監督式學習的任務已明確定義,可應用於各種情境,例如識別垃圾郵件或預測降雨量。
監督式學習的基本概念
監督式機器學習的核心概念如下:
- 資料
- 模型
- 訓練
- 評估中
- 推論
資料
資料是機器學習的動力來源,資料以文字和數字的形式儲存在表格中,或是以圖像和音訊檔案中擷取的像素和波形值的形式存在。我們會將相關資料儲存在資料集中。舉例來說,我們可能有以下資料集:
- 貓的圖片
- 房價
- 天氣資訊
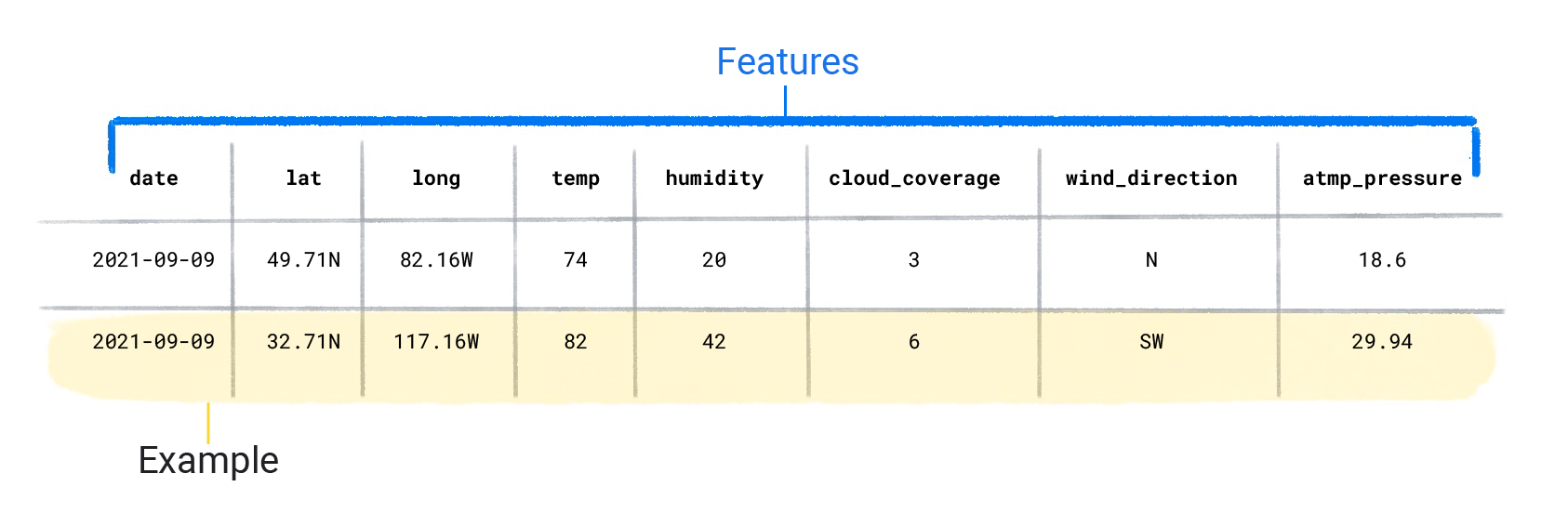
資料集是由個別示例組成,其中包含特徵和標籤。您可以將示例視為試算表中的單一資料列。特徵是監督式模型用來預測標籤的值。標籤是「答案」,也就是我們希望模型預測的值。在預測降雨量的天氣模型中,特徵可能包括緯度、經度、溫度、濕度、雲層覆蓋率、風向和大氣壓。標籤為「降雨量」。
同時包含特徵和標籤的示例稱為標記示例。
兩個標記範例

相反地,未標示的示例包含特徵,但沒有標籤。建立模型後,模型會根據特徵預測標籤。
兩個未標記的示例
資料集特性
資料集的特徵在於其大小和多樣性。大小代表範例數量。多樣性代表這些範例涵蓋的範圍。優質資料集的資料量大且多樣性高。
資料集可以是大型且多樣化、大型但不具多樣性,或是小型但極具多樣性。換句話說,大量的資料集並不能保證足夠的多樣性,而多樣性極高的資料集也無法保證有足夠的範例。
舉例來說,資料集可能包含 100 年的資料,但只限於 7 月份。使用這個資料集來預測 1 月的降雨量,會產生不準確的預測結果。相反地,資料集可能只涵蓋幾年,但包含每個月的資料。由於這個資料集不含足夠的年度資料,無法考量變化情形,因此可能會產生不準確的預測結果。
隨堂測驗
資料集也可以透過其地圖項目數量來加以描述。舉例來說,某些氣象資料集可能包含數百個地圖項目,從衛星影像到雲層覆蓋率值都有。其他資料集可能只包含三或四個特徵,例如濕度、大氣壓力和溫度。資料集包含更多功能,有助於模型發現其他模式,並做出更準確的預測。不過,含有更多特徵的資料集不一定會產生可做出更精確預測的模型,因為某些特徵可能與標籤沒有因果關係。
模型
在監督式學習中,模型是複雜的數字集合,定義從特定輸入特徵模式到特定輸出標籤值的數學關係。模型會透過訓練發現這些模式。
訓練
監督式模型必須先經過訓練,才能進行預測。為了訓練模型,我們會為模型提供含有標記範例的資料集。模型的目標是找出最佳解決方案,從特徵預測標籤。模型會比較預測值與標籤的實際值,找出最佳解決方案。模型會根據預測值和實際值之間的差異 (稱為損失),逐步更新解決方案。換句話說,模型會學習特徵和標籤之間的數學關係,以便針對未知資料做出最佳預測。
舉例來說,如果模型預測 1.15 inches 的降雨量,但實際值為 .75 inches,模型會修改解決方案,讓預測值更接近 .75 inches。模型查看資料集中的每個示例 (在某些情況下會查看多次) 後,就會找到一個解決方案,可針對每個示例做出平均最佳預測。
以下示範如何訓練模型:
模型會接收單一標記範例並提供預測結果。
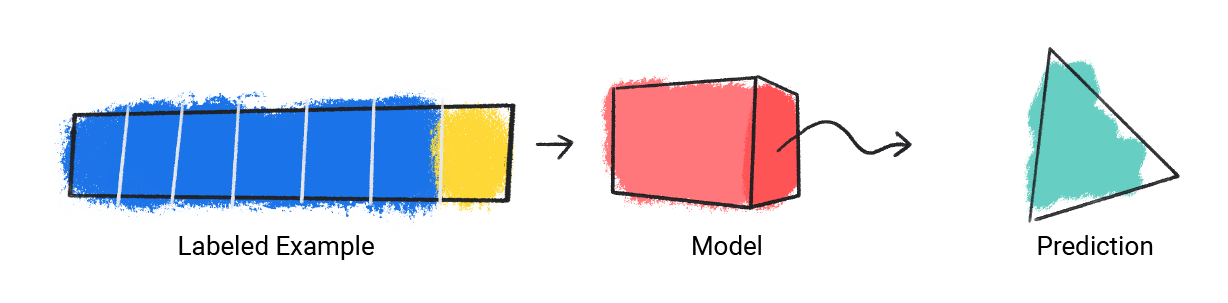
圖 1. 機器學習模型根據標記的範例進行預測。
模型會比較預測值與實際值,並更新解決方案。
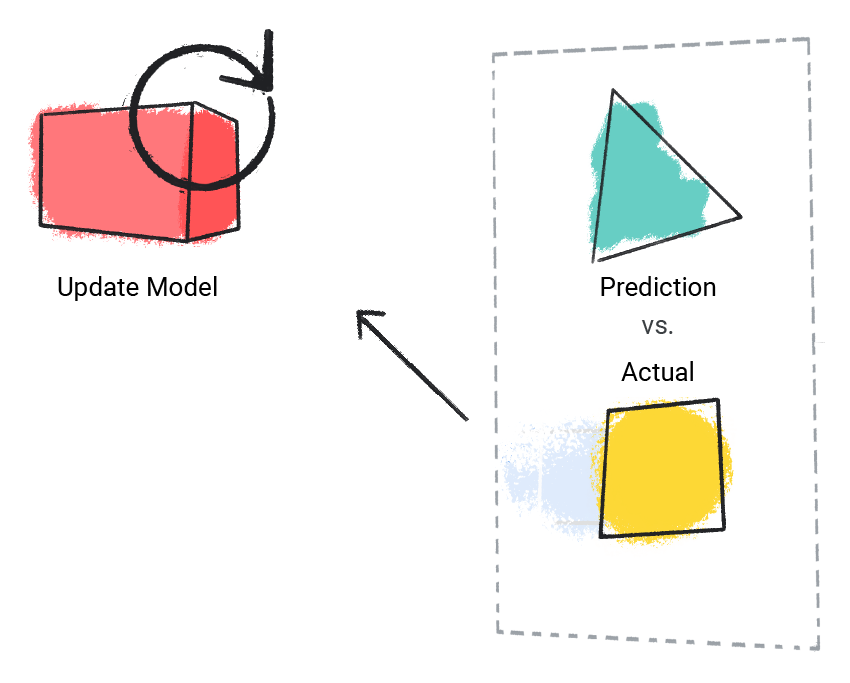
圖 2. 機器學習模型更新預測值。
模型會對資料集中的每個標記示例重複這個程序。
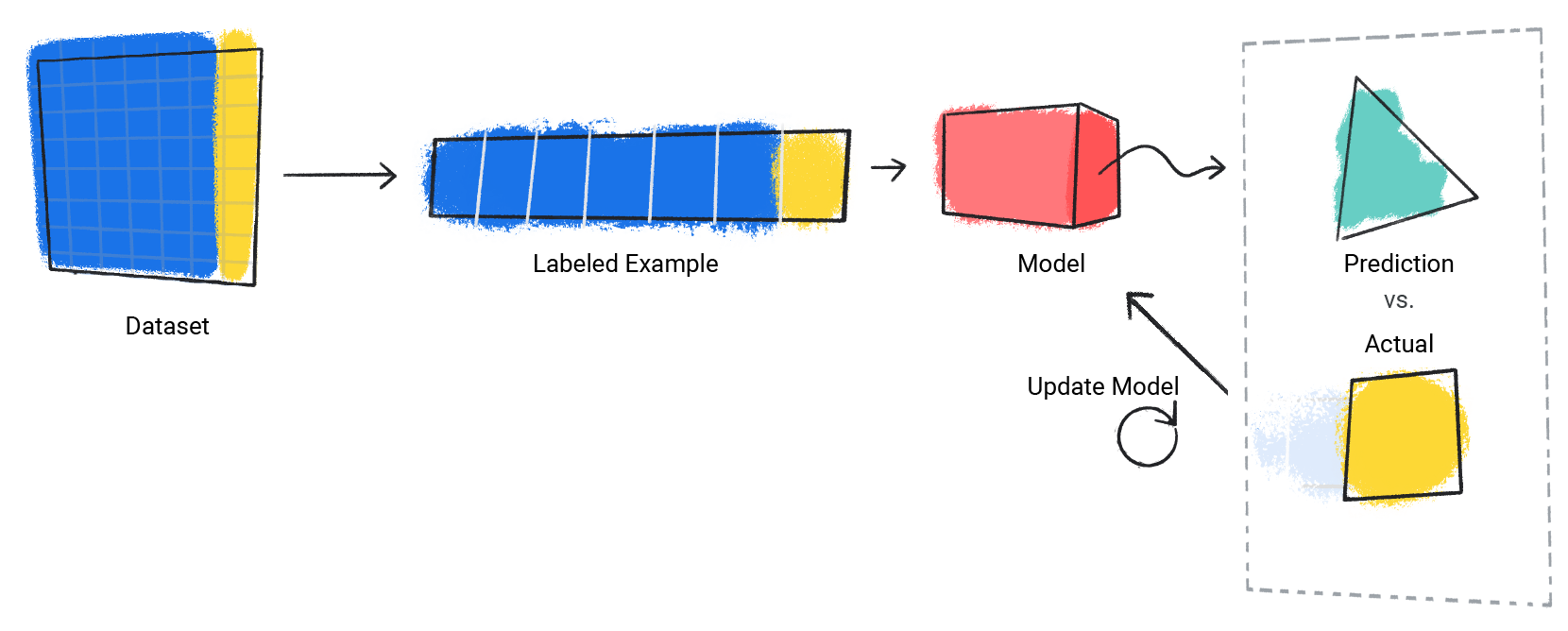
圖 3. 機器學習模型會針對訓練資料集中的每個標記範例更新預測結果。
如此一來,模型就能逐漸學習特徵和標籤之間的正確關係。這也是為什麼大量且多樣化的資料集可產生更優質模型的原因。模型已看到更多資料,且值的範圍更廣泛,因此可更精確地瞭解特徵和標籤之間的關係。
在訓練期間,機器學習專家可以微調模型用於預測的設定和功能。舉例來說,某些功能的預測能力比其他功能更強。因此,機器學習專家可以選擇模型在訓練期間使用的特徵。舉例來說,假設天氣資料集包含 time_of_day 做為特徵。在這種情況下,機器學習專家可以在訓練期間新增或移除 time_of_day,看看模型是否在有或無 time_of_day 的情況下預測得更準確。
評估中
我們會評估已訓練的模型,判斷模型的學習成效。評估模型時,我們會使用已標示的資料集,但只會將資料集的特徵提供給模型。然後將模型的預測結果與標籤的實際值進行比較。
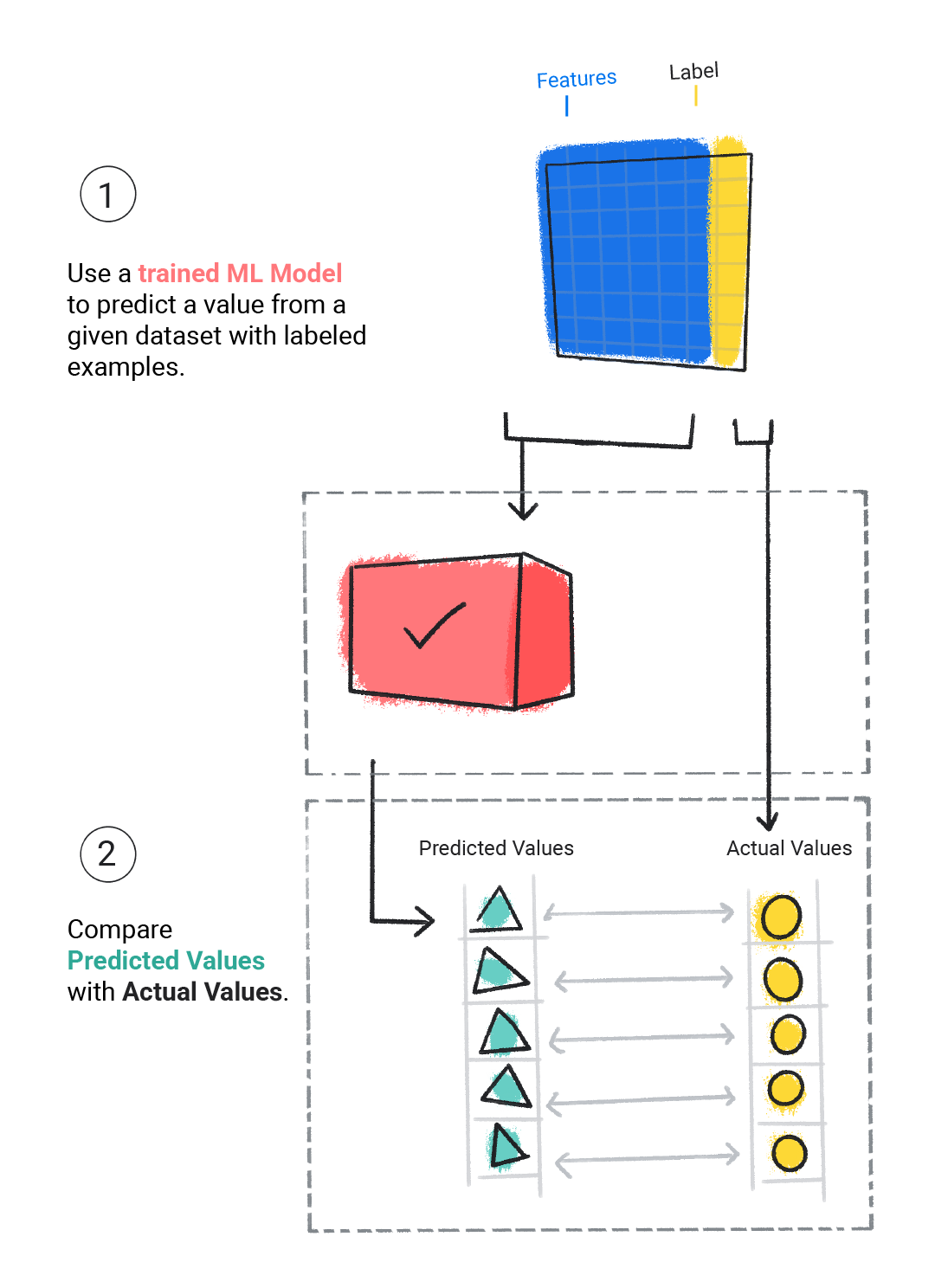
圖 4. 比較機器學習模型的預測結果與實際值,藉此評估模型。
視模型預測結果而定,我們可能會在實際應用程式中部署模型前,進行更多訓練和評估。
隨堂測驗
推論
一旦滿意評估模型的結果,我們就可以使用模型針對未標註的範例進行預測,也就是所謂的推論。在天氣應用程式範例中,我們會將目前的天氣狀況 (例如溫度、大氣壓力和相對濕度) 提供給模型,讓模型預測降雨量。