Các nhiệm vụ của phương pháp học có giám sát được xác định rõ ràng và có thể áp dụng cho nhiều trường hợp, chẳng hạn như xác định nội dung rác hoặc dự đoán lượng mưa.
Các khái niệm cơ bản về học có giám sát
Học máy có giám sát dựa trên các khái niệm cốt lõi sau:
- Dữ liệu
- Mô hình
- Đào tạo
- Đang đánh giá
- Suy luận
Dữ liệu
Dữ liệu là động lực thúc đẩy công nghệ học máy. Dữ liệu có dạng từ và số được lưu trữ trong bảng hoặc dưới dạng giá trị của pixel và dạng sóng được ghi lại trong hình ảnh và tệp âm thanh. Chúng tôi lưu trữ dữ liệu liên quan trong các tập dữ liệu. Ví dụ: chúng ta có thể có một tập dữ liệu như sau:
- Hình ảnh về mèo
- Giá nhà ở
- Thông tin thời tiết
Tập dữ liệu được tạo thành từ các ví dụ riêng lẻ chứa các đặc điểm và một nhãn. Bạn có thể coi một ví dụ tương tự như một hàng trong bảng tính. Các đặc điểm là giá trị mà mô hình có giám sát sử dụng để dự đoán nhãn. Nhãn là "câu trả lời" hoặc giá trị mà chúng ta muốn mô hình dự đoán. Trong mô hình thời tiết dự đoán lượng mưa, các đặc điểm có thể là vĩ độ, kinh độ, nhiệt độ, độ ẩm, mức độ che phủ của đám mây, hướng gió và áp suất khí quyển. Nhãn sẽ là lượng mưa.
Các ví dụ chứa cả tính năng và nhãn được gọi là ví dụ được gắn nhãn.
Hai ví dụ có gắn nhãn

Ngược lại, các ví dụ không được gắn nhãn chứa các tính năng nhưng không có nhãn. Sau khi bạn tạo mô hình, mô hình sẽ dự đoán nhãn từ các tính năng.
Hai ví dụ chưa được gắn nhãn
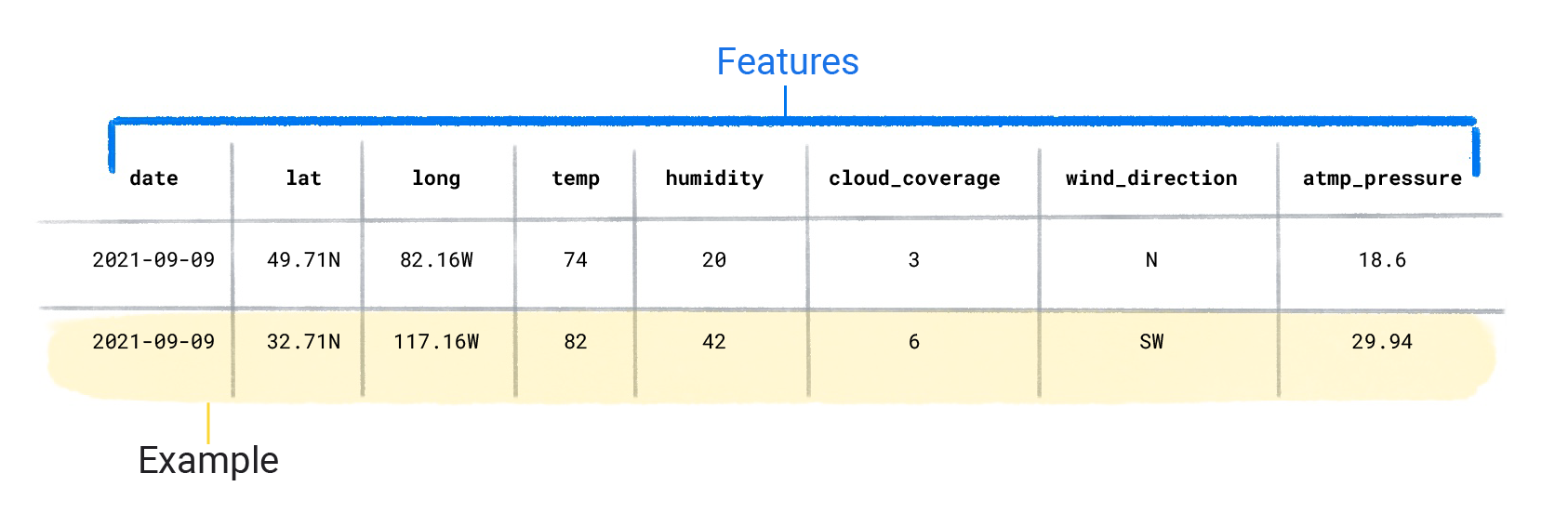
Đặc điểm của tập dữ liệu
Tập dữ liệu được xác định bằng kích thước và tính đa dạng. Kích thước cho biết số lượng ví dụ. Mức độ đa dạng cho biết phạm vi của các ví dụ đó. Tập dữ liệu tốt vừa lớn vừa đa dạng.
Tập dữ liệu có thể lớn và đa dạng, hoặc lớn nhưng không đa dạng, hoặc nhỏ nhưng rất đa dạng. Nói cách khác, một tập dữ liệu lớn không đảm bảo tính đa dạng và một tập dữ liệu rất đa dạng không đảm bảo có đủ ví dụ.
Ví dụ: một tập dữ liệu có thể chứa dữ liệu trong 100 năm, nhưng chỉ dành cho tháng 7. Việc sử dụng tập dữ liệu này để dự đoán lượng mưa trong tháng 1 sẽ dẫn đến kết quả dự đoán không chính xác. Ngược lại, một tập dữ liệu có thể chỉ bao gồm một vài năm nhưng chứa dữ liệu của mọi tháng. Tập dữ liệu này có thể đưa ra kết quả dự đoán không chính xác vì không chứa đủ năm để tính đến sự biến động.
Kiểm tra mức độ hiểu biết
Một tập dữ liệu cũng có thể được mô tả bằng số lượng đặc điểm. Ví dụ: một số tập dữ liệu thời tiết có thể chứa hàng trăm đặc điểm, từ hình ảnh vệ tinh đến giá trị độ che phủ của đám mây. Các tập dữ liệu khác có thể chỉ chứa 3 hoặc 4 đặc điểm, chẳng hạn như độ ẩm, áp suất khí quyển và nhiệt độ. Các tập dữ liệu có nhiều tính năng hơn có thể giúp mô hình khám phá thêm các mẫu và đưa ra dự đoán chính xác hơn. Tuy nhiên, các tập dữ liệu có nhiều đặc điểm hơn không luôn tạo ra các mô hình dự đoán tốt hơn vì một số đặc điểm có thể không có mối quan hệ nhân quả với nhãn.
Mô hình
Trong phương pháp học có giám sát, mô hình là tập hợp phức tạp các con số xác định mối quan hệ toán học từ các mẫu đặc điểm đầu vào cụ thể đến các giá trị nhãn đầu ra cụ thể. Mô hình phát hiện các mẫu này thông qua quá trình huấn luyện.
Đào tạo
Trước khi có thể đưa ra dự đoán, mô hình có giám sát phải được huấn luyện. Để huấn luyện một mô hình, chúng ta cung cấp cho mô hình một tập dữ liệu có các ví dụ được gắn nhãn. Mục tiêu của mô hình là tìm ra giải pháp tốt nhất để dự đoán nhãn từ các đặc điểm. Mô hình tìm giải pháp tốt nhất bằng cách so sánh giá trị dự đoán với giá trị thực tế của nhãn. Dựa trên sự khác biệt giữa giá trị dự đoán và giá trị thực tế – được xác định là mất mát – mô hình sẽ dần cập nhật giải pháp của nó. Nói cách khác, mô hình này học mối quan hệ toán học giữa các đặc điểm và nhãn để có thể đưa ra dự đoán tốt nhất về dữ liệu chưa thấy.
Ví dụ: nếu mô hình dự đoán lượng mưa là 1.15 inches, nhưng giá trị thực tế là .75 inches, thì mô hình sẽ sửa đổi giải pháp để dự đoán gần với .75 inches hơn. Sau khi xem xét từng ví dụ trong tập dữ liệu (trong một số trường hợp, nhiều lần), mô hình sẽ đưa ra một giải pháp đưa ra dự đoán tốt nhất (trung bình) cho từng ví dụ.
Phần sau đây minh hoạ cách huấn luyện mô hình:
Mô hình này lấy một ví dụ được gắn nhãn và đưa ra dự đoán.
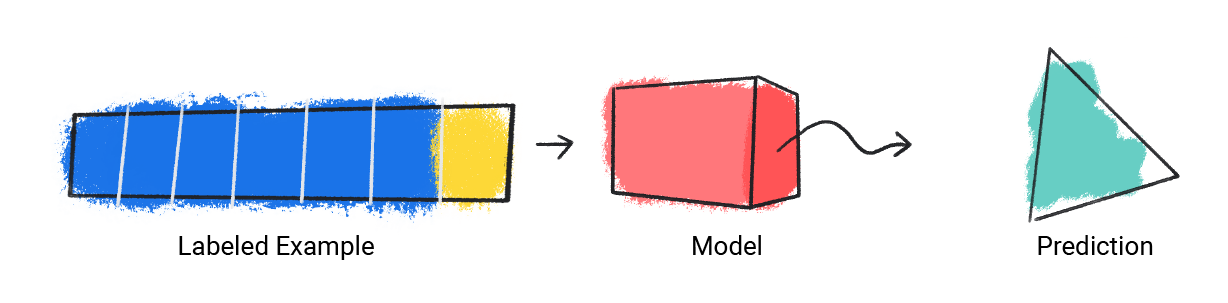
Hình 1 Mô hình học máy đưa ra dự đoán từ một ví dụ được gắn nhãn.
Mô hình so sánh giá trị dự đoán với giá trị thực tế và cập nhật giải pháp.
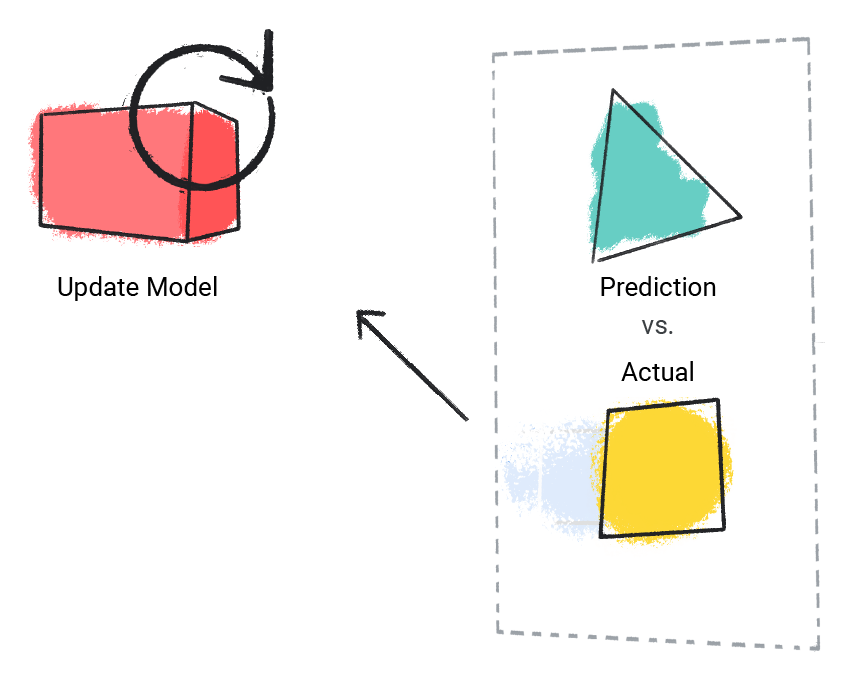
Hình 2. Mô hình học máy cập nhật giá trị dự đoán.
Mô hình lặp lại quy trình này cho mỗi ví dụ được gắn nhãn trong tập dữ liệu.
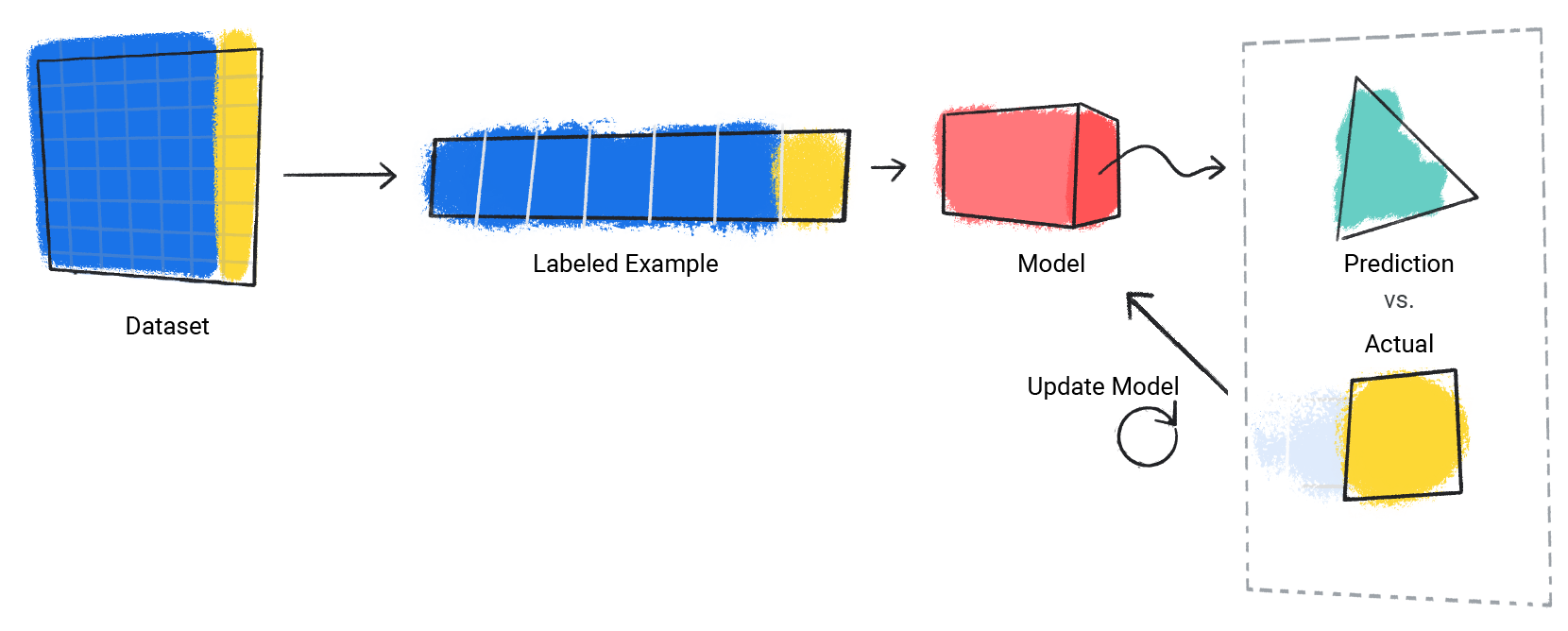
Hình 3. Mô hình học máy cập nhật dự đoán cho từng ví dụ được gắn nhãn trong tập dữ liệu huấn luyện.
Bằng cách này, mô hình sẽ dần học được mối quan hệ chính xác giữa các tính năng và nhãn. Sự hiểu biết dần dần này cũng là lý do khiến các tập dữ liệu lớn và đa dạng tạo ra mô hình tốt hơn. Mô hình đã xem nhiều dữ liệu hơn với phạm vi giá trị rộng hơn và đã tinh chỉnh khả năng hiểu biết về mối quan hệ giữa các tính năng và nhãn.
Trong quá trình huấn luyện, các chuyên gia về máy học có thể điều chỉnh một chút đối với cấu hình và các tính năng mà mô hình sử dụng để đưa ra dự đoán. Ví dụ: một số tính năng có khả năng dự đoán tốt hơn so với các tính năng khác. Do đó, các nhà thực hành học máy có thể chọn những tính năng mà mô hình sử dụng trong quá trình huấn luyện. Ví dụ: giả sử một tập dữ liệu thời tiết chứatime_of_day dưới dạng một tính năng. Trong trường hợp này, người thực hành học máy có thể thêm hoặc xoá time_of_day trong quá trình huấn luyện để xem liệu mô hình có đưa ra dự đoán chính xác hơn khi có hay không có time_of_day.
Đang đánh giá
Chúng ta đánh giá một mô hình đã huấn luyện để xác định mức độ học tập của mô hình đó. Khi đánh giá một mô hình, chúng ta sử dụng một tập dữ liệu được gắn nhãn, nhưng chỉ cung cấp cho mô hình các đặc điểm của tập dữ liệu đó. Sau đó, chúng ta sẽ so sánh kết quả dự đoán của mô hình với giá trị thực của nhãn.
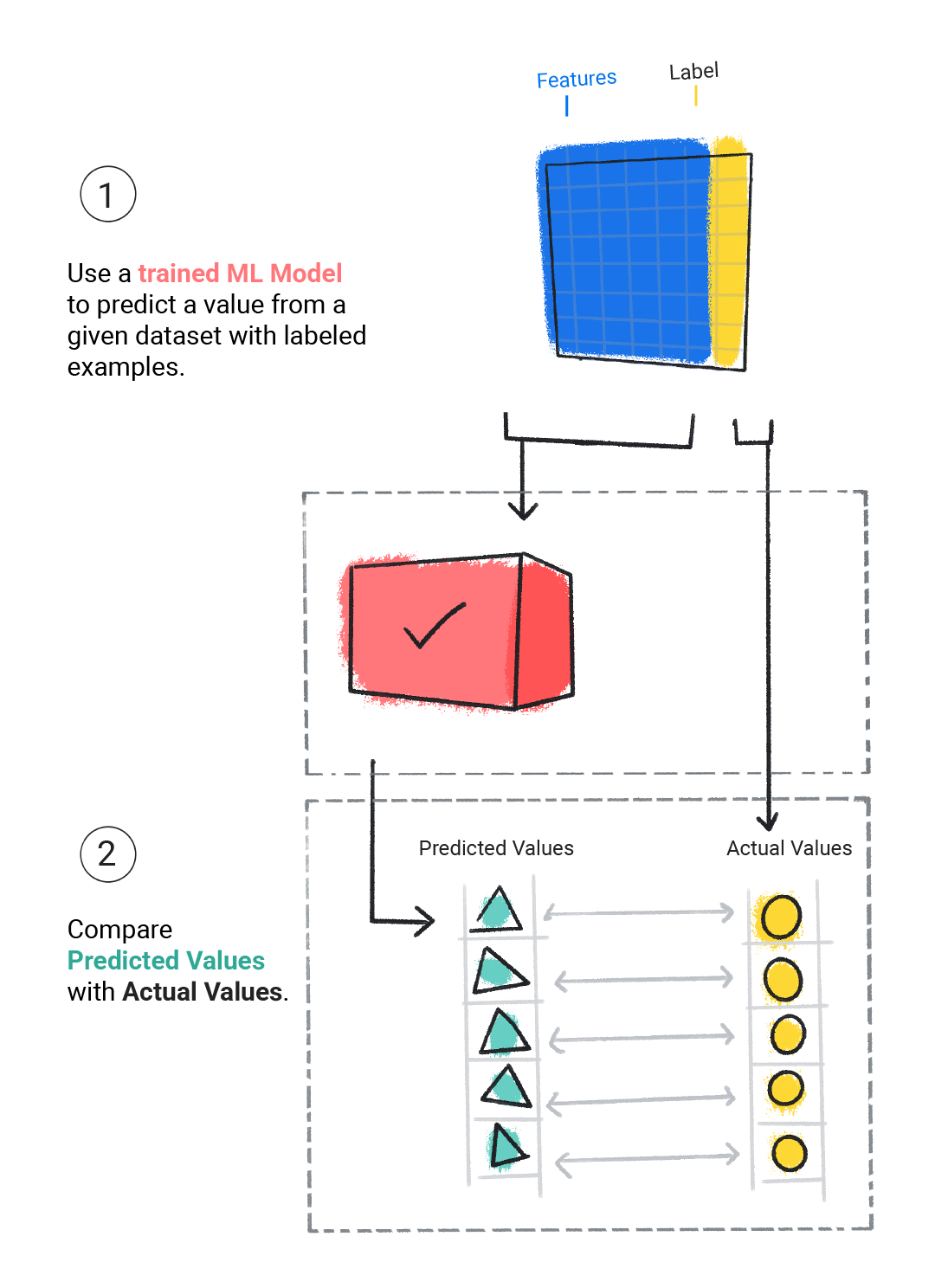
Hình 4. Đánh giá mô hình học máy bằng cách so sánh kết quả dự đoán của mô hình với giá trị thực tế.
Tuỳ thuộc vào kết quả dự đoán của mô hình, chúng ta có thể huấn luyện và đánh giá thêm trước khi triển khai mô hình trong một ứng dụng thực tế.
Kiểm tra mức độ hiểu biết
Suy luận
Khi đã hài lòng với kết quả đánh giá mô hình, chúng ta có thể sử dụng mô hình này để đưa ra dự đoán (gọi là sự suy luận) trên các ví dụ chưa được gắn nhãn. Trong ví dụ về ứng dụng thời tiết, chúng ta sẽ cung cấp cho mô hình các điều kiện thời tiết hiện tại (như nhiệt độ, áp suất khí quyển và độ ẩm tương đối) và mô hình sẽ dự đoán lượng mưa.