Durante la fase di ideazione e pianificazione, esamini gli elementi di una soluzione ML. Durante l'attività di definizione del problema, inquadri un problema in termini di soluzione di ML. Il corso Introduction to Machine Learning Problem Framing tratta questi passaggi in dettaglio. Durante l'attività di pianificazione, valuti la fattibilità di una soluzione, pianifichi gli approcci e imposti le metriche di successo.
Sebbene l'ML possa essere una soluzione teoricamente valida, devi comunque stimarne la fattibilità nel mondo reale. Ad esempio, una soluzione potrebbe funzionare tecnicamente, ma essere impraticabile o impossibile da implementare. I seguenti fattori influenzano la fattibilità di un progetto:
- Disponibilità dei dati
- Difficoltà del problema
- Qualità della previsione
- Requisiti tecnici
- Costo
Disponibilità dei dati
I modelli ML sono efficaci solo se i dati su cui vengono addestrati sono di qualità. Hanno bisogno di molti dati di alta qualità per fare previsioni di alta qualità. Rispondere alle seguenti domande può aiutarti a valutare se disponi dei dati necessari per addestrare un modello:
Quantità. Puoi ottenere dati di alta qualità sufficienti per addestrare un modello? Gli esempi etichettati sono scarsi, difficili da ottenere o troppo costosi? Ad esempio, ottenere immagini mediche etichettate o traduzioni di lingue rare è notoriamente difficile. Per fare previsioni accurate, i modelli di classificazione richiedono numerosi esempi per ogni etichetta. Se il set di dati di addestramento contiene esempi limitati per alcune etichette, il modello non può fare buone previsioni.
Disponibilità della funzionalità al momento della pubblicazione. Tutte le funzionalità utilizzate nell'addestramento saranno disponibili al momento della pubblicazione? I team hanno dedicato molto tempo all'addestramento dei modelli solo per rendersi conto che alcune funzionalità non sono diventate disponibili fino a giorni dopo che il modello le richiedeva.
Ad esempio, supponiamo che un modello preveda se un cliente farà clic su un URL e che una delle funzionalità utilizzate nell'addestramento includa
user_age. Tuttavia, quando il modello fornisce una previsione,user_agenon è disponibile, forse perché l'utente non ha ancora creato un account.Normative. Quali sono le normative e i requisiti legali per l'acquisizione e l'utilizzo dei dati? Ad esempio, alcuni requisiti stabiliscono limiti per l'archiviazione e l'utilizzo di determinati tipi di dati.
AI generativa
I modelli di AI generativa preaddestrati spesso richiedono set di dati curati per eccellere in attività specifiche del dominio. Potresti aver bisogno di set di dati per i seguenti casi d'uso:
-
Prompt engineering,
ottimizzazione efficiente dei parametri e
ottimizzazione fine.
A seconda del caso d'uso, potresti aver bisogno di 10-10.000 esempi di alta qualità
per perfezionare ulteriormente l'output di un modello. Ad esempio, se un modello deve
essere ottimizzato per eccellere in un'attività particolare, come rispondere a domande
mediche, avrai bisogno di un set di dati di alta qualità che sia rappresentativo
dei tipi di domande che gli verranno poste e dei tipi di risposte che
dovrà fornire.
La tabella seguente fornisce stime del numero di esempi necessari per perfezionare l'output di un modello di AI generativa per una determinata tecnica:
-
Informazioni aggiornate. Una volta preaddestrati, i modelli di AI generativa hanno
una knowledge base fissa. Se i contenuti nel dominio del modello cambiano spesso,
avrai bisogno di una strategia per mantenere il modello aggiornato, ad esempio:
- ottimizzazione
- Retrieval-augmented generation (RAG)
- pre-addestramento periodico
| Tecnica | Numero di esempi richiesti |
|---|---|
| Prompting zero-shot | 0 |
| Prompting few-shot | ~10-100 secondi |
| Ottimizzazione efficiente dei parametri 1 | ~100-10.000 |
| Ottimizzazione | ~1000-10.000 (o più) |
Difficoltà del problema
La difficoltà di un problema può essere difficile da stimare. Ciò che inizialmente sembra un approccio plausibile potrebbe in realtà rivelarsi una domanda di ricerca aperta; ciò che sembra pratico e fattibile potrebbe rivelarsi irrealistico o impraticabile. Rispondere alle seguenti domande può aiutarti a valutare la difficoltà di un problema:
È già stato risolto un problema simile? Ad esempio, i team della tua organizzazione hanno utilizzato dati simili (o identici) per creare modelli? Persone o team esterni alla tua organizzazione hanno risolto problemi simili, ad esempio su Kaggle o TensorFlow Hub? In questo caso, è probabile che tu possa utilizzare parti del loro modello per creare il tuo.
La natura del problema è difficile? Conoscere i benchmark umani per l'attività può informare sul livello di difficoltà del problema. Ad esempio:
- Gli esseri umani possono classificare il tipo di animale in un'immagine con una precisione di circa il 95%.
- Gli esseri umani possono classificare le cifre scritte a mano con un'accuratezza di circa il 99%.
I dati precedenti suggeriscono che creare un modello per classificare gli animali è più difficile che creare un modello per classificare le cifre scritte a mano.
Esistono potenziali malintenzionati? Le persone cercheranno attivamente di sfruttare il tuo modello? In questo caso, dovrai aggiornare costantemente il modello prima che possa essere utilizzato in modo improprio. Ad esempio, i filtri antispam non riescono a rilevare nuovi tipi di spam quando qualcuno sfrutta il modello per creare email che sembrano legittime.
AI generativa
I modelli di AI generativa presentano potenziali vulnerabilità che possono aumentare la difficoltà di un problema:
- Origine di input. Da dove proverrà l'input? I prompt avversari possono divulgare dati di addestramento, materiale del preambolo, contenuti del database o informazioni sugli strumenti?
- Utilizzo dell'output. Come verranno utilizzati gli output? Il modello restituirà contenuti non elaborati o ci saranno passaggi intermedi che ne verificheranno l'idoneità? Ad esempio, fornire output non elaborati ai plug-in può causare una serie di problemi di sicurezza.
- Ottimizzazione. Il perfezionamento con un set di dati danneggiato può influire negativamente sui pesi del modello. Questa corruzione farebbe sì che il modello restituisca contenuti errati, tossici o distorti. Come indicato in precedenza, il perfezionamento richiede un set di dati verificato che contenga esempi di alta qualità.
Qualità della previsione
Dovrai valutare attentamente l'impatto che le previsioni di un modello avranno sui tuoi utenti e determinare la qualità di previsione necessaria per il modello.
La qualità della previsione richiesta dipende dal tipo di previsione. Ad esempio, la qualità della previsione richiesta per un sistema di consigli non sarà la stessa per un modello che segnala violazioni delle norme. Consigliare il video sbagliato potrebbe creare un'esperienza utente negativa. Tuttavia, segnalare erroneamente un video come violazione delle norme di una piattaforma potrebbe generare costi di assistenza o, peggio ancora, spese legali.
Il tuo modello dovrà avere una qualità di previsione molto elevata perché le previsioni errate sono estremamente costose? In genere, maggiore è la qualità della previsione richiesta, più difficile è il problema. Purtroppo, i progetti spesso raggiungono rendimenti decrescenti quando cerchi di migliorare la qualità. Ad esempio, aumentare la precisione di un modello dal 99,9% al 99,99% potrebbe comportare un aumento di 10 volte del costo del progetto (se non di più).
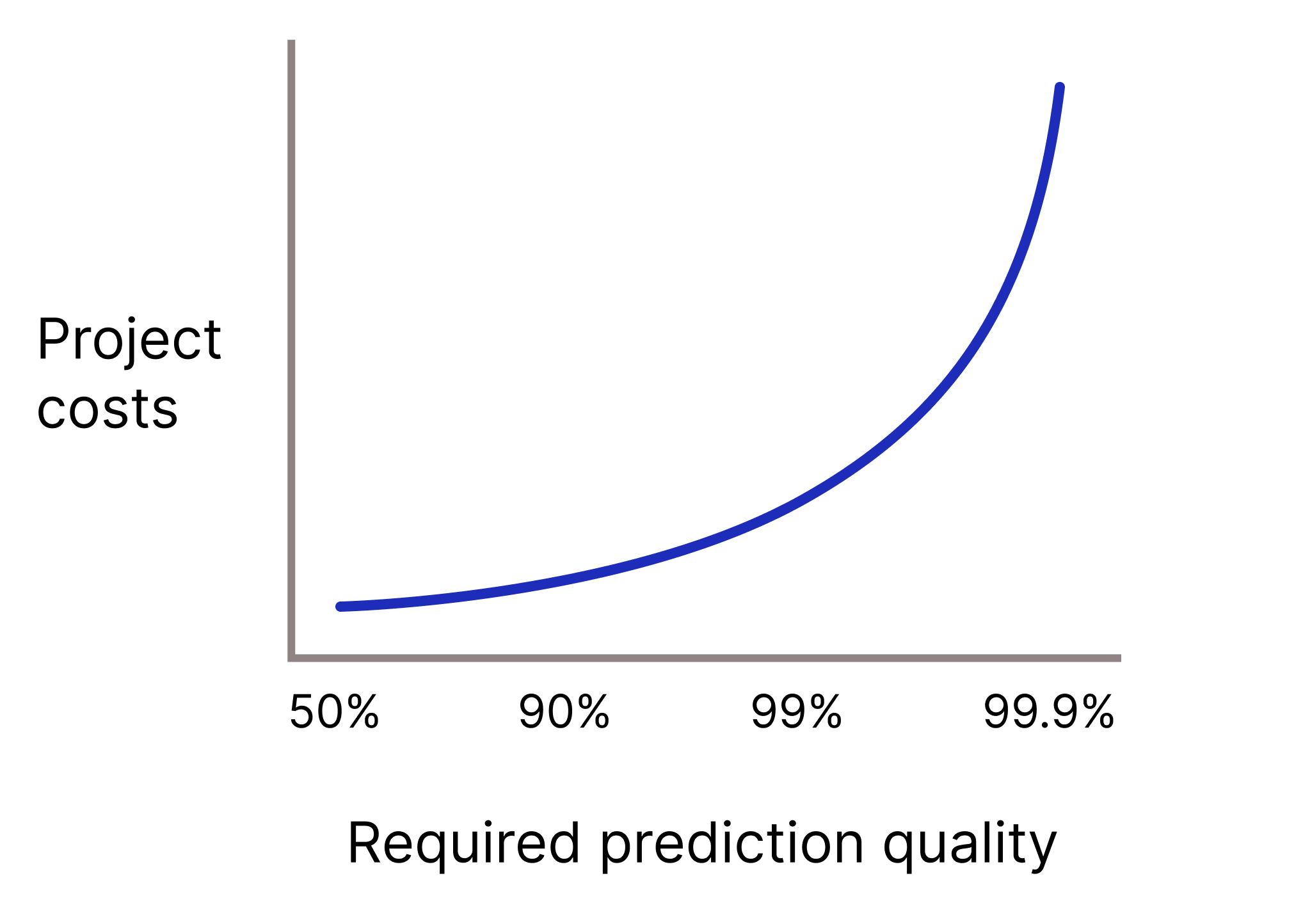
Figura 2. Un progetto ML in genere richiede sempre più risorse man mano che aumenta la qualità della previsione richiesta.
AI generativa
Quando analizzi l'output dell'AI generativa, considera quanto segue:
-
Accuratezza fattuale. Sebbene i modelli di AI generativa possano produrre contenuti fluidi e coerenti, non è garantito che siano veritieri. Le affermazioni false dei modelli di AI generativa sono chiamate confabulazioni.
Ad esempio, i modelli di AI generativa possono inventare e produrre
riassunti di testo errati, risposte sbagliate a domande di matematica
o affermazioni false sul mondo. Molti casi d'uso richiedono ancora la verifica umana dell'output dell'AI generativa prima di essere utilizzati in un ambiente di produzione, ad esempio il codice generato da LLM.
Come per l'ML tradizionale, maggiore è il requisito di accuratezza fattuale, maggiore è il costo di sviluppo e manutenzione.
- Qualità dell'output. Quali sono le conseguenze legali e finanziarie (o implicazioni etiche) di output errati, come contenuti con pregiudizi, plagiati o tossici?
Requisiti tecnici
I modelli hanno una serie di requisiti tecnici che ne influenzano la fattibilità. Di seguito sono riportati i principali requisiti tecnici che devi soddisfare per determinare la fattibilità del tuo progetto:
- Latenza. Quali sono i requisiti di latenza? Con quale velocità devono essere pubblicate le previsioni?
- Query al secondo (QPS). Quali sono i requisiti QPS?
- Utilizzo della RAM. Quali sono i requisiti di RAM per l'addestramento e la pubblicazione?
- Piattaforma. Dove verrà eseguito il modello: online (query inviate al server RPC), WebML (all'interno di un browser web), ODML (su uno smartphone o un tablet) o offline (previsioni salvate in una tabella)?
Interpretabilità. Le previsioni dovranno essere interpretabili? Ad esempio, il tuo prodotto dovrà rispondere a domande come "Perché un determinato contenuto è stato contrassegnato come spam?" o "Perché è stato stabilito che un video viola le norme della piattaforma?"
Frequenza di riqualificazione. Quando i dati sottostanti del modello cambiano rapidamente, potrebbe essere necessario un retraining frequente o continuo. Tuttavia, il riaddestramento frequente può comportare costi significativi che potrebbero superare i vantaggi dell'aggiornamento delle previsioni del modello.
Nella maggior parte dei casi, probabilmente dovrai scendere a compromessi sulla qualità di un modello per rispettarne le specifiche tecniche. In questi casi, dovrai determinare se puoi comunque produrre un modello sufficientemente valido per la produzione.
AI generativa
Quando lavori con l'AI generativa, tieni presente i seguenti requisiti tecnici:
- Piattaforma. Molti modelli preaddestrati sono disponibili in varie dimensioni, consentendo loro di funzionare su una varietà di piattaforme con risorse di calcolo diverse. Ad esempio, i modelli preaddestrati possono variare dalla scala del data center all'adattamento a uno smartphone. Quando scegli le dimensioni di un modello, devi tenere conto dei vincoli di latenza, privacy e qualità del tuo prodotto o servizio. Questi vincoli spesso possono essere in conflitto. Ad esempio, i vincoli di privacy potrebbero richiedere che le inferenze vengano eseguite sul dispositivo di un utente. Tuttavia, la qualità dell'output potrebbe essere scarsa perché il dispositivo non dispone delle risorse di calcolo per produrre buoni risultati.
- Latenza. Le dimensioni dell'input e dell'output del modello influiscono sulla latenza. In particolare, la dimensione dell'output influisce sulla latenza più della dimensione dell'input. Sebbene i modelli possano parallelizzare i propri input, possono generare output solo in sequenza. In altre parole, la latenza potrebbe essere la stessa per l'inserimento di un input di 500 parole o di 10 parole, mentre la generazione di un riepilogo di 500 parole richiede molto più tempo rispetto alla generazione di un riepilogo di 10 parole.
- Utilizzo di strumenti e API. Il modello dovrà utilizzare strumenti e API, ad esempio cercare su internet, utilizzare una calcolatrice o accedere a un client di posta elettronica per completare un'attività? In genere, più strumenti sono necessari per completare un'attività, maggiori sono le possibilità di propagare errori e aumentare le vulnerabilità del modello.
Costo
L'implementazione dell'ML vale i costi? La maggior parte dei progetti ML non verrà approvata se la soluzione ML è più costosa da implementare e gestire rispetto al denaro che genera (o risparmia). I progetti di ML comportano costi umani e costi della macchina.
Costi umani. Quante persone saranno necessarie per passare dalla prova di concetto alla produzione? Man mano che i progetti ML si evolvono, le spese in genere aumentano. Ad esempio, i progetti di ML richiedono più persone per eseguire il deployment e gestire un sistema pronto per la produzione rispetto alla creazione di un prototipo. Cerca di stimare il numero e i tipi di ruoli di cui il progetto avrà bisogno in ogni fase.
Costi della macchina. L'addestramento, il deployment e la manutenzione dei modelli richiedono molta potenza di calcolo e memoria. Ad esempio, potresti aver bisogno di una quota TPU per l'addestramento dei modelli e per la pubblicazione delle previsioni, oltre all'infrastruttura necessaria per la tua pipeline di dati. Potresti dover pagare per ottenere dati etichettati o pagare le tariffe di licenza dei dati. Prima di addestrare un modello, valuta la possibilità di stimare i costi della macchina per la creazione e la manutenzione delle funzionalità di ML a lungo termine.
Costo dell'inferenza. Il modello dovrà effettuare centinaia o migliaia di inferenze che costano più delle entrate generate?
Aspetti da considerare
I problemi relativi a uno qualsiasi degli argomenti precedenti possono rendere difficile l'implementazione di una soluzione di ML, ma le scadenze ravvicinate possono amplificare le difficoltà. Cerca di pianificare e prevedere un tempo sufficiente in base alla difficoltà percepita del problema e poi cerca di riservare ancora più tempo di overhead rispetto a un progetto non di ML.
Verifica di aver compreso tutto
Lavori per un'azienda di conservazione della natura e gestisci il software di identificazione delle piante dell'azienda. Vuoi creare un modello per classificare 60 tipi di specie vegetali invasive per aiutare i conservazionisti a gestire gli habitat per gli animali in pericolo.
Hai trovato un codice di esempio che risolve un problema simile di identificazione delle piante e i costi stimati per implementare la tua soluzione rientrano nel budget del progetto. Sebbene il set di dati contenga molti esempi di addestramento, ne ha solo alcuni per le cinque specie più invasive. La leadership non richiede che le previsioni del modello siano interpretabili e non sembra che ci siano conseguenze negative correlate a previsioni errate. La tua soluzione ML è fattibile?