Dans le cadre du présent document :
L'objectif ultime du développement du machine learning est de maximiser l'utilité du modèle déployé.
Vous pouvez généralement utiliser les mêmes étapes et principes de base de cette section pour n'importe quel problème de ML.
Cette section repose sur les hypothèses suivantes :
- Vous disposez déjà d'un pipeline d'entraînement entièrement opérationnel et d'une configuration qui permet d'obtenir un résultat raisonnable.
- Vous disposez de suffisamment de ressources de calcul pour effectuer des expériences de réglage significatives et exécuter au moins plusieurs jobs d'entraînement en parallèle.
Stratégie d'ajustement incrémentiel
Recommandation : Commencez par une configuration simple. Ensuite, apportez des améliorations progressives tout en approfondissant votre compréhension du problème. Assurez-vous que toute amélioration est basée sur des preuves solides.
Nous partons du principe que votre objectif est de trouver une configuration qui maximise les performances de votre modèle. Parfois, votre objectif est de maximiser l'amélioration du modèle d'ici une date limite fixe. Dans d'autres cas, vous pouvez continuer à améliorer le modèle indéfiniment, par exemple en améliorant continuellement un modèle utilisé en production.
En principe, vous pourriez maximiser les performances en utilisant un algorithme pour rechercher automatiquement l'ensemble des configurations possibles, mais il ne s'agit pas d'une option pratique. L'espace des configurations possibles est extrêmement vaste et il n'existe pas encore d'algorithmes suffisamment sophistiqués pour rechercher efficacement cet espace sans intervention humaine. La plupart des algorithmes de recherche automatisés s'appuient sur un espace de recherche conçu manuellement qui définit l'ensemble des configurations dans lesquelles effectuer la recherche. Ces espaces de recherche peuvent avoir une grande importance.
Pour maximiser les performances, le moyen le plus efficace consiste à commencer par une configuration simple, puis à ajouter progressivement des fonctionnalités et à apporter des améliorations tout en approfondissant votre compréhension du problème.
Nous vous recommandons d'utiliser des algorithmes de recherche automatisés à chaque cycle d'optimisation et de mettre à jour en permanence les espaces de recherche à mesure que vous en apprenez davantage. En explorant, vous trouverez naturellement des configurations de plus en plus performantes. Votre "meilleur" modèle s'améliorera donc en permanence.
Le terme "lancement" fait référence à une mise à jour de notre meilleure configuration (qui peut ou non correspondre au lancement réel d'un modèle de production). Pour chaque "lancement", vous devez vous assurer que le changement est basé sur des preuves solides, et non sur une chance aléatoire basée sur une configuration chanceuse, afin de ne pas ajouter de complexité inutile au pipeline d'entraînement.
De manière générale, notre stratégie d'ajustement incrémentiel consiste à répéter les quatre étapes suivantes :
- Choisissez un objectif pour la prochaine série de tests. Assurez-vous que l'objectif est correctement défini.
- Concevez la prochaine série de tests. Concevez et exécutez un ensemble de tests qui vous permettront d'atteindre cet objectif.
- Tirez des enseignements des résultats expérimentaux. Évaluez le test à l'aide d'une checklist.
- Déterminez si vous souhaitez adopter la modification suggérée.
Le reste de cette section détaille cette stratégie.
Choisir un objectif pour la prochaine série de tests
Si vous essayez d'ajouter plusieurs fonctionnalités ou de répondre à plusieurs questions à la fois, vous risquez de ne pas pouvoir distinguer les effets distincts sur les résultats. Voici quelques exemples d'objectifs :
- Essayez une amélioration potentielle du pipeline (par exemple, un nouveau régularisateur, un nouveau choix de prétraitement, etc.).
- Comprendre l'impact d'un hyperparamètre de modèle spécifique (par exemple, la fonction d'activation)
- Minimisez l'erreur de validation.
Privilégier les progrès à long terme plutôt que les améliorations à court terme des erreurs de validation
Résumé : La plupart du temps, votre objectif principal est d'obtenir des informations sur le problème de réglage.
Nous vous recommandons de consacrer la majorité de votre temps à comprendre le problème et relativement peu de temps à maximiser les performances sur l'ensemble de validation. En d'autres termes, consacrez la majeure partie de votre temps à l'exploration et seulement une petite partie à l'exploitation. Comprendre le problème est essentiel pour maximiser les performances finales. Privilégier les insights par rapport aux gains à court terme permet :
- Évitez de lancer des modifications inutiles qui se sont produites dans des exécutions performantes par simple hasard historique.
- Identifier les hyperparamètres auxquels l'erreur de validation est la plus sensible, ceux qui interagissent le plus et doivent donc être réajustés ensemble, et ceux qui sont relativement insensibles aux autres modifications et peuvent donc être corrigés lors de futurs tests.
- Suggérer de nouvelles fonctionnalités potentielles à essayer, comme de nouveaux régulariseurs en cas de surapprentissage.
- Identifier les caractéristiques qui ne sont pas utiles et qui peuvent donc être supprimées, ce qui réduit la complexité des futurs tests.
- Identifier le moment où les améliorations apportées par le réglage des hyperparamètres ont probablement atteint leur limite
- Réduisez nos espaces de recherche autour de la valeur optimale pour améliorer l'efficacité du réglage.
Vous finirez par comprendre le problème. Vous pouvez ensuite vous concentrer uniquement sur l'erreur de validation, même si les expériences ne sont pas très informatives sur la structure du problème d'optimisation.
Concevoir la prochaine série de tests
Résumé : identifiez les hyperparamètres scientifiques, de nuisance et fixes pour l'objectif expérimental. Créez une séquence d'études pour comparer différentes valeurs des hyperparamètres scientifiques tout en optimisant les hyperparamètres de nuisance. Choisissez l'espace de recherche des hyperparamètres de nuisance pour équilibrer les coûts des ressources et la valeur scientifique.
Identifier les hyperparamètres scientifiques, de nuisance et fixes
Pour un objectif donné, tous les hyperparamètres appartiennent à l'une des catégories suivantes :
- Les hyperparamètres scientifiques sont ceux dont vous essayez de mesurer l'effet sur les performances du modèle.
- Les hyperparamètres de nuisance sont ceux qui doivent être optimisés pour comparer équitablement différentes valeurs des hyperparamètres scientifiques. Les hyperparamètres de nuisance sont semblables aux paramètres de nuisance en statistiques.
- Les hyperparamètres fixes ont des valeurs constantes dans la série actuelle d'expériences. Les valeurs des hyperparamètres fixes ne doivent pas changer lorsque vous comparez différentes valeurs d'hyperparamètres scientifiques. En fixant certains hyperparamètres pour un ensemble d'expériences, vous devez accepter que les conclusions tirées des expériences ne soient pas valides pour d'autres paramètres des hyperparamètres fixes. En d'autres termes, les hyperparamètres fixes créent des mises en garde pour toutes les conclusions que vous tirez des tests.
Par exemple, supposons que votre objectif soit le suivant :
Déterminez si un modèle avec plus de couches cachées présente une erreur de validation plus faible.
Dans ce cas :
- Le taux d'apprentissage est un hyperparamètre de nuisance, car vous ne pouvez comparer équitablement des modèles avec différents nombres de couches masquées que si le taux d'apprentissage est ajusté séparément pour chaque nombre de couches masquées. (Le taux d'apprentissage optimal dépend généralement de l'architecture du modèle.)
- La fonction d'activation peut être un hyperparamètre fixe si vous avez déterminé lors d'expériences précédentes que la meilleure fonction d'activation n'est pas sensible à la profondeur du modèle. Vous êtes également prêt à limiter vos conclusions sur le nombre de couches cachées pour couvrir cette fonction d'activation. Il peut également s'agir d'un hyperparamètre de nuisance si vous êtes prêt à l'ajuster séparément pour chaque nombre de couches cachées.
Un hyperparamètre particulier peut être un hyperparamètre scientifique, un hyperparamètre de nuisance ou un hyperparamètre fixe. La désignation de l'hyperparamètre change en fonction de l'objectif expérimental. Par exemple, la fonction d'activation peut être l'une des suivantes :
- Hyperparamètre scientifique : ReLU ou tanh, quel est le meilleur choix pour notre problème ?
- Hyperparamètre de nuisance : le meilleur modèle à cinq couches est-il meilleur que le meilleur modèle à six couches lorsque vous autorisez plusieurs fonctions d'activation possibles ?
- Hyperparamètre fixe : pour les réseaux ReLU, l'ajout d'une normalisation par lot à un emplacement particulier est-il utile ?
Lorsque vous concevez une nouvelle série de tests :
- Identifiez les hyperparamètres scientifiques pour l'objectif expérimental. (À ce stade, vous pouvez considérer tous les autres hyperparamètres comme des hyperparamètres de nuisance.)
- Convertissez certains hyperparamètres de nuisance en hyperparamètres fixes.
Avec des ressources illimitées, vous laisserez tous les hyperparamètres non scientifiques en tant qu'hyperparamètres de nuisance afin que les conclusions que vous tirez de vos expériences soient exemptes de mises en garde concernant les valeurs d'hyperparamètres fixes. Toutefois, plus vous essayez de régler d'hyperparamètres de nuisance, plus vous risquez de ne pas les régler suffisamment bien pour chaque paramètre des hyperparamètres scientifiques et de tirer des conclusions erronées de vos expériences. Comme décrit dans une section ultérieure, vous pouvez contrer ce risque en augmentant le budget de calcul. Toutefois, votre budget de ressources maximal est souvent inférieur à celui nécessaire pour ajuster tous les hyperparamètres non scientifiques.
Nous vous recommandons de convertir un hyperparamètre de nuisance en hyperparamètre fixe lorsque les inconvénients liés à sa fixation sont moins contraignants que le coût de son inclusion en tant qu'hyperparamètre de nuisance. Plus un hyperparamètre de nuisance interagit avec les hyperparamètres scientifiques, plus il est dommageable de fixer sa valeur. Par exemple, la meilleure valeur de l'intensité de la régularisation de poids dépend généralement de la taille du modèle. Par conséquent, comparer différentes tailles de modèle en supposant une seule valeur spécifique de la régularisation de poids ne serait pas très instructif.
Certains paramètres de l'optimiseur
En règle générale, certains hyperparamètres d'optimiseur (par exemple, le taux d'apprentissage, le momentum, les paramètres de programmation du taux d'apprentissage, les bêtas Adam, etc.) sont des hyperparamètres de nuisance, car ils ont tendance à interagir le plus avec d'autres modifications. Ces hyperparamètres d'optimiseur sont rarement des hyperparamètres scientifiques, car un objectif tel que "quel est le meilleur taux d'apprentissage pour le pipeline actuel ?" ne fournit pas beaucoup d'informations. Après tout, le meilleur paramètre pourrait changer avec la prochaine modification du pipeline.
Vous pouvez parfois corriger certains hyperparamètres de l'optimiseur en raison de contraintes de ressources ou de preuves particulièrement solides qu'ils n'interagissent pas avec les paramètres scientifiques. Toutefois, vous devez généralement supposer que vous devez régler les hyperparamètres de l'optimiseur séparément pour effectuer des comparaisons équitables entre les différents paramètres des hyperparamètres scientifiques. Ils ne doivent donc pas être corrigés. De plus, il n'y a aucune raison a priori de préférer une valeur d'hyperparamètre d'optimiseur à une autre. Par exemple, les valeurs d'hyperparamètre d'optimiseur n'affectent généralement pas le coût de calcul des passes directes ni des gradients.
Choix de l'optimiseur
Le choix de l'optimiseur est généralement l'un des suivants :
- un hyperparamètre scientifique.
- un hyperparamètre fixe
Un optimiseur est un hyperparamètre scientifique si votre objectif expérimental consiste à comparer équitablement deux ou plusieurs optimiseurs différents. Exemple :
Déterminez l'optimiseur qui produit l'erreur de validation la plus faible pour un nombre d'étapes donné.
Vous pouvez également faire de l'optimiseur un hyperparamètre fixe pour diverses raisons, y compris :
- Les tests précédents suggèrent que l'optimiseur le mieux adapté à votre problème de réglage n'est pas sensible aux hyperparamètres scientifiques actuels.
- Vous préférez comparer les valeurs des hyperparamètres scientifiques à l'aide de cet optimiseur, car ses courbes d'entraînement sont plus faciles à interpréter.
- Vous préférez utiliser cet optimiseur, car il utilise moins de mémoire que les autres.
Hyperparamètres de régularisation
Les hyperparamètres introduits par une technique de régularisation sont généralement des hyperparamètres de nuisance. Toutefois, le choix d'inclure ou non la technique de régularisation est un hyperparamètre scientifique ou fixe.
Par exemple, la régularisation par abandon ajoute de la complexité au code. Par conséquent, lorsque vous décidez d'inclure ou non la régularisation par abandon, vous pouvez faire de "pas d'abandon" vs "abandon" un hyperparamètre scientifique, mais du taux d'abandon un hyperparamètre de nuisance. Si vous décidez d'ajouter une régularisation par abandon au pipeline en fonction de ce test, le taux d'abandon sera un hyperparamètre de nuisance dans les futurs tests.
Hyperparamètres architecturaux
Les hyperparamètres architecturaux sont souvent des hyperparamètres scientifiques ou fixes, car les modifications de l'architecture peuvent affecter les coûts de diffusion et d'entraînement, la latence et les besoins en mémoire. Par exemple, le nombre de couches est généralement un hyperparamètre scientifique ou fixe, car il a tendance à avoir des conséquences importantes sur la vitesse d'entraînement et l'utilisation de la mémoire.
Dépendances vis-à-vis des hyperparamètres scientifiques
Dans certains cas, les ensembles d'hyperparamètres de nuisance et fixes dépendent des valeurs des hyperparamètres scientifiques. Par exemple, supposons que vous essayiez de déterminer quel optimiseur dans le momentum de Nesterov et Adam produit l'erreur de validation la plus faible. Dans ce cas :
- L'hyperparamètre scientifique est l'optimiseur, qui prend les valeurs
{"Nesterov_momentum", "Adam"}. - La valeur
optimizer="Nesterov_momentum"introduit les hyperparamètres{learning_rate, momentum}, qui peuvent être des hyperparamètres de nuisance ou fixes. - La valeur
optimizer="Adam"introduit les hyperparamètres{learning_rate, beta1, beta2, epsilon}, qui peuvent être des hyperparamètres de nuisance ou fixes.
Les hyperparamètres qui ne sont présents que pour certaines valeurs des hyperparamètres scientifiques sont appelés hyperparamètres conditionnels.
Ne partez pas du principe que deux hyperparamètres conditionnels sont identiques simplement parce qu'ils portent le même nom. Dans l'exemple précédent, l'hyperparamètre conditionnel appelé learning_rate est un hyperparamètre différent pour optimizer="Nesterov_momentum" et pour optimizer="Adam". Son rôle est similaire (mais pas identique) dans les deux algorithmes, mais la plage de valeurs qui fonctionnent bien dans chacun des optimiseurs est généralement différente de plusieurs ordres de grandeur.
Créer un ensemble d'études
Après avoir identifié les hyperparamètres scientifiques et de nuisance, vous devez concevoir une étude ou une séquence d'études pour progresser vers l'objectif expérimental. Une étude spécifie un ensemble de configurations d'hyperparamètres à exécuter pour une analyse ultérieure. Chaque configuration est appelée essai. Pour créer une étude, vous devez généralement choisir les éléments suivants :
- Les hyperparamètres qui varient d'un essai à l'autre.
- Les valeurs que ces hyperparamètres peuvent prendre (l'espace de recherche).
- Nombre d'essais.
- Un algorithme de recherche automatisé pour échantillonner autant d'essais à partir de l'espace de recherche.
Vous pouvez également créer une étude en spécifiant manuellement l'ensemble des configurations d'hyperparamètres.
L'objectif des études est de :
- Exécutez le pipeline avec différentes valeurs des hyperparamètres scientifiques.
- "Optimiser" (ou "optimiser sur") les hyperparamètres de nuisance afin que les comparaisons entre différentes valeurs des hyperparamètres scientifiques soient aussi équitables que possible.
Dans le cas le plus simple, vous effectuez une étude distincte pour chaque configuration des paramètres scientifiques, où chaque étude ajuste les hyperparamètres de nuisance. Par exemple, si votre objectif est de sélectionner le meilleur optimiseur entre le momentum de Nesterov et Adam, vous pouvez créer deux études :
- Une étude dans laquelle
optimizer="Nesterov_momentum"et les hyperparamètres de nuisance sont{learning_rate, momentum} - Autre étude dans laquelle
optimizer="Adam"et les hyperparamètres de nuisance sont{learning_rate, beta1, beta2, epsilon}.
Pour comparer les deux optimiseurs, vous devez sélectionner le meilleur essai de chaque étude.
Vous pouvez utiliser n'importe quel algorithme d'optimisation sans gradient, y compris des méthodes telles que l'optimisation bayésienne ou les algorithmes évolutionnistes, pour optimiser les hyperparamètres de nuisance. Toutefois, nous préférons utiliser la recherche quasi aléatoire dans la phase d'exploration du réglage en raison des nombreux avantages qu'elle présente dans ce contexte. Une fois l'exploration terminée, nous vous recommandons d'utiliser un logiciel d'optimisation bayésienne de pointe (si disponible).
Prenons un cas plus complexe où vous souhaitez comparer un grand nombre de valeurs d'hyperparamètres scientifiques, mais où il n'est pas pratique de réaliser autant d'études indépendantes. Dans ce cas, vous pouvez procéder comme suit :
- Incluez les paramètres scientifiques dans le même espace de recherche que les hyperparamètres de nuisance.
- Utilisez un algorithme de recherche pour échantillonner les valeurs des hyperparamètres scientifiques et de nuisance dans une même étude.
Cette approche peut poser problème avec les hyperparamètres conditionnels. En effet, il est difficile de spécifier un espace de recherche, sauf si l'ensemble des hyperparamètres de nuisance est le même pour toutes les valeurs des hyperparamètres scientifiques. Dans ce cas, notre préférence pour l'utilisation de la recherche quasi aléatoire plutôt que d'outils d'optimisation de boîte noire plus sophistiqués est encore plus forte, car elle garantit que différentes valeurs des hyperparamètres scientifiques seront échantillonnées de manière uniforme. Quel que soit l'algorithme de recherche, assurez-vous qu'il recherche les paramètres scientifiques de manière uniforme.
Trouver le bon équilibre entre des tests informatifs et abordables
Lorsque vous concevez une étude ou une séquence d'études, allouez un budget limité pour atteindre correctement les trois objectifs suivants :
- Comparer suffisamment de valeurs différentes des hyperparamètres scientifiques.
- Réglez les hyperparamètres de nuisance sur un espace de recherche suffisamment grand.
- Échantillonner l'espace de recherche des hyperparamètres de nuisance de manière suffisamment dense.
Plus vous parviendrez à atteindre ces trois objectifs, plus vous pourrez extraire d'insights du test. Comparer autant de valeurs d'hyperparamètres scientifiques que possible élargit la portée des insights que vous obtenez du test.
Inclure le plus grand nombre possible d'hyperparamètres de nuisance et permettre à chacun d'eux de varier sur la plage la plus large possible augmente la confiance qu'une "bonne" valeur des hyperparamètres de nuisance existe dans l'espace de recherche pour chaque configuration des hyperparamètres scientifiques. Sinon, vous risquez de faire des comparaisons injustes entre les valeurs des hyperparamètres scientifiques en ne recherchant pas les régions possibles de l'espace des hyperparamètres de nuisance où de meilleures valeurs pourraient se trouver pour certaines valeurs des paramètres scientifiques.
Échantillonnez l'espace de recherche des hyperparamètres de nuisance aussi densément que possible. Cela permet d'être plus sûr que la procédure de recherche trouvera les bons paramètres pour les hyperparamètres de nuisance qui existent dans votre espace de recherche. Sinon, vous risquez de faire des comparaisons injustes entre les valeurs des paramètres scientifiques, car certaines valeurs auront plus de chance avec l'échantillonnage des hyperparamètres de nuisance.
Malheureusement, pour améliorer l'une de ces trois dimensions, vous devez effectuer l'une des opérations suivantes :
- Augmenter le nombre d'essais, et donc le coût des ressources.
- Trouver un moyen d'économiser des ressources dans l'une des autres dimensions.
Chaque problème a ses propres spécificités et contraintes de calcul. L'allocation de ressources pour ces trois objectifs nécessite donc un certain niveau de connaissances du domaine. Après avoir exécuté une étude, essayez toujours de déterminer si les hyperparamètres de nuisance ont été suffisamment ajustés. En d'autres termes, l'étude a recherché un espace suffisamment grand et de manière suffisamment approfondie pour comparer équitablement les hyperparamètres scientifiques (comme décrit plus en détail dans la section suivante).
Tirer des enseignements des résultats expérimentaux
Recommandation : En plus d'essayer d'atteindre l'objectif scientifique initial de chaque groupe de tests, parcourez une liste de questions supplémentaires. Si vous identifiez des problèmes, corrigez-les et relancez les tests.
En fin de compte, chaque groupe d'expériences a un objectif spécifique. Vous devez évaluer les preuves fournies par les tests pour atteindre cet objectif. Toutefois, si vous posez les bonnes questions, vous pouvez souvent identifier les problèmes à corriger avant qu'un ensemble de tests donné puisse progresser vers son objectif initial. Si vous ne posez pas ces questions, vous risquez de tirer des conclusions incorrectes.
Comme les tests peuvent être coûteux, vous devez également extraire d'autres insights utiles de chaque groupe de tests, même s'ils ne sont pas immédiatement pertinents pour l'objectif actuel.
Avant d'analyser un ensemble de tests donné pour progresser vers leur objectif initial, posez-vous les questions supplémentaires suivantes :
- L'espace de recherche est-il suffisamment grand ? Si le point optimal d'une étude se trouve près de la limite de l'espace de recherche dans une ou plusieurs dimensions, la recherche n'est probablement pas assez large. Dans ce cas, exécutez une autre étude avec un espace de recherche étendu.
- Avez-vous échantillonné suffisamment de points dans l'espace de recherche ? Si ce n'est pas le cas, exécutez plus de points ou soyez moins ambitieux dans les objectifs de réglage.
- Quelle est la fraction des essais infaisables dans chaque étude ? Autrement dit, quels essais divergent, obtiennent des valeurs de perte très mauvaises ou ne parviennent pas à s'exécuter du tout, car ils enfreignent une contrainte implicite ? Lorsqu'une très grande partie des points d'une étude sont irréalisables, ajustez l'espace de recherche pour éviter d'échantillonner ces points, ce qui nécessite parfois de reparamétrer l'espace de recherche. Dans certains cas, un grand nombre de points infaisables peut indiquer un bug dans le code d'entraînement.
- Le modèle présente-t-il des problèmes d'optimisation ?
- Quels enseignements pouvez-vous tirer des courbes d'entraînement des meilleurs essais ? Par exemple, les meilleurs essais ont-ils des courbes d'entraînement cohérentes avec un surapprentissage problématique ?
Si nécessaire, en fonction des réponses aux questions précédentes, affinez la dernière étude ou le dernier groupe d'études pour améliorer l'espace de recherche et/ou échantillonner davantage d'essais, ou prenez une autre mesure corrective.
Une fois que vous avez répondu aux questions précédentes, vous pouvez évaluer les preuves fournies par les tests par rapport à votre objectif initial. Par exemple, vous pouvez évaluer l'utilité d'un changement.
Identifier les limites d'espace de recherche incorrectes
Un espace de recherche est suspect si le meilleur point échantillonné à partir de celui-ci est proche de sa limite. Vous trouverez peut-être un point encore meilleur si vous élargissez la plage de recherche dans cette direction.
Pour vérifier les limites de l'espace de recherche, nous vous recommandons de représenter les essais terminés sur ce que nous appelons des graphiques d'axes d'hyperparamètres de base. Dans ces graphiques, nous représentons la valeur objective de validation par rapport à l'un des hyperparamètres (par exemple, le taux d'apprentissage). Chaque point du graphique correspond à un essai unique.
La valeur de l'objectif de validation pour chaque essai doit généralement être la meilleure valeur obtenue au cours de l'entraînement.
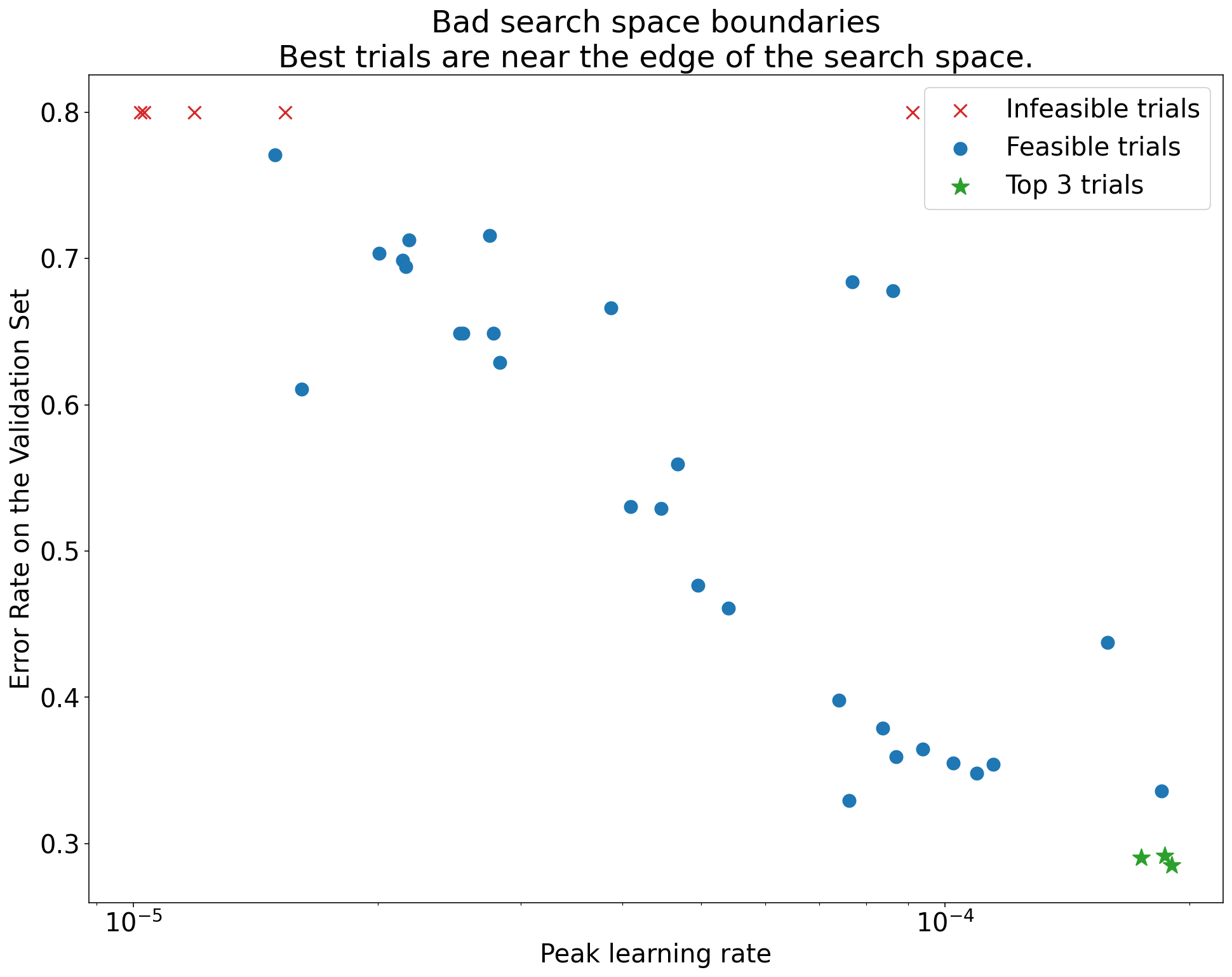
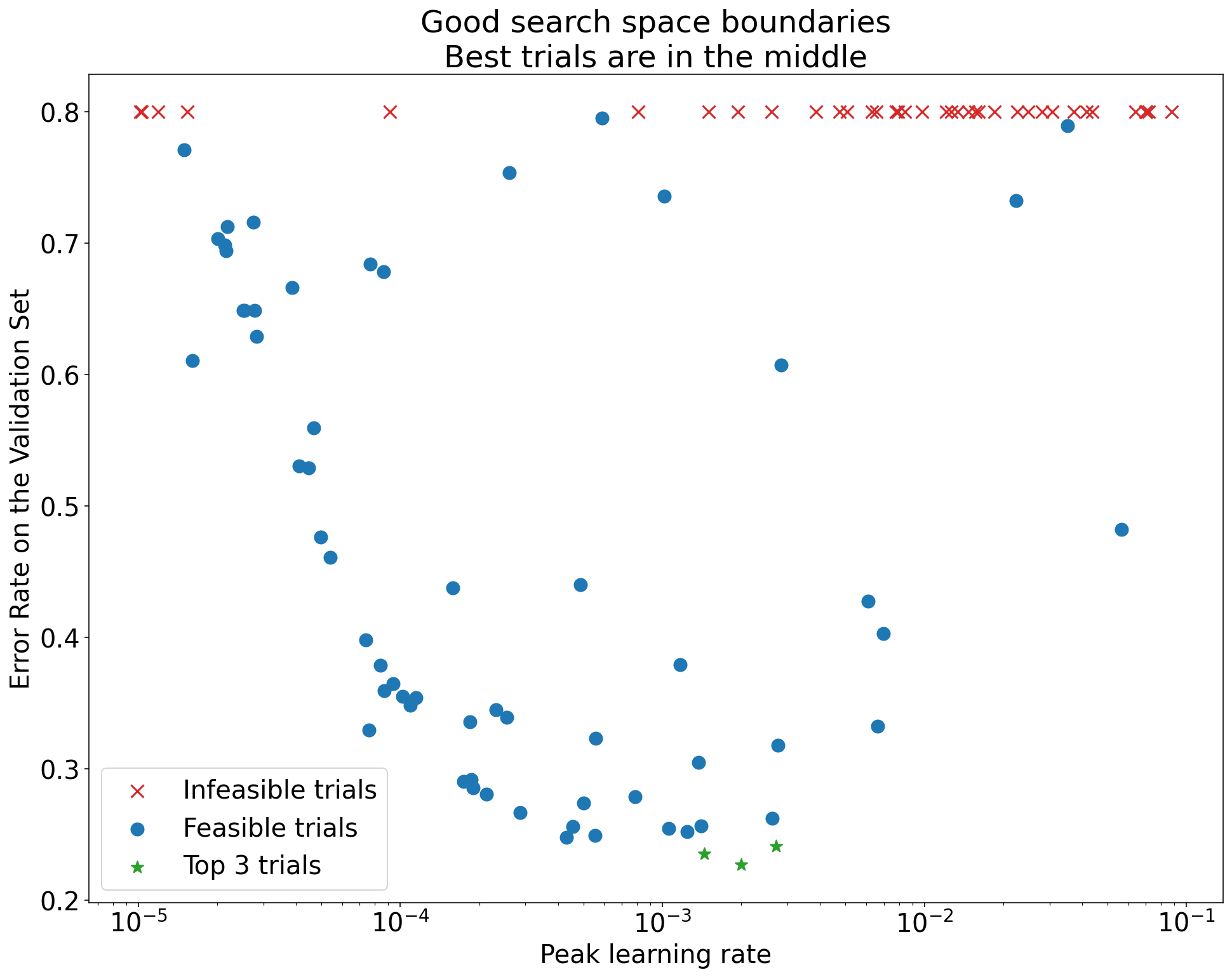
Figure 1 : Exemples de limites d'espace de recherche incorrectes et acceptables.
Les graphiques de la figure 1 montrent le taux d'erreur (plus il est faible, mieux c'est) par rapport au taux d'apprentissage initial. Si les meilleurs points sont regroupés vers le bord d'un espace de recherche (dans une dimension), vous devrez peut-être étendre les limites de l'espace de recherche jusqu'à ce que le meilleur point observé ne soit plus proche de la limite.
Souvent, une étude inclut des essais "infaisables" qui divergent ou donnent de très mauvais résultats (marqués par des croix rouges sur la figure 1). Si tous les essais sont infaisables pour des taux d'apprentissage supérieurs à une certaine valeur seuil, et si les essais les plus performants ont des taux d'apprentissage à la limite de cette région, le modèle peut souffrir de problèmes de stabilité qui l'empêchent d'accéder à des taux d'apprentissage plus élevés.
Échantillonnage insuffisant de points dans l'espace de recherche
En général, il peut être très difficile de savoir si l'espace de recherche a été échantillonné de manière suffisamment dense. 🤖 Il est préférable d'exécuter plus d'essais que moins, mais cela génère évidemment des coûts supplémentaires.
Étant donné qu'il est difficile de savoir quand vous avez échantillonné suffisamment de données, nous vous recommandons de procéder comme suit :
- Échantillonnez ce que vous pouvez vous permettre.
- Calibrer votre confiance intuitive en examinant à plusieurs reprises différents graphiques d'axes d'hyperparamètres et en essayant de déterminer le nombre de points dans la région "bonne" de l'espace de recherche.
Examiner les courbes d'entraînement
Résumé : Examiner les courbes de perte est un moyen simple d'identifier les modes de défaillance courants et peut vous aider à hiérarchiser les prochaines actions potentielles.
Dans de nombreux cas, l'objectif principal de vos tests ne nécessite que de prendre en compte l'erreur de validation de chaque essai. Toutefois, soyez prudent lorsque vous réduisez chaque essai à un seul nombre, car cela peut masquer des détails importants sur ce qui se passe en dessous de la surface. Pour chaque étude, nous vous recommandons vivement d'examiner les courbes de perte d'au moins les meilleures tentatives. Même si cela n'est pas nécessaire pour atteindre l'objectif expérimental principal, l'examen des courbes de perte (y compris la perte d'entraînement et la perte de validation) est un bon moyen d'identifier les modes de défaillance courants et peut vous aider à déterminer les actions à entreprendre ensuite.
Lorsque vous examinez les courbes de perte, concentrez-vous sur les questions suivantes :
Certains essais présentent-ils un surapprentissage problématique ? Le surapprentissage problématique se produit lorsque l'erreur de validation commence à augmenter pendant l'entraînement. Dans les paramètres expérimentaux où vous optimisez les hyperparamètres de nuisance en sélectionnant le "meilleur" essai pour chaque paramètre des hyperparamètres scientifiques, vérifiez s'il existe un surapprentissage problématique dans au moins chacun des meilleurs essais correspondant aux paramètres des hyperparamètres scientifiques que vous comparez. Si l'un des meilleurs essais présente un surapprentissage problématique, effectuez l'une ou les deux opérations suivantes :
- Exécuter à nouveau le test avec des techniques de régularisation supplémentaires
- Réajustez les paramètres de régularisation existants avant de comparer les valeurs des hyperparamètres scientifiques. Cela ne s'applique pas si les hyperparamètres scientifiques incluent des paramètres de régularisation. Dans ce cas, il ne serait pas surprenant que des paramètres de régularisation de faible intensité entraînent un surapprentissage problématique.
Il est souvent facile de réduire le surapprentissage à l'aide de techniques de régularisation courantes qui ajoutent une complexité de code ou un calcul supplémentaire minimes (par exemple, la régularisation par abandon, le lissage d'étiquettes, la diminution du poids). Il est donc généralement facile d'en ajouter un ou plusieurs à la prochaine série de tests. Par exemple, si l'hyperparamètre scientifique est "nombre de couches cachées" et que le meilleur essai qui utilise le plus grand nombre de couches cachées présente un surapprentissage problématique, nous vous recommandons de réessayer avec une régularisation supplémentaire au lieu de sélectionner immédiatement le plus petit nombre de couches cachées.
Même si aucun des "meilleurs" essais ne présente de surapprentissage problématique, il peut toujours y avoir un problème si cela se produit dans l'un des essais. La sélection du meilleur essai supprime les configurations présentant un surapprentissage problématique et favorise celles qui n'en présentent pas. En d'autres termes, la sélection du meilleur essai favorise les configurations avec plus de régularisation. Toutefois, tout ce qui nuit à l'entraînement peut servir de régularisateur, même si ce n'était pas prévu. Par exemple, choisir un taux d'apprentissage plus faible peut régulariser l'entraînement en entravant le processus d'optimisation, mais nous ne voulons généralement pas choisir le taux d'apprentissage de cette manière. Notez que le "meilleur" essai pour chaque paramètre des hyperparamètres scientifiques peut être sélectionné de manière à favoriser les "mauvaises" valeurs de certains hyperparamètres scientifiques ou de nuisance.
La variance d'une étape à l'autre est-elle élevée dans l'erreur d'entraînement ou de validation en fin d'entraînement ? Si tel est le cas, cela peut interférer avec les éléments suivants :
- Votre capacité à comparer différentes valeurs des hyperparamètres scientifiques. En effet, chaque essai se termine de manière aléatoire sur une étape "chanceuse" ou "malchanceuse".
- Votre capacité à reproduire le résultat du meilleur essai en production. En effet, il est possible que le modèle de production ne se termine pas à la même étape "chanceuse " que dans l'étude.
Voici les causes les plus probables de la variance d'une étape à l'autre :
- Variance des lots due à l'échantillonnage aléatoire d'exemples du jeu de données d'entraînement pour chaque lot.
- Petits ensembles de validation
- Utiliser un taux d'apprentissage trop élevé en fin d'entraînement
Voici quelques exemples de mesures correctives possibles :
- Augmentez la taille du lot.
- Obtenir plus de données de validation.
- Utilisation de la diminution du taux d'apprentissage.
- Utilisation de la moyenne de Polyak.
Les essais continuent-ils de s'améliorer à la fin de l'entraînement ? Si c'est le cas, vous êtes dans le régime "compute bound" (lié au calcul) et vous pouvez bénéficier d'une augmentation du nombre d'étapes d'entraînement ou d'une modification du programme de taux d'apprentissage.
Les performances sur les ensembles d'entraînement et de validation ont-elles atteint leur maximum bien avant la dernière étape d'entraînement ? Si c'est le cas, cela indique que vous êtes dans le régime "non lié au calcul" et que vous pourrez peut-être réduire le nombre d'étapes d'entraînement.
Au-delà de cette liste, de nombreux comportements supplémentaires peuvent devenir évidents en examinant les courbes de perte. Par exemple, si la perte d'entraînement augmente pendant l'entraînement, cela indique généralement un bug dans le pipeline d'entraînement.
Détecter si un changement est utile avec des graphiques d'isolation
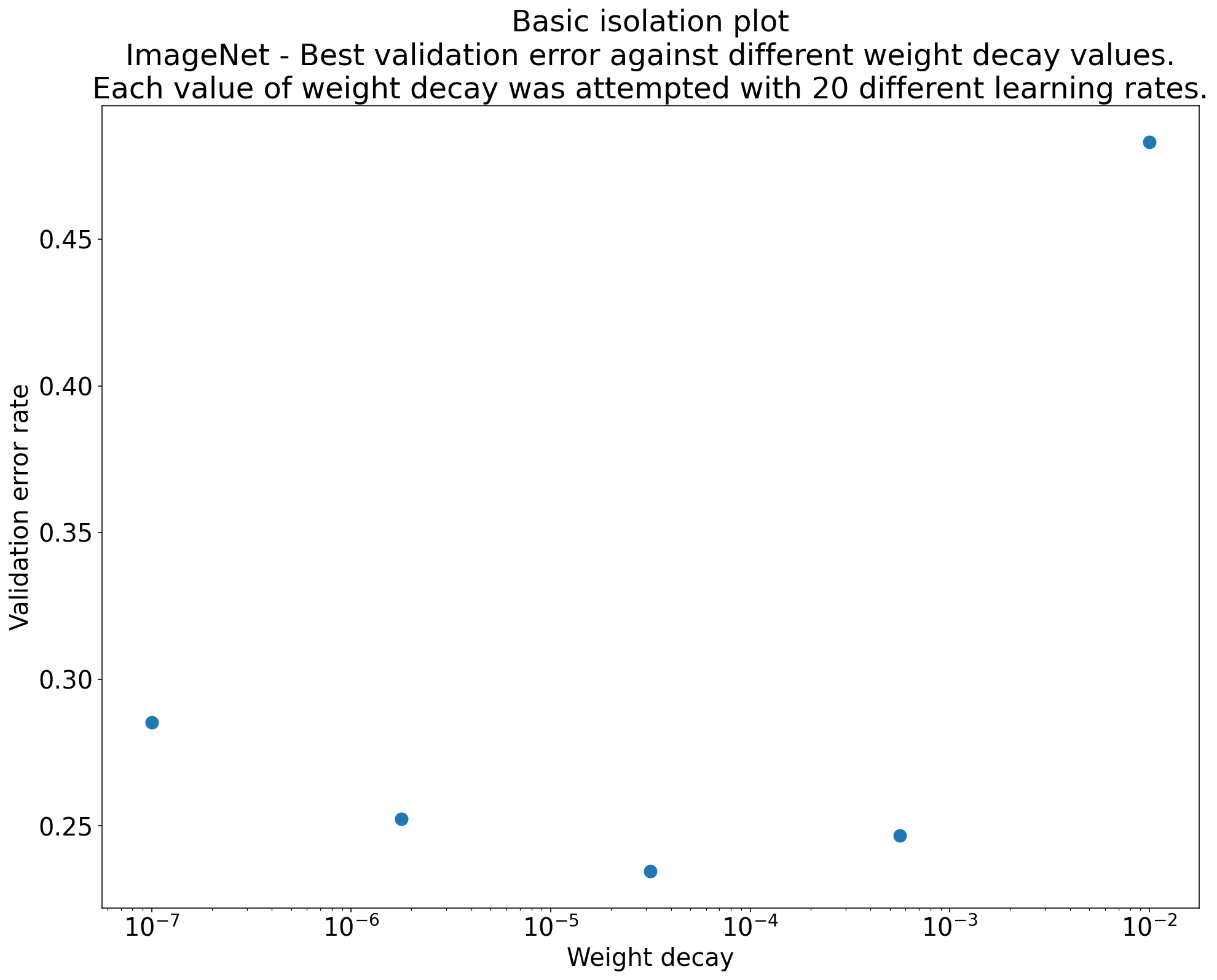
Figure 2 : graphique d'isolation qui étudie la meilleure valeur de diminution du poids pour ResNet-50 entraîné sur ImageNet.
L'objectif d'un ensemble d'expériences est souvent de comparer différentes valeurs d'un hyperparamètre scientifique. Par exemple, supposons que vous souhaitiez déterminer la valeur de la diminution du poids qui entraîne la meilleure erreur de validation. Un graphique d'isolation est un cas particulier du graphique d'axe d'hyperparamètre de base. Chaque point d'un graphique d'isolation correspond aux performances du meilleur essai pour certains (ou tous) des hyperparamètres de nuisance. En d'autres termes, représentez les performances du modèle après avoir "optimisé" les hyperparamètres de nuisance.
Un graphique d'isolation permet de comparer facilement différentes valeurs de l'hyperparamètre scientifique. Par exemple, le graphique d'isolation de la figure 2 révèle la valeur de la diminution du poids qui produit les meilleures performances de validation pour une configuration particulière de ResNet-50 entraînée sur ImageNet.
Si l'objectif est de déterminer s'il faut inclure la régularisation par décroissance du poids, comparez le meilleur point de ce graphique à la référence sans régularisation par décroissance du poids. Pour une comparaison équitable, le taux d'apprentissage de la référence doit également être bien ajusté.
Lorsque vous disposez de données générées par une recherche (quasi)aléatoire et que vous envisagez d'utiliser un hyperparamètre continu pour un graphique d'isolation, vous pouvez approximer le graphique d'isolation en regroupant les valeurs de l'axe x du graphique d'axe d'hyperparamètre de base et en prenant le meilleur essai dans chaque tranche verticale définie par les buckets.
Automatiser les graphiques génériques utiles
Plus il faut d'efforts pour générer des graphiques, moins vous êtes susceptible de les consulter autant que vous le devriez. Nous vous recommandons donc de configurer votre infrastructure pour qu'elle génère automatiquement le plus de graphiques possible. Nous vous recommandons au minimum de générer automatiquement des graphiques d'axes d'hyperparamètres de base pour tous les hyperparamètres que vous faites varier dans un test.
Nous vous recommandons également de générer automatiquement des courbes de perte pour tous les essais. Nous vous recommandons également de faciliter autant que possible la recherche des meilleurs essais de chaque étude et d'examiner leurs courbes de perte.
Vous pouvez ajouter de nombreux autres graphiques et visualisations utiles. Pour paraphraser Geoffrey Hinton :
Chaque fois que vous tracez quelque chose de nouveau, vous apprenez quelque chose de nouveau.
Déterminer s'il faut adopter le changement candidat
Résumé : Lorsque vous décidez de modifier notre modèle ou notre procédure d'entraînement, ou d'adopter une nouvelle configuration d'hyperparamètres, notez les différentes sources de variation dans vos résultats.
Lorsque vous essayez d'améliorer un modèle, une modification candidate particulière peut initialement obtenir une meilleure erreur de validation par rapport à une configuration existante. Toutefois, la répétition du test peut ne pas démontrer d'avantage cohérent. De manière informelle, les sources les plus importantes de résultats incohérents peuvent être regroupées dans les grandes catégories suivantes :
- Variance de la procédure d'entraînement, variance de réentraînement ou variance d'essai : variation entre les exécutions d'entraînement qui utilisent les mêmes hyperparamètres, mais des graines aléatoires différentes. Par exemple, différentes initialisations aléatoires, différents mélanges de données d'entraînement, différents masques de désactivation, différents schémas d'opérations d'augmentation des données et différents ordres d'opérations arithmétiques parallèles sont autant de sources potentielles de variance des essais.
- Variance de la recherche d'hyperparamètres ou variance de l'étude : variation des résultats causée par notre procédure de sélection des hyperparamètres. Par exemple, vous pouvez exécuter le même test avec un espace de recherche spécifique, mais avec deux graines différentes pour la recherche quasi aléatoire, et finir par sélectionner différentes valeurs d'hyperparamètres.
- Variance de la collecte et de l'échantillonnage des données : variance due à une répartition aléatoire des données d'entraînement, de validation et de test, ou variance due au processus de génération des données d'entraînement en général.
Vrai. Vous pouvez comparer les taux d'erreur de validation estimés sur un ensemble de validation fini à l'aide de tests statistiques rigoureux. Toutefois, la variance des essais peut souvent produire à elle seule des différences statistiquement significatives entre deux modèles entraînés différents qui utilisent les mêmes paramètres d'hyperparamètres.
La variance des études nous préoccupe le plus lorsque nous essayons de tirer des conclusions qui vont au-delà du niveau d'un point individuel dans l'espace des hyperparamètres. La variance de l'étude dépend du nombre d'essais et de l'espace de recherche. Nous avons constaté des cas où la variance de l'étude est supérieure à celle du test et des cas où elle est beaucoup plus faible. Par conséquent, avant d'adopter un changement candidat, envisagez d'exécuter le meilleur essai N fois pour caractériser la variance des essais d'une exécution à l'autre. En général, vous pouvez vous contenter de re-caractériser la variance du test après des modifications majeures du pipeline, mais vous aurez peut-être besoin d'estimations plus récentes dans certains cas. Dans d'autres applications, la caractérisation de la variance des essais est trop coûteuse pour être intéressante.
Bien que vous ne souhaitiez adopter que les modifications (y compris les nouvelles configurations d'hyperparamètres) qui produisent de réelles améliorations, exiger une certitude totale qu'une modification donnée aide n'est pas non plus la bonne réponse. Par conséquent, si un nouveau point d'hyperparamètre (ou une autre modification) obtient un meilleur résultat que la référence (en tenant compte de la variance de réentraînement du nouveau point et de la référence au mieux), vous devriez probablement l'adopter comme nouvelle référence pour les comparaisons futures. Toutefois, nous vous recommandons de n'adopter que les modifications qui apportent des améliorations supérieures à la complexité qu'elles ajoutent.
Une fois l'exploration terminée
Résumé : Les outils d'optimisation bayésienne sont une option intéressante une fois que vous avez terminé de rechercher des espaces de recherche adaptés et que vous avez décidé quels hyperparamètres valent la peine d'être réglés.
À terme, vos priorités passeront de l'apprentissage du problème d'optimisation à la production d'une configuration optimale unique à lancer ou à utiliser d'une autre manière. À ce stade, il devrait exister un espace de recherche affiné qui contient confortablement la région locale autour du meilleur essai observé et qui a été suffisamment échantillonné. Votre travail d'exploration devrait avoir révélé les hyperparamètres les plus essentiels à régler et leurs plages raisonnables que vous pouvez utiliser pour construire un espace de recherche pour une étude de réglage automatique finale en utilisant un budget de réglage aussi important que possible.
Comme vous ne cherchez plus à maximiser les insights sur le problème d'optimisation, de nombreux avantages de la recherche quasi-aléatoire ne s'appliquent plus. Par conséquent, vous devez utiliser des outils d'optimisation bayésienne pour trouver automatiquement la meilleure configuration d'hyperparamètres. Open Source Vizier implémente différents algorithmes sophistiqués pour ajuster les modèles de ML, y compris les algorithmes d'optimisation bayésienne.
Supposons que l'espace de recherche contienne un volume non négligeable de points divergents, c'est-à-dire des points qui obtiennent une perte d'entraînement NaN ou même une perte d'entraînement de plusieurs écarts-types inférieure à la moyenne. Dans ce cas, nous vous recommandons d'utiliser des outils d'optimisation de boîte noire qui gèrent correctement les essais qui divergent. (Consultez Optimisation bayésienne avec contraintes inconnues pour découvrir une excellente façon de résoudre ce problème.) Open-Source Vizier permet de marquer les points divergents en marquant les essais comme irréalisables, bien qu'il puisse ne pas utiliser notre approche préférée de Gelbart et al., selon sa configuration.
Une fois l'exploration terminée, pensez à vérifier les performances sur l'ensemble de test. En principe, vous pouvez même intégrer l'ensemble de validation à l'ensemble d'entraînement et réentraîner la meilleure configuration trouvée avec l'optimisation bayésienne. Toutefois, cela n'est approprié que s'il n'y aura pas de futurs lancements avec cette charge de travail spécifique (par exemple, un concours Kaggle ponctuel).