تساعدك الأسئلة التالية في تعزيز فهمك للمفاهيم الأساسية لتعلُّم الآلة.
إمكانيات التوقّعات
يتم تدريب نماذج تعلُّم الآلة الخاضعة للإشراف باستخدام مجموعات بيانات تتضمّن أمثلة مصنّفة. يتعرّف النموذج
على كيفية توقّع التصنيف من السمات. ومع ذلك، ليست كل ميزة في
مجموعة بيانات معيّنة لها قدرة تنبؤية. في بعض الحالات، لا تؤدي سوى بعض الميزات إلى تحديد التصنيف. في مجموعة البيانات أدناه، استخدِم السعر كسمة،
والأعمدة المتبقية كسمات.

ما هي الميزات الثلاث التي تعتقد أنّها من المرجّح أن تكون أفضل العوامل التي تحدّد سعر السيارة؟
Make_model وyear وmiles
من المرجّح أن تكون العلامة التجارية للسيارة أو طرازها وسنة التصنيع والمسافة المقطوعة من بين أهم العوامل التي تساهم في تحديد سعرها.
اللون والارتفاع وmake_model
لا يشكّل ارتفاع السيارة ولونها مؤشرات قوية لسعرها.
أميال، علبة التروس، طراز_السيارة
لا يُعدّ صندوق التروس مؤشرًا رئيسيًا للسعر.
Tire_size وwheel_base وyear
لا يُعدّ حجم الإطارات وقاعدة العجلات مؤشّرين قويّين لسعر السيارة.
التعلُّم الموجَّه وغير الموجَّه
استنادًا إلى المشكلة، ستستخدم إما نهجًا خاضعًا للإشراف أو غير خاضع للإشراف.
على سبيل المثال، إذا كنت تعرف مسبقًا القيمة أو الفئة التي تريد توقّعها،
ستستخدم التعلّم الخاضع للإشراف. ومع ذلك، إذا أردت معرفة ما إذا كانت مجموعة البيانات
تحتوي على أيّ تقسيمات أو تجميعات من الأمثلة ذات الصلة، يمكنك استخدام
التعلم غير الخاضع للإشراف.
لنفترض أنّ لديك مجموعة بيانات للمستخدمين لموقع إلكتروني للتسوّق على الإنترنت، وأنّها تحتوي على الأعمدة التالية:

إذا أردت فهم أنواع المستخدمين الذين يزورون الموقع الإلكتروني، هل ستستخدم التعلّم الخاضع للإشراف أم التعلّم غير الخاضع للإشراف؟
التعلُّم غير الموجَّه
لأنّنا نريد من النموذج تجميع مجموعات من العملاء المرتبطين،
سنستخدم التعلّم غير الخاضع للإشراف. بعد أن عمل النموذج على تجميع المستخدِمين،
أنشأنا أسماء خاصة بنا لكل مجموعة، على سبيل المثال،
"مُحبّو الخصومات" و"مُحبّو الصفقات" و"المتصفّحون" و"المستخدِمون الأوفياء"
و"المتجوّلون".
التعلّم الخاضع للإشراف لأنّني أحاول توقّع الفئة التي
ينتمي إليها المستخدِم.
في التعلّم الخاضع للإشراف، يجب أن تحتوي مجموعة البيانات على التصنيف الذي تحاول
توقّعه. في مجموعة البيانات، لا يتوفّر تصنيف يشير إلى
فئة من المستخدمين.
لنفترض أنّ لديك مجموعة بيانات عن استهلاك الطاقة في المنازل تتضمّن الأعمدة التالية:
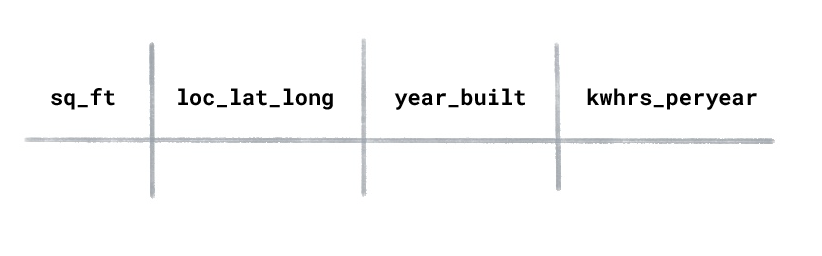
ما هو نوع تعلُّم الآلة الذي ستستخدمه للتنبؤ بساعات الكيلوواط المستخدَمة في السنة
لمنزل تم تشييده حديثًا؟
التعلُّم الخاضع للإشراف
يتم تدريب أسلوب التعلّم المُوجّه على أمثلة مصنّفة. في مجموعة البيانات هذه،
سيكون "كيلووات ساعة مستخدَمة في السنة" هو التصنيف لأنّه
القيمة التي تريد من النموذج توقّعها. ستكون الميزات هي
"المساحة المربعة" و"الموقع الجغرافي" و"سنة الإنشاء".
التعلُّم غير الخاضع للإشراف
يستخدم التعلُّم غير الخاضع للإشراف أمثلة غير مصنَّفة. في هذا المثال،
سيكون "كيلوواط ساعة مستخدَمة في السنة" هو التصنيف لأنّه هو
القيمة التي تريد من النموذج توقّعها.
لنفترض أنّ لديك مجموعة بيانات للرحلات الجوية تتضمّن الأعمدة التالية:

إذا أردت توقّع تكلفة تذكرة طائرة، هل ستستخدم
تحليل الانحدار أو التصنيف؟
الانحدار
الناتج الذي يقدّمه نموذج الانحدار هو قيمة رقمية.
التصنيف
الناتج الذي يصدره نموذج التصنيف هو قيمة منفصلة،
وتكون عادةً كلمة. في هذه الحالة، تكون تكلفة تذكرة الطائرة
قيمة رقمية.
استنادًا إلى مجموعة البيانات، هل يمكنك تدريب نموذج تصنيف
لتصنيف تكلفة تذكرة الطائرة على أنّها
"مرتفعة" أو "متوسطة" أو "منخفضة"؟
نعم، ولكن علينا أولاً تحويل القيم الرقمية في عمود
airplane_ticket_cost إلى قيم تصنيفية.
من الممكن إنشاء نموذج تصنيف من مجموعة البيانات.
يمكنك إجراء ما يلي:
- ابحث عن متوسط تكلفة التذكرة من مطار المغادرة إلى
مطار الوجهة.
- حدِّد الحدود الدنيا التي تشكل "مرتفعًا" و"متوسطًا"
و "منخفضًا".
- قارِن التكلفة المتوقّعة بالحدود الدنيا وأدخِل
الفئة التي تندرج ضمنها القيمة.
لا، لا يمكن إنشاء نموذج تصنيف. قيم
airplane_ticket_cost رقمية وليست تصنيفية.
وبقليل من الجهد، يمكنك إنشاء نموذج تصنيف.
لا، لا تتنبأ نماذج التصنيف إلا بفئتَين فقط، مثل
spam أو not_spam. يجب أن يتوقّع هذا النموذج
ثلاث فئات.
يمكن لنماذج التصنيف توقّع فئات متعدّدة. ويُطلق عليها اسم نماذج التصنيف المتعدّد الفئات.
التدريب والتقييم
بعد تدريب نموذج، نقيّمه باستخدام مجموعة بيانات تتضمّن أمثلة مصنّفة، ونقيس القيمة المتوقّعة للنموذج بالقيمة الفعلية للسمة.
اختَر أفضل إجابتَين عن السؤال.
إذا كانت توقّعات النموذج بعيدة كل البعد عن الواقع، ما الذي يمكنك فعله لتحسينها؟
أعِد تدريب النموذج، ولكن استخدِم الميزات التي تعتقد أنّها تمتلك أعلى قدرة على التوقّع للتصنيف.
يمكن أن تؤدّي إعادة تدريب النموذج باستخدام ميزات أقلّ، ولكنّها تتمتع بقدرة أكبر على التوقّع، إلى إنشاء نموذج يقدّم توقّعات أفضل.
لا يمكنك إصلاح نموذج توقّعاته بعيدة كل البعد عن الواقع.
من الممكن إصلاح نموذج تتوفّر فيه توقّعات غير دقيقة. تتطلّب معظم النماذج جولات تدريب متعدّدة إلى أن تقدّم توقّعات مفيدة.
أعِد تدريب النموذج باستخدام مجموعة بيانات أكبر وأكثر تنوعًا.
يمكن أن تُقدّم النماذج التي تم تدريبها على مجموعات بيانات تتضمّن المزيد من الأمثلة ونطاقًا أوسع من القيم توقعات أفضل لأنّ النموذج يتضمّن حلًا عامًا أفضل للعلاقة بين السمات والتصنيف.
جرِّب نهجًا تدريبيًا مختلفًا. على سبيل المثال، إذا استخدمت نهجًا خاضعًا للإشراف، جرِّب نهجًا غير خاضع للإشراف.
ولن يؤدي نهج تدريبي مختلف إلى تقديم توقعات أفضل.
أنت الآن مستعد لاتخاذ الخطوة التالية في رحلة تعلُّم الآلة:
دليل "الأشخاص والذكاء الاصطناعي" إذا كنت
تبحث عن مجموعة من الطرق وأفضل الممارسات والأمثلة التي يقدّمها
موظفو Google وخبراء المجال والأبحاث الأكاديمية لاستخدام الذكاء الاصطناعي
صياغة المشكلة: إذا كنت تبحث عن
منهج تم اختباره على أرض الواقع لإنشاء نماذج تعلُّم الآلة وتجنُّب المشاكل الشائعة
أثناء ذلك
دورة مكثّفة عن تعلُّم الآلة إذا كنت
مستعدًا لنهج عملي ومفصّل للتعرّف على مزيد من المعلومات حول الذكاء الاصطناعي