アイデア出しと計画のフェーズでは、ML ソリューションの要素を調査します。問題のフレーミング タスクでは、ML ソリューションの観点から問題をフレーミングします。ML の問題のフレーミング入門コースでは、これらの手順について詳しく説明します。計画タスクでは、ソリューションの実現可能性を推定し、アプローチを計画して、成功指標を設定します。
ML は理論的には優れたソリューションかもしれませんが、現実世界の実現可能性を推定する必要があります。たとえば、技術的には機能するソリューションでも、実装が非現実的または不可能である場合があります。プロジェクトの実現可能性に影響する要因は次のとおりです。
- データの可用性
- 問題の難易度
- 予測の品質
- 技術的要件
- 費用
データの可用性
ML モデルの質は、トレーニングに使用するデータの質に比例します。高品質の予測を行うには、高品質のデータが大量に必要です。次の質問に答えることで、モデルのトレーニングに必要なデータがあるかどうかを判断できます。
数量。モデルをトレーニングするのに十分な高品質のデータを取得できますか?ラベル付きの例が不足している、入手が難しい、または高価ですか?たとえば、ラベル付きの医療画像や希少言語の翻訳を取得することは非常に困難です。適切な予測を行うには、分類モデルで各ラベルに多数の例が必要です。トレーニング データセットに一部のラベルの例が限られている場合、モデルは適切な予測を行うことができません。
サービング時の特徴量の可用性。トレーニングで使用されるすべての機能は、サービング時に使用できますか?チームはモデルのトレーニングにかなりの時間を費やしましたが、モデルが必要とする数日後まで一部の機能が利用できないことに気づきました。
たとえば、モデルが顧客が URL をクリックするかどうかを予測し、トレーニングで使用される特徴の 1 つに
user_ageが含まれているとします。ただし、モデルが予測を返すときに、ユーザーがまだアカウントを作成していないなどの理由でuser_ageが使用できない場合があります。規制。データの取得と使用に関する規制と法的要件は何ですか?たとえば、特定の種類のデータの保存と使用に制限を設ける要件もあります。
生成 AI
事前トレーニング済みの 生成 AI モデルは、ドメイン固有のタスクで優れたパフォーマンスを発揮するために、キュレートされたデータセットを必要とすることがよくあります。次のユースケースでは、データセットが必要になる可能性があります。
-
プロンプト エンジニアリング、
パラメータ効率チューニング、ファインチューニング。
ユースケースによっては、モデルの出力をさらに絞り込むために、10 ~ 10,000 個の高品質な例が必要になることがあります。たとえば、医療に関する質問への回答など、特定のタスクで優れたパフォーマンスを発揮するようにモデルをファインチューニングする必要がある場合は、質問の種類と回答の種類を代表する高品質のデータセットが必要です。
次の表に、特定の手法で生成 AI モデルの出力を調整するために必要な例の数の推定値を示します。
-
最新の情報。事前トレーニングが完了すると、生成 AI モデルのナレッジベースは固定されます。モデルのドメイン内のコンテンツが頻繁に変更される場合は、モデルを最新の状態に保つための戦略が必要です。たとえば、次のような戦略があります。
- ファインチューニング
- 検索拡張生成(RAG)
- 定期的な事前トレーニング
| 手法 | 必要な例の数 |
|---|---|
| ゼロショット プロンプト | 0 |
| 少数ショット プロンプト | ~ 10 秒~ 100 秒 |
| パラメータ効率チューニング 1 | ~ 100 ~ 10,000 |
| ファインチューニング | 数千~数万(またはそれ以上) |
問題の難易度
問題の難易度を推定するのは難しい場合があります。一見すると妥当なアプローチに見えても、実際には未解決の研究課題である可能性があります。実用的で実行可能に見えても、実際には非現実的または実行不可能である可能性があります。次の質問に答えることで、問題の難易度を把握できます。
同様の問題はすでに解決されていますか?たとえば、組織内のチームが類似(または同一)のデータを使用してモデルを構築したことはありますか?組織外のユーザーやチームが、Kaggle や TensorFlow Hub などで同様の問題を解決したことはありますか?その場合、そのモデルの一部を使用して独自のモデルを構築できる可能性があります。
問題の性質は難しいですか?タスクの人間によるベンチマークを知ることで、問題の難易度を把握できます。次に例を示します。
- 人間は、画像の動物の種類を約 95% の精度で分類できます。
- 人間は手書きの数字を約 99% の精度で分類できます。
上記のデータは、手書き数字を分類するモデルを作成するよりも、動物を分類するモデルを作成する方が難しいことを示しています。
不正な行為者がいる可能性はありますか?モデルを積極的に悪用しようとするユーザーがいるか?その場合、モデルが不正使用される前に更新するという競争が常に発生します。たとえば、モデルを悪用して正規のメールに見せかけたメールを作成した場合、スパムフィルタで新しいタイプのスパムを検出できません。
生成 AI
生成 AI モデルには、問題の難易度を高める可能性のある脆弱性があります。
- 入力ソース。入力はどこから取得されますか?敵対的プロンプトによって、トレーニング データ、前文資料、データベース コンテンツ、ツール情報が漏洩する可能性はありますか?
- 出力の使用。出力はどのように使用されますか?モデルは未加工のコンテンツを出力しますか?それとも、適切かどうかをテストして検証する中間ステップがありますか?たとえば、プラグインに未加工の出力を提供すると、多くのセキュリティ上の問題が発生する可能性があります。
- ファインチューニング。破損したデータセットでファインチューニングを行うと、モデルの重みに悪影響が及ぶ可能性があります。この破損により、モデルが不正確、有害、または偏ったコンテンツを出力する可能性があります。前述のように、ファインチューニングには、高品質の例が含まれていることが確認されたデータセットが必要です。
予測の品質
モデルの予測がユーザーに与える影響を慎重に検討し、モデルに必要な予測の品質を決定する必要があります。
必要な予測の品質は、予測のタイプによって異なります。たとえば、レコメンデーション システムに必要な予測の品質は、ポリシー違反を検出するモデルと同じではありません。間違った動画をおすすめすると、ユーザー エクスペリエンスが低下する可能性があります。ただし、プラットフォームのポリシーに違反しているとして動画を誤って報告すると、サポート費用が発生したり、最悪の場合は訴訟費用が発生したりする可能性があります。
誤った予測が非常に大きな損失につながるため、モデルの予測品質を非常に高くする必要があるかどうか。一般に、必要な予測品質が高いほど、問題は難しくなります。残念ながら、品質の向上を試みても、プロジェクトは収益逓減に達することがよくあります。たとえば、モデルの精度を 99.9% から 99.99% に上げると、プロジェクトの費用が 10 倍以上になる可能性があります。
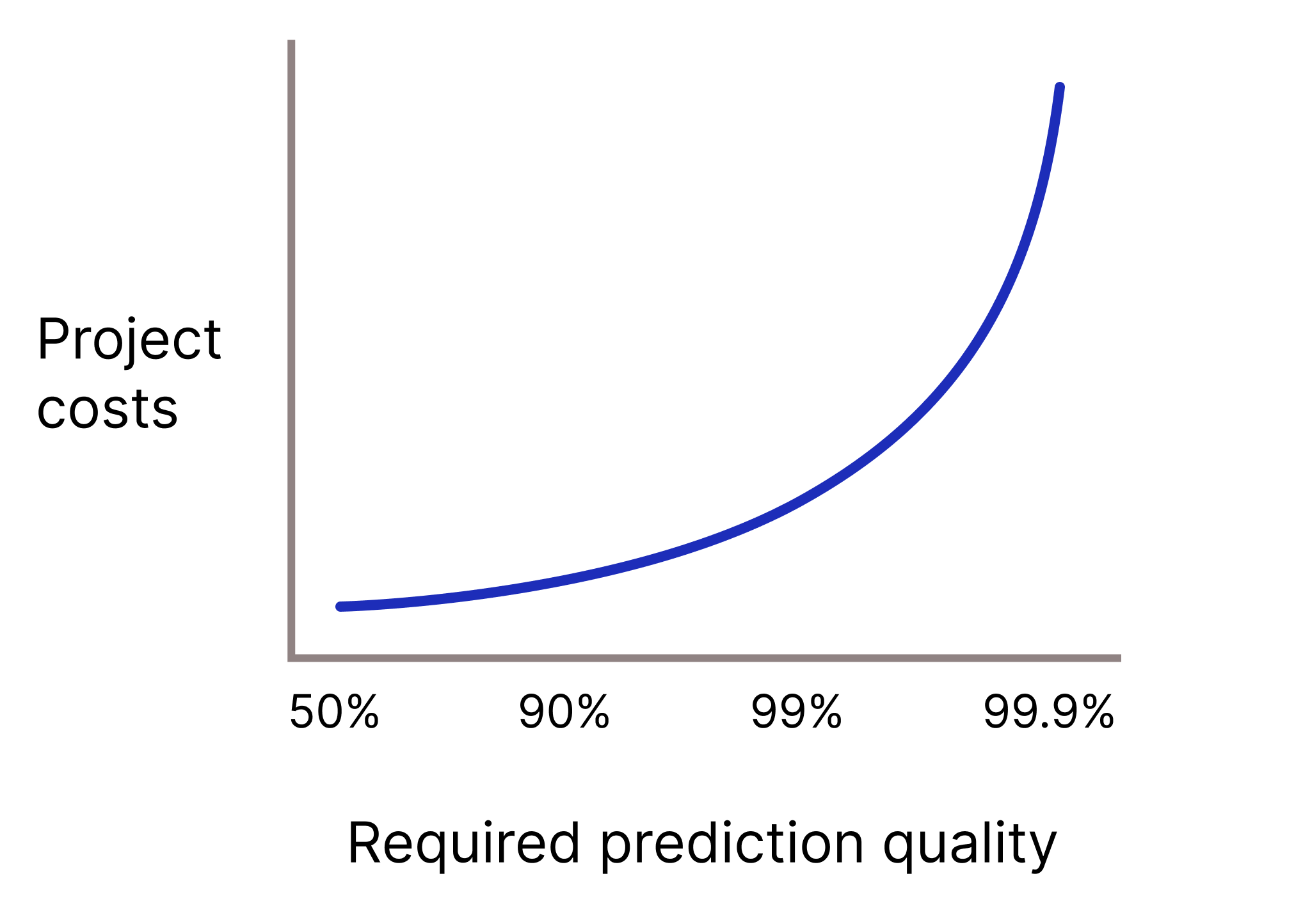
図 2. 通常、ML プロジェクトでは、必要な予測の品質が高くなるにつれて、より多くのリソースが必要になります。
生成 AI
生成 AI の出力を分析する際は、次の点を考慮してください。
-
事実の正確性。生成 AI モデルは流暢で一貫性のあるコンテンツを生成できますが、事実に基づいているとは限りません。生成 AI モデルによる誤った発言は、虚言と呼ばれます。たとえば、生成 AI モデルは、テキストの不正確な要約、数学の問題に対する間違った回答、世界に関する誤ったステートメントを生成することがあります。多くのユースケースでは、生成 AI の出力を本番環境で使用する前に、人間による検証が必要です(LLM で生成されたコードなど)。
従来の ML と同様に、事実の正確性に対する要件が高いほど、開発と保守のコストが高くなります。
- 出力の品質。バイアス、盗用、有害なコンテンツなどの不適切な出力によって、どのような法的および経済的な影響(または倫理的な影響)が生じますか?
技術的要件
モデルには、実現可能性に影響する技術要件がいくつかあります。プロジェクトの実現可能性を判断するために対応する必要がある主な技術要件は次のとおりです。
- レイテンシ。レイテンシの要件は何ですか?予測はどのくらいの速さで提供する必要がありますか?
- 秒間クエリ数(QPS)。QPS の要件は何ですか?
- RAM 使用量。トレーニングとサービングの RAM 要件は何ですか?
- プラットフォーム。モデルの実行場所: オンライン(RPC サーバーに送信されたクエリ)、WebML(ウェブブラウザ内)、ODML(スマートフォンまたはタブレット)、オフライン(テーブルに保存された予測)のいずれか。
解釈可能性。予測を解釈可能にする必要がありますか?たとえば、「特定のコンテンツがスパムとしてマークされたのはなぜですか?」や「動画がプラットフォームのポリシーに違反していると判断されたのはなぜですか?」といった質問に回答する必要があるかどうかなどです。
再トレーニングの頻度。モデルの基盤となるデータが急速に変化する場合は、頻繁な再トレーニングや継続的な再トレーニングが必要になることがあります。ただし、頻繁な再トレーニングは、モデルの予測を更新するメリットを上回るほどの大きな費用につながる可能性があります。
ほとんどの場合、技術仕様に準拠するためにモデルの品質を妥協する必要があるでしょう。このような場合は、本番環境に移行するのに十分なモデルを生成できるかどうかを判断する必要があります。
生成 AI
生成 AI を使用する場合は、次の技術要件を考慮してください。
- プラットフォーム。多くの事前トレーニング済みモデルにはさまざまなサイズがあり、異なるコンピューティング リソースを持つさまざまなプラットフォームで動作します。たとえば、事前トレーニング済みのモデルは、データセンター規模からスマートフォンに収まるものまであります。モデルサイズを選択する際は、プロダクトやサービスのレイテンシ、プライバシー、品質の制約を考慮する必要があります。これらの制約は競合することがよくあります。たとえば、プライバシー制約により、推論をユーザーのデバイスで実行する必要がある場合があります。ただし、デバイスに優れた結果を生成するためのコンピューティング リソースがないため、出力の品質が低い可能性があります。
- レイテンシ。モデルの入力と出力のサイズはレイテンシに影響します。特に、出力サイズは入力サイズよりもレイテンシに影響します。モデルは入力を並列化できますが、出力は順番にしか生成できません。つまり、500 語の入力と 10 語の入力の取り込みにかかるレイテンシは同じでも、500 語の要約の生成には 10 語の要約の生成よりも大幅に時間がかかることがあります。
- ツールと API の使用。タスクを完了するために、インターネット検索、電卓の使用、メール クライアントへのアクセスなどのツールや API をモデルで使用する必要がありますか?通常、タスクの完了に必要なツールが多いほど、間違いが伝播し、モデルの脆弱性が増大する可能性が高くなります。
費用
ML の実装はコストに見合うものですか?ML ソリューションの導入と保守の費用が、そのソリューションが生み出す(または節約する)金額よりも大きい場合、ほとんどの ML プロジェクトは承認されません。ML プロジェクトでは、人間とマシンの両方の費用が発生します。
人的コスト。コンセプト実証から本番環境への移行には何人の人員が必要ですか?ML プロジェクトの進化に伴い、費用は通常増加します。たとえば、ML プロジェクトでは、プロトタイプを作成するよりも、本番環境対応のシステムをデプロイして維持する方が多くの人員を必要とします。各フェーズでプロジェクトに必要な役割の数と種類を推定してみてください。
マシンの費用。モデルのトレーニング、デプロイ、メンテナンスには、大量のコンピューティングとメモリが必要です。たとえば、モデルのトレーニングと予測のサービングに TPU 割り当てが必要になる場合があります。また、データ パイプラインに必要なインフラストラクチャも必要になる場合があります。データのラベル付けやデータ ライセンス料の支払いを求められる場合があります。モデルをトレーニングする前に、ML 機能の構築と長期的なメンテナンスにかかるマシン費用を見積もることを検討してください。
留意点
上記のトピックに関連する問題が発生すると、ML ソリューションの実装が困難になる可能性がありますが、期限が迫っていると、その困難さがさらに増す可能性があります。問題の難易度に基づいて十分な時間を計画して予算を立て、ML 以外のプロジェクトよりもさらに多くのオーバーヘッド時間を確保するようにしてください。
理解度チェック
あなたは自然保護会社に勤務しており、会社の植物識別ソフトウェアを管理しています。絶滅危惧種の動物の生息地を保護するために、60 種類の外来植物種を分類するモデルを作成します。
同様の植物識別問題を解決するサンプルコードが見つかり、ソリューションの実装にかかる推定費用がプロジェクトの予算内に収まる。このデータセットには多くのトレーニング例が含まれていますが、最も侵略的な 5 種についてはわずかしか含まれていません。リーダーシップは、モデルの予測が解釈可能であることを要求しておらず、誤った予測に関連する悪影響はないようです。ML ソリューションは実現可能ですか?