Maschinelles Lernen (ML) ist die Grundlage für einige der wichtigsten Technologien, die wir nutzen, von Übersetzungs-Apps bis hin zu autonomen Fahrzeugen. In diesem Kurs werden die wichtigsten Konzepte hinter ML erläutert.
ML bietet eine neue Möglichkeit, Probleme zu lösen, komplexe Fragen zu beantworten und neue Inhalte zu erstellen. Mit maschinellem Lernen kann das Wetter vorhergesagt, Reisezeiten geschätzt, Songs empfohlen, Sätze automatisch vervollständigt, Artikel zusammengefasst und Bilder generiert werden, die es noch nie gab.
Im Grunde ist ML der Prozess des Trainierens einer Software, die als Modell bezeichnet wird, um nützliche Vorhersagen zu treffen oder Inhalte (wie Text, Bilder, Audio oder Video) aus Daten zu generieren.
Angenommen, Sie möchten eine App erstellen, die Niederschlag vorhersagt. Wir könnten entweder einen herkömmlichen oder einen ML-Ansatz verwenden. Bei einem herkömmlichen Ansatz würden wir eine physikbasierte Darstellung der Erdatmosphäre und -oberfläche erstellen und riesige Mengen an Gleichungen der Strömungsmechanik berechnen. Das ist unglaublich schwierig.
Bei einem ML-Ansatz würden wir einem ML-Modell enorme Mengen an Wetterdaten zur Verfügung stellen, bis das ML-Modell schließlich die mathematische Beziehung zwischen Wetterbedingungen, die unterschiedliche Mengen an Regen erzeugen, gelernt hat. Wir würden dem Modell dann die aktuellen Wetterdaten geben und es würde die Regenmenge vorhersagen.
Wissen testen
Arten von ML-Systemen
ML-Systeme fallen je nachdem, wie sie lernen, Vorhersagen zu treffen oder Inhalte zu generieren, in eine oder mehrere der folgenden Kategorien:
- Beaufsichtigtes Lernen
- Unbeaufsichtigtes Lernen
- Reinforcement Learning
- Generative KI
Beaufsichtigtes Lernen
Modelle für überwachtes Lernen können Vorhersagen treffen, nachdem sie viele Daten mit den richtigen Antworten gesehen und dann die Verbindungen zwischen den Elementen in den Daten ermittelt haben, die die richtigen Antworten liefern. Das ist so, als würde ein Schüler oder Student neuen Stoff lernen, indem er sich alte Prüfungen ansieht, die sowohl Fragen als auch Antworten enthalten. Wenn der Schüler oder Student genügend alte Prüfungen durchgearbeitet hat, ist er gut auf eine neue Prüfung vorbereitet. Diese ML-Systeme werden insofern „überwacht“, als ein Mensch dem ML-System Daten mit den bekannten richtigen Ergebnissen zur Verfügung stellt.
Die beiden häufigsten Anwendungsfälle für überwachtes Lernen sind Regression und Klassifizierung.
Regression
Ein Regressionsmodell sagt einen numerischen Wert voraus. Ein Wettermodell, das die Regenmenge in Zoll oder Millimetern vorhersagt, ist beispielsweise ein Regressionsmodell.
Weitere Beispiele für Regressionsmodelle finden Sie in der folgenden Tabelle:
| Szenario | Mögliche Eingabedaten | Numerische Vorhersage |
|---|---|---|
| Zukünftiger Hauspreis | Grundfläche, Postleitzahl, Anzahl der Schlaf- und Badezimmer, Grundstücksgröße, Hypothekenzinssatz, Grundsteuersatz, Baukosten und Anzahl der zum Verkauf stehenden Häuser in der Gegend. | Der Preis des Zuhauses. |
| Zukünftige Fahrzeit | Historische Verkehrsbedingungen (erfasst über Smartphones, Verkehrssensoren, Fahrdienste und andere Navigations-Apps), Entfernung zum Ziel und Wetterbedingungen. | Die Zeit in Minuten und Sekunden, die benötigt wird, um ein Ziel zu erreichen. |
Klassifizierung
Klassifizierungsmodelle sagen die Wahrscheinlichkeit voraus, dass etwas zu einer Kategorie gehört. Im Gegensatz zu Regressionsmodellen, deren Ausgabe eine Zahl ist, geben Klassifizierungsmodelle einen Wert aus, der angibt, ob etwas zu einer bestimmten Kategorie gehört oder nicht. Klassifizierungsmodelle werden beispielsweise verwendet, um vorherzusagen, ob eine E‑Mail Spam ist oder ob ein Foto eine Katze enthält.
Klassifizierungsmodelle werden in zwei Gruppen unterteilt: binäre Klassifizierung und Multiklassenklassifizierung. Binäre Klassifizierungsmodelle geben einen Wert aus einer Klasse aus, die nur zwei Werte enthält, z. B. ein Modell, das entweder rain oder no rain ausgibt. Multiclass-Klassifizierungsmodelle geben einen Wert aus einer Klasse mit mehr als zwei Werten aus, z. B. ein Modell, das entweder rain, hail, snow oder sleet ausgeben kann.
Wissen testen
Unbeaufsichtigtes Lernen
Modelle für nicht überwachtes Lernen treffen Vorhersagen, indem sie Daten erhalten, die keine richtigen Antworten enthalten. Ziel eines Modells für unüberwachtes Lernen ist es, aussagekräftige Muster in den Daten zu erkennen. Mit anderen Worten: Das Modell hat keine Hinweise darauf, wie die einzelnen Daten kategorisiert werden sollen, sondern muss eigene Regeln ableiten.
Ein häufig verwendetes Modell für unbeaufsichtigtes Lernen nutzt eine Technik namens Clustering. Das Modell findet Datenpunkte, die natürliche Gruppierungen abgrenzen.
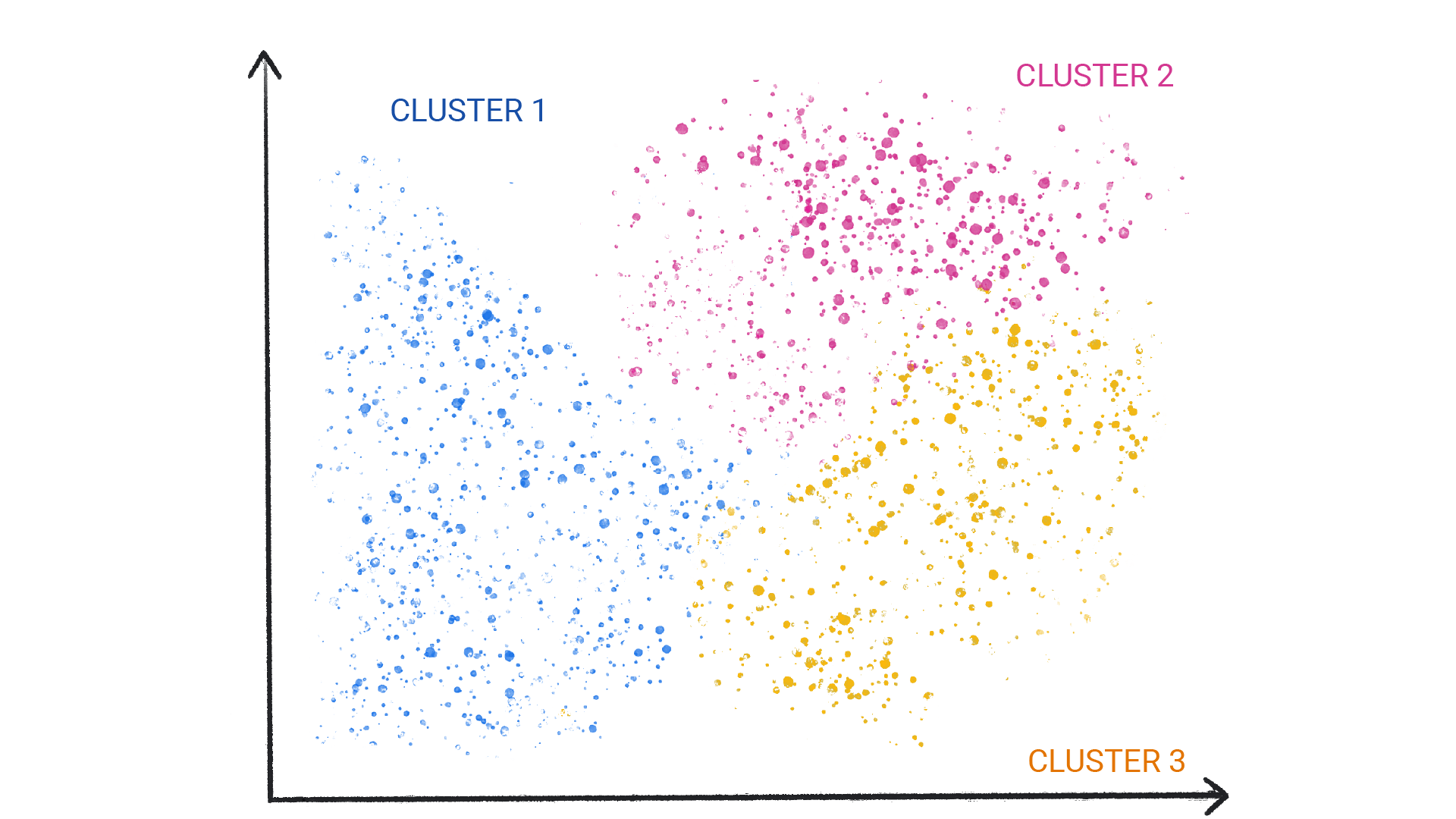
Abbildung 1. Ein ML-Modell, das ähnliche Datenpunkte gruppiert.
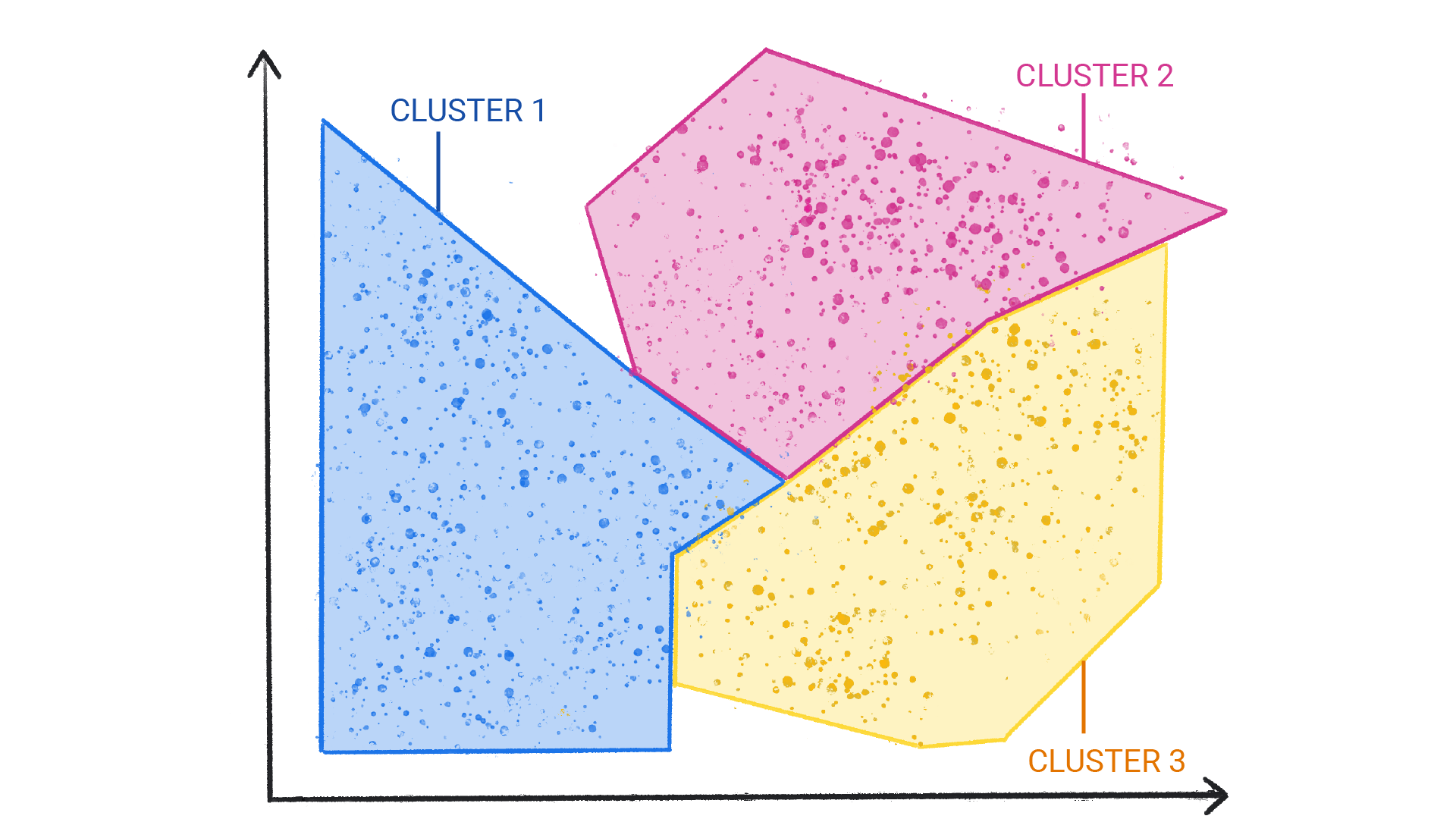
Abbildung 2. Gruppen von Clustern mit natürlichen Abgrenzungen.
Clustering unterscheidet sich von der Klassifizierung, da die Kategorien nicht von Ihnen definiert werden. Ein unüberwachtes Modell könnte beispielsweise ein Wetter-Dataset anhand der Temperatur clustern und so Segmentierungen aufdecken, die die Jahreszeiten definieren. Anschließend können Sie versuchen, diese Cluster auf Grundlage Ihres Verständnisses des Datasets zu benennen.
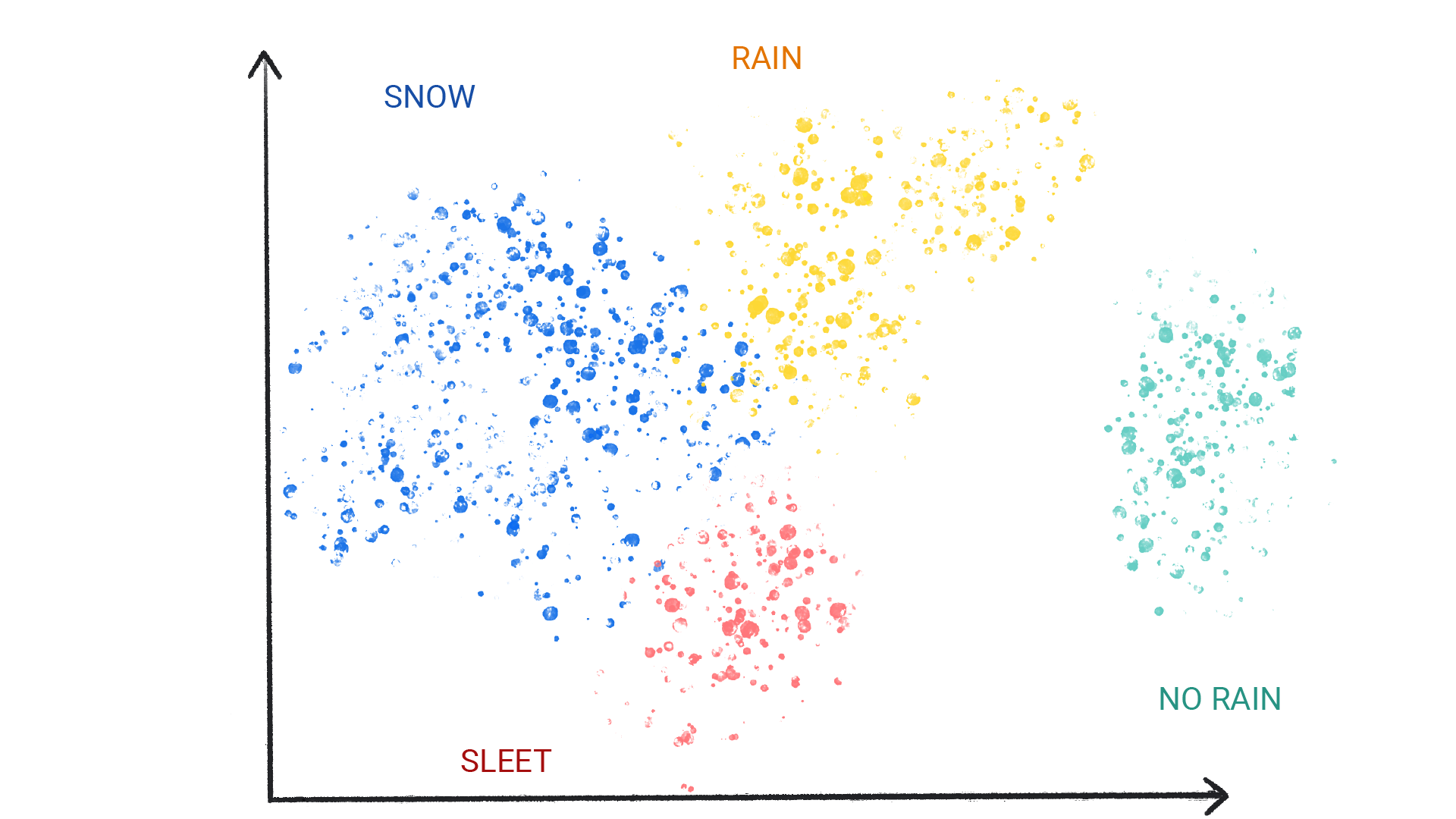
Abbildung 3. Ein ML-Modell, das ähnliche Wettermuster clustert.
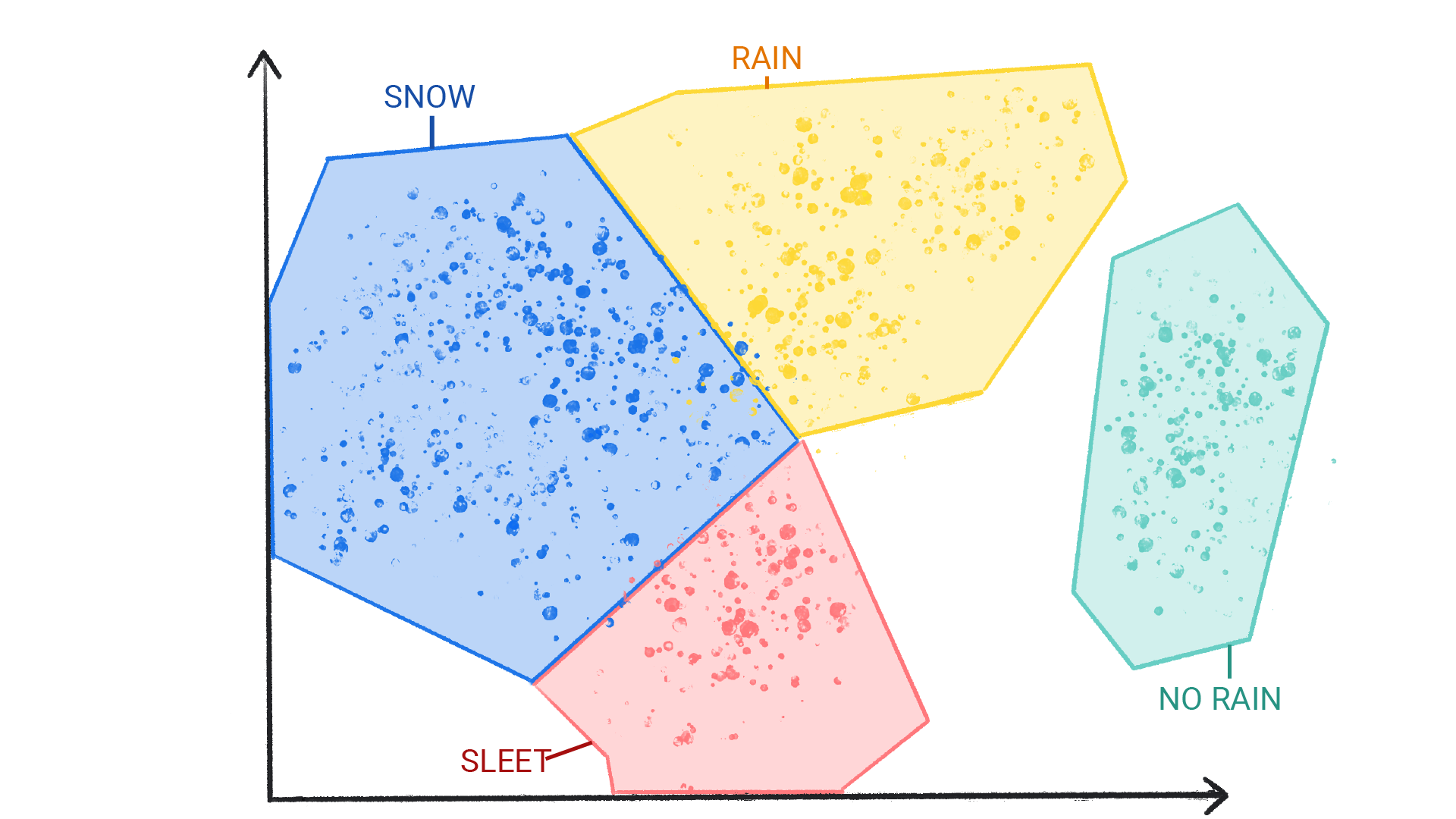
Abbildung 4. Gruppen von Wettermustern, die als Schnee, Graupel, Regen und kein Regen gekennzeichnet sind.
Wissen testen
Reinforcement Learning
Modelle für bestärkendes Lernen treffen Vorhersagen, indem sie basierend auf Aktionen, die in einer Umgebung ausgeführt werden, Belohnungen oder Strafen erhalten. Ein System für bestärkendes Lernen generiert eine Richtlinie, in der die beste Strategie zum Erreichen der meisten Belohnungen definiert wird.
Bestärkendes Lernen wird verwendet, um Roboter für Aufgaben wie das Gehen in einem Raum zu trainieren, und für Softwareprogramme wie AlphaGo, um das Spiel Go zu spielen.
Generative KI
Generative KI ist eine Klasse von Modellen, die Inhalte aus Nutzereingaben erstellt. Generative KI kann beispielsweise einzigartige Bilder, Musikkompositionen und Witze erstellen, Artikel zusammenfassen, erklären, wie eine Aufgabe ausgeführt wird, oder Fotos bearbeiten.
Generative KI kann verschiedene Eingaben verarbeiten und verschiedene Ausgaben erstellen, z. B. Text, Bilder, Audio und Video. Es kann auch Kombinationen dieser Elemente erstellen. Ein Modell kann beispielsweise ein Bild als Eingabe verwenden und ein Bild und Text als Ausgabe erstellen oder ein Bild und Text als Eingabe verwenden und ein Video als Ausgabe erstellen.
Wir können generative Modelle anhand ihrer Ein- und Ausgaben besprechen, die in der Regel als „Eingabetyp“ bis „Ausgabetyp“ geschrieben werden. Im Folgenden finden Sie beispielsweise eine Teilliste einiger Ein- und Ausgaben für generative Modelle:
- Text-zu-Text
- Text zu Bild
- Video aus Text
- Text-zu-Code
- Text-in-Sprache
- Bild und Text-zu-Bild
Die folgende Tabelle enthält Beispiele für generative Modelle, ihre Eingabe und ihre mögliche Ausgabe:
| Modell | Eingabe | Beispielausgabe |
|---|---|---|
| Text-zu-Text | Wer hat das Rennen von Le Mans erfunden? |
Das 24-Stunden-Rennen von Le Mans wurde vom Automobile Club de l'Ouest (ACO) gegründet, einer 1906 gegründeten Motorsportorganisation. Das erste Rennen fand am 26.und 27.Mai 1923 auf dem Circuit de la Sarthe statt, einer 13,426 Kilometer langen Straßenrennstrecke in der Nähe der Stadt Le Mans in Frankreich.
Das Rennen wurde ursprünglich konzipiert, um den ACO und die Region Sarthe zu fördern. Quelle: Bard |
| Text zu Bild | Ein außerirdischer Oktopus schwebt durch ein Portal und liest dabei eine Zeitung. |
 Quelle: Imagen |
| Video aus Text | Ein fotorealistischer Teddybär schwimmt im Meer vor San Francisco. Der Teddybär taucht unter. Der Teddybär schwimmt mit bunten Fischen unter Wasser. Ein Panda schwimmt unter Wasser. |
 Quelle: Phenaki |
| Text-zu-Code | Schreibe eine Python-Schleife, die eine Liste von Zahlen durchläuft und die Primzahlen ausgibt. |
for number in numbers: # Check if the number is prime. is_prime = True for i in range(2, number): if number % i == 0: is_prime = False break # If the number is prime, print it. if is_prime: print(number) Quelle: Bard |
| Bild zu Text |  |
Das ist ein Flamingo. Sie kommen in der Karibik vor. Quelle: Google DeepMind |
Wie funktioniert Generative AI? Allgemein gesagt, lernen generative Modelle Muster in Daten zu erkennen – mit dem Ziel, neue, aber ähnliche Daten zu erzeugen. Generative Modelle sind beispielsweise:
- Comedians, die lernen, andere zu imitieren, indem sie das Verhalten und die Sprechweise von Menschen beobachten
- Künstler, die durch das Studium vieler Gemälde in einem bestimmten Stil lernen, in diesem Stil zu malen
- Coverbands, die lernen, wie eine bestimmte Musikgruppe zu klingen, indem sie sich viel Musik dieser Gruppe anhören
Um einzigartige und kreative Ausgaben zu generieren, werden generative Modelle zunächst mit einem nicht überwachten Ansatz trainiert, bei dem das Modell lernt, die Daten nachzubilden, mit denen es trainiert wird. Das Modell wird manchmal mit überwachtem oder bestärkendem Lernen anhand spezifischer Daten trainiert, die sich auf Aufgaben beziehen, die das Modell ausführen soll, z. B. einen Artikel zusammenfassen oder ein Foto bearbeiten.
Generative KI ist eine sich schnell entwickelnde Technologie, für die ständig neue Anwendungsfälle entdeckt werden. Generative Modelle helfen Unternehmen beispielsweise dabei, ihre E-Commerce-Produktbilder zu optimieren, indem sie automatisch störende Hintergründe entfernen oder die Qualität von Bildern mit niedriger Auflösung verbessern.