다음 질문은 핵심 ML 개념을 이해하는 데 도움이 됩니다.
예측력
지도 ML 모델은 라벨이 지정된 예가 포함된 데이터 세트를 사용하여 학습됩니다. 모델은 특성에서 라벨을 예측하는 방법을 학습합니다. 그러나 데이터 세트의 모든 특성이 예측력을 갖는 것은 아닙니다. 경우에 따라 일부 기능만 라벨의 예측자로 작용합니다. 아래 데이터 세트에서 가격을 라벨로, 나머지 열을 기능으로 사용합니다.

자동차 가격을 가장 잘 예측할 수 있는 세 가지 기능은 무엇인가요?
Make_model, year, miles
자동차의 제조업체/모델, 연식, 주행 거리는 가격을 가장 강력하게 예측하는 요소 중 하나일 수 있습니다.
Color, height, make_model
자동차의 높이와 색상은 자동차 가격을 예측하는 데 큰 도움이 되지 않습니다.
Miles, gearbox, make_model.
변속기는 가격의 주요 예측 요소가 아닙니다.
Tire_size, wheel_base, year
타이어 크기와 휠베이스는 자동차 가격을 예측하는 데 큰 도움이 되지 않습니다.
지도 학습 및 비지도 학습
문제에 따라 감독 방식 또는 비감독 방식을 사용합니다.
예를 들어 예측하려는 값이나 카테고리를 미리 알고 있다면 감독 학습을 사용합니다. 하지만 데이터 세트에 관련 예시의 세분화 또는 그룹이 포함되어 있는지 알아보려면 감독 없는 학습을 사용합니다.
온라인 쇼핑 웹사이트의 사용자 데이터 세트가 있고 여기에 다음 열이 포함되어 있다고 가정해 보겠습니다.

사이트를 방문하는 사용자 유형을 파악하려면 지도 학습과 비지도 학습 중 어느 학습을 사용해야 하나요?
비지도 학습
모델이 관련성 높은 고객 그룹을 클러스터링하도록 하려면 비지도 학습을 사용합니다. 모델이 사용자를 클러스터링한 후 각 클러스터에 자체 이름을 만듭니다(예: '할인 추구자', '특가 사냥꾼', '방문자', '충성도 높음', '방랑자').
지도 학습: 사용자가 속한 클래스를 예측하려고 하기 때문입니다.
지도 학습에서는 데이터 세트에 예측하려는 라벨이 포함되어야 합니다. 데이터 세트에는 사용자 카테고리를 나타내는 라벨이 없습니다.
다음과 같은 열이 있는 주택 에너지 사용량 데이터 세트가 있다고 가정해 보겠습니다.
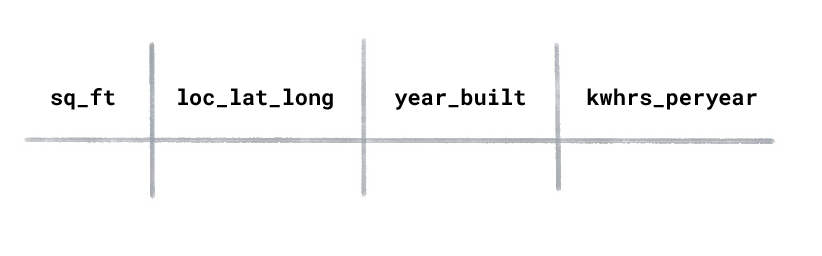
새로 지어진 주택에서 연간 사용되는 킬로와트시를 예측하려면 어떤 유형의 ML을 사용해야 하나요?
지도 학습
지도 학습은 라벨이 지정된 예를 학습합니다. 이 데이터 세트에서 '연간 사용된 킬로와트-시'가 모델에서 예측할 값이므로 라벨이 됩니다. 특성은 '평방 피트', '위치', '건축 연도'입니다.
비지도 학습
비지도 학습은 라벨이 지정되지 않은 예를 사용합니다. 이 예시에서는 '연간 사용된 킬로와트-시'가 라벨이 됩니다. 모델에서 예측할 값이기 때문입니다.
다음과 같은 열이 있는 항공편 데이터 세트가 있다고 가정해 보겠습니다.

비행기 티켓 가격을 예측하려면 회귀 분석을 사용해야 하나요, 아니면 분류를 사용해야 하나요?
분류
분류 모델의 출력은 일반적으로 단어인 불연속 값입니다. 이 경우 비행기 티켓 가격은 숫자 값입니다.
데이터 세트를 기반으로 항공권 가격을 '높음', '평균', '낮음'으로 분류하는 분류 모델을 학습할 수 있나요?
예. 하지만 먼저 airplane_ticket_cost 열의 숫자 값을 범주형 값으로 변환해야 합니다.
데이터 세트에서 분류 모델을 만들 수 있습니다.
다음과 같이 실행합니다.
- 출발 공항에서 도착 공항까지의 항공권 평균 가격을 찾습니다.
- '높음', '평균', '낮음'을 구성하는 임계값을 결정합니다.
- 예측된 비용을 임곗값과 비교하고 값이 속한 카테고리를 출력합니다.
아니요. 분류 모델을 만들 수는 없습니다. airplane_ticket_cost 값은 범주형이 아닌 숫자입니다.
약간의 작업으로 분류 모델을 만들 수 있습니다.
아니요. 분류 모델은 spam 또는 not_spam와 같은 두 가지 카테고리만 예측합니다. 이 모델은 세 가지 카테고리를 예측해야 합니다.
분류 모델은 여러 카테고리를 예측할 수 있습니다. 이를 다중 클래스 분류 모델이라고 합니다.
학습 및 평가
모델을 학습한 후 라벨이 지정된 예가 포함된 데이터 세트를 사용하여 모델을 평가하고 모델의 예측 값을 라벨의 실제 값과 비교합니다.
질문에 가장 적절한 답변 2개를 선택하세요.
모델의 예측이 크게 벗어난 경우 이를 개선하려면 어떻게 해야 하나요?
모델을 다시 학습시키되 라벨에 대한 예측력이 가장 강력하다고 생각되는 기능만 사용합니다.
예측력이 더 높지만 특성이 더 적은 모델을 다시 학습하면 더 나은 예측을 하는 모델을 만들 수 있습니다.
예측이 크게 틀린 모델은 수정할 수 없습니다.
예측이 잘못된 모델을 수정할 수 있습니다. 대부분의 모델은 유용한 예측을 할 때까지 여러 번의 학습이 필요합니다.
더 크고 다양한 데이터 세트를 사용하여 모델을 다시 학습시킵니다.
예시가 더 많고 값의 범위가 더 넓은 데이터 세트에서 학습된 모델은 특성과 라벨 간의 관계에 관한 더 나은 일반화된 솔루션을 보유하고 있으므로 더 나은 예측을 생성할 수 있습니다.
다른 학습 방식을 시도해 보세요. 예를 들어 지도 방식을 사용했다면 비지도 방식을 사용해 봅니다.
다른 학습 접근 방식을 사용해도 더 나은 예측을 얻을 수 없습니다.
이제 ML 여정의 다음 단계를 진행할 준비가 되었습니다.
사람 + AI 가이드북 Google 직원, 업계 전문가, 학술 연구에서 제시한 ML 사용을 위한 일련의 방법, 권장사항, 예시를 찾고 있다면
문제 프레이밍 ML 모델을 만들고 그 과정에서 일반적인 함정을 피하기 위한 현장에서 검증된 접근 방식을 찾고 있다면
머신러닝 단기집중과정 ML에 대해 심층적이고 실무적인 접근 방식으로 자세히 알아보고자 하는 경우