Na potrzeby tego dokumentu:
Ostatecznym celem rozwoju uczenia maszynowego jest maksymalizacja użyteczności wdrożonego modelu.
W przypadku każdego problemu związanego z uczeniem maszynowym możesz zwykle zastosować te same podstawowe kroki i zasady opisane w tej sekcji.
W tej sekcji przyjęto następujące założenia:
- Masz już w pełni działający potok trenowania wraz z konfiguracją, która daje rozsądne wyniki.
- Masz wystarczająco dużo zasobów obliczeniowych, aby przeprowadzać istotne eksperymenty dotyczące dostrajania i uruchamiać równolegle co najmniej kilka zadań trenowania.
Strategia przyrostowego dostrajania
Rekomendacja: zacznij od prostej konfiguracji. Następnie stopniowo wprowadzaj ulepszenia, zdobywając wiedzę o problemie. Upewnij się, że każda zmiana jest oparta na solidnych dowodach.
Zakładamy, że Twoim celem jest znalezienie konfiguracji, która zmaksymalizuje wydajność modelu. Czasami celem jest maksymalne ulepszenie modelu do określonego terminu. W innych przypadkach możesz ulepszać model w nieskończoność, np. stale poprawiać model używany w produkcji.
Teoretycznie możesz zmaksymalizować skuteczność, używając algorytmu do automatycznego przeszukiwania całej przestrzeni możliwych konfiguracji, ale nie jest to praktyczne rozwiązanie. Przestrzeń możliwych konfiguracji jest bardzo duża i nie ma jeszcze algorytmów wystarczająco zaawansowanych, aby skutecznie przeszukiwać tę przestrzeń bez pomocy człowieka. Większość zautomatyzowanych algorytmów wyszukiwania opiera się na ręcznie zaprojektowanej przestrzeni wyszukiwania, która określa zestaw konfiguracji do przeszukania. Te przestrzenie wyszukiwania mogą mieć duże znaczenie.
Najskuteczniejszym sposobem na zmaksymalizowanie wydajności jest rozpoczęcie od prostej konfiguracji i stopniowe dodawanie funkcji oraz wprowadzanie ulepszeń w miarę zdobywania wiedzy o problemie.
W każdej rundzie dostrajania zalecamy używanie automatycznych algorytmów wyszukiwania i ciągłe aktualizowanie przestrzeni wyszukiwania w miarę zdobywania wiedzy. W miarę eksploracji będziesz znajdować coraz lepsze konfiguracje, a tym samym Twój „najlepszy” model będzie się stale ulepszać.
Termin „wprowadzenie” odnosi się do aktualizacji naszej najlepszej konfiguracji (która może, ale nie musi odpowiadać rzeczywistemu wprowadzeniu modelu produkcyjnego). W przypadku każdego „wdrożenia” musisz mieć pewność, że zmiana jest oparta na solidnych dowodach, a nie na przypadkowym szczęściu wynikającym z korzystnej konfiguracji. Dzięki temu unikniesz niepotrzebnego skomplikowania potoku trenowania.
Ogólnie nasza strategia przyrostowego dostrajania polega na powtarzaniu tych 4 kroków:
- Wybierz cel na następną rundę eksperymentów. Sprawdź, czy cel ma odpowiedni zakres.
- Zaplanuj kolejną serię eksperymentów. Zaprojektuj i przeprowadź serię eksperymentów, które pomogą Ci osiągnąć ten cel.
- Wyciągaj wnioski z wyników eksperymentu. Ocena eksperymentu na podstawie listy kontrolnej.
- Zdecyduj, czy chcesz wprowadzić proponowaną zmianę.
W dalszej części tej sekcji opisujemy tę strategię.
Wybierz cel następnej rundy eksperymentów
Jeśli spróbujesz dodać kilka funkcji lub odpowiedzieć na kilka pytań jednocześnie, możesz nie być w stanie rozróżnić poszczególnych efektów na wyniki. Przykładowe cele:
- Wypróbuj potencjalne ulepszenie potoku (np. nowy regulator, wybór wstępnego przetwarzania itp.).
- Poznaj wpływ konkretnego hiperparametru modelu (np. funkcji aktywacji)
- Zminimalizuj błąd weryfikacji.
Priorytetowe traktowanie długoterminowego postępu zamiast krótkoterminowych ulepszeń błędów weryfikacji
Podsumowanie: najczęściej głównym celem jest uzyskanie informacji o problemie z dostrajaniem.
Zalecamy poświęcenie większości czasu na zdobywanie wiedzy o problemie, a stosunkowo mało czasu na chciwe skupianie się na maksymalizacji skuteczności w zbiorze walidacyjnym. Innymi słowy, większość czasu poświęcaj na „eksplorację”, a tylko niewielką część na „eksploatację”. Zrozumienie problemu ma kluczowe znaczenie dla zmaksymalizowania ostatecznej skuteczności. Nadanie większego priorytetu statystykom niż krótkoterminowym zyskom pomaga:
- Unikaj wprowadzania niepotrzebnych zmian, które przypadkowo pojawiły się w przypadku dobrze działających eksperymentów.
- Określ, na które hiperparametry błąd weryfikacji jest najbardziej wrażliwy, które hiperparametry wchodzą ze sobą w interakcje i dlatego wymagają ponownego dostrojenia, a które są stosunkowo niewrażliwe na inne zmiany i dlatego można je ustalić w przyszłych eksperymentach.
- sugerować potencjalne nowe funkcje do wypróbowania, takie jak nowe metody regularyzacji, gdy występuje problem z nadmiernym dopasowaniem;
- Określ funkcje, które nie pomagają, i usuń je, aby zmniejszyć złożoność przyszłych eksperymentów.
- rozpoznawać, kiedy ulepszenia wynikające z dostrajania hiperparametrów prawdopodobnie osiągnęły już maksymalny poziom;
- Zawężaj przestrzenie wyszukiwania wokół optymalnej wartości, aby zwiększyć wydajność dostrajania.
W końcu zrozumiesz problem. Dzięki temu możesz skupić się wyłącznie na błędzie weryfikacji, nawet jeśli eksperymenty nie dostarczają maksymalnej ilości informacji o strukturze problemu z dostrajaniem.
Zaplanuj kolejną rundę eksperymentów
Podsumowanie: określ, które hiperparametry są naukowe, nieistotne i stałe w odniesieniu do celu eksperymentu. Utwórz sekwencję badań, aby porównać różne wartości hiperparametrów naukowych, optymalizując jednocześnie hiperparametry zakłócające. Wybierz przestrzeń wyszukiwania hiperparametrów zakłócających, aby zrównoważyć koszty zasobów z wartością naukową.
Określanie hiperparametrów naukowych, uciążliwych i stałych
W przypadku danego celu wszystkie hiperparametry należą do jednej z tych kategorii:
- Parametry naukowe to te, których wpływ na skuteczność modelu chcesz zmierzyć.
- Hiperparametry pomocnicze to te, które należy zoptymalizować, aby można było rzetelnie porównać różne wartości hiperparametrów naukowych. Hiperparametry zakłócające są podobne do parametrów zakłócających w statystyce.
- Stałe hiperparametry mają stałe wartości w bieżącej rundzie eksperymentów. Wartości stałych hiperparametrów nie powinny się zmieniać podczas porównywania różnych wartości hiperparametrów naukowych. Ustalając pewne hiperparametry dla zestawu eksperymentów, musisz zaakceptować, że wnioski wyciągnięte z tych eksperymentów mogą nie być ważne w przypadku innych ustawień ustalonych hiperparametrów. Innymi słowy, stałe hiperparametry tworzą ograniczenia dla wszelkich wniosków, jakie wyciągasz z eksperymentów.
Załóżmy na przykład, że Twój cel jest taki:
Sprawdź, czy model z większą liczbą warstw ukrytych ma mniejszy błąd weryfikacji.
W tym przypadku:
- Tempo uczenia się jest uciążliwym hiperparametrem, ponieważ modele z różną liczbą warstw ukrytych można porównywać tylko wtedy, gdy tempo uczenia się jest dostrajane oddzielnie dla każdej liczby warstw ukrytych. (Optymalne tempo uczenia się zależy zwykle od architektury modelu).
- Funkcja aktywacji może być stałym hiperparametrem, jeśli w poprzednich eksperymentach udało Ci się ustalić, że najlepsza funkcja aktywacji nie jest wrażliwa na głębokość modelu. Możesz też ograniczyć wnioski dotyczące liczby warstw ukrytych, aby uwzględnić tę funkcję aktywacji. Może to być też uciążliwy hiperparametr, jeśli chcesz dostrajać go osobno dla każdej liczby warstw ukrytych.
Hiperparametr może być hiperparametrem naukowym, hiperparametrem zakłócającym lub hiperparametrem stałym. Jego oznaczenie zmienia się w zależności od celu eksperymentu. Funkcja aktywacji może być na przykład jedną z tych funkcji:
- Hiperparametr naukowy: czy w naszym przypadku lepszym wyborem będzie funkcja ReLU czy tanh?
- Uciążliwy hiperparametr: czy najlepszy model 5-warstwowy jest lepszy od najlepszego modelu 6-warstwowego, jeśli dopuścisz kilka różnych możliwych funkcji aktywacji?
- Stały hiperparametr: czy w przypadku sieci ReLU dodanie normalizacji wsadowej w określonym miejscu pomaga?
Podczas planowania nowej serii eksperymentów:
- Określ hiperparametry naukowe dla celu eksperymentu. (Na tym etapie możesz uznać wszystkie pozostałe hiperparametry za uciążliwe).
- Przekształć niektóre hiperparametry, które sprawiają problemy, w hiperparametry stałe.
Przy nieograniczonych zasobach wszystkie hiperparametry nienaukowe pozostawisz jako hiperparametry zakłócające, aby wnioski wyciągane z eksperymentów nie zawierały zastrzeżeń dotyczących stałych wartości hiperparametrów. Im więcej hiperparametrów zakłócających próbujesz dostroić, tym większe jest ryzyko, że nie uda Ci się ich dostroić wystarczająco dobrze dla każdego ustawienia hiperparametrów naukowych i wyciągniesz z eksperymentów błędne wnioski. Jak opisano w dalszej części, możesz zmniejszyć to ryzyko, zwiększając budżet obliczeniowy. Maksymalny budżet zasobów jest jednak często mniejszy niż ten, który byłby potrzebny do dostrojenia wszystkich hiperparametrów innych niż naukowe.
Zalecamy przekształcenie uciążliwego hiperparametru w stały hiperparametr, gdy wady wynikające z jego ustalenia są mniej uciążliwe niż koszt uwzględnienia go jako uciążliwego hiperparametru. Im bardziej hiperparametr zakłócający wchodzi w interakcje z hiperparametrami naukowymi, tym bardziej szkodliwe jest ustalenie jego wartości. Na przykład optymalna wartość siły rozkładu wagi zależy zwykle od rozmiaru modelu, więc porównywanie różnych rozmiarów modeli przy założeniu jednej konkretnej wartości rozkładu wagi nie byłoby zbyt pouczające.
Niektóre parametry optymalizatora
Ogólnie rzecz biorąc, niektóre hiperparametry optymalizatora (np. tempo uczenia się, momentum, parametry harmonogramu tempa uczenia się, wartości beta algorytmu Adam itp.) są uciążliwymi hiperparametrami, ponieważ zwykle wchodzą w najwięcej interakcji z innymi zmianami. Te hiperparametry optymalizatora rzadko są hiperparametrami naukowymi, ponieważ cel taki jak „jaka jest najlepsza szybkość uczenia się w przypadku bieżącego potoku?” nie daje zbyt wielu informacji. W końcu najlepsze ustawienie może się zmienić po następnej zmianie potoku.
Czasami możesz poprawić niektóre hiperparametry optymalizatora ze względu na ograniczenia zasobów lub szczególnie mocne dowody na to, że nie wchodzą one w interakcje z parametrami naukowymi. Ogólnie jednak należy założyć, że hiperparametry optymalizatora trzeba dostrajać oddzielnie, aby móc dokonywać rzetelnych porównań różnych ustawień hiperparametrów naukowych, a więc nie powinny być one stałe. Nie ma też żadnego powodu, aby preferować jedną wartość hiperparametru optymalizatora nad inną. Na przykład wartości hiperparametrów optymalizatora zwykle w żaden sposób nie wpływają na koszt obliczeniowy przejść w przód ani gradientów.
Wybór optymalizatora
Wybór optymalizatora zwykle obejmuje:
- hiperparametr naukowy,
- stały hiperparametr,
Optymalizator jest hiperparametrem naukowym, jeśli celem eksperymentu jest dokonanie rzetelnego porównania co najmniej 2 różnych optymalizatorów. Na przykład:
Określ, który optymalizator generuje najmniejszy błąd weryfikacji w danej liczbie kroków.
Możesz też ustawić optymalizator jako stały hiperparametr z różnych powodów, m.in.:
- Z poprzednich eksperymentów wynika, że najlepszy optymalizator do Twojego problemu z dostrajaniem nie jest wrażliwy na bieżące hiperparametry naukowe.
- Wolisz porównywać wartości hiperparametrów naukowych za pomocą tego optymalizatora, ponieważ jego krzywe trenowania są łatwiejsze do interpretacji.
- Wolisz korzystać z tego optymalizatora, ponieważ zużywa mniej pamięci niż alternatywne rozwiązania.
Hiperparametry regularyzacji
Hiperparametry wprowadzone przez technikę regularyzacji są zwykle hiperparametrami zakłócającymi. Jednak decyzja o tym, czy w ogóle uwzględnić technikę regularyzacji, jest hiperparametrem naukowym lub stałym.
Na przykład regularyzacja przez wyłączanie dodaje złożoności kodu. Dlatego podczas podejmowania decyzji o uwzględnieniu regularyzacji przez wyłączanie możesz uznać „brak wyłączania” i „wyłączanie” za hiperparametry naukowe, a współczynnik wyłączania za hiperparametr zakłócający. Jeśli na podstawie tego eksperymentu zdecydujesz się dodać do potoku regularyzację przez wyłączanie neuronów, współczynnik wyłączania neuronów będzie w przyszłych eksperymentach hiperparametrem zakłócającym.
Hiperparametry architektury
Hiperparametry architektury są często hiperparametrami naukowymi lub stałymi, ponieważ zmiany architektury mogą wpływać na koszty wyświetlania i trenowania, opóźnienia oraz wymagania dotyczące pamięci. Na przykład liczba warstw jest zwykle hiperparametrem naukowym lub stałym, ponieważ ma ogromny wpływ na szybkość trenowania i wykorzystanie pamięci.
Zależności od hiperparametrów naukowych
W niektórych przypadkach zbiory hiperparametrów zakłócających i stałych zależą od wartości hiperparametrów naukowych. Załóżmy na przykład, że chcesz sprawdzić, który optymalizator w przypadku metody Nesterova z momentum i algorytmu Adam daje najmniejszy błąd walidacji. W tym przypadku:
- Hiperparametrem naukowym jest optymalizator, który przyjmuje wartości
{"Nesterov_momentum", "Adam"} - Wartość
optimizer="Nesterov_momentum"wprowadza hiperparametry{learning_rate, momentum}, które mogą być hiperparametrami uciążliwymi lub stałymi. - Wartość
optimizer="Adam"wprowadza hiperparametry{learning_rate, beta1, beta2, epsilon}, które mogą być hiperparametrami uciążliwymi lub stałymi.
Hiperparametry, które występują tylko w przypadku określonych wartości hiperparametrów naukowych, nazywane są hiperparametrami warunkowymi.
Nie zakładaj, że 2 hiperparametry warunkowe są takie same tylko dlatego, że mają tę samą nazwę. W poprzednim przykładzie hiperparametr warunkowy o nazwie learning_rate jest innym hiperparametrem dla optimizer="Nesterov_momentum" niż dla optimizer="Adam". W obu algorytmach odgrywa podobną (choć nie identyczną) rolę, ale zakres wartości, które dobrze sprawdzają się w każdym z optymalizatorów, zwykle różni się o kilka rzędów wielkości.
Tworzenie zestawu badań
Po zidentyfikowaniu hiperparametrów naukowych i zakłócających należy zaprojektować badanie lub sekwencję badań, aby osiągnąć cel eksperymentalny. Badanie określa zestaw konfiguracji hiperparametrów, które mają być uruchamiane do późniejszej analizy. Każda konfiguracja jest nazywana wersją próbną. Utworzenie badania zwykle obejmuje wybór tych elementów:
- Hiperparametry, które różnią się w poszczególnych próbach.
- Wartości, jakie mogą przyjmować te hiperparametry (przestrzeń wyszukiwania).
- Liczba prób.
- Automatyczny algorytm wyszukiwania, który próbkuje tak wiele prób z przestrzeni wyszukiwania.
Możesz też utworzyć badanie, ręcznie określając zestaw konfiguracji hiperparametrów.
Celem badań jest jednoczesne:
- Uruchom potok z różnymi wartościami hiperparametrów naukowych.
- „Optymalizacja” (lub „optymalizacja ponad”) hiperparametrów zakłócających, aby porównania różnych wartości hiperparametrów naukowych były jak najbardziej obiektywne.
W najprostszym przypadku przeprowadzasz osobne badanie dla każdej konfiguracji parametrów naukowych, w którym dostrajasz hiperparametry zakłócające. Jeśli na przykład chcesz wybrać najlepszy optymalizator spośród optymalizatora z momentum Nesterova i optymalizatora Adam, możesz utworzyć 2 badania:
- Jedno badanie, w którym
optimizer="Nesterov_momentum"i hiperparametry zakłócające są{learning_rate, momentum} - Inne badanie, w którym
optimizer="Adam"i hiperparametry zakłócające są{learning_rate, beta1, beta2, epsilon}.
Aby porównać 2 optymalizatory, wybierz z każdego badania próbę o najlepszych wynikach.
Do optymalizacji hiperparametrów zakłócających możesz użyć dowolnego algorytmu optymalizacji bez gradientu, w tym metod takich jak optymalizacja bayesowska czy algorytmy ewolucyjne. W fazie eksploracji podczas dostrajania wolimy jednak korzystać z wyszukiwania quasi-losowego ze względu na różne zalety, jakie ma ono w tym przypadku. Po zakończeniu eksploracji zalecamy użycie najnowocześniejszego oprogramowania do optymalizacji bayesowskiej (jeśli jest dostępne).
Rozważmy bardziej skomplikowany przypadek, w którym chcesz porównać dużą liczbę wartości hiperparametrów naukowych, ale przeprowadzenie tak wielu niezależnych badań jest niepraktyczne. W takim przypadku możesz wykonać te czynności:
- Uwzględnij parametry naukowe w tym samym obszarze wyszukiwania co hiperparametry zakłócające.
- Użyj algorytmu wyszukiwania, aby w ramach jednego badania pobrać próbki wartości zarówno hiperparametrów naukowych, jak i nieistotnych.
W takim przypadku hiperparametry warunkowe mogą powodować problemy. Trudno jest określić przestrzeń wyszukiwania, chyba że zbiór hiperparametrów zakłócających jest taki sam dla wszystkich wartości hiperparametrów naukowych. W tym przypadku preferujemy wyszukiwanie quasi-losowe od bardziej zaawansowanych narzędzi do optymalizacji typu black box, ponieważ gwarantuje ono równomierne próbkowanie różnych wartości hiperparametrów naukowych. Niezależnie od algorytmu wyszukiwania zadbaj o to, aby przeszukiwał parametry naukowe w jednolity sposób.
Znajdź równowagę między eksperymentami dostarczającymi informacji a eksperymentami niedrogimi
Podczas planowania badania lub sekwencji badań przeznacz ograniczony budżet na odpowiednie osiągnięcie tych 3 celów:
- porównywanie wystarczającej liczby różnych wartości hiperparametrów naukowych;
- Dostrajanie hiperparametrów zakłócających w wystarczająco dużym obszarze wyszukiwania.
- Wystarczająco gęste próbkowanie przestrzeni wyszukiwania hiperparametrów zakłócających.
Im lepiej uda Ci się osiągnąć te 3 cele, tym więcej informacji uzyskasz z eksperymentu. Porównanie jak największej liczby wartości hiperparametrów naukowych poszerza zakres informacji, które możesz uzyskać z eksperymentu.
Uwzględnienie jak największej liczby hiperparametrów zakłócających i umożliwienie każdemu z nich zmiany w jak najszerszym zakresie zwiększa pewność, że w przestrzeni wyszukiwania dla każdej konfiguracji hiperparametrów naukowych istnieje „dobra” wartość hiperparametrów zakłócających. W przeciwnym razie możesz dokonać nieuczciwych porównań wartości hiperparametrów naukowych, ponieważ nie przeszukasz możliwych regionów przestrzeni hiperparametrów zakłócających, w których dla niektórych wartości parametrów naukowych mogą znajdować się lepsze wartości.
Próbkuj przestrzeń wyszukiwania hiperparametrów zakłócających tak gęsto, jak to możliwe. Zwiększa to pewność, że procedura wyszukiwania znajdzie dobre ustawienia dla uciążliwych hiperparametrów, które występują w przestrzeni wyszukiwania. W przeciwnym razie możesz dokonać nieuczciwych porównań wartości parametrów naukowych, ponieważ niektóre wartości będą miały więcej szczęścia w przypadku próbkowania hiperparametrów zakłócających.
Niestety poprawa w każdym z tych 3 wymiarów wymaga jednego z tych działań:
- zwiększenie liczby prób, a tym samym zwiększenie kosztów zasobów;
- Znajdź sposób na oszczędzanie zasobów w jednym z innych wymiarów.
Każdy problem ma swoje własne cechy i ograniczenia obliczeniowe, więc przydzielanie zasobów do tych 3 celów wymaga pewnej wiedzy z danej dziedziny. Po przeprowadzeniu badania zawsze staraj się ocenić, czy hiperparametry zakłócające zostały dostrojone w wystarczającym stopniu. Oznacza to, że badanie zostało przeprowadzone w wystarczająco dużym zakresie, aby można było rzetelnie porównać hiperparametry naukowe (opisane bardziej szczegółowo w następnej sekcji).
Wyciąganie wniosków z wyników eksperymentu
Rekomendacja: oprócz próby osiągnięcia pierwotnego celu naukowego każdej grupy eksperymentów przejrzyj listę kontrolną dodatkowych pytań. Jeśli wykryjesz problemy, zmień eksperymenty i przeprowadź je ponownie.
Każda grupa eksperymentów ma określony cel. Oceń, w jakim stopniu eksperymenty przyczyniają się do osiągnięcia tego celu. Jeśli jednak zadajesz odpowiednie pytania, często możesz znaleźć problemy, które należy rozwiązać, zanim dany zestaw eksperymentów będzie mógł osiągnąć pierwotny cel. Jeśli nie zadajesz tych pytań, możesz wyciągnąć błędne wnioski.
Przeprowadzanie eksperymentów może być kosztowne, dlatego warto wyciągać z każdej grupy eksperymentów inne przydatne wnioski, nawet jeśli nie są one od razu istotne z punktu widzenia bieżącego celu.
Zanim przeanalizujesz dany zestaw eksperymentów, aby osiągnąć pierwotny cel, zadaj sobie te dodatkowe pytania:
- Czy przestrzeń wyszukiwania jest wystarczająco duża? Jeśli optymalny punkt z badania znajduje się w pobliżu granicy przestrzeni wyszukiwania w co najmniej jednym wymiarze, wyszukiwanie prawdopodobnie nie jest wystarczająco szerokie. W takim przypadku przeprowadź kolejne badanie z rozszerzonym zakresem wyszukiwania.
- Czy masz wystarczającą liczbę punktów z przestrzeni wyszukiwania? Jeśli nie, uruchom więcej punktów lub zmniejsz ambicje w zakresie celów dostrajania.
- Jaki odsetek prób w każdym badaniu jest niemożliwy do przeprowadzenia? To znaczy: które próby się rozbiegają, uzyskują bardzo złe wartości funkcji straty lub w ogóle nie działają, ponieważ naruszają jakieś domniemane ograniczenie? Jeśli bardzo duża część punktów w badaniu jest niemożliwa do uzyskania, dostosuj przestrzeń wyszukiwania, aby uniknąć próbkowania takich punktów. Czasami wymaga to ponownego sparametryzowania przestrzeni wyszukiwania. W niektórych przypadkach duża liczba nieosiągalnych punktów może wskazywać na błąd w kodzie trenowania.
- Czy model wykazuje problemy z optymalizacją?
- Czego możesz się nauczyć z krzywych uczenia najlepszych prób? Na przykład czy najlepsze wersje mają krzywe trenowania zgodne z problematycznym nadmiernym dopasowaniem?
W razie potrzeby, na podstawie odpowiedzi na poprzednie pytania, udoskonal ostatnie badanie lub grupę badań, aby zwiększyć przestrzeń wyszukiwania lub pobrać więcej prób albo podjąć inne działania korygujące.
Po udzieleniu odpowiedzi na powyższe pytania możesz ocenić, czy eksperymenty dostarczają dowodów na osiągnięcie pierwotnego celu, np. ocenić, czy zmiana jest przydatna.
Określanie nieprawidłowych granic przestrzeni wyszukiwania
Przestrzeń wyszukiwania jest podejrzana, jeśli najlepszy punkt z niej pobrany znajduje się blisko jej granicy. Jeśli rozszerzysz zakres wyszukiwania w tym kierunku, możesz znaleźć jeszcze lepszy punkt.
Aby sprawdzić granice przestrzeni wyszukiwania, zalecamy wykreślenie ukończonych prób na wykresach, które nazywamy podstawowymi wykresami osi hiperparametrów. Na tych wykresach przedstawiamy wartość celu weryfikacji w porównaniu z jednym z hiperparametrów (np. szybkością uczenia). Każdy punkt na wykresie odpowiada jednemu testowi.
Wartość celu weryfikacji każdego eksperymentu powinna być zwykle najlepszą wartością osiągniętą w trakcie trenowania.
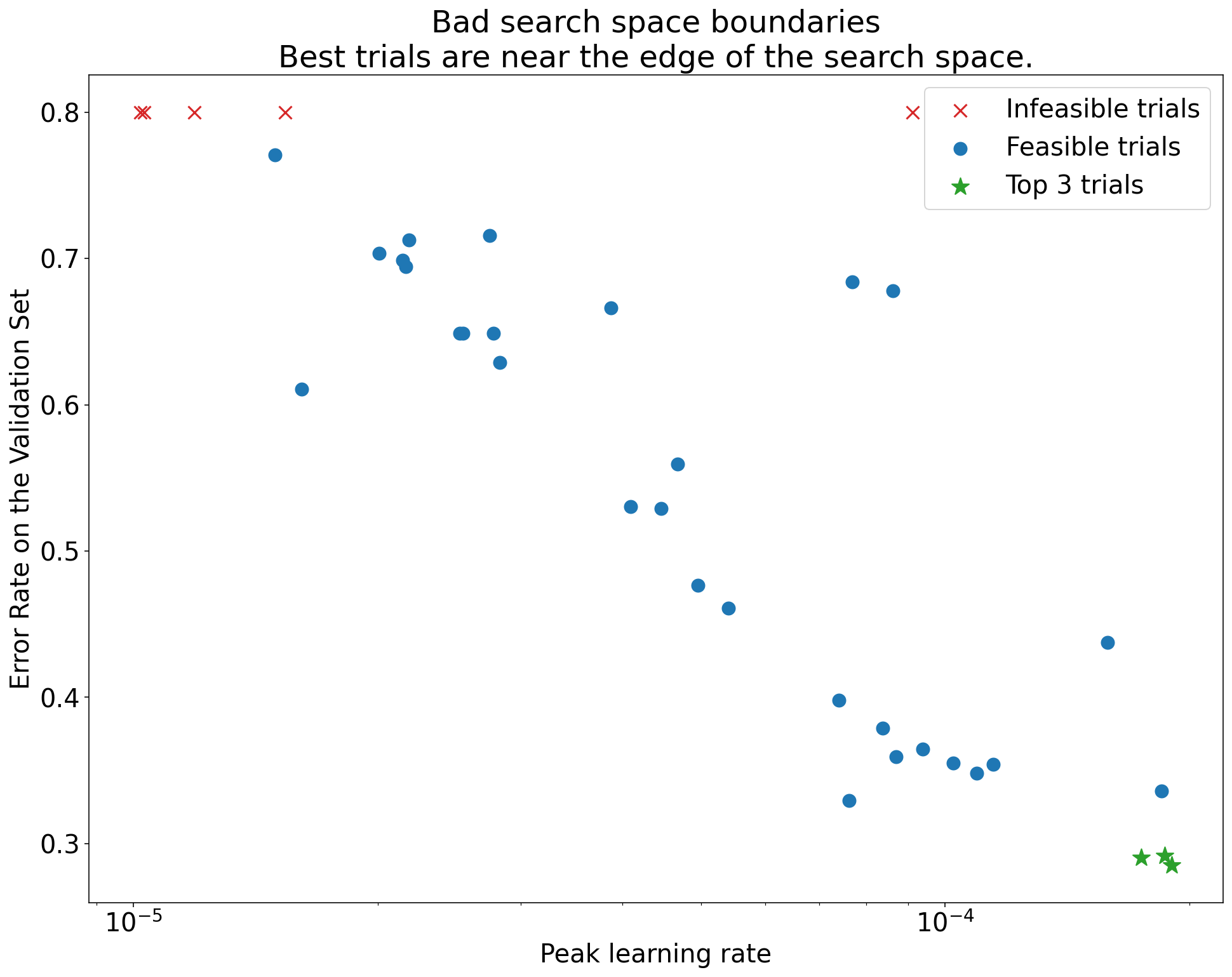
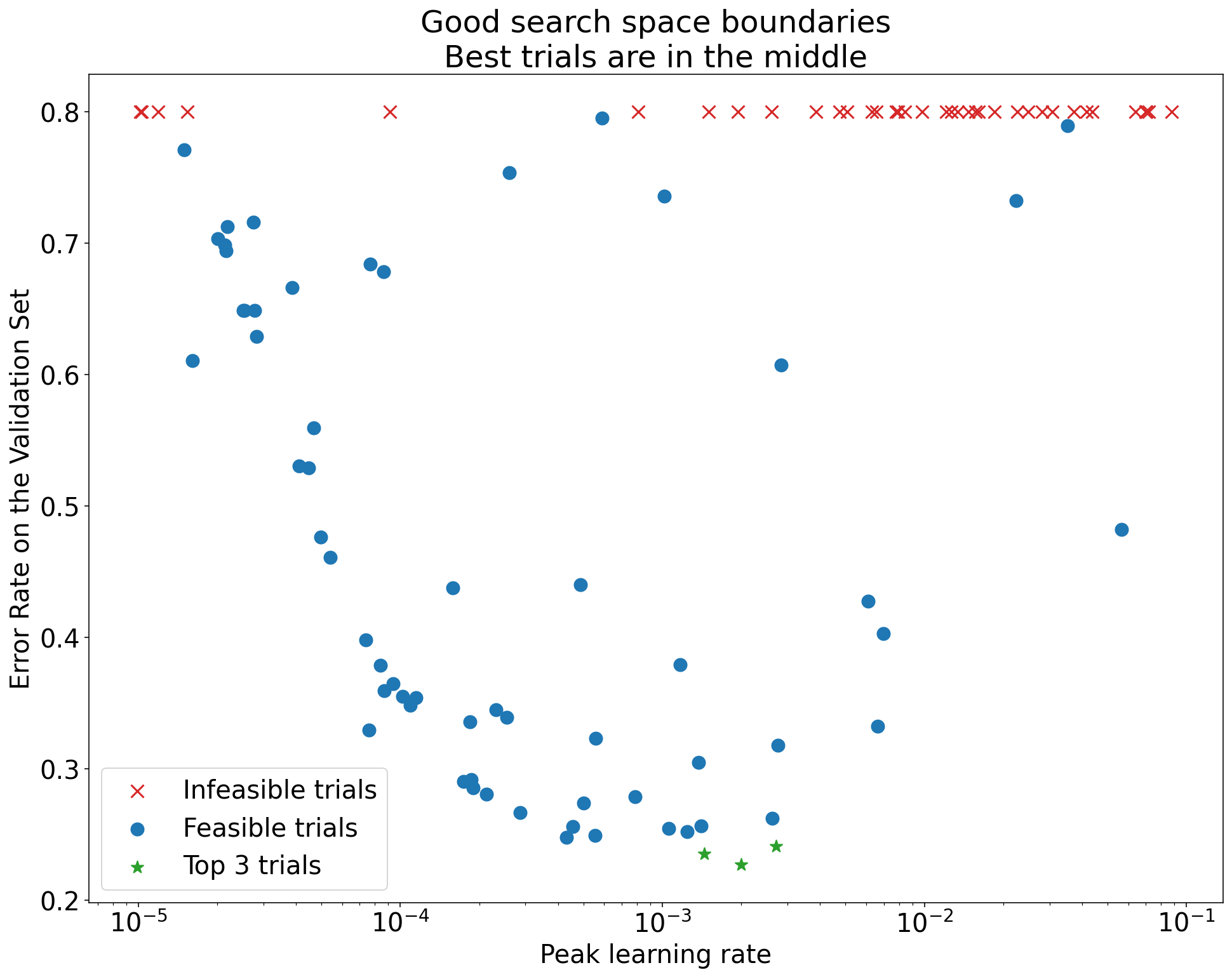
Ilustracja 1. Przykłady nieprawidłowych i prawidłowych granic przestrzeni wyszukiwania.
Wykresy na rysunku 1 przedstawiają współczynnik błędu (im niższy, tym lepiej) w zależności od początkowej szybkości uczenia. Jeśli najlepsze punkty są zgrupowane w pobliżu krawędzi przestrzeni wyszukiwania (w jakimś wymiarze), może być konieczne rozszerzenie granic przestrzeni wyszukiwania, dopóki najlepszy zaobserwowany punkt nie będzie już blisko granicy.
Badanie często obejmuje „niewykonalne” próby, które odbiegają od normy lub dają bardzo złe wyniki (oznaczone czerwonymi znakami X na rysunku 1). Jeśli wszystkie próby są niewykonalne w przypadku współczynników uczenia większych niż pewna wartość progowa, a najskuteczniejsze próby mają współczynniki uczenia na granicy tego regionu, model może mieć problemy ze stabilnością, które uniemożliwiają mu dostęp do wyższych współczynników uczenia.
Nie próbkuje wystarczającej liczby punktów w przestrzeni wyszukiwania
Ogólnie rzecz biorąc, bardzo trudno jest stwierdzić, czy przestrzeń wyszukiwania została wystarczająco dokładnie zbadana. 🤖 Przeprowadzanie większej liczby prób jest lepsze niż przeprowadzanie mniejszej liczby prób, ale większa liczba prób generuje oczywisty dodatkowy koszt.
Trudno jest określić, kiedy próbka jest wystarczająca, dlatego zalecamy:
- wypróbować to, na co Cię stać;
- Kalibrowanie intuicyjnego poziomu ufności przez wielokrotne przyglądanie się różnym wykresom osi hiperparametrów i próby określenia, ile punktów znajduje się w „dobrym” regionie przestrzeni wyszukiwania.
Sprawdzanie krzywych trenowania
Podsumowanie: analiza krzywych strat to łatwy sposób na zidentyfikowanie typowych trybów awarii, który może pomóc w określeniu priorytetów potencjalnych kolejnych działań.
W wielu przypadkach główny cel eksperymentów wymaga jedynie uwzględnienia błędu walidacji każdej wersji próbnej. Uważaj jednak, gdy sprowadzasz każdy test do jednej liczby, ponieważ takie podejście może ukryć ważne szczegóły dotyczące tego, co dzieje się pod powierzchnią. W przypadku każdego badania zdecydowanie zalecamy przyjrzenie się krzywym utraty co najmniej kilku najlepszych prób. Nawet jeśli nie jest to konieczne do osiągnięcia głównego celu eksperymentu, sprawdzenie krzywych strat (w tym strat treningowych i strat walidacyjnych) to dobry sposób na zidentyfikowanie typowych trybów awarii i określenie priorytetów dalszych działań.
Analizując krzywe strat, skup się na tych pytaniach:
Czy któryś z eksperymentów wykazuje problematyczne przetrenowanie? Problem z nadmiernym dopasowaniem występuje, gdy błąd weryfikacji zaczyna rosnąć podczas trenowania. W ustawieniach eksperymentalnych, w których optymalizujesz nieistotne hiperparametry, wybierając „najlepszą” próbę dla każdego ustawienia hiperparametrów naukowych, sprawdź, czy nie występuje problematyczne przetrenowanie w co najmniej każdej z najlepszych prób odpowiadających ustawieniom porównywanych hiperparametrów naukowych. Jeśli którykolwiek z najlepszych modeli wykazuje problematyczne przetrenowanie, wykonaj jedną z tych czynności lub obie:
- Ponowne przeprowadzenie eksperymentu z dodatkowymi technikami regularyzacji
- Przed porównaniem wartości hiperparametrów naukowych ponownie dostrój istniejące parametry regularyzacji. Może to nie mieć zastosowania, jeśli hiperparametry naukowe obejmują parametry regularyzacji, ponieważ w takim przypadku nie byłoby zaskoczeniem, gdyby ustawienia o niskiej sile tych parametrów regularyzacji powodowały problematyczne przetrenowanie.
Ograniczenie nadmiernego dopasowania jest często proste dzięki zastosowaniu typowych technik regularyzacji, które dodają minimalną złożoność kodu lub dodatkowe obliczenia (np. regularyzacja przez wyłączanie, wygładzanie etykiet, zanik wag). Dlatego zwykle łatwo jest dodać co najmniej 1 z nich do kolejnej rundy eksperymentów. Jeśli na przykład hiperparametr naukowy to „liczba warstw ukrytych”, a najlepsza próba, która wykorzystuje największą liczbę warstw ukrytych, wykazuje problematyczne przetrenowanie, zalecamy ponowne przeprowadzenie próby z dodatkową regularyzacją zamiast natychmiastowego wybrania mniejszej liczby warstw ukrytych.
Nawet jeśli żadna z „najlepszych” prób nie wykazuje problematycznego przetrenowania, może ono wystąpić w innych próbach. Wybór najlepszej wersji próbnej eliminuje konfiguracje wykazujące problematyczne nadmierne dopasowanie i preferuje te, które go nie wykazują. Innymi słowy, wybór najlepszej wersji próbnej faworyzuje konfiguracje z większą regularyzacją. Jednak wszystko, co pogarsza trenowanie, może działać jako regulator, nawet jeśli nie było to zamierzone. Na przykład wybranie mniejszego współczynnika uczenia może regulować trenowanie przez utrudnianie procesu optymalizacji, ale zwykle nie chcemy wybierać współczynnika uczenia w ten sposób. Pamiętaj, że „najlepsza” próba dla każdego ustawienia hiperparametrów naukowych może być wybrana w taki sposób, aby faworyzować „złe” wartości niektórych hiperparametrów naukowych lub zakłócających.
Czy pod koniec trenowania występuje duża zmienność błędu trenowania lub weryfikacji? Jeśli tak jest, może to zakłócić:
- możliwość porównywania różnych wartości hiperparametrów naukowych; Dzieje się tak, ponieważ każdy okres próbny kończy się losowo na „szczęśliwym” lub „nieszczęśliwym” kroku.
- Możliwość odtworzenia w środowisku produkcyjnym wyniku najlepszej wersji próbnej. Dzieje się tak, ponieważ model produkcyjny może nie zakończyć się na tym samym „szczęśliwym” kroku co w badaniu.
Najczęstsze przyczyny różnic między poszczególnymi krokami to:
- Wariancja wsadu wynikająca z losowego próbkowania przykładów ze zbioru treningowego dla każdego wsadu.
- Małe zbiory walidacyjne
- Używanie zbyt wysokiego tempa uczenia się w późniejszej fazie trenowania.
Możliwe rozwiązania to:
- zwiększenie rozmiaru partii,
- uzyskiwanie większej ilości danych weryfikacyjnych,
- Korzystanie z zmniejszania tempa uczenia się.
- Korzystanie z uśredniania Polyaka.
Czy na końcu szkolenia próby nadal się poprawiają? Jeśli tak jest, korzystasz z „ograniczenia obliczeniowego” i możesz zwiększyć liczbę kroków trenowania lub zmienić harmonogram szybkości uczenia się.
Czy wyniki w zbiorach treningowych i walidacyjnych osiągnęły już maksymalny poziom na długo przed ostatnim etapem trenowania? Jeśli tak jest, oznacza to, że jesteś w trybie „nieograniczonym przez moc obliczeniową” i możesz zmniejszyć liczbę kroków trenowania.
Oprócz tego z analizy krzywych strat można wywnioskować wiele dodatkowych zachowań. Na przykład wzrost straty trenowania podczas trenowania zwykle wskazuje na błąd w potoku trenowania.
Sprawdzanie, czy zmiana jest przydatna, za pomocą wykresów izolacji
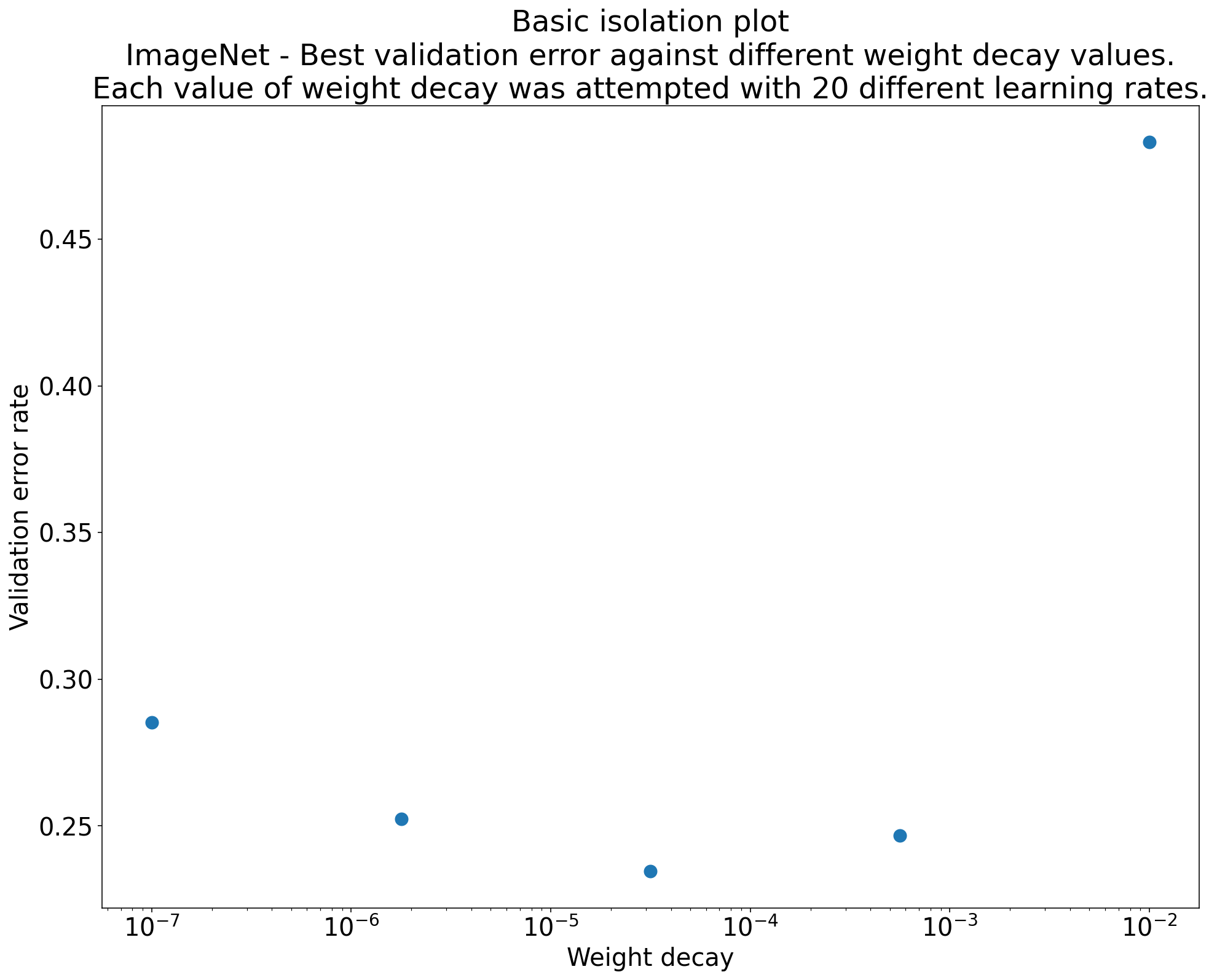
Rysunek 2. Wykres izolacji, który pokazuje najlepszą wartość współczynnika zaniku wagi w przypadku sieci ResNet-50 wytrenowanej na zbiorze ImageNet.
Często celem zestawu eksperymentów jest porównanie różnych wartości hiperparametru naukowego. Załóżmy na przykład, że chcesz określić wartość spadku wagi, która powoduje najmniejszy błąd weryfikacji. Wykres izolacji to szczególny przypadek podstawowego wykresu osi hiperparametrów. Każdy punkt na wykresie izolacji odpowiada skuteczności najlepszej wersji próbnej w przypadku niektórych (lub wszystkich) hiperparametrów zakłócających. Innymi słowy, wykreśl skuteczność modelu po „zoptymalizowaniu” hiperparametrów zakłócających.
Wykres izolacji ułatwia porównanie różnych wartości hiperparametrów naukowych. Na przykład wykres izolacji na rysunku 2 pokazuje wartość zaniku wagi, która zapewnia najlepszą skuteczność weryfikacji w przypadku konkretnej konfiguracji sieci ResNet-50 wytrenowanej na zbiorze ImageNet.
Jeśli chcesz sprawdzić, czy w ogóle uwzględniać zanikanie wagi, porównaj najlepszy punkt na tym wykresie z wartością bazową bez zanikania wagi. Aby porównanie było rzetelne, tempo uczenia się modelu bazowego powinno być równie dobrze dostrojone.
Jeśli masz dane wygenerowane przez (quasi)losowe wyszukiwanie i rozważasz użycie ciągłego hiperparametru na potrzeby wykresu izolacji, możesz przybliżyć wykres izolacji, dzieląc wartości osi x podstawowego wykresu osi hiperparametrów na przedziały i wybierając najlepszą próbę w każdym pionowym wycinku zdefiniowanym przez te przedziały.
Automatyzowanie ogólnie przydatnych wykresów
Im więcej wysiłku wymaga generowanie wykresów, tym mniejsze prawdopodobieństwo, że będziesz je przeglądać tak często, jak powinieneś. Dlatego zalecamy skonfigurowanie infrastruktury tak, aby automatycznie generowała jak najwięcej wykresów. Zalecamy automatyczne generowanie wykresów osi podstawowych hiperparametrów dla wszystkich hiperparametrów, które są zmieniane w eksperymencie.
Dodatkowo zalecamy automatyczne generowanie krzywych strat dla wszystkich prób. Zalecamy też, aby jak najbardziej ułatwić znajdowanie najlepszych wyników kilku prób w każdym badaniu i sprawdzanie ich krzywych strat.
Możesz dodać wiele innych przydatnych wykresów i wizualizacji. Parafrazując Geoffreya Hintona:
Za każdym razem, gdy coś wykreślasz, uczysz się czegoś nowego.
Określanie, czy zaakceptować proponowaną zmianę
Podsumowanie: gdy decydujesz, czy wprowadzić zmianę w modelu lub procedurze trenowania albo zastosować nową konfigurację hiperparametrów, zwróć uwagę na różne źródła zmienności wyników.
Podczas próby ulepszenia modelu konkretna proponowana zmiana może początkowo osiągać mniejszy błąd weryfikacji w porównaniu z obecną konfiguracją. Powtórzenie eksperymentu może jednak nie wykazać żadnej spójnej przewagi. Nieformalnie najważniejsze źródła niespójnych wyników można podzielić na te ogólne kategorie:
- Wariancja procedury trenowania, wariancja ponownego trenowania lub wariancja próbna: zmienność między przebiegami trenowania, które używają tych samych hiperparametrów, ale różnych wartości początkowych. Na przykład różne losowe inicjalizacje, tasowania danych treningowych, maski wyłączania, wzorce operacji rozszerzania danych i kolejności równoległych operacji arytmetycznych to potencjalne źródła wariancji prób.
- Wariancja wyszukiwania hiperparametrów lub wariancja badania: zmienność wyników spowodowana procedurą wyboru hiperparametrów. Możesz na przykład przeprowadzić ten sam eksperyment w określonej przestrzeni wyszukiwania, ale z 2 różnymi wartościami początkowymi dla wyszukiwania quasi-losowego, i w rezultacie wybrać różne wartości hiperparametrów.
- Wariancja związana z gromadzeniem danych i próbkowaniem: wariancja wynikająca z dowolnego rodzaju losowego podziału na dane treningowe, weryfikacyjne i testowe lub wariancja wynikająca z procesu generowania danych treningowych w ogóle.
Owszem, możesz porównać oszacowane na skończonym zbiorze walidacyjnym wskaźniki błędów walidacji za pomocą dokładnych testów statystycznych. Jednak często sama wariancja wersji próbnej może powodować statystycznie istotne różnice między 2 różnymi wytrenowanymi modelami, które korzystają z tych samych ustawień hiperparametrów.
Najbardziej martwi nas wariancja badania, gdy próbujemy wyciągać wnioski wykraczające poza poziom pojedynczego punktu w przestrzeni hiperparametrów. Wariancja badania zależy od liczby prób i przestrzeni wyszukiwania. Zdarzały się przypadki, w których wariancja badania była większa niż wariancja testu, a także przypadki, w których była znacznie mniejsza. Dlatego przed wprowadzeniem proponowanej zmiany warto przeprowadzić najlepszą próbę N razy, aby określić wariancję między próbami. Zwykle po wprowadzeniu istotnych zmian w potoku wystarczy ponownie określić charakterystykę wariancji testu, ale w niektórych przypadkach możesz potrzebować nowszych szacunków. W innych zastosowaniach określenie wariancji próbnej jest zbyt kosztowne, aby było opłacalne.
Chociaż chcesz wprowadzać tylko te zmiany (w tym nowe konfiguracje hiperparametrów), które przynoszą rzeczywiste ulepszenia, wymaganie całkowitej pewności, że dana zmiana pomaga, również nie jest właściwym rozwiązaniem. Jeśli nowy punkt hiperparametrów (lub inna zmiana) daje lepszy wynik niż wartość bazowa (z uwzględnieniem wariancji ponownego trenowania zarówno nowego punktu, jak i wartości bazowej w największym możliwym stopniu), prawdopodobnie warto przyjąć go jako nową wartość bazową do przyszłych porównań. Zalecamy jednak wprowadzanie tylko tych zmian, które przynoszą korzyści przewyższające dodatkową złożoność.
Po zakończeniu eksploracyjnego określania stawek
Podsumowanie: narzędzia do optymalizacji bayesowskiej to atrakcyjna opcja, gdy skończysz wyszukiwać dobre przestrzenie wyszukiwania i zdecydujesz, które hiperparametry warto dostroić.
W końcu priorytety się zmienią – zamiast zdobywać więcej informacji o problemie dostrajania, będziesz dążyć do uzyskania jednej najlepszej konfiguracji, którą można wdrożyć lub w inny sposób wykorzystać. W tym momencie powinien pojawić się zawężony obszar wyszukiwania, który obejmuje lokalny region wokół najlepszej zaobserwowanej wersji próbnej i został odpowiednio zbadany. Prace eksploracyjne powinny ujawnić najważniejsze hiperparametry do dostrojenia i ich rozsądne zakresy, których możesz użyć do utworzenia przestrzeni wyszukiwania na potrzeby końcowego badania automatycznego dostrajania z jak największym budżetem dostrajania.
Ponieważ nie zależy Ci już na maksymalizacji wglądu w problem z dostrajaniem, wiele zalet wyszukiwania quasi-losowego nie ma już zastosowania. Dlatego warto używać narzędzi do optymalizacji bayesowskiej, aby automatycznie znajdować najlepszą konfigurację hiperparametrów. Open-Source Vizier implementuje różne zaawansowane algorytmy do dostrajania modeli ML, w tym algorytmy optymalizacji bayesowskiej.
Załóżmy, że przestrzeń wyszukiwania zawiera znaczną liczbę punktów rozbieżnych, czyli punktów, które powodują, że funkcja straty podczas trenowania zwraca wartość NaN lub nawet wartość o wiele odchyleń standardowych gorszą od średniej. W takim przypadku zalecamy korzystanie z narzędzi do optymalizacji typu black box, które prawidłowo obsługują próby, które się od siebie różnią. (Doskonały sposób na rozwiązanie tego problemu znajdziesz w artykule Optymalizacja bayesowska z nieznanymi ograniczeniami). Open-Source Vizier obsługuje oznaczanie punktów rozbieżnych przez oznaczanie prób jako niewykonalnych, chociaż w zależności od konfiguracji może nie stosować preferowanego przez nas podejścia z artykułu Gelbart i wsp..
Po zakończeniu eksploracyjnego sprawdzania danych możesz sprawdzić skuteczność na zbiorze testowym. W zasadzie możesz nawet włączyć zbiór weryfikacyjny do zbioru treningowego i ponownie wytrenować najlepszą konfigurację znalezioną za pomocą optymalizacji bayesowskiej. Jest to jednak odpowiednie tylko wtedy, gdy w przyszłości nie będą miały miejsca kolejne uruchomienia z tym konkretnym zbiorem zadań (np. jednorazowy konkurs Kaggle).