Gözetimli öğrenmenin görevleri iyi tanımlanmıştır ve spam'i tanımlama veya yağış tahmini yapma gibi birçok senaryoya uygulanabilir.
Temel denetimli öğrenme kavramları
Gözetimli makine öğrenimi aşağıdaki temel kavramlara dayanır:
- Veriler
- Model
- Eğitim
- Değerlendiriliyor
- Çıkarma
Veriler
Veriler, makine öğreniminin itici gücüdür. Veriler tablolarda depolanan kelimeler ve sayılar biçiminde veya resim ve ses dosyalarında yakalanan piksellerin ve dalga formlarının değerleri olarak gelir. İlgili verileri veri kümelerinde depolarız. Örneğin, aşağıdaki verileri içeren bir veri kümemiz olabilir:
- kedi görselleri
- Konut fiyatları
- Hava durumu
Veri kümeleri, özellikler ve etiket içeren bağımsız örneklerden oluşur. Bir örneği, e-tablodaki tek bir satıra benzetebilirsiniz. Özellikler, gözetimli bir modelin etiketi tahmin etmek için kullandığı değerlerdir. Etiket,"yanıt" veya modelin tahmin etmesini istediğimiz değerdir. Yağışı tahmin eden bir hava modelinde enlem, boylam, sıcaklık, nem, bulut kapsamı, rüzgar yönü ve atmosfer basıncı gibi özellikler bulunabilir. Etiket yağış miktarı olur.
Hem özellik hem de etiket içeren örneklere etiketli örnekler denir.
Etiketlenmiş iki örnek

Buna karşılık, etiketsiz örneklerde özellikler bulunur ancak etiket yoktur. Bir model oluşturduktan sonra model, özelliklerden etiketi tahmin eder.
Etiketlenmemiş iki örnek
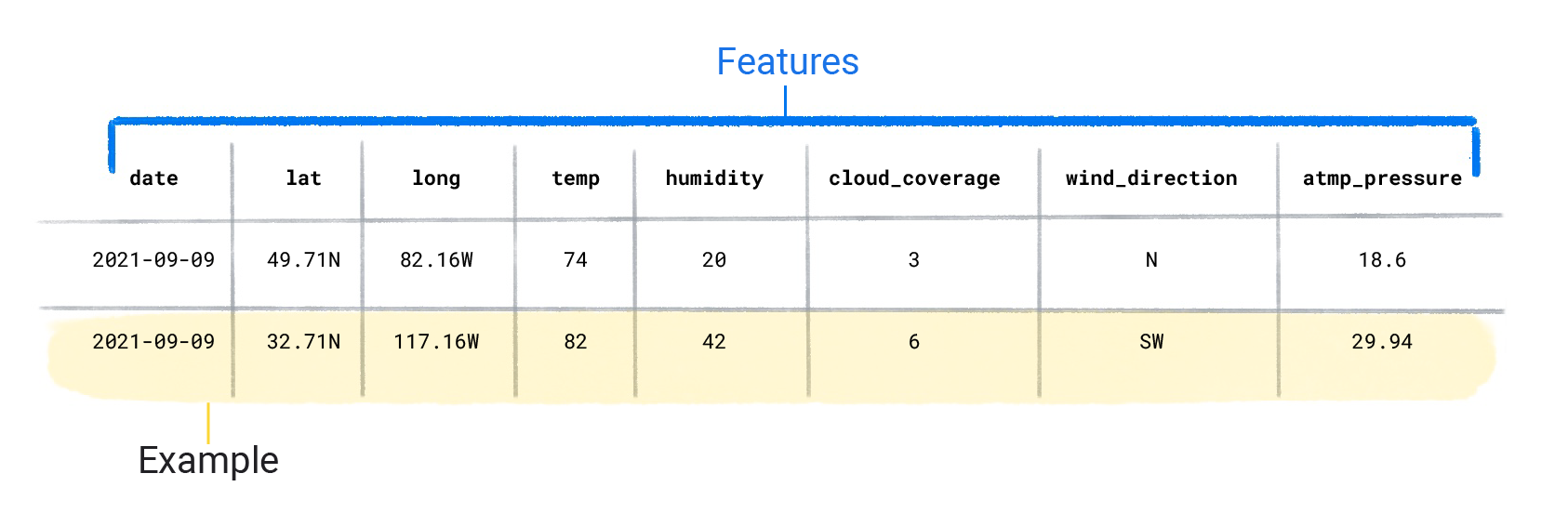
Veri kümesi özellikleri
Veri kümeleri boyutları ve çeşitlilikleriyle karakterize edilir. Boyut, örnek sayısını belirtir. Çeşitlilik, bu örneklerin kapsadığı aralığı gösterir. İyi veri kümeleri hem büyük hem de çok çeşitlidir.
Veri kümeleri büyük ve çeşitli, büyük ancak çeşitli olmayan veya küçük ancak çok çeşitli olabilir. Başka bir deyişle, büyük bir veri kümesi yeterli çeşitliliği garanti etmez ve çok çeşitli bir veri kümesi yeterli örneği garanti etmez.
Örneğin, bir veri kümesi 100 yıllık veri içerebilir ancak yalnızca Temmuz ayına ait olabilir. Ocak ayındaki yağış miktarını tahmin etmek için bu veri kümesini kullanmak, kötü tahminler yapılmasına neden olur. Buna karşılık, bir veri kümesi yalnızca birkaç yılı kapsayabilir ancak her ayı içerebilir. Bu veri kümesi, değişkenliği hesaba katacak yeterli yıl içermediğinden kötü tahminler oluşturabilir.
Öğrendiklerinizi test etme
Bir veri kümesi, özelliklerinin sayısıyla da karakterize edilebilir. Örneğin, bazı hava durumu veri kümeleri; uydu görüntülerinden bulut kapsama alanı değerlerine kadar yüzlerce özellik içerebilir. Diğer veri kümeleri yalnızca üç veya dört özellik (ör. nem, atmosferik basınç ve sıcaklık) içerebilir. Daha fazla özelliğe sahip veri kümeleri, modelin ek kalıplar keşfetmesine ve daha iyi tahminler yapmasına yardımcı olabilir. Ancak daha fazla özelliğe sahip veri kümeleri, bazı özelliklerin etiketle nedensel bir ilişkisi olmayabileceğinden her zaman daha iyi tahminler yapan modeller üretmez.
Model
Gözetimli öğrenmede model, belirli giriş özelliği kalıplarından belirli çıkış etiketi değerlerine kadar olan matematiksel ilişkiyi tanımlayan karmaşık bir sayı koleksiyonudur. Model, bu kalıpları eğitim yoluyla keşfeder.
Eğitim
Gözetimli bir modelin tahminde bulunabilmesi için eğitilmesi gerekir. Bir modeli eğitmek için modele etiketli örnekler içeren bir veri kümesi veririz. Modelin amacı, özelliklerden etiketleri tahmin etmek için en iyi çözümü bulmaktır. Model, tahmini değerini etiketin gerçek değeriyle karşılaştırarak en iyi çözümü bulur. Model, tahmin edilen ve gerçek değerler arasındaki farka (kayıp olarak tanımlanır) göre çözümünü kademeli olarak günceller. Diğer bir deyişle model, görülmeyen verilerle ilgili en iyi tahminleri yapabilmek için özellikler ile etiket arasındaki matematiksel ilişkiyi öğrenir.
Örneğin, model 1.15 inches yağmur tahmininde bulunduysa ancak gerçek değer .75 inches ise model, çözümünü tahmininin .75 inches'e daha yakın olması için değiştirir. Model, veri kümesindeki her bir örneği inceledikten (bazı durumlarda birden çok kez) sonra, örneklerin her biri için ortalama olarak en iyi tahminleri yapan bir çözüme ulaşır.
Aşağıda bir modelin eğitimi gösterilmektedir:
Model, tek bir etiketli örnek alır ve tahmin sağlar.
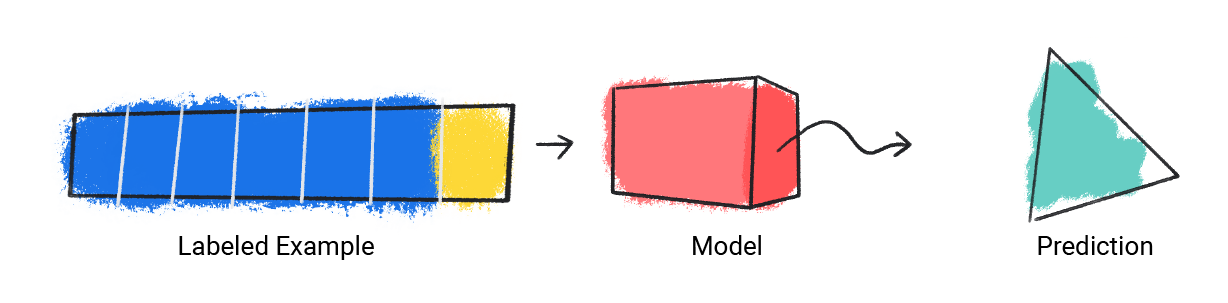
Şekil 1. Etiketli bir örnekten tahmin yapan bir yapay zeka modeli.
Model, tahmin ettiği değeri gerçek değerle karşılaştırır ve çözümünü günceller.
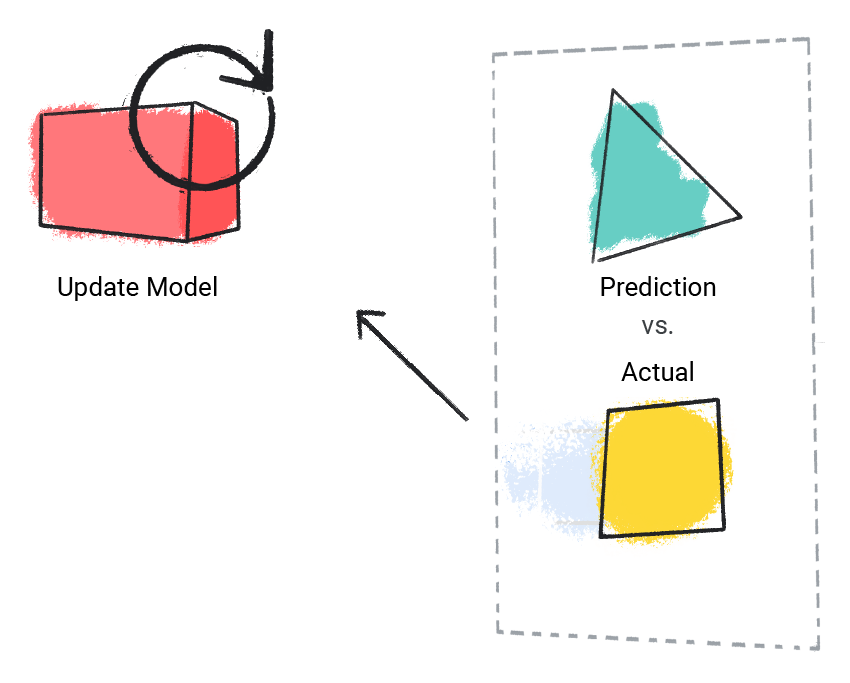
Şekil 2. Tahmin edilen değerini güncelleyen bir makine öğrenimi modeli.
Model, veri kümesindeki her etiketli örnek için bu işlemi tekrarlar.

Şekil 3. Eğitim veri kümesindeki her etiketli örnek için tahminlerini güncelleyen bir makine öğrenimi modeli.
Bu sayede model, özellikler ile etiket arasındaki doğru ilişkiyi kademeli olarak öğrenir. Büyük ve çeşitli veri kümelerinin daha iyi bir model oluşturmasının nedeni de bu kademeli anlama sürecidir. Model, daha geniş bir değer aralığına sahip daha fazla veri gördü ve özellikler ile etiket arasındaki ilişkiyi daha iyi anladı.
ML uzmanları, eğitim sırasında modelin tahmin yapmak için kullandığı yapılandırmalarda ve özelliklerde küçük ayarlamalar yapabilir. Örneğin, bazı özellikler diğerlerinden daha fazla tahmin gücüne sahiptir. Bu nedenle, ML uygulayıcıları, modelin eğitim sırasında hangi özellikleri kullanacağını seçebilir. Örneğin, bir hava durumu veri kümesinin özellik olarak time_of_day içerdiğini varsayalım. Bu durumda, bir makine öğrenimi uzmanı, modelin time_of_day ile veya olmadan daha iyi tahminler yapıp yapmadığını görmek için eğitim sırasında time_of_day'ü ekleyebilir ya da kaldırabilir.
Değerlendiriliyor
Eğitilmiş bir modeli, ne kadar iyi öğrendiğini belirlemek için değerlendiririz. Bir modeli değerlendirirken etiketli bir veri kümesi kullanırız ancak modele yalnızca veri kümesinin özelliklerini veririz. Ardından modelin tahminlerini etiketin gerçek değerleriyle karşılaştırırız.
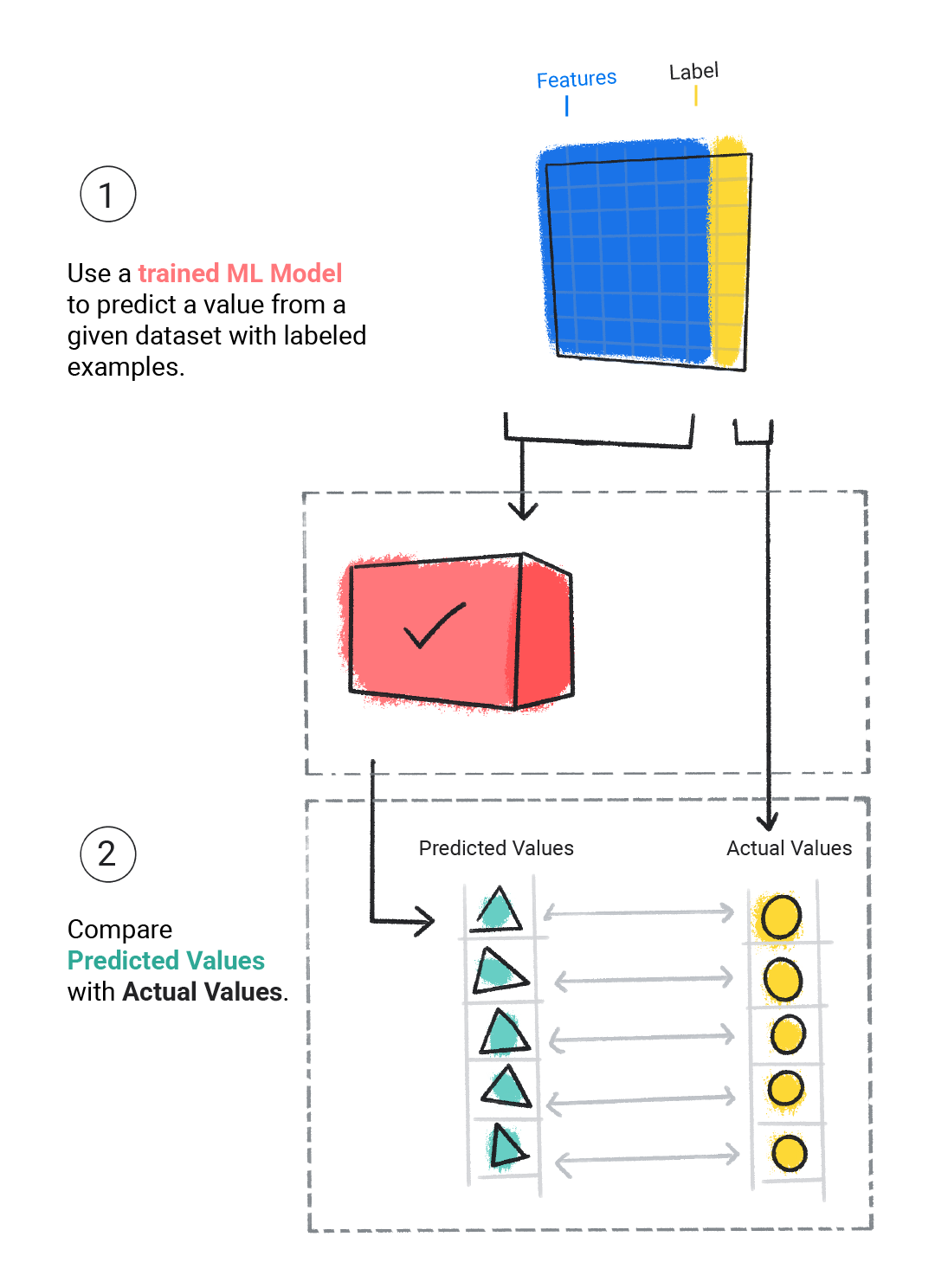
Şekil 4. Bir ML modelinin tahminlerini gerçek değerlerle karşılaştırarak modelin değerlendirilmesi.
Modelin tahminlerine bağlı olarak, modeli gerçek bir uygulamaya dağıtmadan önce daha fazla eğitim ve değerlendirme yapabiliriz.
Öğrendiklerinizi test etme
Çıkarma
Modeli değerlendirmeyle elde ettiğimiz sonuçlardan memnun kaldıktan sonra, etiketlenmemiş örneklerde çıkarım adı verilen tahminler yapmak için modeli kullanabiliriz. Hava durumu uygulaması örneğinde, modele mevcut hava koşullarını (ör. sıcaklık, atmosferik basınç ve bağıl nem) veririz. Model de yağmur miktarını tahmin eder.