Pertanyaan berikut akan membantu Anda memantapkan pemahaman tentang konsep ML inti.
Daya prediktif
Model ML yang diawasi dilatih menggunakan set data dengan contoh berlabel. Model
mempelajari cara memprediksi label dari fitur. Namun, tidak setiap fitur dalam
set data memiliki kemampuan prediktif. Dalam beberapa kasus, hanya beberapa fitur yang berfungsi sebagai
prediktor label. Dalam set data di bawah, gunakan harga sebagai label
dan kolom lainnya sebagai fitur.

Menurut Anda, tiga fitur mana yang kemungkinan besar merupakan prediktor terbaik untuk harga mobil?
Merek_model, tahun, mil.
Merek/model, tahun, dan jarak tempuh mobil kemungkinan merupakan
prediktor terkuat untuk harganya.
Warna, tinggi, make_model.
Tinggi dan warna mobil bukanlah prediktor yang kuat untuk harga
mobil.
Miles, gearbox, make_model.
Kotak roda gigi bukan merupakan prediktor utama harga.
Tire_size, wheel_base, year.
Ukuran ban dan jarak sumbu roda bukanlah prediktor yang kuat untuk harga
mobil.
Supervised dan unsupervised learning
Berdasarkan masalahnya, Anda akan menggunakan pendekatan yang diawasi atau tidak diawasi.
Misalnya, jika Anda mengetahui sebelumnya nilai atau kategori yang ingin diprediksi,
Anda akan menggunakan pembelajaran terawasi. Namun, jika Anda ingin mempelajari apakah set data Anda berisi segmentasi atau pengelompokan contoh terkait, Anda akan menggunakan pembelajaran tanpa pengawasan.
Misalkan Anda memiliki set data pengguna untuk situs belanja online, dan set data tersebut
berisi kolom berikut:

Jika Anda ingin memahami jenis pengguna yang mengunjungi situs, apakah Anda akan menggunakan supervised learning atau unsupervised learning?
Unsupervised learning.
Karena kita ingin model mengelompokkan grup pelanggan terkait,
kita akan menggunakan pembelajaran tanpa pengawasan. Setelah model mengelompokkan pengguna,
kita akan membuat nama kita sendiri untuk setiap cluster, misalnya,
"pencari diskon", "pemburu promo", "peselancar", "setia",
dan "pengembara".
Supervised learning karena saya mencoba memprediksi kelas
pengguna.
Dalam supervised learning, set data harus berisi label yang
coba Anda prediksi. Dalam set data, tidak ada label yang merujuk pada kategori pengguna.
Misalkan Anda memiliki set data penggunaan energi untuk rumah dengan kolom berikut:
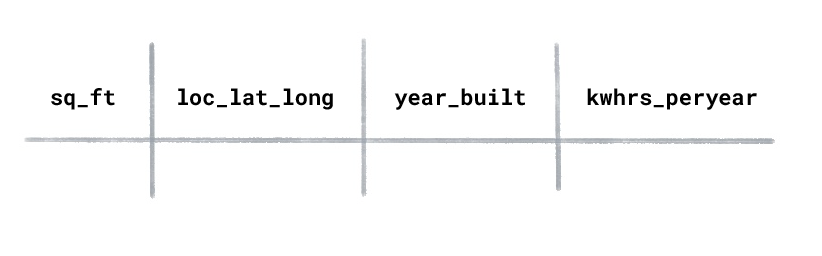
Jenis ML apa yang akan Anda gunakan untuk memprediksi kilowatt jam yang digunakan per
tahun untuk rumah yang baru dibangun?
Supervised learning.
Supervised learning dilatih pada contoh berlabel. Dalam set data ini, "kilowatt jam yang digunakan per tahun” akan menjadi label karena ini adalah nilai yang ingin diprediksi oleh model. Fiturnya adalah
"luas bangunan”, "lokasi”, dan "tahun pembangunan”.
Unsupervised learning.
Unsupervised learning menggunakan contoh tak berlabel. Dalam contoh ini,
"kilowatt hours used per year” akan menjadi label karena ini adalah
nilai yang ingin Anda prediksi oleh model.
Misalnya, Anda memiliki set data penerbangan dengan kolom berikut:

Jika Anda ingin memprediksi biaya tiket pesawat, apakah Anda akan menggunakan
regresi atau klasifikasi?
Regresi
Output model regresi adalah nilai numerik.
Klasifikasi
Output model klasifikasi adalah nilai diskret,
biasanya berupa kata. Dalam hal ini, biaya tiket pesawat adalah
nilai numerik.
Berdasarkan set data, dapatkah Anda melatih model klasifikasi
untuk mengklasifikasikan biaya tiket pesawat sebagai
"tinggi", "sedang", atau "rendah"?
Ya, tetapi kita harus mengonversi nilai numerik di kolom
airplane_ticket_cost menjadi nilai kategoris terlebih dahulu.
Anda dapat membuat model klasifikasi dari set data.
Anda akan melakukan sesuatu seperti berikut:
- Temukan biaya rata-rata tiket dari bandara keberangkatan ke
bandara tujuan.
- Tentukan batas yang akan membentuk "tinggi", "sedang",
dan "rendah".
- Bandingkan perkiraan biaya dengan nilai minimum dan maksimum, lalu keluarkan
kategori nilai yang termasuk dalam rentang tersebut.
Tidak. Model klasifikasi tidak dapat dibuat. Nilai
airplane_ticket_cost bersifat numerik, bukan kategoris.
Dengan sedikit upaya, Anda dapat membuat model klasifikasi.
Tidak. Model klasifikasi hanya memprediksi dua kategori, seperti
spam atau not_spam. Model ini perlu memprediksi
tiga kategori.
Model klasifikasi dapat memprediksi beberapa kategori. Model ini
disebut model klasifikasi multikelas.
Melatih dan mengevaluasi
Setelah melatih model, kita mengevaluasinya menggunakan set data dengan contoh berlabel dan membandingkan nilai yang diprediksi model dengan nilai sebenarnya label.
Pilih dua jawaban terbaik untuk pertanyaan tersebut.
Jika prediksi model sangat jauh, apa yang dapat Anda lakukan untuk
memperbaikinya?
Latih ulang model, tetapi hanya gunakan fitur yang menurut Anda memiliki
daya prediksi terkuat untuk label.
Melatih ulang model dengan lebih sedikit fitur, tetapi memiliki kemampuan prediksi yang lebih baik, dapat menghasilkan model yang membuat prediksi yang lebih baik.
Anda tidak dapat memperbaiki model yang prediksinya sangat jauh.
Anda dapat memperbaiki model yang prediksinya tidak akurat. Sebagian besar model memerlukan beberapa putaran pelatihan hingga menghasilkan prediksi yang berguna.
Latih ulang model menggunakan set data yang lebih besar dan beragam.
Model yang dilatih pada set data dengan lebih banyak contoh dan rentang nilai yang lebih luas dapat menghasilkan prediksi yang lebih baik karena model memiliki solusi umum yang lebih baik untuk hubungan antara fitur dan label.
Coba pendekatan pelatihan yang berbeda. Misalnya, jika Anda menggunakan
pendekatan yang diawasi, coba pendekatan yang tidak diawasi.
Pendekatan pelatihan yang berbeda tidak akan menghasilkan prediksi yang lebih baik.
Sekarang Anda siap mengambil langkah berikutnya dalam perjalanan ML Anda: