをおすすめします。つまり、時間のほとんどを「探索」に費やし、「活用」にはわずかな時間しか費やさないということです。最終的なパフォーマンスを最大限に高めるには、問題を理解することが重要です。短期的な利益よりも分析情報を優先することで、次のことが可能になります。
- パフォーマンスの高い実行にたまたま存在していた不要な変更を、過去の偶然によってリリースすることを避けます。
- 検証エラーが最も影響を受けるハイパーパラメータ、最も相互作用するハイパーパラメータ(そのため、一緒に再チューニングする必要がある)、他の変更に対して比較的影響を受けないハイパーパラメータ(そのため、将来のテストで固定できる)を特定します。
- 過適合が問題になっている場合は、新しい正則化項など、試してみるべき新しい機能を提案します。
- 役に立たないため削除できる特徴を特定し、今後のテストの複雑さを軽減します。
- ハイパーパラメータ チューニングによる改善が飽和状態になった可能性が高い場合を認識する。
- 最適な値の周辺で検索空間を絞り込み、チューニング効率を向上させます。
最終的には、問題が理解できるようになります。これにより、チューニング問題の構造に関する情報が実験から十分に得られなくても、検証エラーにのみ集中できます。
次のテストを設計する
概要: 実験の目標に対して、どのハイパーパラメータが科学的ハイパーパラメータ、ノイズ ハイパーパラメータ、固定ハイパーパラメータであるかを特定します。一連のスタディを作成して、科学的ハイパーパラメータのさまざまな値を比較しながら、ノイズ ハイパーパラメータを最適化します。リソース費用と科学的価値のバランスを取るために、不要なハイパーパラメータの検索空間を選択します。
科学的ハイパーパラメータ、迷惑ハイパーパラメータ、固定ハイパーパラメータを特定する
特定の目標に対して、すべてのハイパーパラメータは次のいずれかのカテゴリに分類されます。
- 科学的ハイパーパラメータとは、モデルのパフォーマンスに対する効果を測定しようとしているハイパーパラメータです。
- ノイズ ハイパーパラメータは、科学的ハイパーパラメータのさまざまな値を公平に比較するために最適化する必要があるハイパーパラメータです。不要なハイパーパラメータは、統計の不要なパラメータに似ています。
- 固定ハイパーパラメータは、現在の実験ラウンドで一定の値になります。科学的ハイパーパラメータの異なる値を比較するときに、固定ハイパーパラメータの値が変更されないようにする必要があります。一連のテストで特定のハイパーパラメータを固定すると、テストから得られた結論が、固定されたハイパーパラメータの他の設定では有効でない可能性があることを受け入れる必要があります。つまり、ハイパーパラメータを固定すると、テストから得られる結論に注意が必要になります。
たとえば、次のような目標を設定したとします。
隠れ層が多いモデルの検証エラーが少ないかどうかを判断します。
この例の場合は、次のようになります。
- 学習率は、隠しレイヤの数ごとに学習率を個別に調整した場合にのみ、隠しレイヤの数が異なるモデルを公平に比較できるため、厄介なハイパーパラメータです。(最適な学習率は通常、モデル アーキテクチャによって異なります)。
- 最適な活性化関数がモデルの深さに影響しないことが以前のテストで判明している場合は、活性化関数を固定ハイパーパラメータにできます。または、この活性化関数をカバーするために、隠れ層の数に関する結論を制限しても構いません。または、隠れレイヤの数ごとに個別に調整する準備ができている場合は、迷惑なハイパーパラメータになる可能性があります。
特定のハイパーパラメータは、科学的ハイパーパラメータ、ノイズ ハイパーパラメータ、固定ハイパーパラメータのいずれかになります。ハイパーパラメータの指定は、実験の目標によって異なります。たとえば、活性化関数は次のいずれかになります。
- 科学的なハイパーパラメータ: 問題に適しているのは ReLU と tanh のどちらですか?
- 不要なハイパーパラメータ: 複数の異なる活性化関数を使用する場合、最適な 5 層モデルは最適な 6 層モデルよりも優れていますか?
- 固定ハイパーパラメータ: ReLU ネットの場合、特定の場所にバッチ正規化を追加すると役立ちますか?
新しいテストラウンドを設計する際は、次の点に注意してください。
- テスト目標の科学的ハイパーパラメータを特定します。(この段階では、他のすべてのハイパーパラメータをノイズ ハイパーパラメータと見なすことができます)。
- 一部の不要なハイパーパラメータを固定ハイパーパラメータに変換します。
リソースに制限がない場合は、科学的でないハイパーパラメータをすべて nuisance ハイパーパラメータとして残し、実験から得られた結論が固定ハイパーパラメータ値に関する注意書きの影響を受けないようにします。ただし、調整しようとするノイズ ハイパーパラメータが多いほど、科学的ハイパーパラメータの各設定に対して十分に調整できず、実験から誤った結論に達するリスクが高くなります。後述のセクションで説明するように、計算予算を増やすことでこのリスクを軽減できます。ただし、リソース予算の上限は、科学的でないすべてのハイパーパラメータを調整するために必要な量よりも少ないことがよくあります。
固定ハイパーパラメータに変換することで生じる注意点が、それをノイズ ハイパーパラメータとして含めるコストよりも負担が少ない場合は、ノイズ ハイパーパラメータを固定ハイパーパラメータに変換することをおすすめします。ノイズ ハイパーパラメータが科学的ハイパーパラメータと相互作用するほど、その値を修正する際の悪影響が大きくなります。たとえば、重み減衰の強度の最適な値は通常、モデルサイズによって異なるため、重み減衰の特定の単一の値を想定して異なるモデルサイズを比較しても、あまり有益な結果は得られません。
一部のオプティマイザー パラメータ
経験則として、一部のオプティマイザー ハイパーパラメータ(学習率、モーメンタム、学習率スケジュールのパラメータ、Adam ベータなど)は、他の変更と最も相互作用する傾向があるため、迷惑なハイパーパラメータです。「現在のパイプラインに最適な学習率は何か」のような目標では、あまり有益な情報が得られないため、これらのオプティマイザー ハイパーパラメータは科学的なハイパーパラメータになることはほとんどありません。結局のところ、最適な設定は次のパイプラインの変更で変わる可能性があります。
リソースの制約や、オプティマイザーのハイパーパラメータが科学的パラメータと相互作用しないという特に強い証拠があるため、オプティマイザーのハイパーパラメータを固定することがあります。ただし、一般的には、科学的ハイパーパラメータの異なる設定を公平に比較するために、オプティマイザーのハイパーパラメータを個別に調整する必要があるため、固定しないことを前提としてください。さらに、あるオプティマイザー ハイパーパラメータ値を別の値よりも優先する理由はありません。たとえば、オプティマイザー ハイパーパラメータ値は通常、フォワード パスやグラデーションの計算コストに影響しません。
オプティマイザーの選択
通常、オプティマイザーの選択は次のいずれかになります。
- 科学的なハイパーパラメータ
- 固定ハイパーパラメータ
テストの目標が 2 つ以上の異なるオプティマイザーを公平に比較することである場合、オプティマイザーは科学的ハイパーパラメータです。次に例を示します。
指定されたステップ数で検証エラーが最も小さくなるオプティマイザーを特定します。
また、次のようなさまざまな理由で、オプティマイザーを固定ハイパーパラメータにすることもできます。
- 以前のテストでは、チューニング問題に最適なオプティマイザーは現在の科学的ハイパーパラメータに依存しないことが示されています。
- このオプティマイザーのトレーニング曲線は推論が容易であるため、このオプティマイザーを使用して科学的ハイパーパラメータの値を比較することをおすすめします。
- このオプティマイザーは、他のオプティマイザーよりもメモリ使用量が少ないため、このオプティマイザーを使用します。
正則化ハイパーパラメータ
正則化手法で導入されたハイパーパラメータは、通常、不要なハイパーパラメータです。ただし、正則化手法をまったく含めるかどうかは、科学的ハイパーパラメータまたは固定ハイパーパラメータです。
たとえば、ドロップアウト正則化はコードの複雑さを増します。したがって、ドロップアウト正則化を含めるかどうかを決定する際に、「ドロップアウトなし」と「ドロップアウトあり」を科学的ハイパーパラメータとし、ドロップアウト率をノイズ ハイパーパラメータにすることができます。このテストに基づいてパイプラインにドロップアウト正則化を追加する場合、ドロップアウト率は今後のテストで厄介なハイパーパラメータになります。
アーキテクチャ ハイパーパラメータ
アーキテクチャの変更は、サービングとトレーニングの費用、レイテンシ、メモリ要件に影響する可能性があるため、アーキテクチャのハイパーパラメータは科学的または固定のハイパーパラメータであることがよくあります。たとえば、レイヤ数は通常、トレーニング速度とメモリ使用量に大きな影響を与えるため、科学的または固定のハイパーパラメータになります。
科学的ハイパーパラメータへの依存関係
場合によっては、ノイズ ハイパーパラメータと固定ハイパーパラメータのセットは、科学的ハイパーパラメータの値に依存します。たとえば、Nesterov モメンタムと Adam のどちらのオプティマイザーが検証エラーを最小限に抑えるかを判断しようとしているとします。この例の場合は、次のようになります。
- 科学的ハイパーパラメータはオプティマイザーで、値
{"Nesterov_momentum", "Adam"}を取ります。 - 値
optimizer="Nesterov_momentum"は、{learning_rate, momentum}ハイパーパラメータを導入します。これは、迷惑なハイパーパラメータまたは固定ハイパーパラメータのいずれかです。 - 値
optimizer="Adam"は、{learning_rate, beta1, beta2, epsilon}(迷惑なハイパーパラメータまたは固定ハイパーパラメータのいずれか)というハイパーパラメータを導入します。
科学的ハイパーパラメータの特定の値に対してのみ存在するハイパーパラメータは、条件付きハイパーパラメータと呼ばれます。名前が同じだからといって、2 つの条件付きハイパーパラメータが同じであると想定しないでください。前の例では、learning_rate という条件付きハイパーパラメータは、optimizer="Nesterov_momentum" と optimizer="Adam" で異なるハイパーパラメータです。その役割は 2 つのアルゴリズムで似ていますが(同一ではありません)、各オプティマイザーでうまく機能する値の範囲は、通常、数桁異なります。
スタディのセットを作成する
科学的ハイパーパラメータとノイズ ハイパーパラメータを特定したら、実験目標に向けて進捗を上げるためのスタディまたは一連のスタディを設計する必要があります。スタディでは、後続の分析で実行するハイパーパラメータ構成のセットを指定します。各構成はトライアルと呼ばれます。通常、スタディの作成では次の項目を選択します。
- トライアル間で変化するハイパーパラメータ。
- ハイパーパラメータが取りうる値(検索スペース)。
- トライアルの数。
- 検索空間から多くのトライアルをサンプリングする自動検索アルゴリズム。
または、ハイパーパラメータ構成のセットを手動で指定して、スタディを作成することもできます。
この調査の目的は、次のことを同時に行うことです。
- 科学的ハイパーパラメータのさまざまな値を使用してパイプラインを実行します。
- 科学的ハイパーパラメータの異なる値間の比較が可能な限り公平になるように、不要なハイパーパラメータを「最適化」します。
最も簡単なケースでは、科学的パラメータの構成ごとに個別のスタディを作成し、各スタディで nuisance ハイパーパラメータを調整します。たとえば、Nesterov モメンタムと Adam のうち最適なオプティマイザーを選択することが目標である場合は、次の 2 つのスタディを作成できます。
optimizer="Nesterov_momentum"とノイズ ハイパーパラメータが{learning_rate, momentum}である 1 つのスタディoptimizer="Adam"とノイズ ハイパーパラメータが{learning_rate, beta1, beta2, epsilon}である別のスタディ。
各スタディからパフォーマンスが最も高いトライアルを選択して、2 つのオプティマイザーを比較します。
ベイズ最適化や進化アルゴリズムなどの方法を含む、勾配なしの最適化アルゴリズムを使用して、不要なハイパーパラメータを最適化できます。ただし、この設定では準ランダム検索にさまざまな利点があるため、チューニングの探索フェーズでは準ランダム検索を使用することをおすすめします。探索が完了したら、最先端のベイズ最適化ソフトウェア(利用可能な場合)を使用することをおすすめします。
科学的ハイパーパラメータの多数の値を比較したいが、それほど多くの独立した研究を行うのは現実的ではないという、より複雑なケースを考えてみましょう。この場合は、次の操作を行います。
- 科学的パラメータを、ノイズ ハイパーパラメータと同じ探索空間に含めます。
- 検索アルゴリズムを使用して、1 つのスタディで科学的ハイパーパラメータとノイズ ハイパーパラメータの両方の値をサンプリングします。
このアプローチでは、条件付きハイパーパラメータが問題を引き起こす可能性があります。結局のところ、科学的ハイパーパラメータのすべての値に対して、不要なハイパーパラメータのセットが同じでない限り、探索空間を指定することは困難です。この場合、準ランダム検索を使用する方が、より高度なブラックボックス最適化ツールを使用するよりも望ましいです。準ランダム検索では、科学的ハイパーパラメータのさまざまな値が均一にサンプリングされることが保証されるためです。検索アルゴリズムに関係なく、科学的パラメータを均一に検索するようにしてください。
有益で手頃なテストのバランスを取る
スタディまたは一連のスタディを設計する際は、次の 3 つの目標を十分に達成できるように、限られた予算を割り当てます。
- 科学的ハイパーパラメータのさまざまな値を十分に比較する。
- 十分に大きな検索空間で、不要なハイパーパラメータをチューニングします。
- 十分な密度でノイズ ハイパーパラメータの検索空間をサンプリングする。
これらの 3 つの目標を達成できればできるほど、テストからより多くの分析情報を抽出できます。科学的ハイパーパラメータの値をできるだけ多く比較することで、テストから得られる分析情報の範囲が広がります。
できるだけ多くのノイズ ハイパーパラメータを含め、各ノイズ ハイパーパラメータをできるだけ広い範囲で変化させることで、科学的ハイパーパラメータの各構成の検索スペースにノイズ ハイパーパラメータの「適切な」値が存在するという信頼性が高まります。そうしないと、科学的パラメータの特定の値に対してより良い値が存在する可能性のある、ノイズ ハイパーパラメータ空間の領域を検索しないことで、科学的ハイパーパラメータの値間で不公平な比較が行われる可能性があります。
可能な限り密に、不要なハイパーパラメータの検索空間をサンプリングします。これにより、検索スペースに存在するノイズ ハイパーパラメータの適切な設定が検索手順で見つかる可能性が高まります。そうしないと、一部の値がノイズ ハイパーパラメータのサンプリングで幸運になるため、科学的パラメータの値の間に不公平な比較が生じる可能性があります。
残念ながら、これら 3 つのディメンションのいずれかを改善するには、次のいずれかが必要です。
- 試行回数を増やし、リソース費用を増やします。
- 他のディメンションのいずれかでリソースを節約する方法を見つける。
問題にはそれぞれ固有の特性と計算上の制約があるため、これらの 3 つの目標にリソースを割り当てるには、ある程度のドメイン知識が必要です。スタディを実行したら、常にスタディで十分なほどに不要なハイパーパラメータが調整されたかどうかを確認してください。つまり、この研究では、科学的ハイパーパラメータを公平に比較するのに十分な広さの空間を十分に検索しました(詳細については、次のセクションで説明します)。
テスト結果から学ぶ
推奨事項: 各実験グループの元の科学的目標を達成しようとするだけでなく、追加の質問のチェックリストを確認します。問題が見つかった場合は、テストを修正して再実行します。
最終的に、各テストグループには特定の目標があります。テストで得られた証拠を評価して、その目標を達成できるかどうかを判断する必要があります。ただし、適切な質問をすることで、一連のテストが本来の目標に向かって進む前に修正すべき問題を見つけることができます。これらの質問をしないと、誤った結論を導き出す可能性があります。
テストの実施には費用がかかるため、現在の目標に直接関係しない場合でも、テストの各グループから他の有用な分析情報を抽出する必要があります。
一連のテストを分析して元の目標を達成する前に、次の質問を自問します。
- 検索スペースは十分に大きいか?スタディの最適点が 1 つ以上のディメンションの検索空間の境界に近い場合、検索範囲が十分でない可能性があります。この場合は、検索スペースを拡大して別のスタディを実行します。
- 検索空間から十分な数のポイントをサンプリングしましたか?そうでない場合は、ポイントを増やすか、チューニング目標の野心を抑えます。
- 各スタディで実行不可能なトライアルの割合はどのくらいですか?つまり、どのトライアルが発散し、損失値が非常に大きくなるか、暗黙的な制約に違反して実行に失敗するかを特定します。スタディ内のポイントの大部分が実行不可能な場合は、そのようなポイントのサンプリングを回避するように検索スペースを調整します。これには、検索スペースの再パラメータ化が必要になることがあります。実行不可能なポイントが多数ある場合は、トレーニング コードにバグがある可能性があります。
- モデルに最適化の問題がありますか?
- 最適なトライアルのトレーニング曲線から何を学べますか?たとえば、最適なトライアルのトレーニング曲線は、問題のある過剰適合と一致していますか?
必要に応じて、前の質問の回答に基づいて、最新の研究または研究グループを絞り込み、検索スペースを改善したり、より多くのトライアルをサンプリングしたり、その他の修正措置を講じたりします。
上記の質問に回答したら、テストで得られた結果を元の目標に照らして評価します。たとえば、変更が有効かどうかを評価します。
不正な検索スペースの境界を特定する
検索スペースからサンプリングされた最適なポイントが境界に近い場合、その検索スペースは疑わしいと見なされます。その方向に検索範囲を広げると、さらに良いポイントが見つかる可能性があります。
探索空間の境界を確認するには、完了したトライアルを基本的なハイパーパラメータ軸プロットにプロットすることをおすすめします。これらのグラフでは、検証の目的値とハイパーパラメータ(学習率など)の 1 つをプロットします。プロット上の各点は、1 つのトライアルに対応しています。
通常、各トライアルの検証目標値は、トレーニング中に達成された最良の値になります。
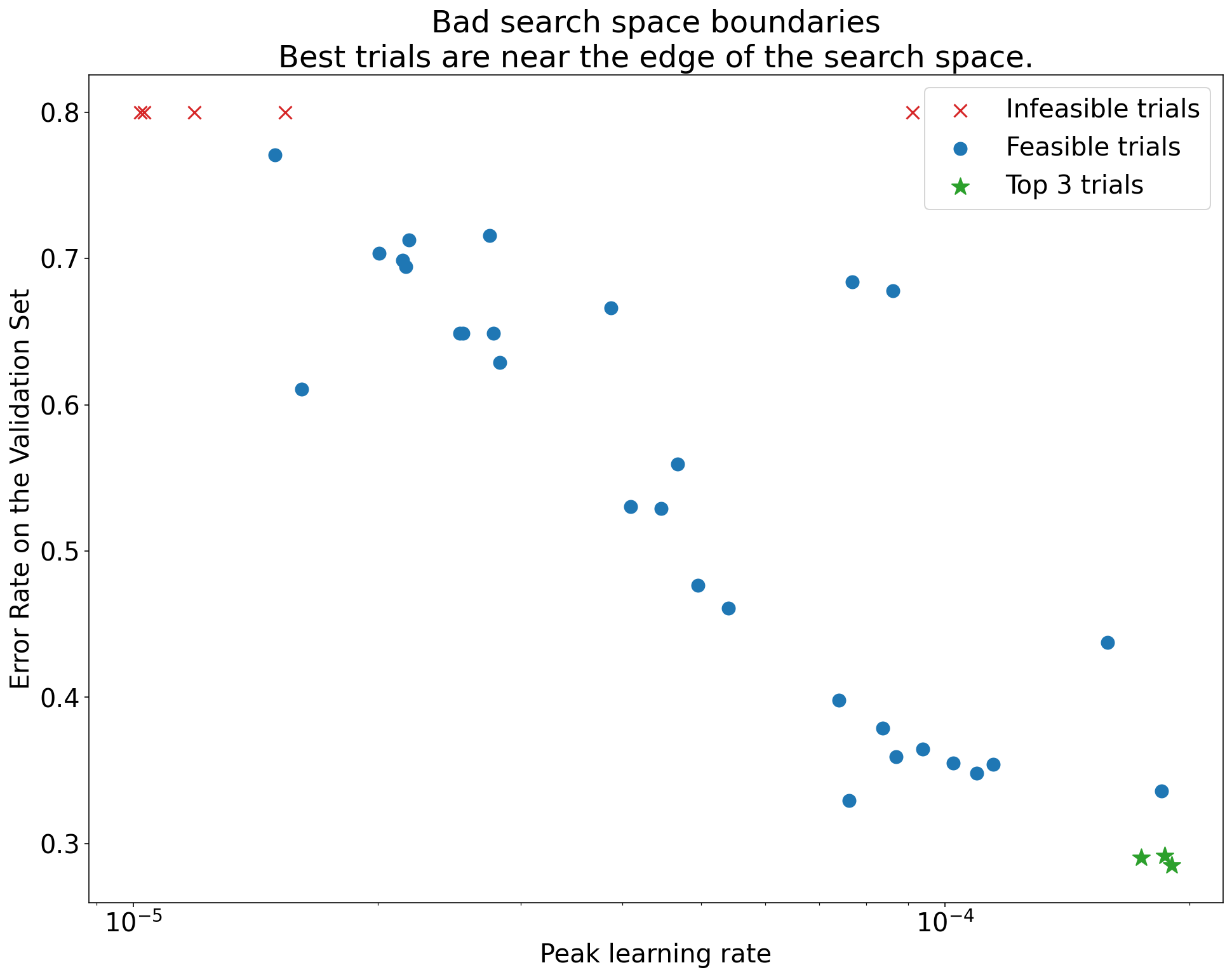
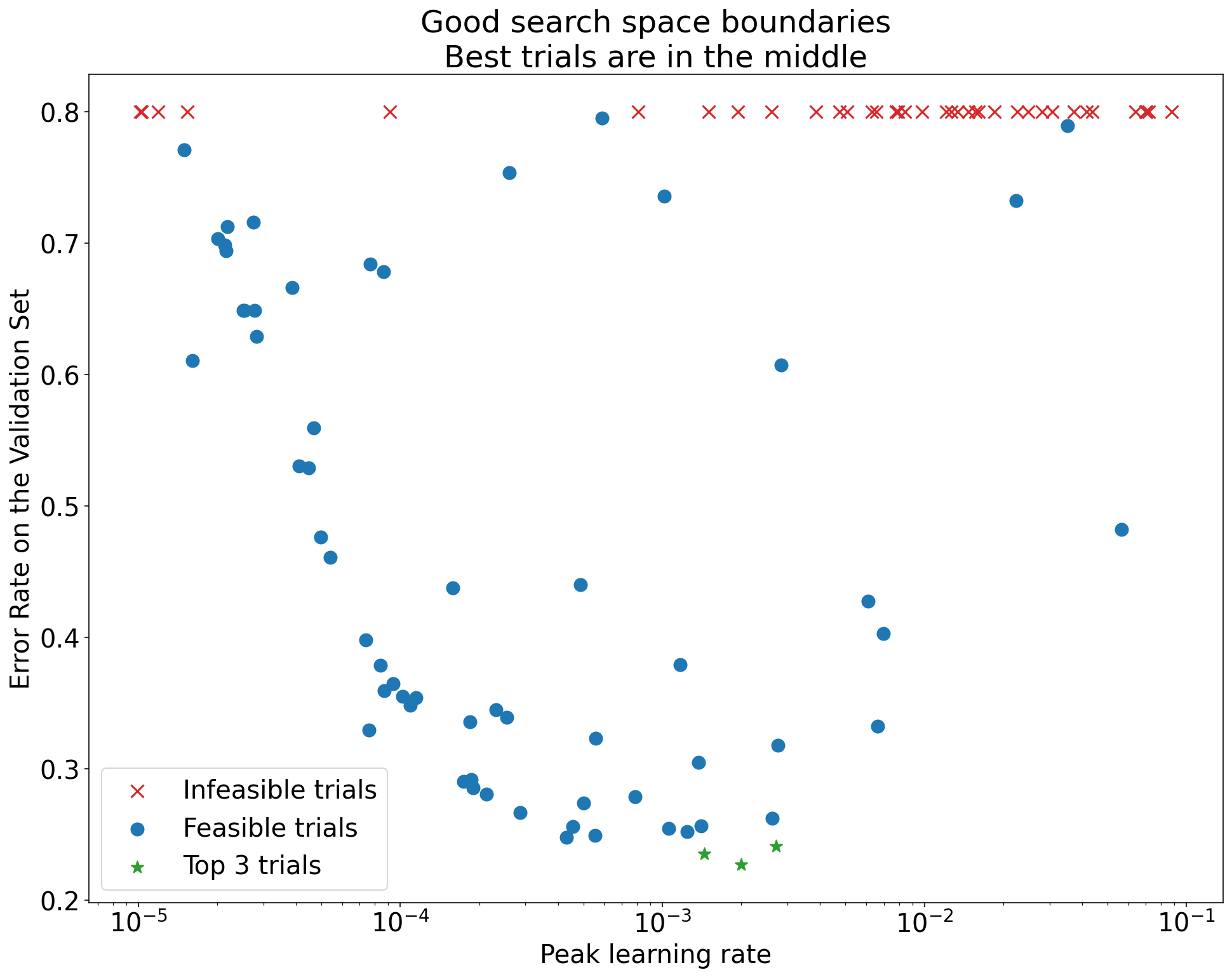
図 1: 検索空間の境界の悪い例と許容可能な検索空間の境界の例。
図 1 のプロットは、初期学習率に対するエラー率(低いほど良い)を示しています。最適なポイントが(あるディメンションで)検索空間の端に集中している場合は、最適な観測ポイントが境界の近くにない状態になるまで、検索空間の境界を拡大する必要があるかもしれません。
多くの場合、研究には、結果が大きく異なるか、非常に悪い結果になる「実行不可能な」試験が含まれます(図 1 の赤い X でマークされています)。すべてのトライアルで、学習率が特定のしきい値よりも大きい場合に実行不可能であり、パフォーマンスが最も高いトライアルの学習率がその領域の端にある場合、モデルで安定性の問題が発生し、より高い学習率にアクセスできない可能性があります。
検索空間で十分な数のポイントをサンプリングしていない
一般に、検索空間が十分に密にサンプリングされているかどうかを判断することは非常に困難です。🤖 試行回数は少ないよりも多い方が良いですが、試行回数を増やすとコストが明らかに増加します。
十分なサンプルを収集できたかどうかを判断するのは難しいため、次のことをおすすめします。
- 購入可能なものを試す。
- さまざまなハイパーパラメータ軸のプロットを繰り返し見て、検索空間の「良好」な領域に何個のポイントがあるかを把握しようとすることで、直感的な信頼度を調整します。
トレーニング曲線を確認する
概要: 損失曲線を調べることは、一般的な障害モードを特定する簡単な方法であり、次のアクションの優先順位付けに役立ちます。
多くの場合、テストの主な目的は、各トライアルの検証エラーを考慮することのみです。ただし、各トライアルを 1 つの数値に減らす場合は注意が必要です。その焦点によって、表面下で何が起こっているかについての重要な詳細が隠される可能性があるためです。すべてのスタディで、少なくとも上位数個のトライアルの損失曲線を確認することを強くおすすめします。主な実験目標に対処するために必要でない場合でも、損失曲線(トレーニング損失と検証損失の両方を含む)を調べることは、一般的な障害モードを特定するうえで有効な方法であり、次に取るべきアクションの優先順位付けに役立ちます。
損失曲線を確認する際は、次の点に注目してください。
問題のある過適合を示すトライアルはありますか?問題のある過学習は、トレーニング中に検証エラーが増加し始めたときに発生します。科学的ハイパーパラメータの各設定で「最適な」トライアルを選択して、不要なハイパーパラメータを最適化する実験設定では、比較する科学的ハイパーパラメータの設定に対応する少なくとも各最適なトライアルで、問題のある過適合を確認します。最適なトライアルのいずれかで問題のある過適合が発生した場合は、次のいずれかまたは両方を行います。
- 追加の正則化手法を使用してテストを再実行する
- 科学的ハイパーパラメータの値を比較する前に、既存の正則化パラメータを再調整します。科学的ハイパーパラメータに正則化パラメータが含まれている場合は、この限りではありません。正則化パラメータの強度が低い設定で過適合の問題が発生しても、驚くことではありません。
過適合の軽減は、コードの複雑さや追加の計算を最小限に抑える一般的な正則化手法(ドロップアウト正則化、ラベル スムージング、重み減衰など)を使用して簡単に行うことができます。そのため、通常は次のテストにこれらの 1 つ以上を追加するのは簡単です。たとえば、科学的ハイパーパラメータが「隠れ層の数」で、隠れ層の数が最も多い最適なトライアルで過剰適合の問題が発生した場合は、隠れ層の数が少ないものをすぐに選択するのではなく、追加の正則化を試すことをおすすめします。
「最適」なトライアルのいずれにも問題のある過適合が見られない場合でも、いずれかのトライアルで過適合が発生している場合は、問題が発生している可能性があります。最適なトライアルを選択すると、問題のある過剰適合を示す構成が抑制され、過剰適合を示さない構成が優先されます。つまり、最適なトライアルを選択すると、正則化の多い構成が優先されます。ただし、トレーニングを悪化させるものは、意図したものでなくても正則化項として機能する可能性があります。たとえば、学習率を小さくすると、最適化プロセスが妨げられ、トレーニングが正則化される可能性がありますが、通常、この方法で学習率を選択することはありません。科学的ハイパーパラメータの各設定の「最適な」トライアルは、一部の科学的ハイパーパラメータまたはノイズ ハイパーパラメータの「悪い」値を優先するように選択される場合があります。
トレーニングの後半で、トレーニング エラーまたは検証エラーのステップごとの分散が大きいですか?その場合、次の両方に影響する可能性があります。
- 科学的ハイパーパラメータのさまざまな値を比較する機能。これは、各トライアルがランダムに「ラッキー」または「アンラッキー」なステップで終了するためです。
- 本番環境で最適なトライアルの結果を再現できるかどうか。これは、本番環境モデルが調査と同じ「ラッキー」なステップで終了しない可能性があるためです。
ステップ間の差異が生じる最も可能性の高い原因は次のとおりです。
- 各バッチのトレーニング セットから例をランダムにサンプリングすることによるバッチ分散。
- 小さな検証セット
- トレーニングの後半で学習率が高すぎる。
考えられる解決策は次のとおりです。
- バッチサイズを大きくする。
- 検証データをさらに取得します。
- 学習率の減衰を使用する。
- Polyak 平均化を使用する。
トレーニングの終了時にトライアルはまだ改善されていますか?その場合は、コンピューティング バウンドのレジームに該当するため、トレーニング ステップ数を増やすか、学習率のスケジュールを変更すると効果的です。
トレーニング セットと検証セットのパフォーマンスが、最終的なトレーニング ステップの前に飽和状態になっていませんか?その場合は、コンピューティング バウンドではない状態であり、トレーニング ステップ数を減らすことができる可能性があります。
このリスト以外にも、損失曲線を確認することで、多くの追加の動作が明らかになります。たとえば、トレーニング中にトレーニング損失が増加している場合は、通常、トレーニング パイプラインにバグがあることを示します。
分離プロットを使用して変更が有用かどうかを検出する
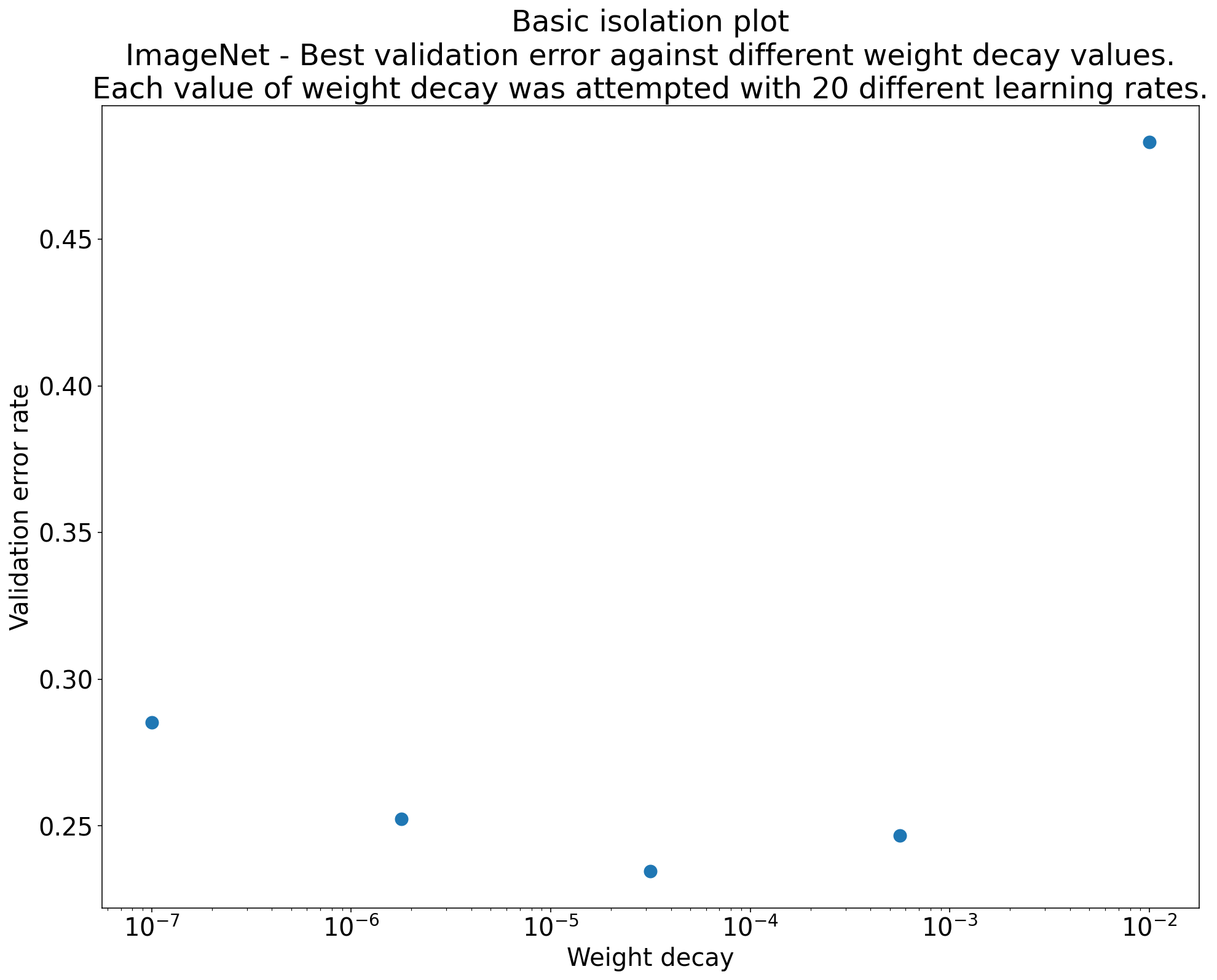
図 2: ImageNet でトレーニングされた ResNet-50 の最適な重み減衰値を調査する分離プロット。
通常、一連のテストの目的は、科学的ハイパーパラメータのさまざまな値を比較することです。たとえば、検証エラーが最小になる重み減衰の値を特定するとします。分離プロットは、基本的なハイパーパラメータ軸プロットの特殊なケースです。分離プロットの各点は、一部(またはすべて)のノイズ ハイパーパラメータにおける最適なトライアルのパフォーマンスに対応します。つまり、不要なハイパーパラメータを「最適化」した後のモデルのパフォーマンスをプロットします。
分離プロットを使用すると、科学的ハイパーパラメータのさまざまな値を簡単に比較できます。たとえば、図 2 の分離プロットは、ImageNet でトレーニングされた ResNet-50 の特定の構成で最適な検証パフォーマンスを生み出す重み減衰の値を示しています。
目標が重み減衰を含めるかどうかを判断することである場合は、このプロットの最適なポイントを重み減衰なしのベースラインと比較します。公平な比較を行うには、ベースラインの学習率も同様に調整する必要があります。
(準)ランダム検索で生成されたデータがあり、分離プロットの連続ハイパーパラメータを検討している場合は、基本ハイパーパラメータ軸プロットの x 軸の値をバケット化し、バケットで定義された各垂直スライスで最適なトライアルを取得することで、分離プロットを近似できます。
汎用性の高いプロットを自動化する
プロットの生成に手間がかかるほど、プロットを十分に確認する可能性は低くなります。そのため、できるだけ多くのプロットを自動的に生成するようにインフラストラクチャを設定することをおすすめします。少なくとも、テストで変化させるすべてのハイパーパラメータについて、基本的なハイパーパラメータ軸プロットを自動的に生成することをおすすめします。
また、すべてのトライアルの損失曲線を自動的に生成することをおすすめします。また、各スタディの最適なトライアルを簡単に見つけて、損失曲線を確認できるようにすることをおすすめします。
他にも、有用なプロットや可視化を多数追加できます。Geoffrey Hinton の言葉を言い換えると、次のようになります。
新しいプロットを作成するたびに、新しいことを学びます。
候補の変更を採用するかどうかを判断する
概要: モデルやトレーニング手順を変更するか、新しいハイパーパラメータ構成を採用するかを決定する際は、結果のさまざまな変動要因に注意してください。
モデルの改善を試みる際、特定の候補の変更によって、当初は既存の構成よりも優れた検証エラーが達成されることがあります。ただし、テストを繰り返すと、一貫したメリットがないことがわかる場合があります。非公式には、不整合な結果の最も重要な原因は、次の広範なカテゴリに分類できます。
- トレーニング手順の分散、再トレーニングの分散、トライアルの分散: 同じハイパーパラメータを使用するが、異なるランダム シードを使用するトレーニング実行間のばらつき。たとえば、異なるランダム初期化、トレーニング データのシャッフル、ドロップアウト マスク、データ拡張オペレーションのパターン、並列算術演算の順序はすべて、トライアルの分散の潜在的な原因です。
- ハイパーパラメータ検索の分散、またはスタディの分散: ハイパーパラメータを選択する手順によって生じる結果のばらつき。たとえば、特定の検索空間で同じテストを実行しても、準ランダム検索のシードが 2 つ異なるため、選択されるハイパーパラメータ値が異なる場合があります。
- データの収集とサンプリングの分散: トレーニング データ、検証データ、テストデータへのランダム分割による分散、またはトレーニング データの生成プロセス全般による分散。
有限の検証セットで推定された検証エラー率を、厳密な統計検定を使用して比較できます。ただし、多くの場合、トライアルの分散のみで、同じハイパーパラメータ設定を使用する 2 つの異なるトレーニング済みモデル間に統計的に有意な差が生じることがあります。
ハイパーパラメータ空間の個々のポイントのレベルを超えた結論を導き出そうとする場合、研究の分散が最も懸念されます。調査の分散は、試行回数と検索スペースによって異なります。試験の分散よりも調査の分散が大きい場合と、はるかに小さい場合が見られます。したがって、候補の変更を採用する前に、最適なトライアルを N 回実行して、トライアル間の分散を特徴付けることを検討してください。通常、パイプラインに大きな変更を加えた後に試用期間の分散を再特性化するだけで済みますが、場合によってはより新しい推定値が必要になることがあります。他のアプリケーションでは、トライアルの分散を特徴付けるのはコストがかかりすぎて、価値がありません。
実際の改善につながる変更(新しいハイパーパラメータ構成を含む)のみを採用したい場合でも、特定の変更が役立つことを完全に確信する必要はありません。したがって、新しいハイパーパラメータ ポイント(またはその他の変更)がベースラインよりも良い結果が得られた場合(新しいポイントとベースラインの両方の再トレーニングの分散を可能な限り考慮した場合)、おそらくそれを今後の比較の新しいベースラインとして採用する必要があります。ただし、変更によって生じる複雑さよりも大きな改善効果が得られる変更のみを採用することをおすすめします。
探索の終了後
概要: ベイズ最適化ツールは、適切な検索スペースの検索が完了し、チューニングする価値のあるハイパーパラメータが決定されたら、魅力的な選択肢となります。
最終的には、チューニングの問題について詳しく学習することから、リリースまたはその他の用途で使用する単一の最適な構成を作成することに優先順位が移ります。この時点で、最適な観測トライアルの周囲のローカル領域を十分に含み、適切にサンプリングされた絞り込み済みの検索スペースが存在するはずです。探索作業では、調整する最も重要なハイパーパラメータと、可能な限り大きなチューニング予算を使用して最終的な自動チューニング スタディの検索スペースを構築するために使用できる妥当な範囲が明らかになっているはずです。
チューニングの問題に関する分析情報の最大化を重視しなくなったため、準ランダム検索の多くの利点は適用されなくなります。したがって、ベイズ最適化ツールを使用して、最適なハイパーパラメータ構成を自動的に見つける必要があります。オープンソースの Vizier は、ベイズ最適化アルゴリズムなど、ML モデルのチューニング用のさまざまな高度なアルゴリズムを実装しています。
検索スペースに、NaN トレーニング損失を取得するポイントや、平均よりも標準偏差が大幅に悪いトレーニング損失を取得するポイントなど、発散点が大量に含まれているとします。この場合は、発散するトライアルを適切に処理するブラックボックス最適化ツールを使用することをおすすめします。(この問題に対処する優れた方法については、制約が不明な場合のベイズ最適化をご覧ください)。オープンソースの Vizier は、トライアルを実行不可能としてマークすることで、発散点をマークすることをサポートしています。ただし、構成によっては、Gelbart らの推奨アプローチを使用しない場合があります。
探索が完了したら、テストセットのパフォーマンスを確認することを検討してください。原則として、検証セットをトレーニング セットに折り畳み、ベイズ最適化で見つかった最適な構成を再トレーニングすることもできます。ただし、この特定のワークロードで今後リリースがない場合(1 回限りの Kaggle コンペティションなど)にのみ、この方法が適切です。