以下の質問は、ML のコアコンセプトの理解を深めるのに役立ちます。
予測力
教師あり ML モデルは、ラベル付きの例を含むデータセットを使用してトレーニングされます。モデルは、特徴からラベルを予測する方法を学習します。ただし、データセット内のすべての特徴に予測力が備わっているわけではありません。場合によっては、ラベルの予測子として機能するのは一部の特徴のみです。次のデータセットでは、price をラベルとして、残りの列を特徴として使用します。

自動車の価格を最も予測できると思われる機能は、次の中から 3 つ選んでください。
Make_model、年、マイル数。
車のメーカー/モデル、年式、走行距離は、価格を予測するうえで最も重要な要素です。
Color、height、make_model。
車の高さと色は、車の価格を予測する強い指標ではありません。
マイル、ギアボックス、make_model。
ギアボックスは価格の主要な予測因子ではありません。
Tire_size、wheel_base、year。
タイヤサイズとホイールベースは、車の価格を予測するうえで有力な指標ではありません。
教師あり学習と教師なし学習
問題に応じて、教師ありまたは教師なしのアプローチを使用します。たとえば、予測する値またはカテゴリが事前にわかっている場合は、教師あり学習を使用します。ただし、データセットに関連するサンプルのセグメンテーションやグループ化が含まれているかどうかを学習する場合は、教師なし学習を使用します。
オンライン ショッピング ウェブサイトのユーザーのデータセットがあり、次の列が含まれているとします。

サイトにアクセスするユーザーの種類を把握したい場合、教師あり学習と教師なし学習のどちらを使用しますか?
教師なし学習。
関連する顧客のグループをモデルでクラスタリングするため、教師なし学習を使用します。モデルがユーザーをクラスタ化した後、各クラスタに独自の名前を作成します(「割引を求める人」、「お買い得を求める人」、「サーファー」、「ロイヤル」、「放浪者」など)。
教師あり学習。ユーザーがどのクラスに属しているかを予測しようとしているため。
教師あり学習では、データセットに予測しようとしているラベルが含まれている必要があります。データセットに、ユーザーのカテゴリを参照するラベルがない。
家屋のエネルギー使用量のデータセットに次の列があるとします。
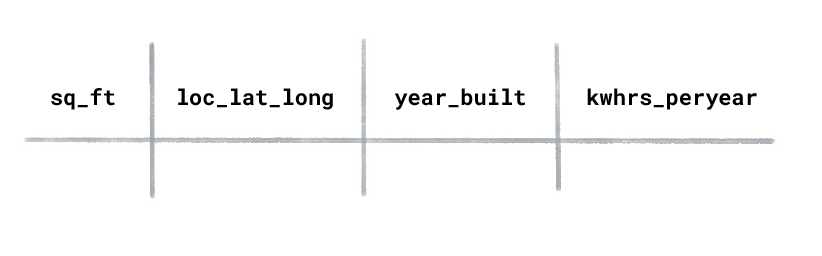
新築住宅で年間に使用されるキロワット時を予測するには、どのタイプの ML を使用すればよいですか。
教師あり学習。
教師あり学習は、ラベル付きのサンプルでトレーニングします。このデータセットでは、モデルに予測させる値である「年間使用電力量」がラベルになります。特徴量は「面積」、「場所」、「築年数」です。
教師なし学習。
教師なし学習では、ラベルのないサンプルを使用します。この例では、モデルに予測させる値であるため、「年間使用電力量」がラベルになります。
次のような列を含むフライト データセットがあるとします。

航空券の費用を予測する場合、回帰分析と分類のどちらを使用しますか?
分類
分類モデルの出力は離散値(通常は単語)です。この場合、航空券の費用は数値です。
データセットに基づいて、航空券の費用を「高」、「平均」、「低」に分類する分類モデルをトレーニングできますか?
はい。ただし、まず airplane_ticket_cost 列の数値をカテゴリ値に変換する必要があります。
このデータセットから分類モデルを作成できます。次のようにします。
- 出発地の空港から目的地の空港までの航空券の平均価格を確認します。
- 「高」、「平均」、「低」を構成するしきい値を決定します。
- 予測された費用をしきい値と比較し、値が属するカテゴリを出力します。
いいえ。分類モデルを作成することはできません。airplane_ticket_cost 値はカテゴリではなく数値です。
少し手間をかけて、分類モデルを作成できます。
いいえ。分類モデルは、spam や not_spam などの 2 つのカテゴリのみを予測します。このモデルでは、3 つのカテゴリを予測する必要があります。
分類モデルは複数のカテゴリを予測できます。これらはマルチクラス分類モデルと呼ばれます。
トレーニングと評価
モデルをトレーニングしたら、ラベル付きの例を含むデータセットを使用してモデルを評価し、モデルの予測値とラベルの実際の値を比較します。
質問に最も適切な回答を 2 つ選択してください。
モデルの予測が大きく外れている場合、予測を改善するにはどうすればよいですか。
モデルを再トレーニングしますが、ラベルの予測力が最も高いと思われる特徴のみを使用します。
特徴の数は少ないが予測力が優れたモデルを再トレーニングすると、より正確な予測を行うモデルを生成できます。
予測が大きく外れているモデルは修正できません。
予測が外れたモデルは修正できます。ほとんどのモデルでは、有用な予測を行うまで複数回のトレーニングが必要です。
より大規模で多様なデータセットを使用してモデルを再トレーニングします。
サンプル数が多く、値の範囲が広いデータセットでトレーニングされたモデルは、特徴とラベルの関係に対する一般化されたソリューションが優れているため、より優れた予測を生成できます。
別のトレーニング方法を試します。たとえば、教師あり学習アプローチを使用した場合は、教師なし学習アプローチを試します。
別のトレーニング方法では、より良い予測は得られません。
これで、ML の次のステップに進む準備が整いました。
People + AI ガイドブック。Google 社員、業界の専門家、学術研究によって提示された ML の使用方法、ベスト プラクティス、例を探している場合。
問題のフレーミング。ML モデルを作成して、その過程でよくある問題を回避するための実証済みのアプローチをお探しの場合。
ML 集中講座。ML について詳しく学び、実践的なアプローチを試す準備ができている。