Zadania uczenia nadzorowanego są dobrze zdefiniowane i można je stosować w wielu scenariuszach, np. do wykrywania spamu czy przewidywania opadów.
Podstawowe pojęcia dotyczące uczenia nadzorowanego
Uczenie maszynowe z nadzorem opiera się na tych podstawowych koncepcjach:
- Dane
- Model
- Szkolenia
- Sprawdzanie
- Wnioskowanie
Dane
Dane są siłą napędową uczenia maszynowego. Dane występują w postaci słów i liczb przechowywanych w tabelach lub jako wartości pikseli i krzywych fali zarejestrowanych w plikach graficznych i dźwiękowych. Powiązane dane są przechowywane w zbiorach danych. Możemy na przykład mieć zbiór danych zawierający te informacje:
- Zdjęcia kotów
- ceny mieszkań,
- Informacje o pogodzie
Zbiory danych składają się z pojedynczych przykładów zawierających cechy i oznaczenia. Możesz sobie wyobrazić przykład jako analogiczny do pojedynczego wiersza w arkuszu kalkulacyjnym. Cechy to wartości, których model nadzorowany używa do przewidywania etykiety. Etykieta to „odpowiedź”, czyli wartość, którą model ma przewidzieć. W przypadku modelu pogody, który prognozuje opady, cechy mogą obejmować szerokość geograficzną, długość geograficzną, temperaturę, wilgotność, zasięg chmur, kierunek wiatru i ciśnienie atmosferyczne. Etykieta to ilość opadów.
Przykłady, które zawierają zarówno cechy, jak i oznaczniki, nazywamy oznaczonymi przykładami.
2 oznaczone przykłady

Natomiast przykłady bez etykiety zawierają funkcje, ale nie mają etykiety. Po utworzeniu modelu model prognozuje etykietę na podstawie cech.
2 oznaczone przykłady
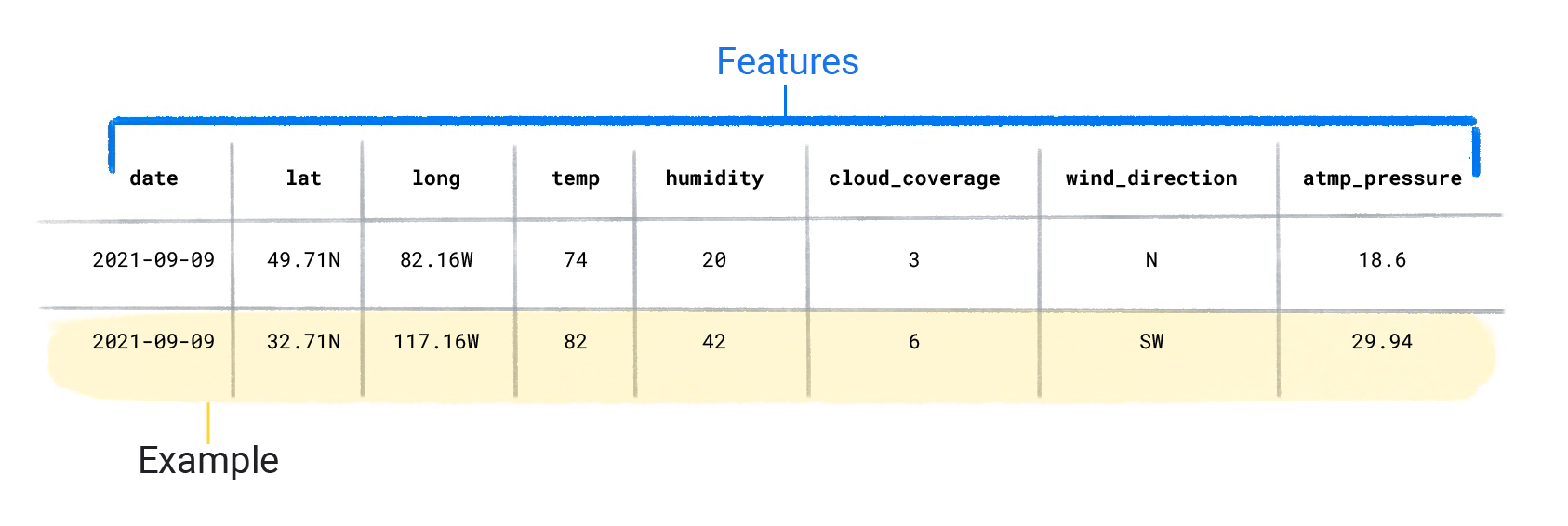
Charakterystyka zbioru danych
Zbiór danych charakteryzuje się rozmiarem i różnorodnością. Rozmiar wskazuje liczbę przykładów. Rozpiętość wskazuje zakres, jaki obejmują te przykłady. Dobre zbiory danych są duże i bardzo zróżnicowane.
Zestawy danych mogą być duże i zróżnicowane, duże, ale nie zróżnicowane lub małe, ale bardzo zróżnicowane. Innymi słowy, duży zbiór danych nie gwarantuje wystarczającej różnorodności, a zbiór danych o dużej różnorodności nie gwarantuje wystarczającej liczby przykładów.
Zbiór danych może np. zawierać dane z 100 lat, ale tylko z lipca. Użycie tego zbioru danych do prognozowania opadów w styczniu dałoby złe wyniki. Zbiór danych może obejmować tylko kilka lat, ale zawierać dane z każdego miesiąca. Ten zbiór danych może generować słabe prognozy, ponieważ nie zawiera wystarczającej liczby lat, aby uwzględnić zmienność.
Sprawdź swoją wiedzę
Zbiór danych można też scharakteryzować na podstawie liczby jego cech. Na przykład niektóre zbiory danych o pogodzie mogą zawierać setki elementów, od zdjęć satelitarnych po wartości pokrycia chmur. Inne zbiory danych mogą zawierać tylko 3 lub 4 cechy, np. wilgotność, ciśnienie atmosferyczne i temperaturę. Zestawy danych zawierające więcej cech mogą pomóc modelowi w odkrywaniu dodatkowych wzorców i wykonywaniu lepszych prognoz. Zbiory danych zawierające więcej cech nie zawsze generują modele, które dają lepsze prognozy, ponieważ niektóre cechy mogą nie mieć związku przyczynowego z etykietą.
Model
W przypadku uczenia nadzorowanego model to złożona kolekcja liczb, które definiują związek matematyczny między określonymi wzorami cech wejściowych a określonymi wartościami etykiet wyjściowych. Model wykrywa te wzorce podczas trenowania.
Szkolenia
Zanim model nadzorowany będzie mógł dokonywać prognoz, musi zostać wytrenowany. Aby wytrenować model, przekazujemy mu zbiór danych z przykładami z etykietami. Celem modelu jest znalezienie najlepszego rozwiązania do przewidywania etykiet na podstawie cech. Model znajduje najlepsze rozwiązanie, porównując przewidywaną wartość z rzeczywistą wartością etykiety. Na podstawie różnicy między przewidywaną a rzeczywistą wartością – zdefiniowanej jako strata – model stopniowo aktualizuje swoje rozwiązanie. Inaczej mówiąc, model uczy się matematycznych zależności między cechami a etykietą, aby móc dokonywać najlepszych prognoz na podstawie nieznanych danych.
Jeśli na przykład model przewidział 1.15 inches mm deszczu, ale rzeczywista wartość wyniosła .75 inches mm, model modyfikuje swoje rozwiązanie, aby jego prognoza była bliższa wartości .75 inches. Po przeanalizowaniu każdego przykładu w zbiorze danych (w niektórych przypadkach wielokrotnie) model znajduje rozwiązanie, które zapewnia najlepsze prognozy dla każdego z przykładów.
Poniżej przedstawiamy trenowanie modelu:
Model przyjmuje pojedynczy przykład z oznaczeniem i wydaje prognozę.
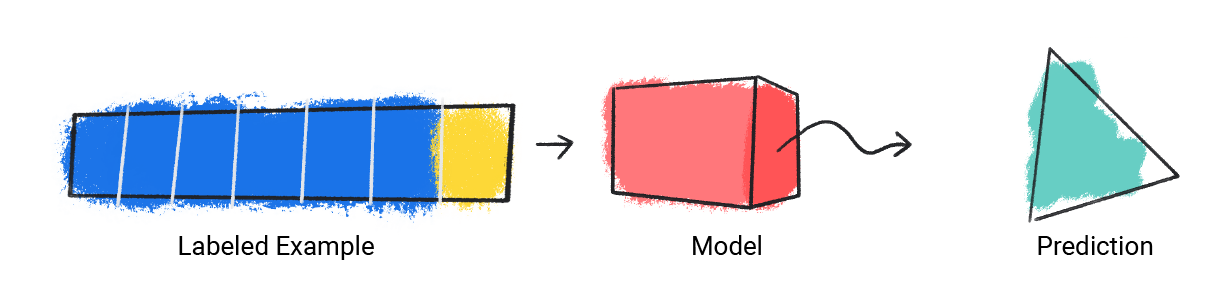
Rysunek 1 Model ML tworzący prognozę na podstawie przykładu z oznaczoną etykietą.
Model porównuje przewidywaną wartość z rzeczywistą i aktualizuje rozwiązanie.
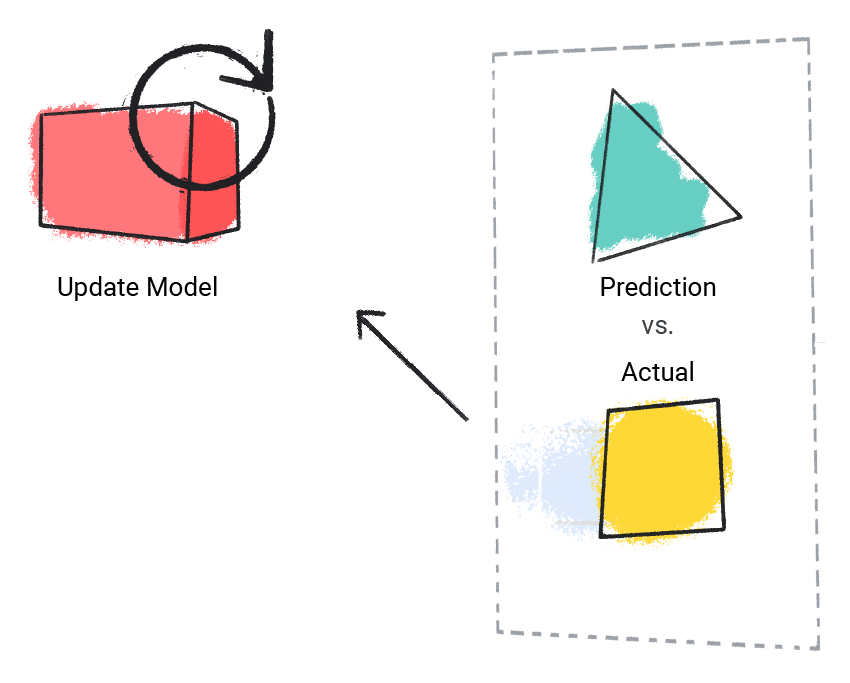
Rysunek 2. Model ML aktualizuje prognozowaną wartość.
Model powtarza ten proces w przypadku każdego przykładu z oznaczoną etykietą w zbiorze danych.
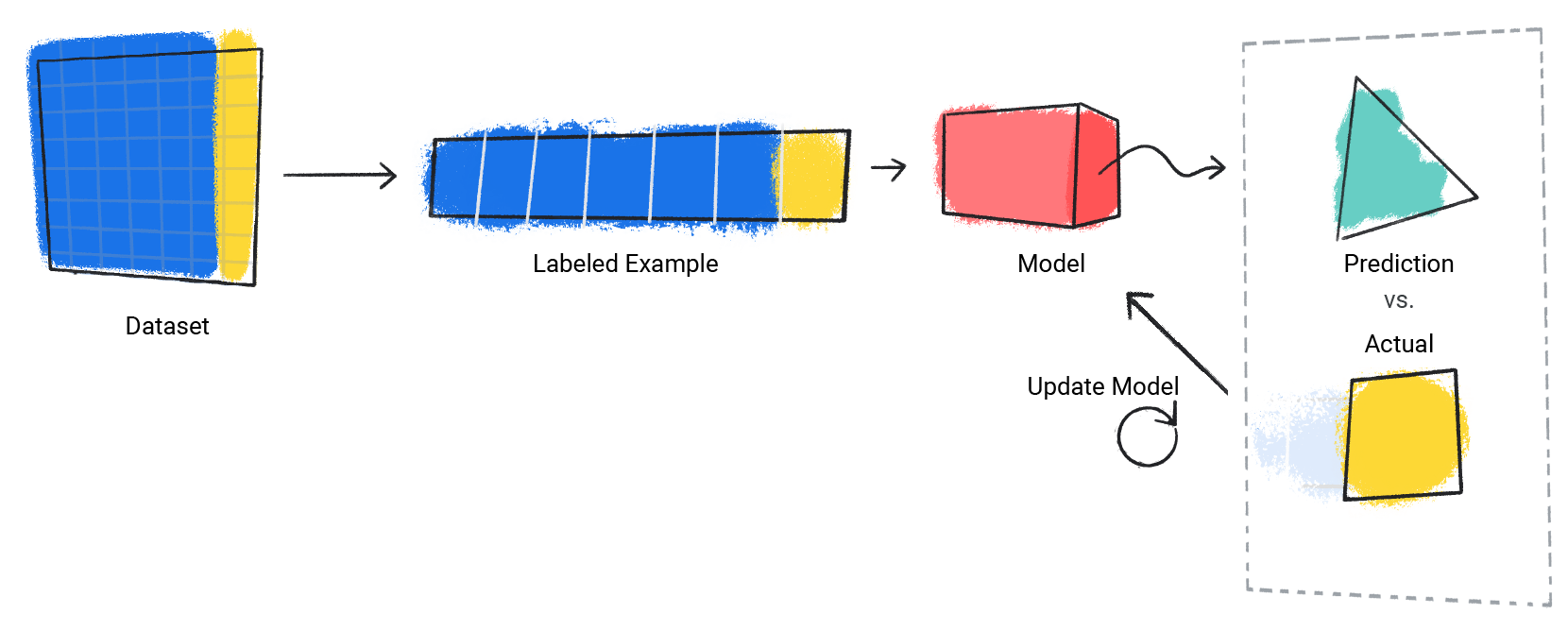
Rysunek 3. Model uczenia maszynowego aktualizuje prognozy dla każdego przykładu z oznaczeniem w zbiorze danych treningowych.
W ten sposób model stopniowo uczy się właściwej zależności między cechami a etykietą. To stopniowe poznawanie jest też powodem, dla którego duże i zróżnicowane zbiory danych dają lepszy model. Model otrzymał więcej danych z szerszym zakresem wartości i doskonalił zrozumienie relacji między cechami a etykietą.
Podczas trenowania specjaliści od uczenia maszynowego mogą wprowadzać subtelne zmiany w konfiguracjach i cechach, których model używa do prognozowania. Na przykład niektóre funkcje mają większą moc predykcyjną niż inne. Dzięki temu użytkownicy ML mogą wybrać, których cech ma używać model podczas trenowania. Załóżmy na przykład, że zbiór danych o pogodzie zawiera jako cechę zmienną time_of_day. W tym przypadku specjalista od systemów uczących się może dodać lub usunąć time_of_day podczas trenowania, aby sprawdzić, czy model lepiej prognozuje z tym atrybutem czy bez niego.
Sprawdzanie
Trenowany model oceniamy, aby określić, jak dobrze się nauczył. Podczas oceny modelu używamy zbioru danych z oznaczonymi etykietami, ale modelowi przekazujemy tylko jego cechy. Następnie porównujemy prognozy modelu z wartościami rzeczywistymi etykiet.
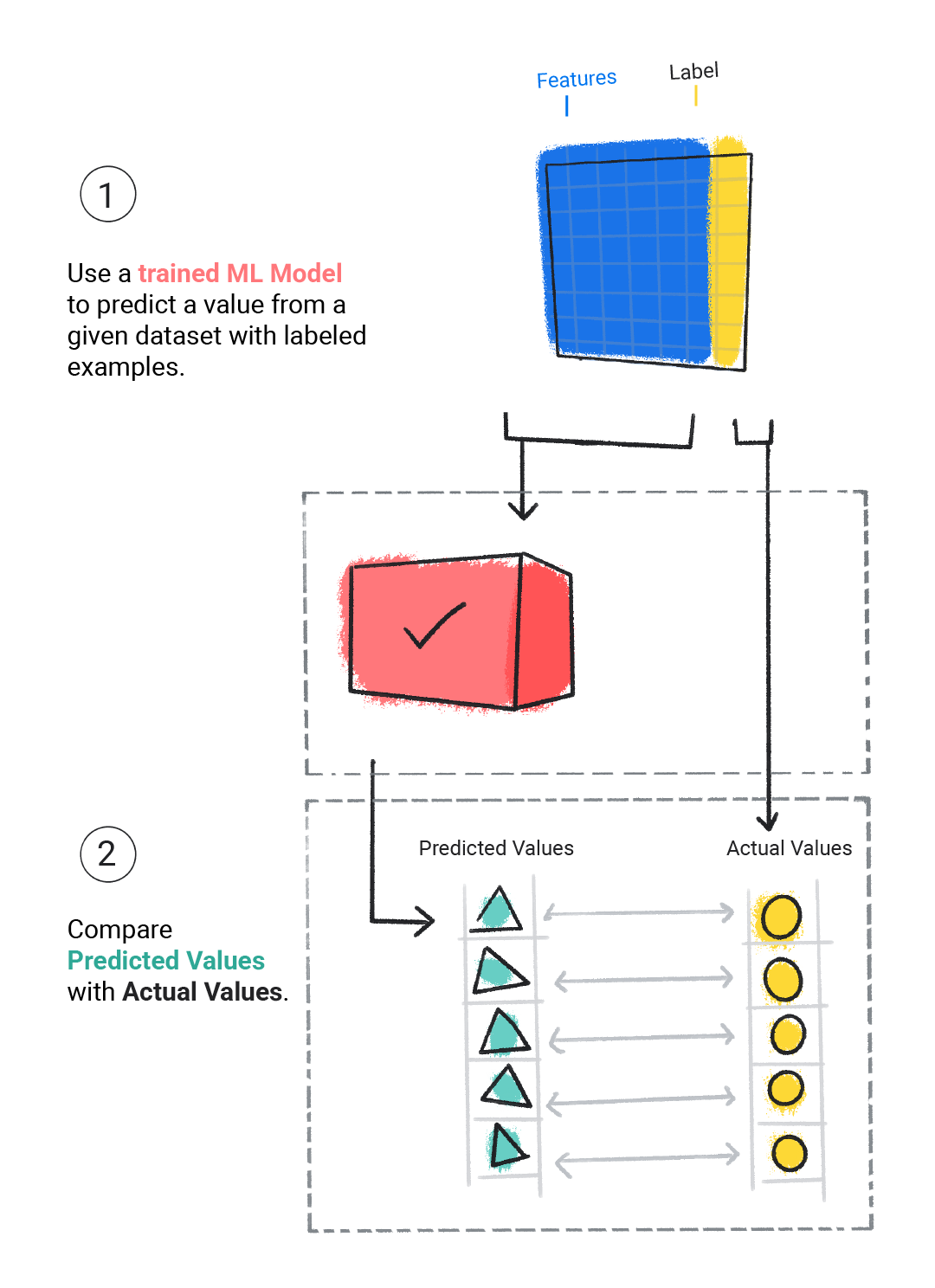
Rysunek 4 Ocenianie modelu ML przez porównywanie jego prognoz z rzeczywistymi wartościami.
W zależności od prognoz modelu możemy przeprowadzić dodatkowe trenowanie i ocenę przed wdrożeniem modelu w rzeczywistym zastosowaniu.
Sprawdź swoją wiedzę
Wnioskowanie
Gdy jesteśmy zadowoleni z wyników oceny modelu, możemy go wykorzystać do prognozowania, czyli wyciągania wniosków na podstawie przykładów bez etykiet. W przypadku aplikacji pogodowej modelowi podajemy aktualne warunki pogodowe, takie jak temperatura, ciśnienie atmosferyczne i względna wilgotność, a on przewiduje ilość opadów.