Tugas supervised learning ditentukan dengan baik dan dapat diterapkan ke berbagai skenario—seperti mengidentifikasi spam atau memprediksi presipitasi.
Konsep dasar supervised learning
Machine learning terpandu didasarkan pada konsep inti berikut:
- Data
- Model
- Pelatihan
- Mengevaluasi
- Inferensi
Data
Data adalah pendorong ML. Data berupa kata dan angka yang disimpan dalam tabel, atau sebagai nilai piksel dan bentuk gelombang yang diambil dalam gambar dan file audio. Kami menyimpan data terkait dalam set data. Misalnya, kita mungkin memiliki set data berikut:
- Gambar kucing
- Harga perumahan
- Informasi cuaca
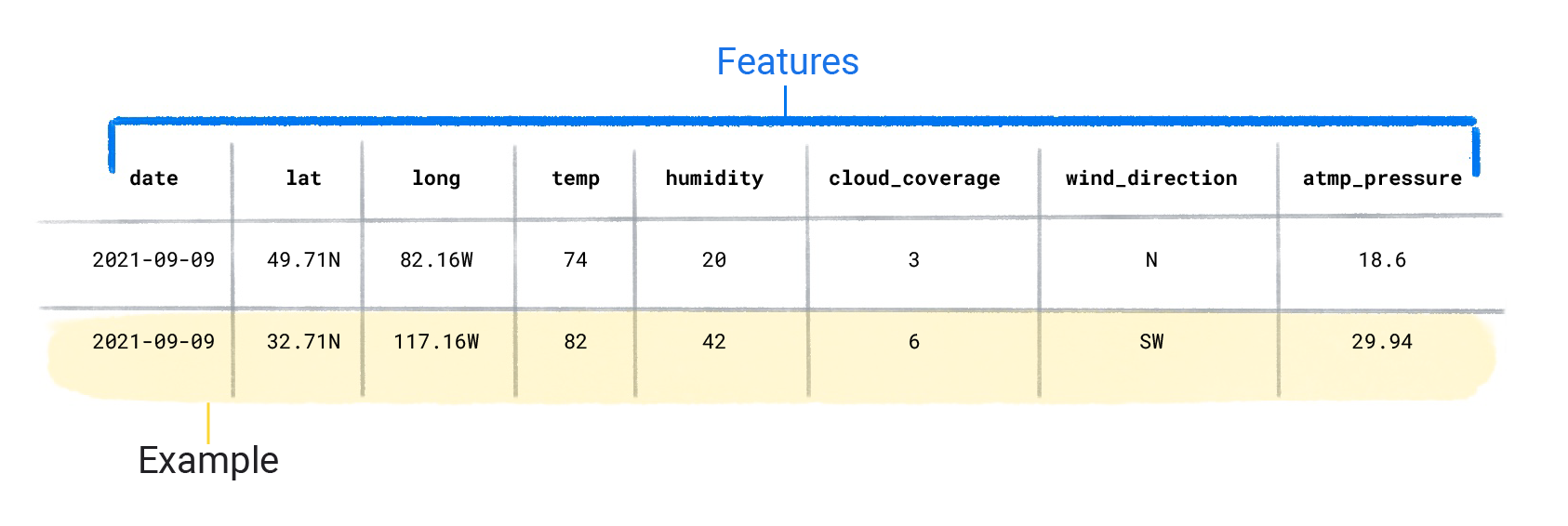
Set data terdiri dari setiap contoh yang berisi fitur dan label. Anda dapat menganggap contoh sebagai analog dengan satu baris dalam spreadsheet. Fitur adalah nilai yang digunakan model dengan pengawasan untuk memprediksi label. Label adalah "jawaban", atau nilai yang ingin diprediksi oleh model. Dalam model cuaca yang memprediksi curah hujan, fitur dapat berupa lintang, bujur, suhu, kelembapan, cakupan awan, arah angin, dan tekanan atmosfer. Labelnya akan menjadi jumlah curah hujan.
Contoh yang berisi fitur dan label disebut contoh berlabel.
Dua contoh berlabel

Sebaliknya, contoh tanpa label berisi fitur, tetapi tidak ada label. Setelah Anda membuat model, model akan memprediksi label dari fitur.
Dua contoh tanpa label
Karakteristik set data
Set data dicirikan oleh ukuran dan keragamannya. Ukuran menunjukkan jumlah contoh. Keragaman menunjukkan rentang yang dicakup oleh contoh tersebut. Set data yang baik besar dan sangat beragam.
Set data dapat berukuran besar dan beragam, atau besar tetapi tidak beragam, atau kecil tetapi sangat beragam. Dengan kata lain, set data yang besar tidak menjamin keberagaman yang memadai, dan set data yang sangat beragam tidak menjamin contoh yang memadai.
Misalnya, set data mungkin berisi data selama 100 tahun, tetapi hanya untuk bulan Juli. Menggunakan set data ini untuk memprediksi curah hujan pada bulan Januari akan menghasilkan prediksi yang buruk. Sebaliknya, set data mungkin hanya mencakup beberapa tahun, tetapi berisi setiap bulan. Set data ini mungkin menghasilkan prediksi yang buruk karena tidak berisi tahun yang cukup untuk memperhitungkan variabilitas.
Memeriksa Pemahaman Anda
Set data juga dapat dikarakterisasi berdasarkan jumlah fiturnya. Misalnya, beberapa set data cuaca mungkin berisi ratusan fitur, mulai dari citra satelit hingga nilai cakupan awan. Set data lain mungkin hanya berisi tiga atau empat fitur, seperti kelembapan, tekanan atmosfer, dan suhu. Set data dengan lebih banyak fitur dapat membantu model menemukan pola tambahan dan membuat prediksi yang lebih baik. Namun, set data dengan lebih banyak fitur tidak selalu menghasilkan model yang membuat prediksi yang lebih baik karena beberapa fitur mungkin tidak memiliki hubungan kausal dengan label.
Model
Dalam supervised learning, model adalah kumpulan angka kompleks yang menentukan hubungan matematika dari pola fitur input tertentu ke nilai label output tertentu. Model menemukan pola ini melalui pelatihan.
Pelatihan
Sebelum dapat membuat prediksi, model tersupervisi harus dilatih. Untuk melatih model, kita memberi model set data dengan contoh berlabel. Sasaran model adalah menemukan solusi terbaik untuk memprediksi label dari fitur. Model ini menemukan solusi terbaik dengan membandingkan nilai prediksinya dengan nilai aktual label. Berdasarkan perbedaan antara nilai prediksi dan nilai aktual—yang ditentukan sebagai kerugian—model akan memperbarui solusinya secara bertahap. Dengan kata lain, model mempelajari hubungan matematis antara fitur dan label sehingga dapat membuat prediksi terbaik pada data yang belum dilihat.
Misalnya, jika model memprediksi hujan 1.15 inches, tetapi nilai sebenarnya
adalah .75 inches, model akan mengubah solusinya sehingga prediksinya lebih dekat dengan
.75 inches. Setelah model melihat setiap contoh dalam set data—dalam beberapa kasus, beberapa kali—model akan menemukan solusi yang membuat prediksi terbaik, rata-rata, untuk setiap contoh.
Berikut ini menunjukkan pelatihan model:
Model ini mengambil satu contoh berlabel dan memberikan prediksi.
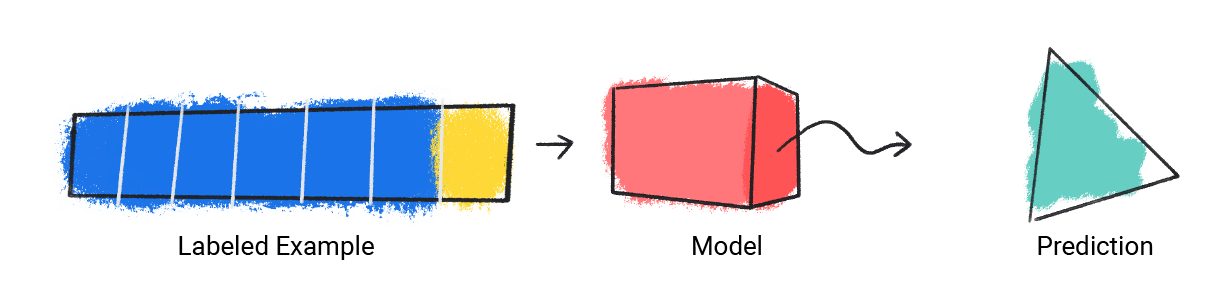
Gambar 1. Model ML yang membuat prediksi dari contoh berlabel.
Model membandingkan nilai prediksinya dengan nilai sebenarnya dan memperbarui solusinya.
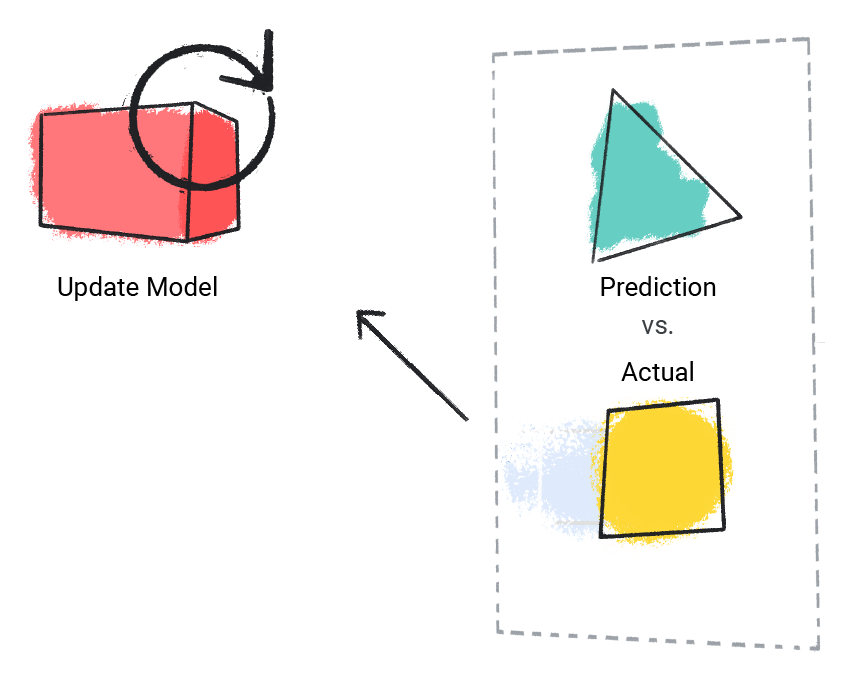
Gambar 2. Model ML yang memperbarui nilai prediksinya.
Model mengulangi proses ini untuk setiap contoh berlabel dalam set data.
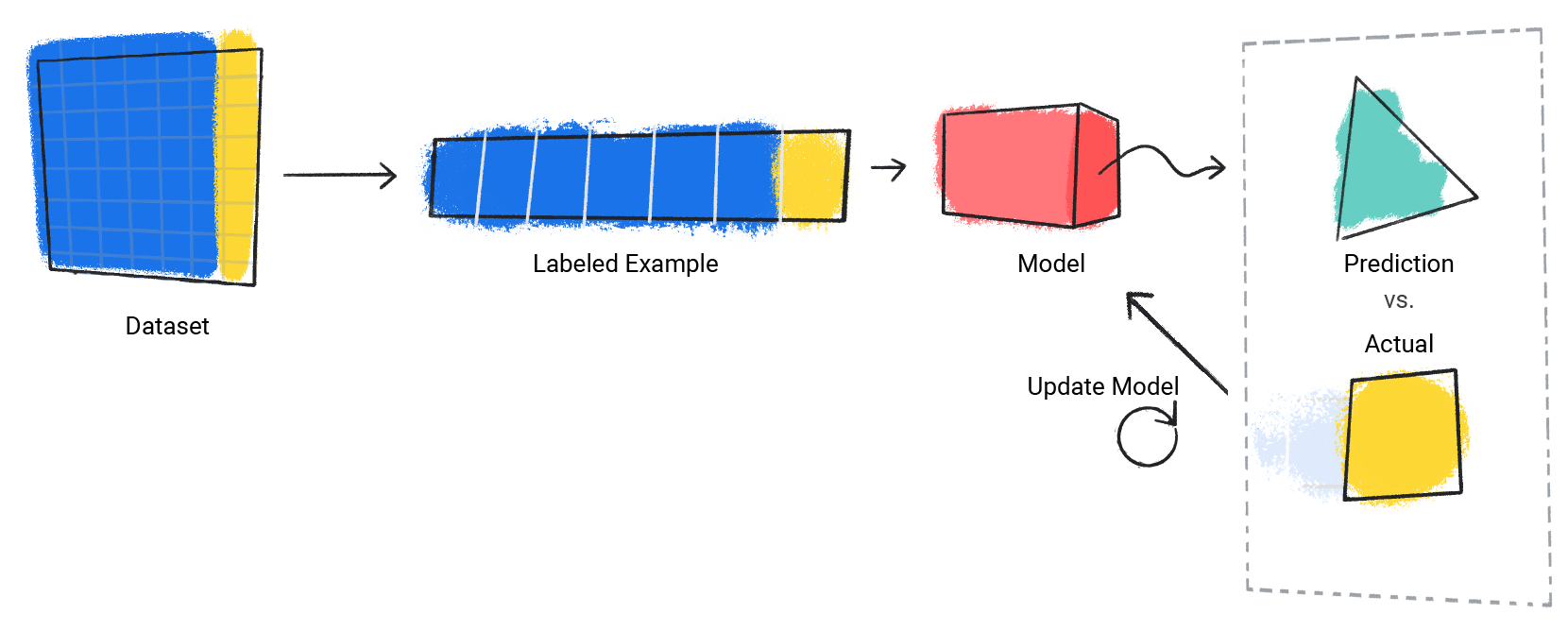
Gambar 3. Model ML yang memperbarui prediksinya untuk setiap contoh berlabel dalam set data pelatihan.
Dengan cara ini, model secara bertahap mempelajari hubungan yang benar antara fitur dan label. Pemahaman bertahap ini juga menjadi alasan set data yang besar dan beragam menghasilkan model yang lebih baik. Model telah melihat lebih banyak data dengan rentang nilai yang lebih luas dan telah meningkatkan pemahamannya tentang hubungan antara fitur dan label.
Selama pelatihan, praktisi ML dapat melakukan penyesuaian kecil pada konfigurasi dan fitur yang digunakan model untuk membuat prediksi. Misalnya,
fitur tertentu memiliki kemampuan prediktif yang lebih baik daripada yang lain. Oleh karena itu, praktisi
ML dapat memilih fitur yang digunakan model selama pelatihan. Misalnya, set data cuaca berisitime_of_day sebagai fitur. Dalam hal
ini, praktisi ML dapat menambahkan atau menghapus time_of_day selama pelatihan untuk melihat
apakah model membuat prediksi yang lebih baik dengan atau tanpanya.
Mengevaluasi
Kita mengevaluasi model terlatih untuk menentukan seberapa baik model tersebut belajar. Saat mengevaluasi model, kita menggunakan set data berlabel, tetapi kita hanya memberikan fitur set data kepada model. Kemudian, kita membandingkan prediksi model dengan nilai sebenarnya dari label.
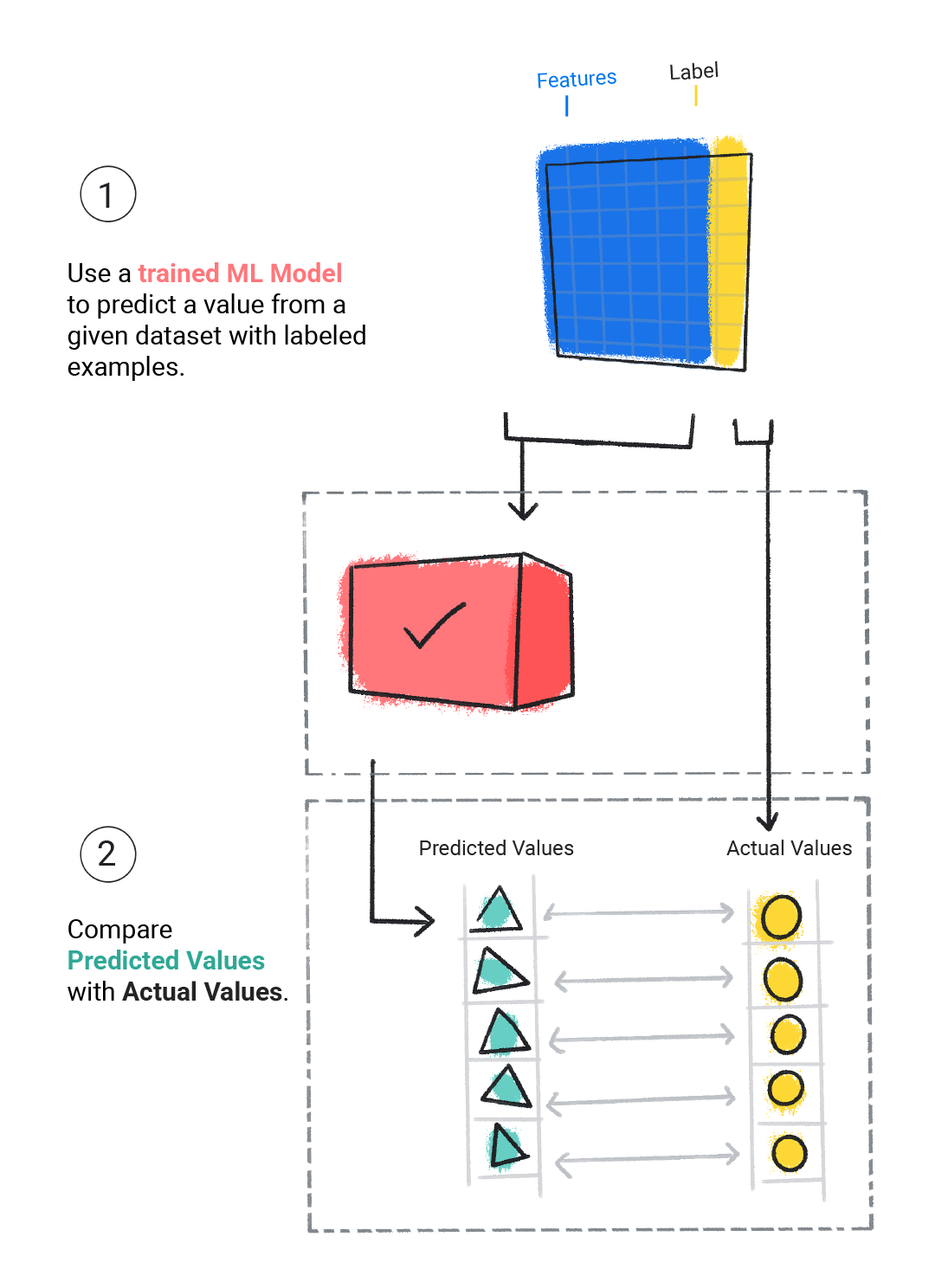
Gambar 4. Mengevaluasi model ML dengan membandingkan prediksinya dengan nilai yang sebenarnya.
Bergantung pada prediksi model, kita mungkin melakukan lebih banyak pelatihan dan evaluasi sebelum men-deploy model dalam aplikasi dunia nyata.
Memeriksa Pemahaman Anda
Inferensi
Setelah puas dengan hasil dari evaluasi model, kita dapat menggunakan model untuk membuat prediksi, yang disebut inferensi, pada contoh yang tidak berlabel. Dalam contoh aplikasi cuaca, kita akan memberikan kondisi cuaca saat ini—seperti suhu, tekanan atmosfer, dan kelembapan relatif—ke model, dan model akan memprediksi jumlah curah hujan.