Las siguientes preguntas te ayudarán a consolidar tus conocimientos sobre los conceptos básicos del AA.
Poder predictivo
Los modelos de AA supervisados se entrenan con conjuntos de datos con ejemplos etiquetados. El modelo aprende a predecir la etiqueta a partir de los atributos. Sin embargo, no todos los atributos de un conjunto de datos tienen poder predictivo. En algunos casos, solo algunas características actúan como predictores de la etiqueta. En el siguiente conjunto de datos, usa el precio como la etiqueta y las columnas restantes como las características.

¿Cuáles de las siguientes opciones crees que son los mejores predictores del precio de un automóvil?
Make_model, year, miles
Es probable que la marca o el modelo, el año y el kilometraje de un automóvil sean algunos de los predictores más sólidos de su precio.
Color, altura y make_model.
La altura y el color de un automóvil no son predictores sólidos del precio de un automóvil.
Millas, caja de cambios, marca_modelo.
La caja de cambios no es un predictor principal del precio.
Tire_size, wheel_base, year.
El tamaño de los neumáticos y la distancia entre ejes no son buenos predictores del precio de un automóvil.
Aprendizaje supervisado y no supervisado
Según el problema, usarás un enfoque supervisado o no supervisado.
Por ejemplo, si conoces de antemano el valor o la categoría que deseas predecir, deberías usar el aprendizaje supervisado. Sin embargo, si quieres saber si tu conjunto de datos contiene segmentaciones o agrupaciones de ejemplos relacionados, debes usar el aprendizaje no supervisado.
Supongamos que tienes un conjunto de datos de usuarios de un sitio web de compras en línea que contiene las siguientes columnas:

Si quisieras comprender los tipos de usuarios que visitan el sitio, ¿usarías el aprendizaje supervisado o no supervisado?
Aprendizaje no supervisado.
Como queremos que el modelo agrupe grupos de clientes relacionados,
usaremos el aprendizaje no supervisado. Después de que el modelo agrupó a los usuarios,
creamos nuestros propios nombres para cada clúster, por ejemplo,
"buscadores de descuentos", "buscadores de ofertas", "navegadores", "leales"
y "errantes".
Aprendizaje supervisado porque intento predecir a qué clase pertenece un usuario.
En el aprendizaje supervisado, el conjunto de datos debe contener la etiqueta que intentas predecir. En el conjunto de datos, no hay ninguna etiqueta que haga referencia a una categoría de usuario.
Supongamos que tienes un conjunto de datos de uso de energía para casas con las siguientes columnas:
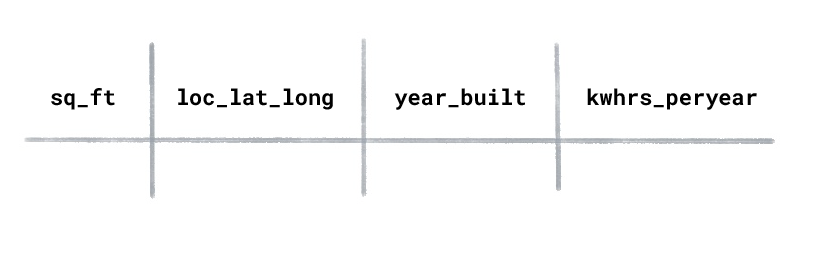
¿Qué tipo de AA usarías para predecir los kilovatios-hora utilizados por año en una casa recién construida?
Aprendizaje supervisado.
El aprendizaje supervisado se entrena con ejemplos etiquetados. En este conjunto de datos, “kilowatt hours used per year” sería la etiqueta porque es el valor que deseas que el modelo prediga. Las características serían “metros cuadrados”, “ubicación” y “año de construcción”.
Aprendizaje no supervisado.
El aprendizaje no supervisado usa ejemplos sin etiqueta. En este ejemplo, “kilowatt hours used per year” sería la etiqueta porque es el valor que deseas que el modelo prediga.
Supongamos que tienes un conjunto de datos de vuelos con las siguientes columnas:

Si quisieras predecir el costo de un boleto de avión, ¿usarías la regresión o la clasificación?
Regresión
El resultado de un modelo de regresión es un valor numérico.
Clasificación
El resultado de un modelo de clasificación es un valor discreto, generalmente una palabra. En este caso, el costo de un boleto de avión es un valor numérico.
En función del conjunto de datos, ¿podrías entrenar un modelo de clasificación para clasificar el costo de un boleto de avión como “alto”, “promedio” o “bajo”?
Sí, pero primero debemos convertir los valores numéricos de la columna airplane_ticket_cost en valores categóricos.
Es posible crear un modelo de clasificación a partir del conjunto de datos.
Harías algo como lo siguiente:
- Busca el costo promedio de un boleto del aeropuerto de salida al aeropuerto de destino.
- Determina los umbrales que constituirían “alto”, “promedio” y “bajo”.
- Compara el costo previsto con los umbrales y muestra la
categoría en la que se encuentra el valor.
No. No es posible crear un modelo de clasificación. Los valores de airplane_ticket_cost son numéricos, no categóricos.
Con un poco de trabajo, podrías crear un modelo de clasificación.
No. Los modelos de clasificación solo predicen dos categorías, como spam o not_spam. Este modelo tendría que predecir tres categorías.
Los modelos de clasificación pueden predecir varias categorías. Se llaman modelos de clasificación de varias clases.
Entrenamiento y evaluación
Después de entrenar un modelo, lo evaluamos con un conjunto de datos con ejemplos etiquetados y comparamos el valor previsto del modelo con el valor real de la etiqueta.
Selecciona las dos mejores respuestas para la pregunta.
Si las predicciones del modelo están muy lejos, ¿qué podrías hacer para mejorarlas?
Vuelve a entrenar el modelo, pero usa solo las características que crees que tienen el poder predictivo más fuerte para la etiqueta.
Volver a entrenar el modelo con menos atributos, pero con más poder predictivo, puede producir un modelo que realice mejores predicciones.
No puedes corregir un modelo cuyas predicciones están muy lejos.
Es posible corregir un modelo cuyas predicciones no son precisas. La mayoría de los modelos requieren varias rondas de entrenamiento hasta que hacen predicciones útiles.
Vuelve a entrenar el modelo con un conjunto de datos más grande y diverso.
Los modelos entrenados en conjuntos de datos con más ejemplos y un rango más amplio de valores pueden producir mejores predicciones porque el modelo tiene una mejor solución generalizada para la relación entre los atributos y la etiqueta.
Prueba con otro enfoque de entrenamiento. Por ejemplo, si usaste un enfoque supervisado, prueba uno no supervisado.
Un enfoque de entrenamiento diferente no produciría mejores predicciones.
Ya puedes dar el siguiente paso en tu recorrido de AA:
Guía People + AI. Si buscas un conjunto de métodos, prácticas recomendadas y ejemplos presentados por Googlers, expertos de la industria y la investigación académica para usar el AA.
Enmarcado de problemas. Si buscas un enfoque probado en el campo para crear modelos de AA y evitar errores comunes en el camino.
Curso intensivo de aprendizaje automático. Si estás
preparado para un enfoque práctico y detallado para aprender más sobre el AA.