Systemy uczące się (ML) są podstawą niektórych z najważniejszych technologii, z których korzystamy, od aplikacji do tłumaczenia po pojazdy autonomiczne. Na tym szkoleniu wyjaśniamy podstawowe koncepcje uczenia maszynowego.
Uczenie maszynowe to nowy sposób rozwiązywania problemów, odpowiadania na złożone pytania i tworzenia nowych treści. Systemy uczące się mogą przewidywać pogodę, szacować czas podróży, rekomendować utwory, automatycznie uzupełniać zdania, streszczać artykuły i generować nigdy wcześniej niewidziane obrazy.
W najprostszym ujęciu uczenie maszynowe to proces trenowania oprogramowania, zwanego modelem, w celu tworzenia przydatnych prognoz lub generowania treści (takich jak tekst, obrazy, dźwięki czy filmy) na podstawie danych.
Załóżmy na przykład, że chcemy utworzyć aplikację do prognozowania opadów. Możemy zastosować tradycyjne podejście lub podejście oparte na uczeniu maszynowym. W tradycyjnym podejściu tworzymy oparty na fizyce model atmosfery i powierzchni Ziemi, obliczając ogromne ilości równań dynamiki płynów. Jest to niezwykle trudne.
W przypadku podejścia opartego na uczeniu maszynowym dostarczylibyśmy modelowi ML ogromne ilości danych pogodowych, aż w końcu nauczyłby się matematycznej zależności między wzorcami pogodowymi, które powodują różne ilości opadów. Następnie podamy modelowi aktualne dane pogodowe, a on przewidzi ilość opadów.
Sprawdź swoją wiedzę
Rodzaje systemów ML
Systemy ML należą do co najmniej jednej z tych kategorii w zależności od tego, jak uczą się tworzyć prognozy lub generować treści:
- Uczenie nadzorowane
- Uczenie nienadzorowane
- Uczenie się przez wzmocnienie
- Generatywna AI
Uczenie nadzorowane
Modele uczenia nadzorowanego mogą dokonywać prognoz po przeanalizowaniu dużej ilości danych z prawidłowymi odpowiedziami i odkryciu powiązań między elementami danych, które prowadzą do prawidłowych odpowiedzi. To tak, jakby uczeń uczył się nowego materiału, studiując stare egzaminy, które zawierają zarówno pytania, jak i odpowiedzi. Gdy uczeń przećwiczy wystarczającą liczbę starych egzaminów, będzie dobrze przygotowany do nowego egzaminu. Te systemy ML są „nadzorowane”, ponieważ człowiek przekazuje im dane ze znanymi prawidłowymi wynikami.
Dwa najczęstsze zastosowania uczenia nadzorowanego to regresja i klasyfikacja.
Regresja
Model regresji prognozuje wartość liczbową. Na przykład model pogodowy, który przewiduje ilość opadów w calach lub milimetrach, jest modelem regresji.
Więcej przykładów modeli regresji znajdziesz w tabeli poniżej:
| Scenariusz | Możliwe dane wejściowe | Prognoza numeryczna |
|---|---|---|
| Przyszła cena domu | powierzchnia w stopach kwadratowych, kod pocztowy, liczba sypialni i łazienek, wielkość działki, stopa procentowa kredytu hipotecznego, stawka podatku od nieruchomości, koszty budowy i liczba domów na sprzedaż w okolicy. | Cena domu. |
| Czas przyszłego przejazdu | historyczne warunki drogowe (zbierane ze smartfonów, czujników drogowych, aplikacji do zamawiania przejazdów i innych aplikacji nawigacyjnych), odległość od miejsca docelowego i warunki pogodowe. | Czas w minutach i sekundach potrzebny na dotarcie do miejsca docelowego. |
Klasyfikacja
Modele klasyfikacji prognozują prawdopodobieństwo, że coś należy do danej kategorii. W przeciwieństwie do modeli regresji, których wynikiem jest liczba, modele klasyfikacji zwracają wartość określającą, czy coś należy do danej kategorii. Modele klasyfikacji służą na przykład do przewidywania, czy e-mail jest spamem lub czy zdjęcie zawiera kota.
Modele klasyfikacji dzielą się na 2 grupy: klasyfikację binarną i klasyfikację wieloklasową. Binarne modele klasyfikacji zwracają wartość z klasy, która zawiera tylko 2 wartości, np. model, który zwraca wartość rain lub no rain. Modele klasyfikacji wieloklasowej zwracają wartość z klasy, która zawiera więcej niż 2 wartości, np. model, który może zwracać rain, hail, snow lub sleet.
Sprawdź swoją wiedzę
Uczenie nienadzorowane
Modele uczenia nienadzorowanego dokonują prognoz na podstawie danych, które nie zawierają żadnych prawidłowych odpowiedzi. Celem modelu uczenia nienadzorowanego jest identyfikowanie istotnych wzorców w danych. Innymi słowy, model nie ma wskazówek, jak kategoryzować poszczególne dane, ale musi sam wywnioskować własne reguły.
Powszechnie stosowany model uczenia nienadzorowanego wykorzystuje technikę zwaną klastrowaniem. Model znajduje punkty danych, które wyznaczają naturalne grupy.
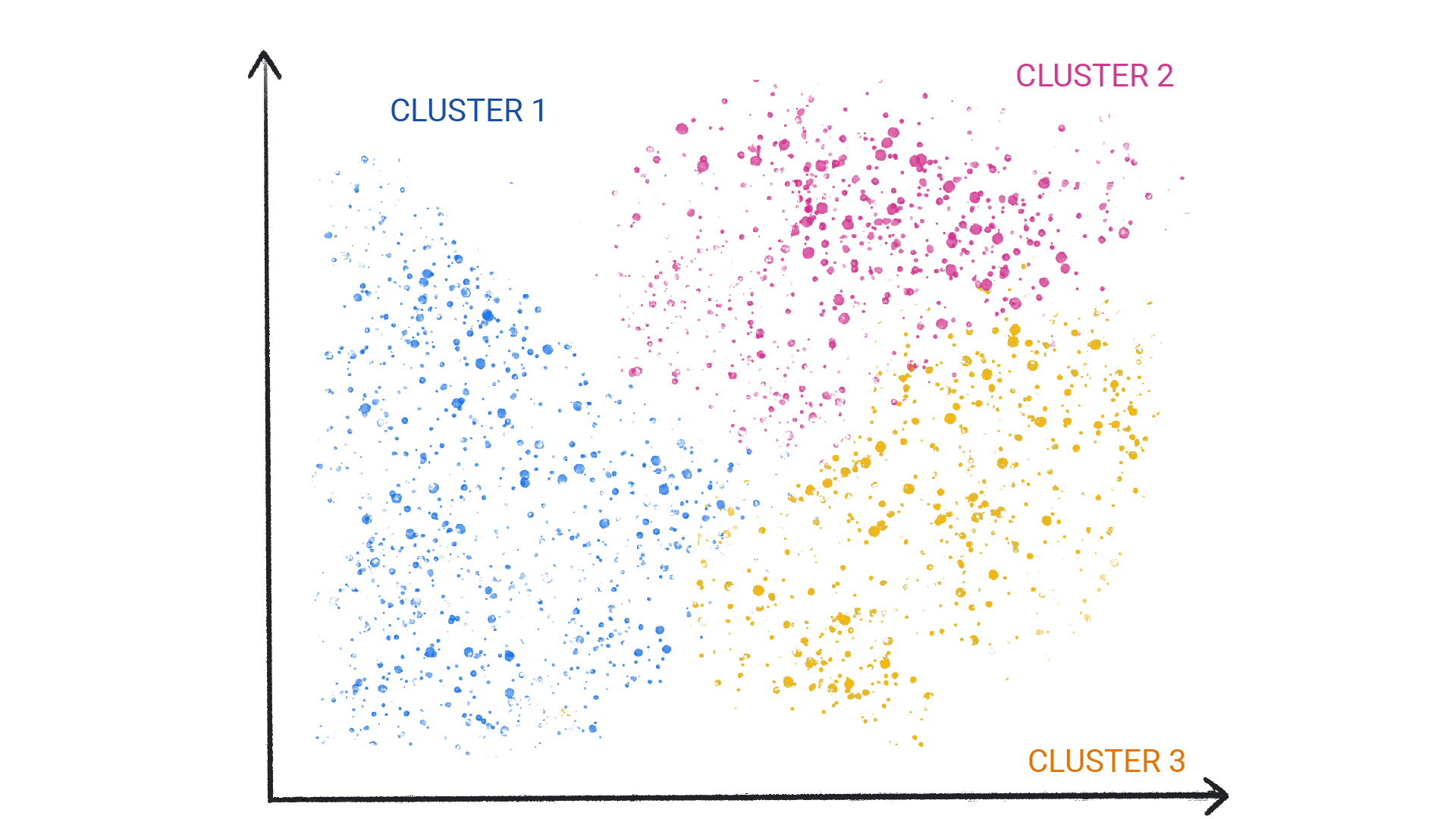
Rysunek 1. Model ML grupujący podobne punkty danych.
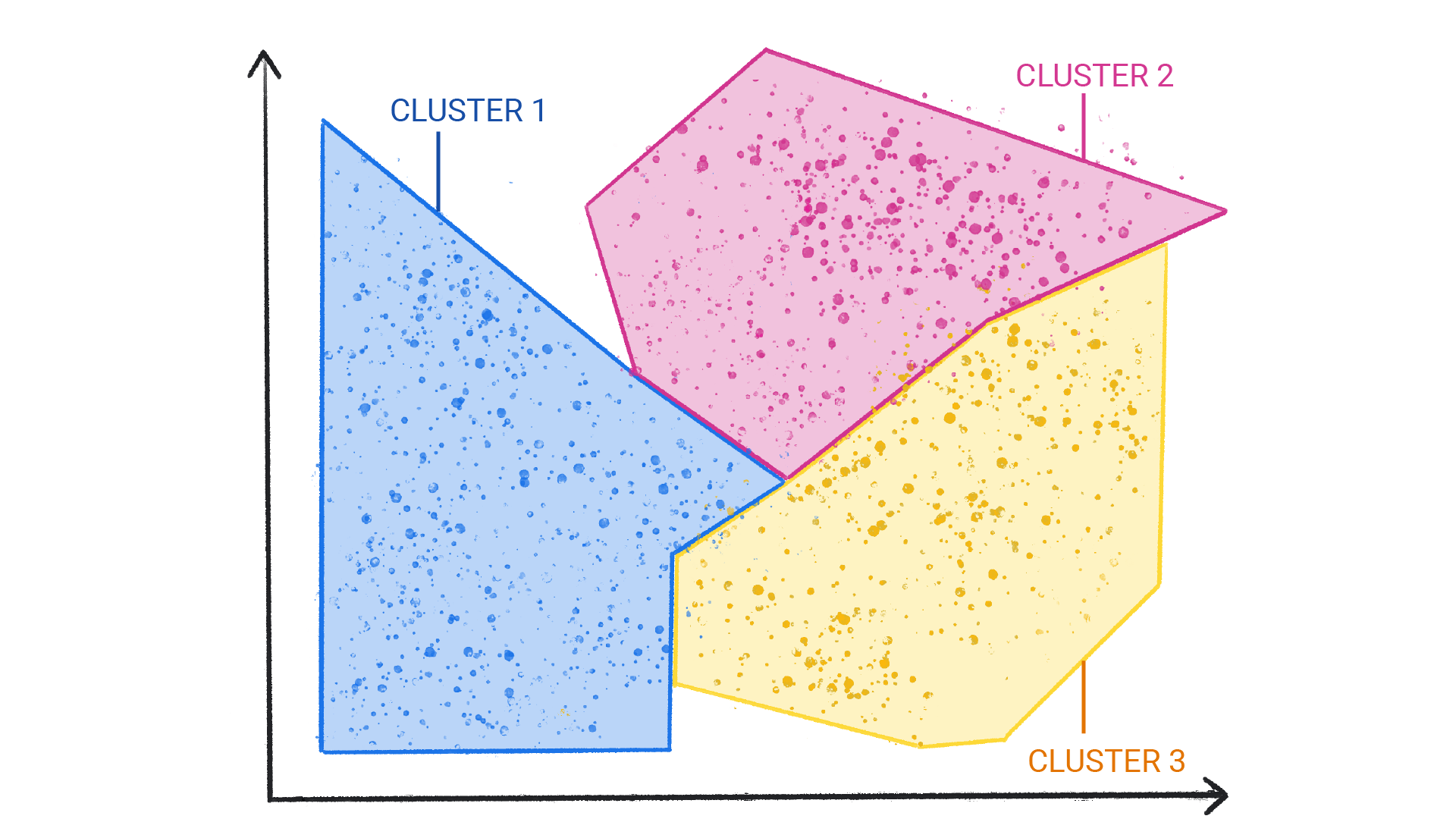
Rysunek 2. Grupy klastrów z naturalnymi podziałami.
Grupowanie różni się od klasyfikacji, ponieważ kategorie nie są definiowane przez Ciebie. Na przykład model nienadzorowany może grupować zbiór danych pogodowych na podstawie temperatury, ujawniając segmenty, które definiują pory roku. Następnie możesz spróbować nazwać te klastry na podstawie swojej wiedzy o zbiorze danych.
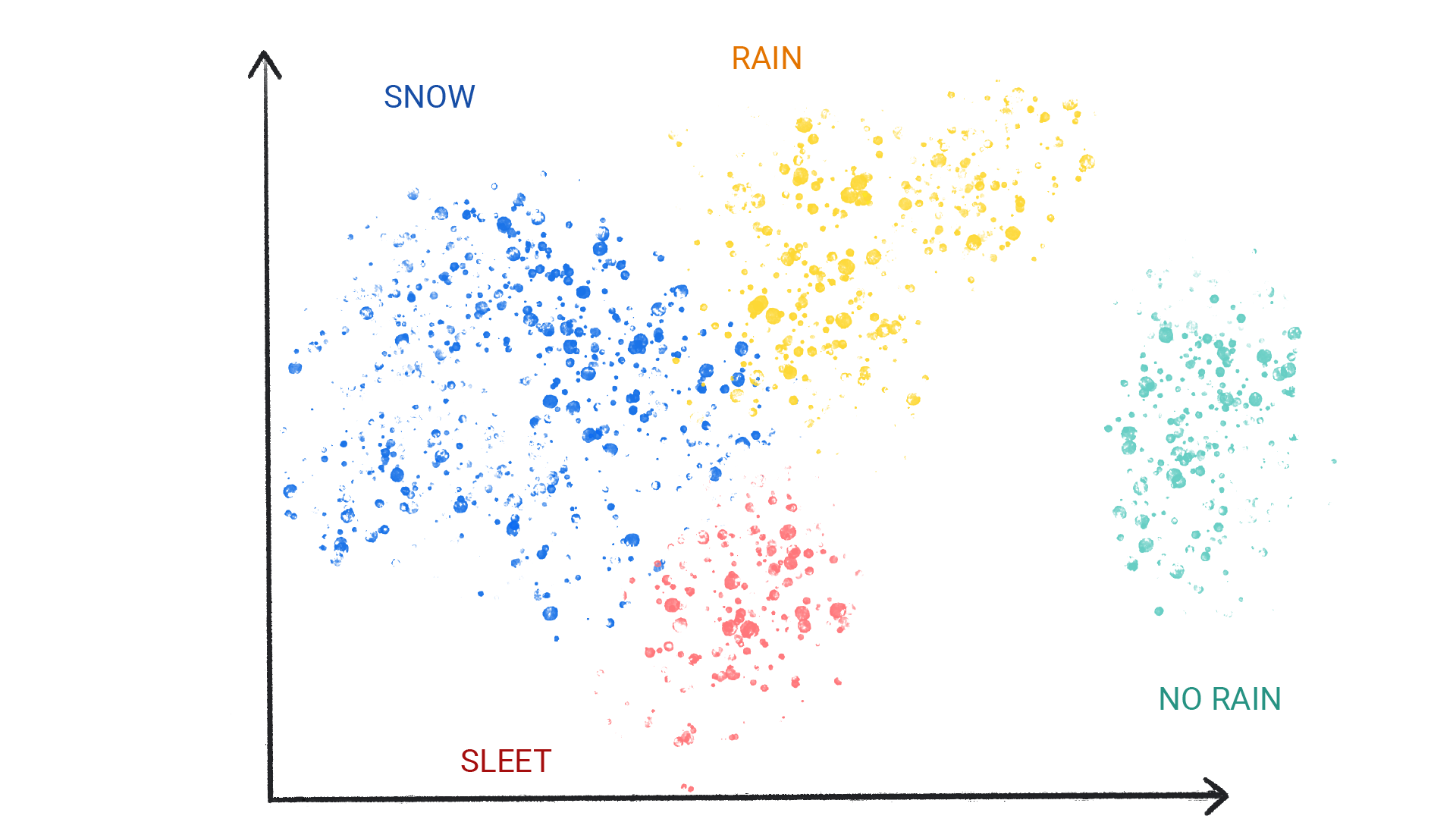
Rysunek 3. Model uczenia maszynowego, który grupuje podobne wzorce pogodowe.
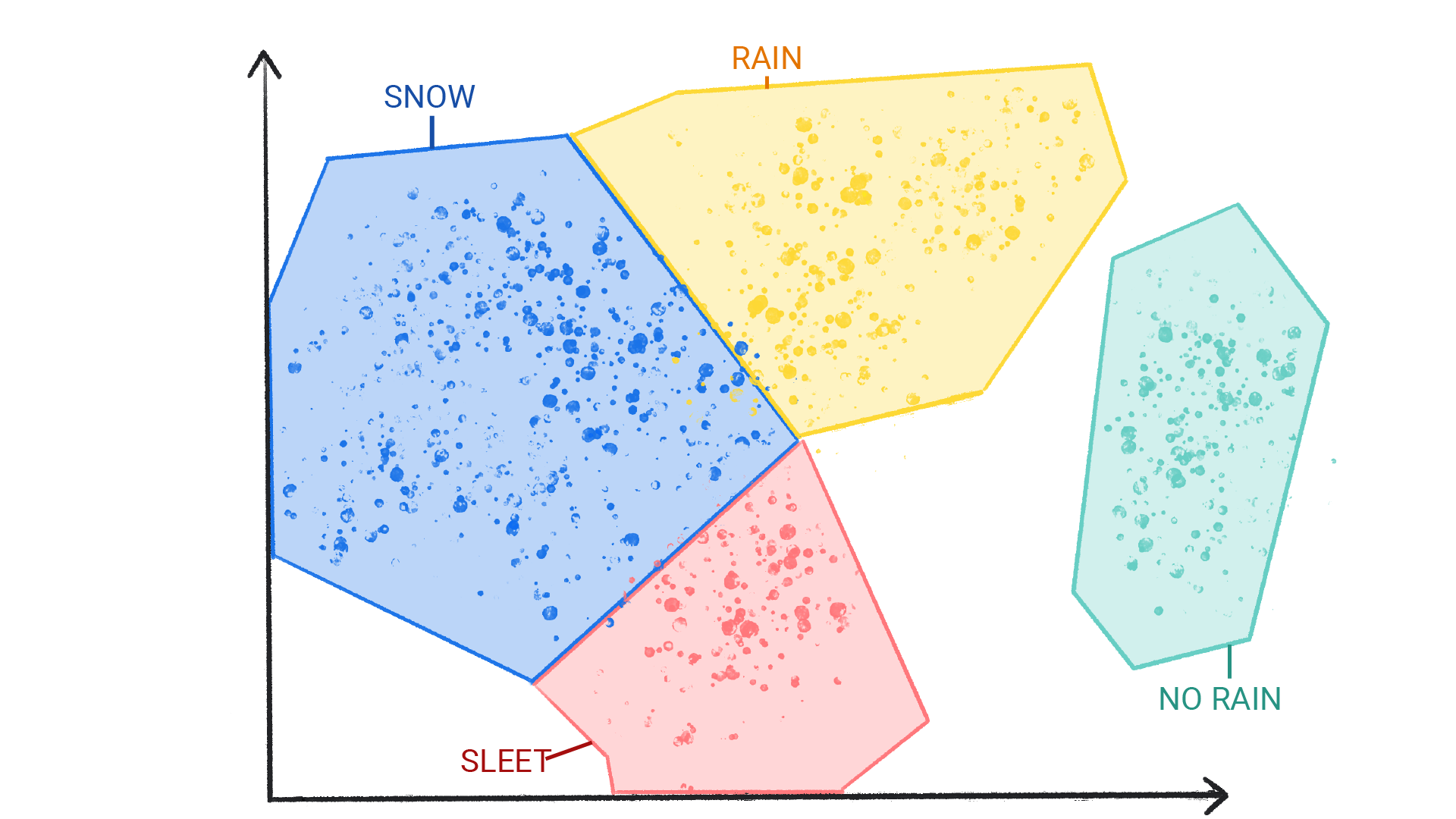
Rysunek 4. Grupy wzorców pogodowych oznaczonych jako śnieg, deszcz ze śniegiem, deszcz i brak deszczu.
Sprawdź swoją wiedzę
Uczenie się przez wzmocnienie
Modele uczenia przez wzmacnianie dokonują prognoz, otrzymując nagrody lub kary na podstawie działań wykonywanych w środowisku. System uczenia się przez wzmacnianie generuje zasady, które określają najlepszą strategię uzyskiwania jak największej liczby nagród.
Uczenie ze wzmocnieniem jest wykorzystywane do trenowania robotów w wykonywaniu zadań, takich jak poruszanie się po pomieszczeniu, oraz programów, takich jak AlphaGo, w grze Go.
Generatywna AI
Generatywna AI to klasa modeli, które tworzą treści na podstawie danych wejściowych użytkownika. Generatywna AI może na przykład tworzyć unikalne obrazy, kompozycje muzyczne i żarty, streszczać artykuły, wyjaśniać, jak wykonać zadanie, lub edytować zdjęcia.
Generatywna AI może przyjmować różne dane wejściowe i tworzyć różne dane wyjściowe, takie jak tekst, obrazy, dźwięki i filmy. Może też tworzyć kombinacje tych elementów. Na przykład model może przyjmować obraz jako dane wejściowe i tworzyć obraz i tekst jako dane wyjściowe lub przyjmować obraz i tekst jako dane wejściowe i tworzyć film jako dane wyjściowe.
Modele generatywne możemy omawiać na podstawie ich danych wejściowych i wyjściowych, zwykle zapisywanych jako „typ danych wejściowych” – „typ danych wyjściowych”. Oto na przykład częściowa lista danych wejściowych i wyjściowych modeli generatywnych:
- Tekst na tekst
- Tekst na obraz
- Tekst na film
- Tekst na kod
- Zamiana tekstu na mowę
- Obraz i tekst na obraz
W tabeli poniżej znajdziesz przykłady modeli generatywnych, ich dane wejściowe i możliwe dane wyjściowe:
| Model | Dane wejściowe | Przykładowe dane wyjściowe |
|---|---|---|
| Tekst na tekst | Kto wymyślił wyścig Le Mans? |
Wyścig 24 Godziny Le Mans został założony przez Automobile Club de l'Ouest (ACO), organizację motoryzacyjną założoną w 1906 roku. Pierwszy wyścig odbył się 26 i 27 maja 1923 roku na torze Circuit de la Sarthe, czyli 13,426-kilometrowym (8,345-milowym) torze drogowym położonym w pobliżu miasta Le Mans we Francji.
Wyścig został pierwotnie wymyślony jako sposób na promocję ACO i regionu Sarthe. Źródło: Bard |
| Tekst na obraz | Obca ośmiornica unosi się w portalu, czytając gazetę. |
 Źródło: Imagen |
| Tekst na film | Fotorealistyczny miś pluszowy pływa w oceanie w San Francisco. Miś pluszowy zanurza się w wodzie. Miś pływa pod wodą z kolorowymi rybami. Panda pływa pod wodą. |
 Źródło: Phenaki |
| Tekst na kod | Napisz pętlę w Pythonie, która iteruje po liście liczb i wyświetla liczby pierwsze. |
for number in numbers: # Check if the number is prime. is_prime = True for i in range(2, number): if number % i == 0: is_prime = False break # If the number is prime, print it. if is_prime: print(number) Źródło: Bard |
| Obraz na tekst |  |
To jest flaming. Występują na Karaibach. Źródło: Google DeepMind |
Jak działa generatywna AI? Ogólnie modele generatywne uczą się wzorców w danych, aby tworzyć nowe, ale podobne dane. Modele generatywne działają podobnie do tych poniżej:
- komicy, którzy uczą się naśladować innych, obserwując ich zachowania i sposób mówienia;
- Artyści, którzy uczą się malować w określonym stylu, studiując wiele obrazów w tym stylu.
- zespoły coverowe, które uczą się brzmieć jak konkretna grupa muzyczna, słuchając wielu utworów tej grupy;
Aby generować unikalne i kreatywne wyniki, modele generatywne są początkowo trenowane przy użyciu metody bez nadzoru, w której model uczy się naśladować dane, na których jest trenowany. Model jest czasami dalej trenowany przy użyciu uczenia nadzorowanego lub uczenia ze wzmocnieniem na podstawie konkretnych danych związanych z zadaniami, o które może być proszony, np. podsumowanie artykułu lub edycja zdjęcia.
Generatywna AI to szybko rozwijająca się technologia, w przypadku której stale odkrywane są nowe zastosowania. Na przykład modele generatywne pomagają firmom ulepszać zdjęcia produktów w e-commerce, automatycznie usuwając rozpraszające tła lub poprawiając jakość obrazów o niskiej rozdzielczości.