Theo mục đích của tài liệu này:
Mục tiêu cuối cùng của việc phát triển công nghệ học máy là tối đa hoá tính hữu ích của mô hình được triển khai.
Thông thường, bạn có thể sử dụng các bước và nguyên tắc cơ bản tương tự trong phần này cho mọi vấn đề về học máy.
Phần này đưa ra các giả định sau:
- Bạn đã có một quy trình huấn luyện đang chạy đầy đủ cùng với một cấu hình mang lại kết quả hợp lý.
- Bạn có đủ tài nguyên điện toán để tiến hành các thử nghiệm điều chỉnh có ý nghĩa và chạy song song ít nhất một số công việc huấn luyện.
Chiến lược điều chỉnh gia tăng
Đề xuất: Bắt đầu bằng một cấu hình đơn giản. Sau đó, hãy cải thiện dần trong khi tìm hiểu sâu hơn về vấn đề. Đảm bảo rằng mọi điểm cải tiến đều dựa trên bằng chứng xác thực.
Chúng tôi giả định rằng mục tiêu của bạn là tìm ra một cấu hình giúp tối đa hoá hiệu suất của mô hình. Đôi khi, mục tiêu của bạn là tối đa hoá mức độ cải thiện mô hình theo một thời hạn cố định. Trong các trường hợp khác, bạn có thể tiếp tục cải thiện mô hình vô thời hạn; ví dụ: liên tục cải thiện một mô hình được sử dụng trong quá trình sản xuất.
Về nguyên tắc, bạn có thể tối đa hoá hiệu suất bằng cách sử dụng một thuật toán để tự động tìm kiếm toàn bộ không gian của các cấu hình có thể, nhưng đây không phải là một lựa chọn thực tế. Không gian của các cấu hình có thể có là vô cùng lớn và chưa có thuật toán nào đủ tinh vi để tìm kiếm hiệu quả không gian này mà không có hướng dẫn của con người. Hầu hết các thuật toán tìm kiếm tự động đều dựa vào một không gian tìm kiếm được thiết kế thủ công để xác định tập hợp các cấu hình cần tìm kiếm và những không gian tìm kiếm này có thể có ý nghĩa khá lớn.
Cách hiệu quả nhất để tối đa hoá hiệu suất là bắt đầu bằng một cấu hình đơn giản, sau đó tăng dần các tính năng và cải thiện trong khi xây dựng thông tin chi tiết về vấn đề.
Bạn nên sử dụng các thuật toán tìm kiếm tự động trong mỗi vòng điều chỉnh và liên tục cập nhật các không gian tìm kiếm khi bạn hiểu rõ hơn. Khi khám phá, bạn sẽ tìm thấy các cấu hình ngày càng tốt hơn và do đó, mô hình "tốt nhất" của bạn sẽ liên tục được cải thiện.
Thuật ngữ "ra mắt" đề cập đến bản cập nhật cho cấu hình tốt nhất của chúng tôi (có thể hoặc không tương ứng với việc ra mắt thực tế một mô hình sản xuất). Đối với mỗi "lần ra mắt", bạn phải đảm bảo rằng thay đổi đó dựa trên bằng chứng xác thực (chứ không chỉ là cơ hội ngẫu nhiên dựa trên một cấu hình may mắn) để không làm tăng thêm sự phức tạp không cần thiết cho quy trình huấn luyện.
Nhìn chung, chiến lược điều chỉnh gia tăng của chúng tôi bao gồm việc lặp lại 4 bước sau:
- Chọn một mục tiêu cho vòng thử nghiệm tiếp theo. Đảm bảo rằng mục tiêu được đặt trong phạm vi phù hợp.
- Thiết kế vòng thử nghiệm tiếp theo. Thiết kế và thực hiện một loạt thử nghiệm để đạt được mục tiêu này.
- Học hỏi từ kết quả thử nghiệm. Đánh giá thử nghiệm dựa trên danh sách kiểm tra.
- Xác định xem có nên áp dụng thay đổi đề xuất hay không.
Phần còn lại của phần này trình bày chi tiết về chiến lược này.
Chọn một mục tiêu cho vòng thử nghiệm tiếp theo
Nếu cố gắng thêm nhiều tính năng hoặc trả lời nhiều câu hỏi cùng lúc, bạn có thể không phân biệt được các tác động riêng biệt đối với kết quả. Ví dụ về các mục tiêu:
- Thử một điểm cải tiến tiềm năng cho quy trình (ví dụ: một bộ điều chỉnh mới, lựa chọn tiền xử lý, v.v.).
- Tìm hiểu tác động của một siêu tham số mô hình cụ thể (ví dụ: hàm kích hoạt)
- Giảm thiểu lỗi xác thực.
Ưu tiên tiến trình dài hạn hơn là cải thiện lỗi xác thực ngắn hạn
Tóm tắt: Hầu hết thời gian, mục tiêu chính của bạn là hiểu rõ vấn đề điều chỉnh.
Bạn nên dành phần lớn thời gian để tìm hiểu vấn đề và dành tương đối ít thời gian để tập trung tối đa hoá hiệu suất trên tập hợp xác thực. Nói cách khác, hãy dành phần lớn thời gian cho việc "khám phá" và chỉ dành một ít thời gian cho việc "khai thác". Việc hiểu rõ vấn đề là yếu tố quan trọng để tối đa hoá hiệu suất cuối cùng. Việc ưu tiên thông tin chi tiết hơn là lợi nhuận ngắn hạn sẽ giúp:
- Tránh ra mắt những thay đổi không cần thiết xuất hiện trong các lần chạy có hiệu suất cao chỉ do tình cờ trong quá khứ.
- Xác định siêu tham số mà lỗi xác thực nhạy cảm nhất, siêu tham số tương tác nhiều nhất và do đó cần được điều chỉnh lại cùng nhau, cũng như siêu tham số tương đối không nhạy cảm với các thay đổi khác và do đó có thể được cố định trong các thử nghiệm trong tương lai.
- Đề xuất các tính năng mới tiềm năng để thử, chẳng hạn như các hàm điều chuẩn mới khi hiện tượng khớp quá mức là một vấn đề.
- Xác định những tính năng không hữu ích và do đó có thể bị xoá, giúp giảm độ phức tạp của các thử nghiệm trong tương lai.
- Nhận biết thời điểm các điểm cải thiện từ việc điều chỉnh siêu tham số có khả năng đã đạt đến mức tối đa.
- Thu hẹp không gian tìm kiếm xung quanh giá trị tối ưu để cải thiện hiệu quả điều chỉnh.
Cuối cùng, bạn sẽ hiểu được vấn đề. Sau đó, bạn có thể chỉ tập trung vào lỗi xác thực ngay cả khi các thử nghiệm không cung cấp nhiều thông tin nhất về cấu trúc của vấn đề điều chỉnh.
Thiết kế vòng thử nghiệm tiếp theo
Tóm tắt: Xác định siêu tham số nào là siêu tham số khoa học, gây phiền toái và cố định cho mục tiêu thử nghiệm. Tạo một chuỗi các nghiên cứu để so sánh các giá trị khác nhau của siêu tham số khoa học trong khi tối ưu hoá các siêu tham số gây phiền toái. Chọn không gian tìm kiếm của các siêu tham số gây phiền toái để cân bằng chi phí tài nguyên với giá trị khoa học.
Xác định các siêu tham số khoa học, gây phiền toái và cố định
Đối với một mục tiêu nhất định, tất cả các siêu tham số đều thuộc một trong các danh mục sau:
- siêu tham số khoa học là những tham số mà bạn đang cố gắng đo lường mức độ ảnh hưởng đến hiệu suất của mô hình.
- siêu tham số gây phiền toái là những tham số cần được tối ưu hoá để so sánh công bằng các giá trị khác nhau của siêu tham số khoa học. Siêu tham số gây phiền toái tương tự như tham số gây phiền toái trong số liệu thống kê.
- siêu tham số cố định có giá trị không đổi trong vòng thử nghiệm hiện tại. Giá trị của các siêu tham số cố định không được thay đổi khi bạn so sánh các giá trị khác nhau của siêu tham số khoa học. Bằng cách cố định một số siêu tham số nhất định cho một nhóm thử nghiệm, bạn phải chấp nhận rằng kết luận rút ra từ các thử nghiệm có thể không hợp lệ đối với các chế độ cài đặt khác của siêu tham số cố định. Nói cách khác, các siêu tham số cố định sẽ tạo ra những hạn chế đối với mọi kết luận mà bạn rút ra từ các thử nghiệm.
Ví dụ: giả sử mục tiêu của bạn như sau:
Xác định xem một mô hình có nhiều lớp ẩn hơn có lỗi xác thực thấp hơn hay không.
Trong trường hợp này:
- Tốc độ học tập là một siêu tham số gây phiền toái vì bạn chỉ có thể so sánh một cách công bằng các mô hình có số lượng lớp ẩn khác nhau nếu tốc độ học tập được điều chỉnh riêng cho từng số lượng lớp ẩn. (Tốc độ học tập tối ưu thường phụ thuộc vào cấu trúc mô hình).
- Hàm kích hoạt có thể là một siêu tham số cố định nếu bạn đã xác định trong các thử nghiệm trước rằng hàm kích hoạt tốt nhất không nhạy cảm với độ sâu của mô hình. Hoặc, bạn sẵn sàng giới hạn kết luận về số lượng lớp ẩn để bao gồm hàm kích hoạt này. Ngoài ra, đây có thể là một siêu tham số gây phiền toái nếu bạn chuẩn bị điều chỉnh riêng cho từng số lượng lớp ẩn.
Một siêu tham số cụ thể có thể là siêu tham số khoa học, siêu tham số gây phiền toái hoặc siêu tham số cố định; chỉ định của siêu tham số thay đổi tuỳ thuộc vào mục tiêu thử nghiệm. Ví dụ: hàm kích hoạt có thể là bất kỳ hàm nào sau đây:
- Siêu tham số khoa học: ReLU hay tanh là lựa chọn tốt hơn cho vấn đề của chúng ta?
- Siêu tham số gây phiền toái: Mô hình 5 lớp tốt nhất có tốt hơn mô hình 6 lớp tốt nhất khi bạn cho phép một số hàm kích hoạt có thể khác nhau không?
- Siêu tham số cố định: Đối với mạng ReLU, việc thêm tính năng chuẩn hoá theo lô ở một vị trí cụ thể có giúp ích không?
Khi thiết kế một loạt thử nghiệm mới:
- Xác định các siêu tham số khoa học cho mục tiêu thử nghiệm. (Ở giai đoạn này, bạn có thể coi tất cả các siêu tham số khác là siêu tham số gây phiền toái.)
- Chuyển đổi một số siêu tham số gây phiền toái thành siêu tham số cố định.
Với nguồn lực không giới hạn, bạn sẽ coi tất cả siêu tham số không phải khoa học là siêu tham số gây phiền toái để kết luận mà bạn rút ra từ các thử nghiệm không có cảnh báo về các giá trị siêu tham số cố định. Tuy nhiên, bạn càng cố gắng điều chỉnh nhiều siêu tham số gây phiền toái, thì nguy cơ bạn không điều chỉnh chúng đủ tốt cho từng chế độ cài đặt của các siêu tham số khoa học càng lớn và cuối cùng bạn sẽ đưa ra kết luận sai từ các thử nghiệm của mình. Như mô tả trong phần sau, bạn có thể giảm thiểu rủi ro này bằng cách tăng ngân sách tính toán. Tuy nhiên, ngân sách tài nguyên tối đa của bạn thường thấp hơn mức cần thiết để điều chỉnh tất cả các siêu tham số không khoa học.
Bạn nên chuyển đổi một siêu tham số gây phiền toái thành một siêu tham số cố định khi những hạn chế do việc cố định siêu tham số đó gây ra ít phiền toái hơn so với chi phí khi đưa siêu tham số đó vào dưới dạng một siêu tham số gây phiền toái. Một siêu tham số gây phiền toái tương tác càng nhiều với các siêu tham số khoa học, thì việc cố định giá trị của siêu tham số đó càng gây hại. Ví dụ: giá trị tốt nhất của mức độ suy giảm trọng số thường phụ thuộc vào kích thước mô hình, vì vậy, việc so sánh các kích thước mô hình khác nhau giả định một giá trị cụ thể duy nhất của mức độ suy giảm trọng số sẽ không mang lại nhiều thông tin chi tiết.
Một số thông số của trình tối ưu hoá
Theo nguyên tắc chung, một số siêu tham số của trình tối ưu hoá (ví dụ: tốc độ học, động lượng, tham số lịch tốc độ học, beta Adam, v.v.) là các siêu tham số gây phiền toái vì chúng có xu hướng tương tác nhiều nhất với các thay đổi khác. Các siêu tham số của trình tối ưu hoá này hiếm khi là siêu tham số khoa học vì mục tiêu như "tốc độ học tập tốt nhất cho quy trình hiện tại là gì?" không cung cấp nhiều thông tin chi tiết. Sau cùng, chế độ cài đặt tốt nhất có thể thay đổi theo thay đổi tiếp theo của quy trình.
Đôi khi, bạn có thể cố định một số siêu tham số của trình tối ưu hoá do các hạn chế về tài nguyên hoặc bằng chứng đặc biệt mạnh mẽ cho thấy chúng không tương tác với các tham số khoa học. Tuy nhiên, bạn thường phải giả định rằng bạn phải điều chỉnh riêng các siêu tham số của trình tối ưu hoá để so sánh công bằng giữa các chế độ cài đặt khác nhau của siêu tham số khoa học, và do đó không được cố định. Hơn nữa, không có lý do tiên nghiệm nào để ưu tiên một giá trị siêu tham số của trình tối ưu hoá hơn một giá trị khác; ví dụ: các giá trị siêu tham số của trình tối ưu hoá thường không ảnh hưởng đến chi phí tính toán của các lượt truyền xuôi hoặc độ dốc theo bất kỳ cách nào.
Lựa chọn về trình tối ưu hoá
Lựa chọn về trình tối ưu hoá thường là:
- một siêu tham số khoa học
- một siêu tham số cố định
Trình tối ưu hoá là một siêu tham số khoa học nếu mục tiêu thử nghiệm của bạn liên quan đến việc so sánh công bằng giữa hai hoặc nhiều trình tối ưu hoá khác nhau. Ví dụ:
Xác định trình tối ưu hoá nào tạo ra lỗi xác thực thấp nhất trong một số bước nhất định.
Ngoài ra, bạn có thể đặt trình tối ưu hoá thành một siêu tham số cố định vì nhiều lý do, bao gồm:
- Các thử nghiệm trước đây cho thấy rằng trình tối ưu hoá tốt nhất cho vấn đề điều chỉnh của bạn không nhạy cảm với các siêu tham số khoa học hiện tại.
- Bạn muốn so sánh các giá trị của siêu tham số khoa học bằng cách sử dụng trình tối ưu hoá này vì các đường cong huấn luyện của trình tối ưu hoá này dễ lý giải hơn.
- Bạn muốn sử dụng trình tối ưu hoá này vì trình này sử dụng ít bộ nhớ hơn các trình tối ưu hoá khác.
Siêu tham số điều chuẩn
Các siêu tham số do kỹ thuật điều chuẩn đưa ra thường là các siêu tham số gây phiền toái. Tuy nhiên, việc có nên đưa kỹ thuật điều chuẩn vào hay không là một siêu tham số khoa học hoặc cố định.
Ví dụ: việc điều chỉnh bằng cách loại bỏ sẽ làm tăng độ phức tạp của mã. Do đó, khi quyết định có nên đưa quy trình điều chỉnh bỏ qua vào hay không, bạn có thể coi "không bỏ qua" so với "bỏ qua" là một siêu tham số khoa học, nhưng tốc độ bỏ qua lại là một siêu tham số gây phiền toái. Nếu bạn quyết định thêm quy trình điều chỉnh bỏ qua vào quy trình dựa trên thử nghiệm này, thì tỷ lệ bỏ qua sẽ là một siêu tham số gây phiền toái trong các thử nghiệm trong tương lai.
Siêu tham số kiến trúc
Siêu tham số kiến trúc thường là siêu tham số khoa học hoặc cố định vì các thay đổi về kiến trúc có thể ảnh hưởng đến chi phí phân phát và huấn luyện, độ trễ và yêu cầu về bộ nhớ. Ví dụ: số lượng lớp thường là một siêu tham số khoa học hoặc cố định vì nó có xu hướng gây ra hậu quả nghiêm trọng cho tốc độ huấn luyện và mức sử dụng bộ nhớ.
Các phần phụ thuộc vào siêu tham số khoa học
Trong một số trường hợp, các tập hợp siêu tham số cố định và gây phiền toái phụ thuộc vào các giá trị của siêu tham số khoa học. Ví dụ: giả sử bạn đang cố gắng xác định trình tối ưu hoá nào trong Nesterov momentum và Adam tạo ra lỗi xác thực thấp nhất. Trong trường hợp này:
- Siêu tham số khoa học là trình tối ưu hoá, nhận các giá trị
{"Nesterov_momentum", "Adam"} - Giá trị
optimizer="Nesterov_momentum"giới thiệu các siêu tham số{learning_rate, momentum}, có thể là siêu tham số phiền toái hoặc cố định. - Giá trị
optimizer="Adam"giới thiệu các siêu tham số{learning_rate, beta1, beta2, epsilon}, có thể là siêu tham số cố định hoặc gây phiền toái.
Các siêu tham số chỉ xuất hiện đối với một số giá trị nhất định của siêu tham số khoa học được gọi là siêu tham số có điều kiện.
Đừng giả định rằng hai siêu tham số có điều kiện giống nhau chỉ vì chúng có cùng tên! Trong ví dụ trước, siêu tham số có điều kiện có tên là learning_rate là một siêu tham số khác cho optimizer="Nesterov_momentum" so với optimizer="Adam". Vai trò của nó tương tự (mặc dù không giống hệt nhau) trong hai thuật toán, nhưng phạm vi giá trị hoạt động tốt trong mỗi trình tối ưu hoá thường khác nhau theo một số bậc độ lớn.
Tạo một bộ thẻ học tập
Sau khi xác định các siêu tham số khoa học và gây phiền toái, bạn nên thiết kế một nghiên cứu hoặc chuỗi nghiên cứu để đạt được mục tiêu thử nghiệm. Nghiên cứu chỉ định một tập hợp các cấu hình siêu tham số sẽ được chạy để phân tích sau đó. Mỗi cấu hình được gọi là một thử nghiệm. Việc tạo một nghiên cứu thường liên quan đến việc chọn những nội dung sau:
- Các siêu tham số thay đổi trong các thử nghiệm.
- Các giá trị mà những siêu tham số đó có thể nhận (không gian tìm kiếm).
- Số lần thử.
- Một thuật toán tìm kiếm tự động để lấy mẫu nhiều thử nghiệm như vậy từ không gian tìm kiếm.
Ngoài ra, bạn có thể tạo một nghiên cứu bằng cách chỉ định tập hợp các cấu hình siêu tham số theo cách thủ công.
Mục đích của các nghiên cứu này là đồng thời:
- Chạy quy trình bằng các giá trị khác nhau của siêu tham số khoa học.
- "Tối ưu hoá" (hoặc "tối ưu hoá quá mức") các siêu tham số gây phiền toái để việc so sánh giữa các giá trị khác nhau của siêu tham số khoa học được công bằng nhất có thể.
Trong trường hợp đơn giản nhất, bạn sẽ thực hiện một nghiên cứu riêng cho từng cấu hình của các thông số khoa học, trong đó mỗi nghiên cứu điều chỉnh các siêu tham số gây phiền toái. Ví dụ: nếu mục tiêu của bạn là chọn trình tối ưu hoá tốt nhất trong số Nesterov momentum và Adam, bạn có thể tạo 2 nghiên cứu:
- Một nghiên cứu trong đó
optimizer="Nesterov_momentum"và các siêu tham số gây phiền toái là{learning_rate, momentum} - Một nghiên cứu khác trong đó
optimizer="Adam"và các siêu tham số gây phiền toái là{learning_rate, beta1, beta2, epsilon}.
Bạn sẽ so sánh hai trình tối ưu hoá bằng cách chọn thử nghiệm hoạt động hiệu quả nhất trong mỗi nghiên cứu.
Bạn có thể sử dụng bất kỳ thuật toán tối ưu hoá không có độ dốc nào, bao gồm cả các phương pháp như tối ưu hoá Bayesian hoặc thuật toán tiến hoá, để tối ưu hoá các siêu tham số gây phiền toái. Tuy nhiên, chúng tôi muốn sử dụng tìm kiếm gần ngẫu nhiên trong giai đoạn khám phá của quá trình điều chỉnh vì nhiều ưu điểm mà phương pháp này mang lại trong chế độ cài đặt này. Sau khi quá trình khám phá kết thúc, bạn nên sử dụng phần mềm tối ưu hoá theo phương pháp Bayesian hiện đại (nếu có).
Hãy xem xét một trường hợp phức tạp hơn, trong đó bạn muốn so sánh một số lượng lớn các giá trị của siêu tham số khoa học nhưng không thực tế khi thực hiện nhiều nghiên cứu độc lập như vậy. Trong trường hợp này, bạn có thể làm như sau:
- Đưa các tham số khoa học vào cùng không gian tìm kiếm với các siêu tham số gây phiền toái.
- Sử dụng thuật toán tìm kiếm để lấy mẫu các giá trị của cả siêu tham số khoa học và siêu tham số gây phiền toái trong một nghiên cứu duy nhất.
Khi áp dụng phương pháp này, các siêu tham số có điều kiện có thể gây ra vấn đề. Sau tất cả, rất khó để chỉ định một không gian tìm kiếm trừ phi tập hợp các siêu tham số gây phiền toái là giống nhau cho tất cả các giá trị của siêu tham số khoa học. Trong trường hợp này, chúng tôi càng ưu tiên sử dụng tìm kiếm gần ngẫu nhiên hơn là các công cụ tối ưu hoá hộp đen phức tạp hơn, vì phương pháp này đảm bảo các giá trị khác nhau của siêu tham số khoa học sẽ được lấy mẫu một cách đồng nhất. Bất kể thuật toán tìm kiếm là gì, hãy đảm bảo rằng thuật toán đó tìm kiếm các thông số khoa học một cách đồng nhất.
Cân bằng giữa các thử nghiệm mang tính thông tin và có chi phí hợp lý
Khi thiết kế một nghiên cứu hoặc chuỗi nghiên cứu, hãy phân bổ một ngân sách hạn chế để đạt được thoả đáng 3 mục tiêu sau:
- So sánh đủ các giá trị khác nhau của siêu tham số khoa học.
- Điều chỉnh các siêu tham số gây phiền toái trong một không gian tìm kiếm đủ lớn.
- Lấy mẫu không gian tìm kiếm của các siêu tham số gây phiền toái một cách đủ dày đặc.
Bạn càng đạt được 3 mục tiêu này, bạn càng có thể trích xuất nhiều thông tin chi tiết từ thử nghiệm. Việc so sánh càng nhiều giá trị của siêu tham số khoa học càng tốt sẽ mở rộng phạm vi thông tin chi tiết mà bạn thu được từ thử nghiệm.
Việc đưa vào càng nhiều siêu tham số gây phiền toái càng tốt và cho phép mỗi siêu tham số gây phiền toái thay đổi trong phạm vi càng rộng càng tốt sẽ làm tăng độ tin cậy rằng giá trị "tốt" của siêu tham số gây phiền toái tồn tại trong không gian tìm kiếm cho từng cấu hình của siêu tham số khoa học. Nếu không, bạn có thể so sánh không công bằng giữa các giá trị của siêu tham số khoa học bằng cách không tìm kiếm các vùng có thể có của không gian siêu tham số gây phiền toái, nơi có thể có các giá trị tốt hơn cho một số giá trị của các tham số khoa học.
Lấy mẫu không gian tìm kiếm của các siêu tham số gây phiền toái một cách dày đặc nhất có thể. Làm như vậy sẽ tăng độ tin cậy rằng quy trình tìm kiếm sẽ tìm thấy mọi chế độ cài đặt phù hợp cho các siêu tham số gây phiền toái có trong không gian tìm kiếm của bạn. Nếu không, bạn có thể so sánh không công bằng giữa các giá trị của tham số khoa học do một số giá trị may mắn hơn với việc lấy mẫu các siêu tham số gây phiền toái.
Rất tiếc, việc cải thiện bất kỳ khía cạnh nào trong 3 khía cạnh này đều đòi hỏi một trong những điều kiện sau:
- Tăng số lượng thử nghiệm, do đó làm tăng chi phí tài nguyên.
- Tìm cách tiết kiệm tài nguyên ở một trong những khía cạnh khác.
Mỗi vấn đề đều có đặc điểm riêng và các hạn chế về tính toán, vì vậy, việc phân bổ tài nguyên cho 3 mục tiêu này đòi hỏi bạn phải có một số kiến thức về lĩnh vực này. Sau khi chạy một nghiên cứu, hãy luôn cố gắng cảm nhận xem nghiên cứu có điều chỉnh các siêu tham số gây phiền toái đủ tốt hay không. Tức là nghiên cứu đã tìm kiếm một không gian đủ lớn và đủ rộng để so sánh một cách công bằng các siêu tham số khoa học (như được mô tả chi tiết hơn trong phần tiếp theo).
Học hỏi từ kết quả thử nghiệm
Đề xuất: Ngoài việc cố gắng đạt được mục tiêu khoa học ban đầu của mỗi nhóm thử nghiệm, hãy xem xét danh sách kiểm tra các câu hỏi bổ sung. Nếu bạn phát hiện ra vấn đề, hãy sửa đổi và chạy lại thử nghiệm.
Cuối cùng, mỗi nhóm thử nghiệm đều có một mục tiêu cụ thể. Bạn nên đánh giá bằng chứng mà các thử nghiệm cung cấp để đạt được mục tiêu đó. Tuy nhiên, nếu đặt đúng câu hỏi, bạn thường có thể tìm ra các vấn đề cần khắc phục trước khi một nhóm thử nghiệm nhất định có thể tiến tới mục tiêu ban đầu. Nếu không đặt những câu hỏi này, bạn có thể đưa ra kết luận không chính xác.
Vì việc chạy thử nghiệm có thể tốn kém, nên bạn cũng nên trích xuất những thông tin chi tiết hữu ích khác từ mỗi nhóm thử nghiệm, ngay cả khi những thông tin chi tiết này không liên quan ngay đến mục tiêu hiện tại.
Trước khi phân tích một nhóm thử nghiệm nhất định để đạt được mục tiêu ban đầu, hãy tự hỏi mình những câu hỏi bổ sung sau:
- Không gian tìm kiếm có đủ lớn không? Nếu điểm tối ưu trong một nghiên cứu nằm gần ranh giới của không gian tìm kiếm theo một hoặc nhiều phương diện, thì có thể phạm vi tìm kiếm chưa đủ rộng. Trong trường hợp này, hãy chạy một nghiên cứu khác với không gian tìm kiếm mở rộng.
- Bạn đã lấy đủ điểm từ không gian tìm kiếm chưa? Nếu không, hãy chạy thêm các điểm hoặc đặt mục tiêu điều chỉnh ít tham vọng hơn.
- Có bao nhiêu thử nghiệm trong mỗi nghiên cứu là không khả thi? Tức là những thử nghiệm nào phân kỳ, có giá trị tổn thất thực sự kém hoặc không chạy được vì vi phạm một số ràng buộc ngầm định? Khi một phần rất lớn các điểm trong một nghiên cứu là không khả thi, hãy điều chỉnh không gian tìm kiếm để tránh lấy mẫu các điểm như vậy. Đôi khi, bạn cần tham số hoá lại không gian tìm kiếm. Trong một số trường hợp, số lượng lớn các điểm không khả thi có thể cho thấy lỗi trong mã huấn luyện.
- Mô hình có gặp vấn đề về việc tối ưu hoá không?
- Bạn có thể học được gì từ các đường cong huấn luyện của những thử nghiệm tốt nhất? Ví dụ: liệu các thử nghiệm tốt nhất có đường cong huấn luyện nhất quán với tình trạng khớp quá mức có vấn đề hay không?
Nếu cần, dựa trên câu trả lời cho các câu hỏi trước đó, hãy tinh chỉnh nghiên cứu hoặc nhóm nghiên cứu gần đây nhất để cải thiện không gian tìm kiếm và/hoặc lấy mẫu nhiều thử nghiệm hơn hoặc thực hiện một số biện pháp khắc phục khác.
Sau khi trả lời các câu hỏi trước, bạn có thể đánh giá bằng chứng mà các thử nghiệm cung cấp cho mục tiêu ban đầu của bạn; ví dụ: đánh giá xem một thay đổi có hữu ích hay không.
Xác định ranh giới không gian tìm kiếm không hợp lệ
Không gian tìm kiếm sẽ đáng ngờ nếu điểm tốt nhất được lấy mẫu từ không gian đó gần với ranh giới của không gian. Bạn có thể tìm thấy một điểm thậm chí còn tốt hơn nếu mở rộng phạm vi tìm kiếm theo hướng đó.
Để kiểm tra ranh giới không gian tìm kiếm, bạn nên vẽ các thử nghiệm đã hoàn tất trên cái mà chúng tôi gọi là các biểu đồ trục siêu tham số cơ bản. Trong những trường hợp này, chúng ta sẽ vẽ giá trị mục tiêu xác thực so với một trong các siêu tham số (ví dụ: tốc độ học). Mỗi điểm trên biểu đồ tương ứng với một thử nghiệm duy nhất.
Giá trị mục tiêu xác thực cho mỗi thử nghiệm thường phải là giá trị tốt nhất mà thử nghiệm đạt được trong quá trình huấn luyện.
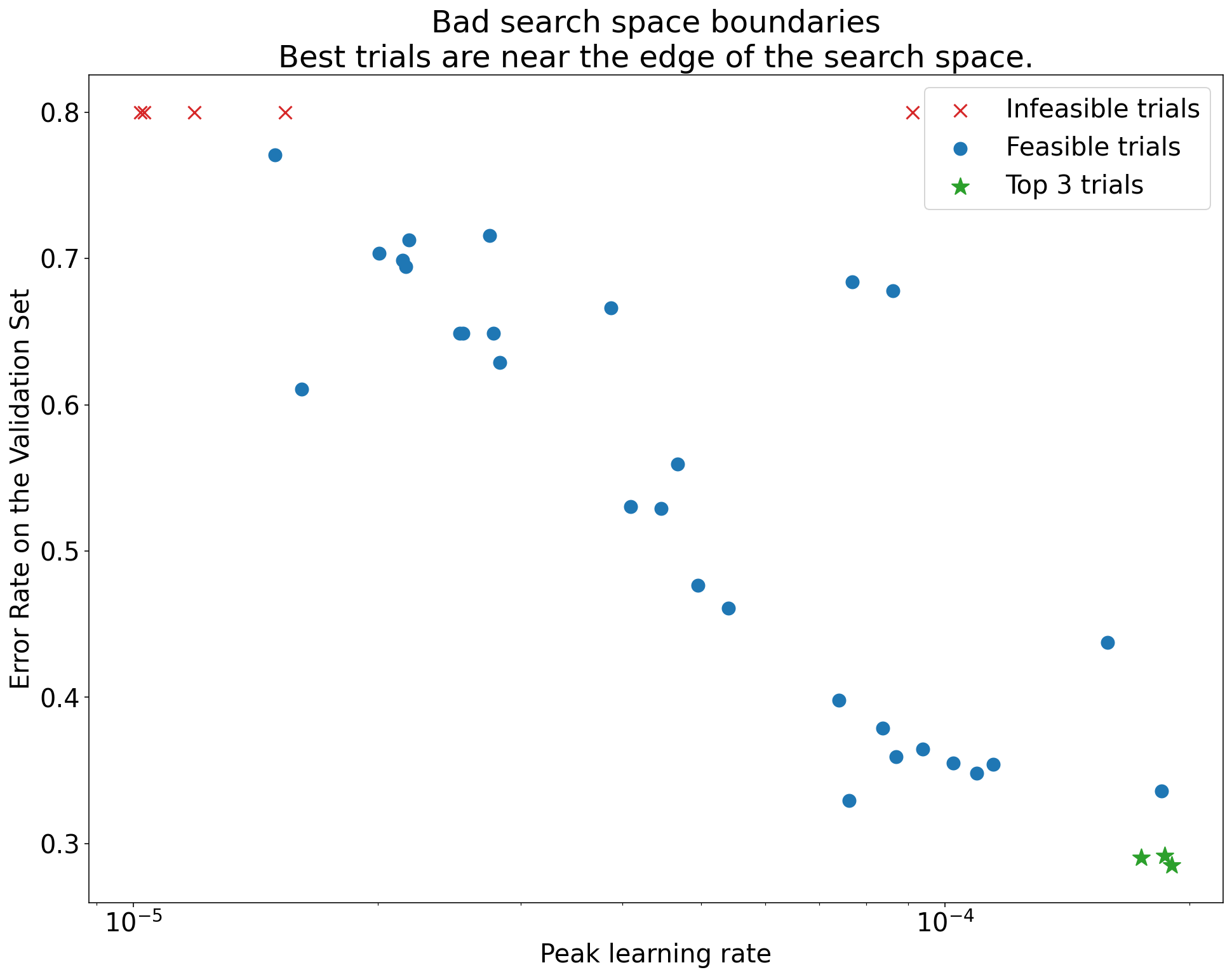
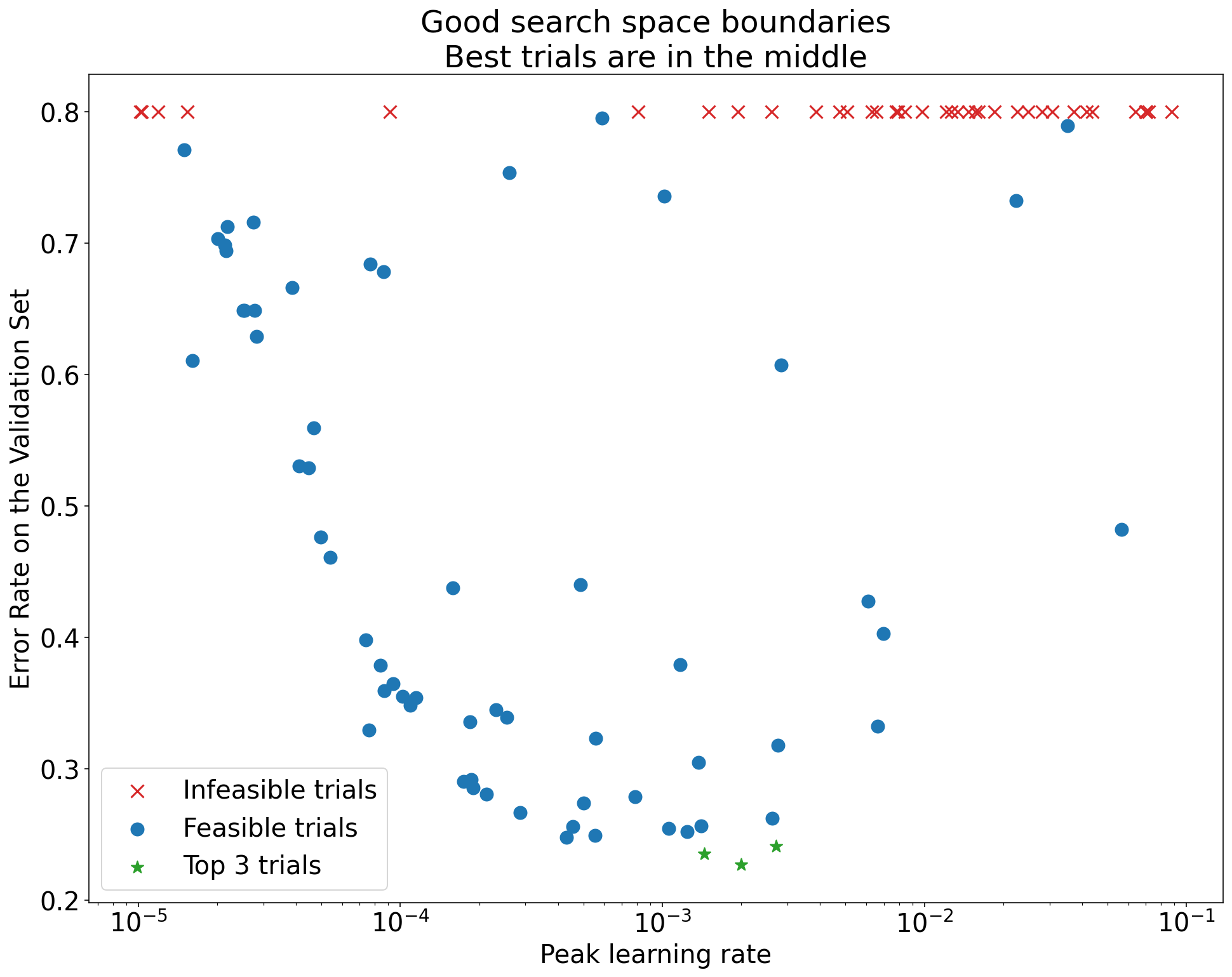
Hình 1: Ví dụ về ranh giới không gian tìm kiếm không phù hợp và ranh giới không gian tìm kiếm phù hợp.
Các biểu đồ trong Hình 1 cho thấy tỷ lệ lỗi (càng thấp càng tốt) so với tốc độ học tập ban đầu. Nếu các điểm tốt nhất tập trung về phía rìa của một không gian tìm kiếm (theo một số phương diện), thì bạn có thể cần mở rộng ranh giới không gian tìm kiếm cho đến khi điểm quan sát tốt nhất không còn gần với ranh giới nữa.
Thường thì một nghiên cứu sẽ bao gồm các thử nghiệm "không khả thi" có kết quả khác biệt hoặc rất tệ (được đánh dấu bằng chữ X màu đỏ trong Hình 1). Nếu tất cả các thử nghiệm đều không khả thi đối với tốc độ học tập lớn hơn một giá trị ngưỡng nào đó và nếu các thử nghiệm hoạt động hiệu quả nhất có tốc độ học tập ở rìa của khu vực đó, thì mô hình có thể gặp phải các vấn đề về độ ổn định khiến mô hình không thể truy cập vào tốc độ học tập cao hơn.
Không lấy đủ điểm trong không gian tìm kiếm
Nói chung, rất khó để biết liệu không gian tìm kiếm đã được lấy mẫu đủ dày hay chưa. 🤖 Chạy nhiều thử nghiệm sẽ tốt hơn so với chạy ít thử nghiệm, nhưng nhiều thử nghiệm sẽ phát sinh thêm chi phí.
Vì rất khó xác định thời điểm bạn đã lấy đủ mẫu, nên chúng tôi đề xuất:
- Thử những sản phẩm bạn có thể mua.
- Điều chỉnh độ tin cậy trực quan bằng cách xem đi xem lại nhiều biểu đồ trục siêu tham số và cố gắng cảm nhận xem có bao nhiêu điểm trong vùng "tốt" của không gian tìm kiếm.
Kiểm tra các đường cong huấn luyện
Tóm tắt: Việc kiểm tra đường cong tổn thất là một cách dễ dàng để xác định các chế độ lỗi phổ biến và có thể giúp bạn ưu tiên các hành động tiềm năng tiếp theo.
Trong nhiều trường hợp, mục tiêu chính của các thử nghiệm chỉ yêu cầu xem xét lỗi xác thực của từng thử nghiệm. Tuy nhiên, hãy cẩn thận khi giảm mỗi lượt thử xuống một con số duy nhất vì việc tập trung đó có thể che giấu các chi tiết quan trọng về những gì đang diễn ra bên dưới bề mặt. Đối với mỗi nghiên cứu, bạn nên xem xét đường cong tổn thất của ít nhất một vài thử nghiệm tốt nhất. Ngay cả khi không cần thiết để giải quyết mục tiêu thử nghiệm chính, việc kiểm tra các đường cong tổn thất (bao gồm cả tổn thất khi huấn luyện và tổn thất khi xác thực) là một cách hay để xác định các chế độ thất bại thường gặp và có thể giúp bạn ưu tiên những hành động cần thực hiện tiếp theo.
Khi kiểm tra các đường cong tổn thất, hãy tập trung vào những câu hỏi sau:
Có thử nghiệm nào cho thấy tình trạng khớp quá mức có vấn đề không? Hiện tượng khớp quá mức có vấn đề xảy ra khi lỗi xác thực bắt đầu tăng trong quá trình huấn luyện. Trong các chế độ cài đặt thử nghiệm mà bạn tối ưu hoá các siêu tham số gây phiền toái bằng cách chọn thử nghiệm "tốt nhất" cho từng chế độ cài đặt của siêu tham số khoa học, hãy kiểm tra tình trạng khớp quá mức có vấn đề trong ít nhất từng thử nghiệm tốt nhất tương ứng với các chế độ cài đặt của siêu tham số khoa học mà bạn đang so sánh. Nếu bất kỳ thử nghiệm nào trong số những thử nghiệm tốt nhất cho thấy tình trạng khớp quá mức có vấn đề, hãy thực hiện một hoặc cả hai thao tác sau:
- Chạy lại thử nghiệm bằng các kỹ thuật điều chỉnh bổ sung
- Điều chỉnh lại các thông số điều chuẩn hiện có trước khi so sánh các giá trị của siêu tham số khoa học. Điều này có thể không áp dụng nếu các siêu tham số khoa học bao gồm các tham số điều chuẩn, vì khi đó, sẽ không có gì đáng ngạc nhiên nếu các chế độ cài đặt có độ mạnh thấp của các tham số điều chuẩn đó dẫn đến tình trạng khớp quá mức có vấn đề.
Việc giảm tình trạng khớp quá mức thường khá đơn giản khi sử dụng các kỹ thuật điều chỉnh phổ biến giúp giảm thiểu độ phức tạp của mã hoặc tăng thêm khả năng tính toán (ví dụ: điều chỉnh bằng cách loại bỏ, làm mượt nhãn, giảm trọng số). Do đó, bạn thường có thể dễ dàng thêm một hoặc nhiều mục tiêu trong số này vào vòng thử nghiệm tiếp theo. Ví dụ: nếu siêu tham số khoa học là "số lượng lớp ẩn" và thử nghiệm tốt nhất sử dụng số lượng lớp ẩn lớn nhất cho thấy tình trạng khớp quá mức có vấn đề, thì bạn nên thử lại với chế độ điều chỉnh bổ sung thay vì chọn ngay số lượng lớp ẩn nhỏ hơn.
Ngay cả khi không có thử nghiệm "tốt nhất" nào cho thấy tình trạng khớp quá mức có vấn đề, vẫn có thể xảy ra vấn đề nếu tình trạng này xuất hiện trong bất kỳ thử nghiệm nào. Việc chọn thử nghiệm tốt nhất sẽ loại bỏ những cấu hình có hiện tượng khớp quá mức gây ra vấn đề và ưu tiên những cấu hình không có hiện tượng này. Nói cách khác, việc chọn thử nghiệm tốt nhất sẽ ưu tiên các cấu hình có nhiều quy tắc hoá hơn. Tuy nhiên, bất cứ điều gì khiến quá trình huấn luyện trở nên tồi tệ hơn đều có thể đóng vai trò là một yếu tố điều chỉnh, ngay cả khi điều đó không phải là mục đích. Ví dụ: việc chọn tốc độ học tập nhỏ hơn có thể điều chỉnh quá trình huấn luyện bằng cách hạn chế quá trình tối ưu hoá, nhưng thông thường chúng ta không muốn chọn tốc độ học tập theo cách này. Xin lưu ý rằng "thử nghiệm" tốt nhất cho mỗi chế độ cài đặt của siêu tham số khoa học có thể được chọn theo cách ưu tiên các giá trị "xấu" của một số siêu tham số khoa học hoặc gây phiền toái.
Có sự khác biệt lớn giữa các bước trong quá trình huấn luyện hoặc lỗi xác thực muộn trong quá trình huấn luyện không? Nếu có, điều này có thể gây trở ngại cho cả hai điều sau:
- Khả năng so sánh các giá trị khác nhau của siêu tham số khoa học. Đó là do mỗi lượt thử nghiệm kết thúc ngẫu nhiên ở một bước "may mắn" hoặc "không may mắn".
- Khả năng tái tạo kết quả của thử nghiệm hiệu quả nhất trong quá trình sản xuất. Lý do là vì mô hình sản xuất có thể không kết thúc ở bước "may mắn" giống như trong nghiên cứu.
Sau đây là những nguyên nhân có nhiều khả năng gây ra sự chênh lệch giữa các bước:
- Phương sai theo lô do lấy mẫu ngẫu nhiên các ví dụ từ tập huấn luyện cho mỗi lô.
- Tập hợp xác thực nhỏ
- Sử dụng tốc độ học tập quá cao vào cuối quá trình huấn luyện.
Bạn có thể khắc phục bằng cách:
- Tăng kích thước lô.
- Thu thập thêm dữ liệu xác thực.
- Sử dụng tốc độ học giảm dần.
- Sử dụng phương pháp lấy trung bình Polyak.
Các lần thử có còn cải thiện vào cuối quá trình huấn luyện không? Nếu vậy, bạn đang ở chế độ "bị giới hạn về tính toán" và có thể hưởng lợi từ việc tăng số lượng bước huấn luyện hoặc thay đổi lịch trình tốc độ học.
Hiệu suất trên các tập hợp huấn luyện và xác thực có đạt đến mức tối đa từ rất lâu trước bước huấn luyện cuối cùng không? Nếu có, điều này cho thấy bạn đang ở chế độ "không bị giới hạn về tính toán" và bạn có thể giảm số lượng bước huấn luyện.
Ngoài danh sách này, bạn có thể thấy nhiều hành vi khác khi kiểm tra các đường cong tổn thất. Ví dụ: tổn thất huấn luyện tăng lên trong quá trình huấn luyện thường cho thấy có lỗi trong quy trình huấn luyện.
Phát hiện xem một thay đổi có hữu ích hay không bằng các biểu đồ riêng biệt
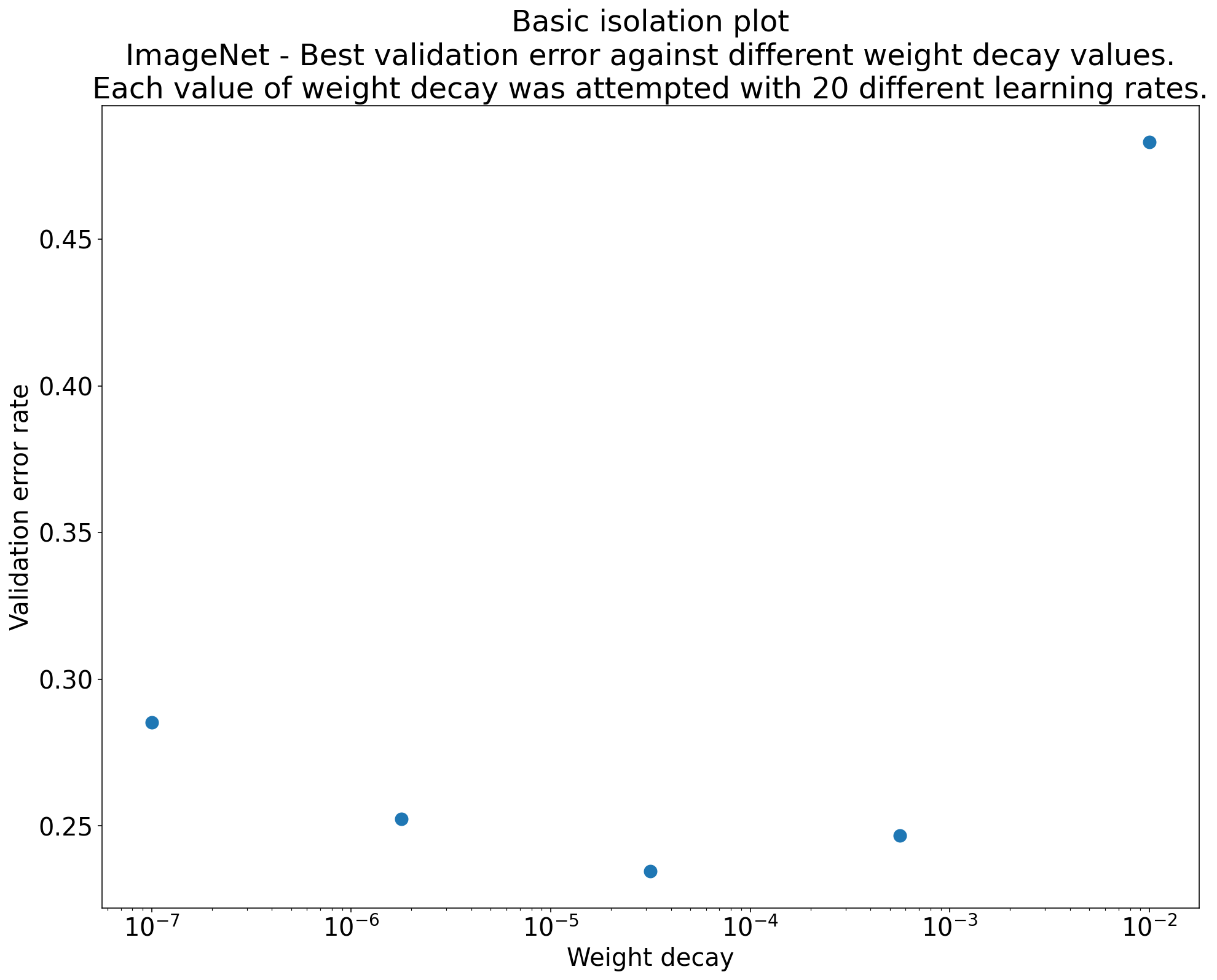
Hình 2: Biểu đồ cách ly nghiên cứu giá trị tốt nhất của độ trễ trọng số cho ResNet-50 được huấn luyện trên ImageNet.
Thông thường, mục tiêu của một nhóm thử nghiệm là so sánh các giá trị khác nhau của một siêu tham số khoa học. Ví dụ: giả sử bạn muốn xác định giá trị của hệ số phân rã trọng số dẫn đến lỗi xác thực tốt nhất. Biểu đồ cách ly là một trường hợp đặc biệt của biểu đồ trục siêu tham số cơ bản. Mỗi điểm trên biểu đồ cách ly tương ứng với hiệu suất của thử nghiệm tốt nhất trên một số (hoặc tất cả) siêu tham số gây phiền toái. Nói cách khác, hãy vẽ biểu đồ hiệu suất của mô hình sau khi "tối ưu hoá" các siêu tham số gây phiền toái.
Biểu đồ cách ly giúp đơn giản hoá việc so sánh tương đương giữa các giá trị khác nhau của siêu tham số khoa học. Ví dụ: biểu đồ cách ly trong Hình 2 cho thấy giá trị của độ giảm trọng số tạo ra hiệu suất xác thực tốt nhất cho một cấu hình cụ thể của ResNet-50 được huấn luyện trên ImageNet.
Nếu mục tiêu là xác định xem có nên đưa độ trễ trọng số vào hay không, hãy so sánh điểm tốt nhất từ biểu đồ này với đường cơ sở không có độ trễ trọng số. Để so sánh một cách công bằng, đường cơ sở cũng phải có tốc độ học tập được điều chỉnh tốt như nhau.
Khi có dữ liệu do tìm kiếm (gần) ngẫu nhiên tạo ra và đang cân nhắc một siêu tham số liên tục cho biểu đồ cách ly, bạn có thể ước chừng biểu đồ cách ly bằng cách phân loại các giá trị trên trục x của biểu đồ trục siêu tham số cơ bản và lấy thử nghiệm tốt nhất trong mỗi lát cắt dọc do các nhóm xác định.
Tự động hoá các biểu đồ hữu ích chung
Càng mất nhiều công sức để tạo ra các biểu đồ, thì bạn càng ít có khả năng xem xét chúng nhiều như bạn nên làm. Do đó, bạn nên thiết lập cơ sở hạ tầng để tự động tạo càng nhiều biểu đồ càng tốt. Ở mức tối thiểu, bạn nên tự động tạo các biểu đồ trục siêu tham số cơ bản cho tất cả các siêu tham số mà bạn thay đổi trong một thử nghiệm.
Ngoài ra, bạn nên tự động tạo đường cong tổn thất cho tất cả các thử nghiệm. Hơn nữa, bạn nên tìm cách dễ dàng nhất để tìm ra một vài thử nghiệm tốt nhất của mỗi nghiên cứu và xem xét đường cong tổn thất của chúng.
Bạn có thể thêm nhiều biểu đồ và hình ảnh trực quan hữu ích khác. Diễn giải lời của Geoffrey Hinton:
Mỗi lần bạn vẽ một thứ gì đó mới, bạn sẽ học được điều gì đó mới.
Xác định xem có nên áp dụng thay đổi đề xuất hay không
Tóm tắt: Khi quyết định có nên thay đổi mô hình hoặc quy trình huấn luyện hay áp dụng cấu hình siêu tham số mới, hãy lưu ý đến các nguồn biến động khác nhau trong kết quả của bạn.
Khi cố gắng cải thiện một mô hình, một thay đổi cụ thể có thể ban đầu đạt được lỗi xác thực tốt hơn so với cấu hình hiện tại. Tuy nhiên, việc lặp lại thử nghiệm có thể không mang lại lợi thế nhất quán. Một cách không chính thức, các nguồn quan trọng nhất gây ra kết quả không nhất quán có thể được nhóm thành các danh mục chung sau:
- Phương sai của quy trình huấn luyện, phương sai của việc huấn luyện lại hoặc phương sai của thử nghiệm: sự khác biệt giữa các lần huấn luyện sử dụng cùng siêu tham số nhưng các hạt giống ngẫu nhiên khác nhau. Ví dụ: các hoạt động khởi tạo ngẫu nhiên, xáo trộn dữ liệu huấn luyện, mặt nạ bỏ qua, mẫu của các hoạt động tăng cường dữ liệu và thứ tự của các hoạt động số học song song đều là những nguồn tiềm năng của phương sai thử nghiệm.
- Phương sai tìm kiếm siêu tham số hoặc phương sai nghiên cứu: sự biến thiên trong kết quả do quy trình chọn siêu tham số của chúng tôi gây ra. Ví dụ: bạn có thể chạy cùng một thử nghiệm với một không gian tìm kiếm cụ thể nhưng có 2 giá trị ban đầu khác nhau cho tìm kiếm gần ngẫu nhiên và cuối cùng chọn các giá trị siêu tham số khác nhau.
- Phương sai của việc lấy mẫu và thu thập dữ liệu: phương sai từ bất kỳ loại phân chia ngẫu nhiên nào thành dữ liệu huấn luyện, xác thực và kiểm thử hoặc phương sai do quy trình tạo dữ liệu huấn luyện nói chung.
Đúng vậy, bạn có thể so sánh tỷ lệ lỗi xác thực ước tính trên một tập hợp xác thực hữu hạn bằng cách sử dụng các kiểm định thống kê tỉ mỉ. Tuy nhiên, thường thì chỉ riêng phương sai của thử nghiệm có thể tạo ra sự khác biệt có ý nghĩa thống kê giữa hai mô hình được huấn luyện khác nhau sử dụng cùng chế độ cài đặt siêu tham số.
Chúng tôi lo ngại nhất về sự khác biệt trong nghiên cứu khi cố gắng đưa ra kết luận vượt quá mức của một điểm riêng lẻ trong không gian siêu tham số. Phương sai của nghiên cứu phụ thuộc vào số lượng thử nghiệm và không gian tìm kiếm. Chúng tôi đã ghi nhận những trường hợp phương sai của nghiên cứu lớn hơn phương sai của thử nghiệm và những trường hợp phương sai của nghiên cứu nhỏ hơn nhiều. Do đó, trước khi áp dụng một thay đổi đề xuất, hãy cân nhắc chạy thử nghiệm tốt nhất N lần để xác định đặc điểm của phương sai thử nghiệm giữa các lần chạy. Thông thường, bạn chỉ cần mô tả lại phương sai của thử nghiệm sau khi có những thay đổi lớn đối với quy trình, nhưng trong một số trường hợp, bạn có thể cần ước tính mới hơn. Trong các ứng dụng khác, việc mô tả phương sai của thử nghiệm quá tốn kém nên không đáng.
Mặc dù bạn chỉ muốn áp dụng những thay đổi (bao gồm cả cấu hình siêu tham số mới) mang lại những cải tiến thực sự, nhưng việc yêu cầu sự chắc chắn hoàn toàn rằng một thay đổi nhất định sẽ giúp ích cũng không phải là câu trả lời đúng. Do đó, nếu một điểm siêu tham số mới (hoặc thay đổi khác) mang lại kết quả tốt hơn so với đường cơ sở (có tính đến phương sai huấn luyện lại của cả điểm mới và đường cơ sở trong khả năng tốt nhất có thể), thì bạn nên áp dụng điểm đó làm đường cơ sở mới cho các hoạt động so sánh trong tương lai. Tuy nhiên, bạn chỉ nên áp dụng những thay đổi mang lại những điểm cải tiến vượt trội so với mọi sự phức tạp mà chúng mang lại.
Sau khi quá trình khám phá kết thúc
Tóm tắt: Các công cụ tối ưu hoá theo phương pháp Bayes là một lựa chọn hấp dẫn sau khi bạn hoàn tất việc tìm kiếm các không gian tìm kiếm phù hợp và đã quyết định những siêu tham số nào đáng điều chỉnh.
Cuối cùng, các ưu tiên của bạn sẽ chuyển từ việc tìm hiểu thêm về vấn đề điều chỉnh sang việc tạo ra một cấu hình tốt nhất để khởi chạy hoặc sử dụng. Tại thời điểm đó, phải có một không gian tìm kiếm tinh tế, chứa đựng thoải mái khu vực địa phương xung quanh thử nghiệm được quan sát tốt nhất và đã được lấy mẫu đầy đủ. Công việc khám phá của bạn sẽ cho thấy các siêu tham số quan trọng nhất cần điều chỉnh và các phạm vi hợp lý mà bạn có thể sử dụng để tạo không gian tìm kiếm cho một nghiên cứu điều chỉnh tự động cuối cùng bằng cách sử dụng ngân sách điều chỉnh lớn nhất có thể.
Vì bạn không còn quan tâm đến việc tối đa hoá thông tin chi tiết về vấn đề điều chỉnh, nên nhiều lợi thế của tìm kiếm gần ngẫu nhiên không còn áp dụng được nữa. Do đó, bạn nên sử dụng các công cụ tối ưu hoá theo phương pháp Bayes để tự động tìm ra cấu hình siêu tham số phù hợp nhất. Vizier nguồn mở triển khai nhiều thuật toán tinh vi để điều chỉnh các mô hình học máy, bao gồm cả các thuật toán Tối ưu hoá theo Bayes.
Giả sử không gian tìm kiếm chứa một lượng đáng kể các điểm phân kỳ, tức là các điểm nhận được tổn thất huấn luyện NaN hoặc thậm chí tổn thất huấn luyện tệ hơn nhiều độ lệch chuẩn so với giá trị trung bình. Trong trường hợp này, bạn nên sử dụng các công cụ tối ưu hoá hộp đen để xử lý đúng những thử nghiệm khác biệt. (Hãy xem bài viết Tối ưu hoá theo phương pháp Bayes với các ràng buộc chưa biết để biết một cách hiệu quả để giải quyết vấn đề này.) Vizier mã nguồn mở hỗ trợ đánh dấu các điểm khác biệt bằng cách đánh dấu các thử nghiệm là không khả thi, mặc dù có thể không sử dụng phương pháp ưu tiên của chúng tôi từ Gelbart và cộng sự, tuỳ thuộc vào cách được định cấu hình.
Sau khi quá trình khám phá kết thúc, hãy cân nhắc kiểm tra hiệu suất trên tập hợp kiểm thử. Về nguyên tắc, bạn thậm chí có thể gộp tập hợp xác thực vào tập hợp huấn luyện và huấn luyện lại cấu hình tốt nhất tìm được bằng phương pháp tối ưu hoá Bayesian. Tuy nhiên, bạn chỉ nên làm như vậy nếu không có các lần ra mắt trong tương lai với khối lượng công việc cụ thể này (ví dụ: cuộc thi Kaggle một lần).