ในระยะการระดมความคิดและการวางแผน คุณจะตรวจสอบองค์ประกอบของโซลูชัน ML ในระหว่างงานการกำหนดกรอบปัญหา คุณจะกำหนดกรอบปัญหาในแง่ของโซลูชัน ML หลักสูตรข้อมูลเบื้องต้นเกี่ยวกับการกำหนดกรอบปัญหาแมชชีนเลิร์นนิง จะครอบคลุมขั้นตอนเหล่านั้นโดยละเอียด ในระหว่างงานการวางแผน คุณจะประเมินความเป็นไปได้ของโซลูชัน วางแผนแนวทาง และกำหนดเมตริกความสำเร็จ
แม้ว่า ML อาจเป็นโซลูชันที่ดีในทางทฤษฎี แต่คุณยังคงต้องประเมินความเป็นไปได้ในโลกแห่งความเป็นจริง เช่น โซลูชันอาจใช้งานได้ในทางเทคนิค แต่ไม่สามารถนำไปใช้ได้จริง ปัจจัยต่อไปนี้ มีผลต่อความเป็นไปได้ของโปรเจ็กต์
- ความพร้อมใช้งานของข้อมูล
- ความยากของปัญหา
- คุณภาพการคาดการณ์
- ข้อกำหนดทางเทคนิค
- ค่าใช้จ่าย
ความพร้อมใช้งานของข้อมูล
โมเดล ML จะทำงานได้ดีเพียงใดนั้นขึ้นอยู่กับข้อมูลที่ใช้ฝึก โมเดลต้องการข้อมูลคุณภาพสูงจำนวนมากเพื่อทำการคาดการณ์คุณภาพสูง การตอบคำถามต่อไปนี้จะช่วยให้คุณประเมินได้ว่ามีข้อมูลที่จำเป็นต่อการฝึกโมเดลหรือไม่
จำนวน คุณมีข้อมูลคุณภาพสูงเพียงพอที่จะฝึกโมเดลไหม ตัวอย่างที่มีป้ายกำกับ หายาก ได้มายาก หรือแพงเกินไปไหม ตัวอย่างเช่น การติดป้ายกำกับรูปภาพทางการแพทย์หรือการแปลภาษาที่หายากนั้นเป็นเรื่องยากมาก หากต้องการคาดการณ์ได้ดี โมเดลการจัดประเภท ต้องมี ตัวอย่างจำนวนมากสำหรับ ป้ายกำกับทุกรายการ หาก ชุดข้อมูลการฝึก มีตัวอย่างที่จำกัดสำหรับป้ายกำกับบางรายการ โมเดลจะทำการคาดการณ์ได้ไม่ดี
ความพร้อมในการใช้งานฟีเจอร์ในเวลาที่แสดง ฟีเจอร์ทั้งหมดที่ใช้ในการ ฝึกจะพร้อมใช้งานในเวลาที่ให้บริการไหม ทีมใช้เวลาจำนวนมากฝึกโมเดล แต่ก็พบว่าฟีเจอร์บางอย่างไม่พร้อมใช้งาน จนกระทั่งหลายวันหลังจากที่โมเดลต้องการฟีเจอร์เหล่านั้น
ตัวอย่างเช่น สมมติว่าโมเดลคาดการณ์ว่าลูกค้าจะคลิก URL หรือไม่ และฟีเจอร์อย่างหนึ่งที่ใช้ในการฝึกคือ
user_ageอย่างไรก็ตาม เมื่อโมเดลแสดงผลการคาดการณ์user_ageจะไม่พร้อมใช้งาน อาจเป็นเพราะผู้ใช้ยังไม่ได้สร้างบัญชีกฎระเบียบ กฎระเบียบและข้อกำหนดทางกฎหมายสำหรับการ ได้มาและการใช้ข้อมูลมีอะไรบ้าง เช่น ข้อกำหนดบางอย่างจะกำหนดขีดจำกัดในการจัดเก็บและใช้ข้อมูลบางประเภท
Generative AI
โมเดล Generative AI ที่ผ่านการฝึกเบื้องต้นมักต้องใช้ชุดข้อมูลที่คัดสรรมาแล้วเพื่อให้ทำงานที่เจาะจงโดเมนได้ดี คุณอาจต้องใช้ชุดข้อมูลสำหรับกรณีการใช้งานต่อไปนี้
-
การออกแบบพรอมต์
การปรับแต่งที่มีประสิทธิภาพของพารามิเตอร์ และ
การปรับแต่ง
คุณอาจต้องใช้ตัวอย่างคุณภาพสูง 10-10,000 รายการเพื่อปรับแต่งเอาต์พุตของโมเดลเพิ่มเติม ทั้งนี้ขึ้นอยู่กับกรณีการใช้งาน
ตัวอย่างเช่น หากต้องมีการปรับแต่งโมเดลเพื่อทำงานบางอย่างให้ได้ดี เช่น ตอบคำถามทางการแพทย์ คุณจะต้องมีชุดข้อมูลคุณภาพสูงซึ่งแสดงถึงประเภทคำถามที่จะถาม รวมถึงประเภทคำตอบที่ควรตอบ
ตารางต่อไปนี้แสดงค่าประมาณจำนวนตัวอย่าง ที่จำเป็นในการปรับเอาต์พุตของโมเดล Generative AI สำหรับเทคนิคที่กำหนด
-
ข้อมูลล่าสุด เมื่อได้รับการฝึกเบื้องต้นแล้ว โมเดล Generative AI จะมี
ฐานความรู้ที่แน่นอน หากเนื้อหาในโดเมนของโมเดลมีการเปลี่ยนแปลงบ่อย
คุณจะต้องมีกลยุทธ์ในการอัปเดตโมเดลให้เป็นเวอร์ชันล่าสุด เช่น
- การปรับแต่ง
- การสร้างที่เพิ่มการดึงข้อมูล (RAG)
- การฝึกเบื้องต้นเป็นระยะ
| เทคนิค | จำนวนตัวอย่างที่จำเป็น |
|---|---|
| การเขียนพรอมต์แบบ Zero-Shot Prompting | 0 |
| Few-Shot Prompting | ประมาณ 10-100 วินาที |
| การปรับแต่งที่มีประสิทธิภาพของพารามิเตอร์ 1 | ~100–10,000 |
| การปรับแต่ง | ~1,000–10,000 (หรือมากกว่า) |
ความยากของปัญหา
การประเมินความยากของปัญหาอาจเป็นเรื่องยาก สิ่งที่ดูเหมือนจะเป็นแนวทางที่สมเหตุสมผลในตอนแรกอาจกลายเป็นคำถามวิจัยที่ยังไม่มีคำตอบ ส่วนสิ่งที่ดูเหมือนจะทำได้จริงอาจกลายเป็นสิ่งที่ทำไม่ได้หรือใช้งานไม่ได้ การตอบคำถามต่อไปนี้จะช่วยประเมินความยากของปัญหาได้
เคยมีปัญหาที่คล้ายกันนี้และได้รับการแก้ไขแล้วหรือไม่ เช่น ทีมในองค์กรของคุณใช้ข้อมูลที่คล้ายกัน (หรือเหมือนกัน) เพื่อสร้างโมเดลหรือไม่ มีบุคคลหรือทีมภายนอกองค์กรของคุณเคยแก้ปัญหาที่คล้ายกันไหม เช่น ที่ Kaggle หรือ TensorFlow Hub หากเป็นเช่นนั้น คุณก็น่าจะใช้บางส่วนของโมเดลของบุคคลอื่นเพื่อสร้างโมเดลของคุณเองได้
โปรเจ็กต์วิจัยที่ไม่มีโซลูชันที่รับประกันลักษณะของปัญหาซับซ้อนไหม การทราบเกณฑ์มาตรฐานของมนุษย์สำหรับ งานจะช่วยให้ทราบระดับความยากของปัญหา เช่น
- มนุษย์สามารถจัดประเภทสัตว์ในรูปภาพได้โดยมีความแม่นยำประมาณ 95%
- มนุษย์สามารถจัดประเภทตัวเลขที่เขียนด้วยลายมือได้ด้วยความแม่นยำประมาณ 99%
ข้อมูลข้างต้นชี้ให้เห็นว่าการสร้างโมเดลเพื่อจัดประเภทสัตว์นั้นยากกว่าการสร้างโมเดลเพื่อจัดประเภทตัวเลขที่เขียนด้วยลายมือ
มีผู้ไม่ประสงค์ดีที่อาจแฝงตัวอยู่ไหม จะมีผู้พยายาม ใช้ประโยชน์จากโมเดลของคุณไหม หากเป็นเช่นนั้น คุณจะต้องรีบอัปเดตโมเดลอยู่เสมอ ก่อนที่จะมีการนำไปใช้ในทางที่ผิด ตัวอย่างเช่น ตัวกรองจดหมายขยะไม่สามารถตรวจจับจดหมายขยะประเภทใหม่ ได้เมื่อมีผู้ใช้โมเดลในทางที่ผิดเพื่อสร้างอีเมลที่ดูเหมือน ถูกต้อง
Generative AI
โมเดล Generative AI มีช่องโหว่ที่อาจเพิ่มความยากของปัญหาได้ ดังนี้
- แหล่งที่มาของอินพุต ข้อมูลจะมาจากที่ใด พรอมต์ที่เป็นการโจมตี จะทำให้ข้อมูลการฝึก เนื้อหาเบื้องต้น เนื้อหาในฐานข้อมูล หรือข้อมูลเครื่องมือรั่วไหลได้ไหม
- การใช้เอาต์พุต ระบบจะใช้เอาต์พุตอย่างไร โมเดลจะแสดงเนื้อหาดิบหรือจะมีขั้นตอนกลางที่ทดสอบและยืนยันว่าเนื้อหานั้นเหมาะสม เช่น การให้เอาต์พุตดิบแก่ปลั๊กอินอาจ ทำให้เกิดปัญหาด้านความปลอดภัยหลายอย่าง
- การปรับแต่ง การปรับแต่งด้วยชุดข้อมูลที่เสียหายอาจส่งผลเสียต่อ น้ำหนักของโมเดล การทำให้ข้อมูลเสียหายนี้จะส่งผลให้โมเดล แสดงเนื้อหาที่ไม่ถูกต้อง เป็นพิษ หรือมีอคติ ดังที่ได้กล่าวไว้ก่อนหน้านี้ การปรับแต่งต้องใช้ชุดข้อมูลที่ได้รับการยืนยันว่ามี ตัวอย่างคุณภาพสูง
คุณภาพการคาดการณ์
คุณจะต้องพิจารณาอย่างรอบคอบถึงผลกระทบที่การคาดการณ์ของโมเดลจะมีต่อผู้ใช้ และกำหนดคุณภาพการคาดการณ์ที่จำเป็นสำหรับโมเดล
คุณภาพการคาดการณ์ที่จำเป็นจะขึ้นอยู่กับประเภทของการคาดการณ์ เช่น คุณภาพการคาดการณ์ที่จำเป็นสำหรับระบบคำแนะนำจะไม่เหมือนกับโมเดลที่แจ้งการละเมิดนโยบาย การแนะนำวิดีโอที่ไม่ถูกต้องอาจทำให้ผู้ใช้ได้รับประสบการณ์การใช้งานที่ไม่ดี อย่างไรก็ตาม การแจ้งว่าวิดีโอละเมิดนโยบายของแพลตฟอร์มอย่างไม่ถูกต้องอาจทำให้เกิดค่าใช้จ่ายในการสนับสนุน หรือที่แย่กว่านั้นคือค่าธรรมเนียมทางกฎหมาย
โมเดลของคุณจำเป็นต้องมีคุณภาพการคาดการณ์สูงมากไหมเนื่องจากการคาดการณ์ที่ผิดพลาดมีต้นทุนสูงมาก โดยทั่วไปแล้ว ยิ่งต้องใช้การคาดการณ์ที่มีคุณภาพสูงเท่าใด ปัญหาก็จะยิ่งยากขึ้นเท่านั้น น่าเสียดายที่โปรเจ็กต์มักจะถึงจุดที่ผลตอบแทนลดลงเมื่อคุณพยายามปรับปรุงคุณภาพ ตัวอย่างเช่น การเพิ่มความแม่นยำของโมเดลจาก 99.9% เป็น 99.99% อาจหมายถึงต้นทุนของโปรเจ็กต์เพิ่มขึ้น 10 เท่า (หรือมากกว่านั้น)
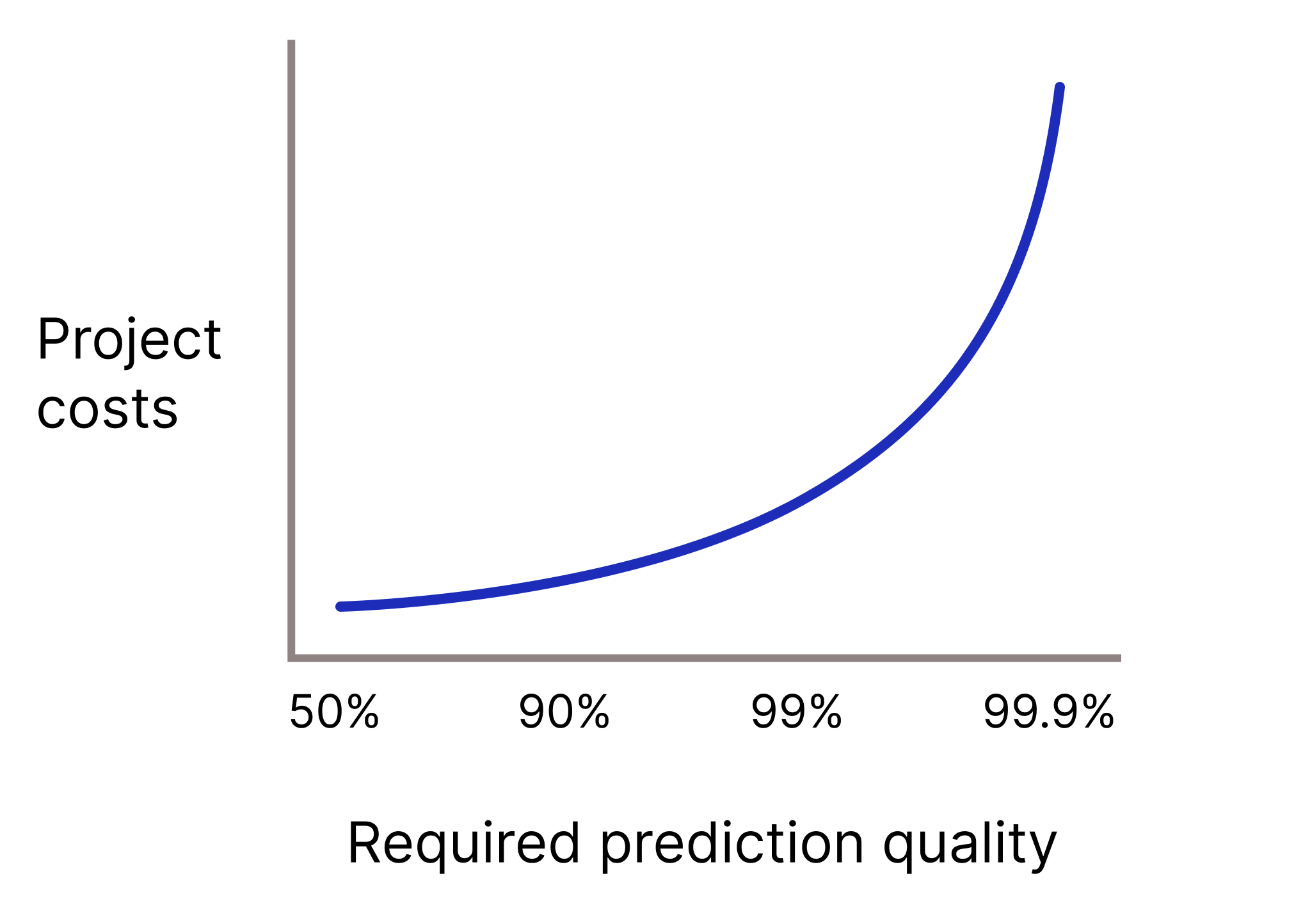
รูปที่ 2 โดยปกติแล้ว โปรเจ็กต์ ML จะต้องใช้ทรัพยากรมากขึ้นเรื่อยๆ เมื่อคุณภาพการคาดการณ์ที่ต้องการเพิ่มขึ้น
Generative AI
เมื่อวิเคราะห์ผลลัพธ์ของ Generative AI ให้พิจารณาสิ่งต่อไปนี้
-
ความถูกต้องของข้อเท็จจริง แม้ว่าโมเดล Generative AI จะสร้างเนื้อหาที่คล่องแคล่ว
และสอดคล้องกันได้ แต่ก็ไม่ได้รับประกันว่าเนื้อหาจะเป็นข้อเท็จจริง ข้อความเท็จจากโมเดล Generative AI เรียกว่าการแต่งเรื่อง
เช่น โมเดล Generative AI อาจแต่งเรื่องและสร้าง
สรุปข้อความที่ไม่ถูกต้อง คำตอบที่ผิดสำหรับคำถามคณิตศาสตร์
หรือข้อความเท็จเกี่ยวกับโลก กรณีการใช้งานหลายอย่างยังคง
ต้องมีการยืนยันจากมนุษย์สำหรับเอาต์พุตของ Generative AI ก่อนที่จะนำไปใช้
ในสภาพแวดล้อมการผลิต เช่น โค้ดที่ LLM สร้างขึ้น
เช่นเดียวกับ ML แบบเดิม ยิ่งต้องการความถูกต้องตามข้อเท็จจริงมากเท่าใด ต้นทุนในการพัฒนาและบำรุงรักษาก็จะยิ่งสูงขึ้นเท่านั้น
- คุณภาพเอาต์พุต ผลทางกฎหมายและการเงิน (หรือผลกระทบด้านจริยธรรม) ของเอาต์พุตที่ไม่ดี เช่น เนื้อหาที่ลำเอียง คัดลอกมา หรือเป็นพิษคืออะไร
ข้อกำหนดทางเทคนิค
โมเดลมีข้อกำหนดทางเทคนิคหลายอย่างที่ส่งผลต่อความเป็นไปได้ ข้อกำหนดทางเทคนิคหลักที่คุณต้องพิจารณาเพื่อกำหนดความเป็นไปได้ของโปรเจ็กต์มีดังนี้
- เวลาในการตอบสนอง ข้อกำหนดด้านเวลาในการตอบสนองมีอะไรบ้าง ต้องแสดงการคาดการณ์เร็วเพียงใด
- จำนวนคำค้นหาต่อวินาที (QPS) ข้อกำหนด QPS มีอะไรบ้าง
- การใช้ RAM ข้อกำหนดของ RAM สำหรับการฝึกและการแสดงมีอะไรบ้าง
- แพลตฟอร์ม โมเดลจะทำงานที่ใด: ออนไลน์ (คำค้นหาที่ส่งไปยังเซิร์ฟเวอร์ RPC), WebML (ภายในเว็บเบราว์เซอร์), ODML (ในโทรศัพท์หรือแท็บเล็ต) หรือออฟไลน์ (การคาดการณ์ที่บันทึกไว้ในตาราง)
ความสามารถในการตีความ การคาดการณ์จำเป็นต้องตีความได้ไหม ตัวอย่างเช่น ผลิตภัณฑ์ของคุณจะต้องตอบคำถามอย่าง "ทำไมเนื้อหาบางรายการจึงถูกทำเครื่องหมายว่าเป็นสแปม" หรือ "ทำไมวิดีโอจึงถูกระบุว่าละเมิดนโยบายของแพลตฟอร์ม" หรือไม่
ความถี่ในการฝึกโมเดลซ้ำ เมื่อข้อมูลพื้นฐานของโมเดลเปลี่ยนแปลงอย่างรวดเร็ว คุณอาจต้องฝึกโมเดลซ้ำบ่อยๆ หรืออย่างต่อเนื่อง อย่างไรก็ตาม การฝึกโมเดลซ้ำบ่อยๆ อาจทำให้มีค่าใช้จ่ายสูงมาก ซึ่งอาจมากกว่าประโยชน์ของการอัปเดตการคาดการณ์ของโมเดล
ในกรณีส่วนใหญ่ คุณอาจต้องลดคุณภาพของโมเดลลงเพื่อให้เป็นไปตามข้อกำหนดทางเทคนิค ในกรณีดังกล่าว คุณจะต้อง พิจารณาว่ายังสามารถสร้างโมเดลที่เพียงพอต่อการ ใช้งานจริงได้หรือไม่
Generative AI
โปรดคำนึงถึงข้อกำหนดทางเทคนิคต่อไปนี้เมื่อทำงานกับ Generative AI
- แพลตฟอร์ม โมเดลที่ฝึกไว้ล่วงหน้าจำนวนมากมีหลายขนาด จึงทำงานได้บนแพลตฟอร์มต่างๆ ที่มี ทรัพยากรการคำนวณที่แตกต่างกัน ตัวอย่างเช่น โมเดลที่ฝึกไว้ล่วงหน้าอาจมีตั้งแต่ขนาดระดับศูนย์ข้อมูลไปจนถึงขนาดที่พอดีกับโทรศัพท์ คุณจะต้องพิจารณาข้อจำกัดด้านเวลาในการตอบสนอง ความเป็นส่วนตัว และคุณภาพของผลิตภัณฑ์หรือบริการเมื่อเลือกขนาดโมเดล ข้อจำกัดเหล่านี้มักขัดแย้งกัน ตัวอย่างเช่น ข้อจำกัดด้านความเป็นส่วนตัวอาจกำหนดให้การอนุมานทำงานในอุปกรณ์ของผู้ใช้ อย่างไรก็ตาม คุณภาพเอาต์พุตอาจไม่ดีเนื่องจากอุปกรณ์ไม่มีทรัพยากรการประมวลผลที่จะสร้างผลลัพธ์ที่ดี
- เวลาในการตอบสนอง ขนาดอินพุตและเอาต์พุตของโมเดลส่งผลต่อเวลาในการตอบสนอง โดยเฉพาะอย่างยิ่ง ขนาดเอาต์พุตส่งผลต่อเวลาในการตอบสนองมากกว่าขนาดอินพุต แม้ว่าโมเดลจะประมวลผลอินพุตแบบขนานได้ แต่จะสร้างเอาต์พุตได้ตามลำดับเท่านั้น กล่าวคือ เวลาในการตอบสนองอาจเท่ากันในการป้อนข้อมูล 500 คำหรือ 10 คำ แต่การสร้างสรุป 500 คำจะใช้เวลานานกว่าการสร้างสรุป 10 คำอย่างมาก
- การใช้เครื่องมือและ API โมเดลจะต้องใช้เครื่องมือและ API เช่น การค้นหาในอินเทอร์เน็ต การใช้เครื่องคิดเลข หรือการเข้าถึง โปรแกรมรับส่งอีเมลเพื่อทำงานให้เสร็จหรือไม่ โดยปกติแล้ว ยิ่งต้องใช้เครื่องมือมากเท่าใดในการ ทำงานให้เสร็จ ก็ยิ่งมีโอกาสที่จะเกิดข้อผิดพลาดและ เพิ่มช่องโหว่ของโมเดลมากขึ้นเท่านั้น
ค่าใช้จ่าย
การติดตั้งใช้งาน ML จะคุ้มค่าใช้จ่ายไหม โปรเจ็กต์ ML ส่วนใหญ่จะไม่ได้รับการอนุมัติ หากโซลูชัน ML มีต้นทุนในการติดตั้งใช้งานและบำรุงรักษาสูงกว่าเงินที่โซลูชัน สร้าง (หรือประหยัด) ได้ โปรเจ็กต์ ML จะมีค่าใช้จ่ายทั้งของมนุษย์และเครื่องจักร
ค่าใช้จ่ายด้านบุคลากร ต้องใช้คนกี่คนในการทำให้โปรเจ็กต์เปลี่ยนจาก การพิสูจน์แนวคิดไปสู่การผลิต เมื่อโปรเจ็กต์ ML พัฒนาขึ้น ค่าใช้จ่ายมักจะ เพิ่มขึ้น ตัวอย่างเช่น โปรเจ็กต์ ML ต้องใช้บุคลากรจำนวนมากกว่าในการติดตั้งใช้งานและ บำรุงรักษาระบบที่พร้อมใช้งานจริงมากกว่าการสร้างต้นแบบ ลอง ประเมินจำนวนและประเภทของบทบาทที่โปรเจ็กต์จะต้องมีในแต่ละเฟส
ค่าเครื่อง การฝึก การใช้งาน และการบำรุงรักษาโมเดลต้องใช้การประมวลผลและหน่วยความจำจำนวนมาก เช่น คุณอาจต้องมีโควต้า TPU สำหรับการฝึกโมเดลและการแสดงผลการคาดการณ์ รวมถึงโครงสร้างพื้นฐานที่จำเป็นสำหรับไปป์ไลน์ข้อมูล คุณอาจต้องชำระเงินเพื่อติดป้ายกำกับข้อมูลหรือชำระค่าธรรมเนียมการอนุญาตให้ใช้ข้อมูล ก่อนฝึกโมเดล ให้พิจารณาการประมาณค่าใช้จ่ายของเครื่อง ในการสร้างและบำรุงรักษาฟีเจอร์ ML ในระยะยาว
ค่าใช้จ่ายในการอนุมาน โมเดลจะต้องทำการอนุมานหลายร้อยหรือหลายพันรายการ ซึ่งมีค่าใช้จ่ายมากกว่ารายได้ที่สร้างขึ้นหรือไม่
โปรดทราบ
การพบปัญหาที่เกี่ยวข้องกับหัวข้อก่อนหน้าอาจทำให้การใช้โซลูชัน ML เป็นเรื่องท้าทาย แต่กำหนดเวลาที่กระชั้นชิดอาจเพิ่มความท้าทายให้มากขึ้น พยายามวางแผนและจัดสรรเวลาให้เพียงพอตามความยากของปัญหาที่รับรู้ แล้วพยายามจัดสรรเวลาเพิ่มเติมมากกว่าที่คุณอาจทำสำหรับโปรเจ็กต์ที่ไม่ใช่ ML
ทดสอบความเข้าใจ
คุณทำงานให้กับบริษัทอนุรักษ์ธรรมชาติและจัดการซอฟต์แวร์ระบุพืชของบริษัท คุณต้องการสร้างโมเดลเพื่อจัดประเภทพืชพันธุ์ต่างถิ่น 60 ชนิดเพื่อช่วยนักอนุรักษ์จัดการที่อยู่อาศัยของสัตว์ใกล้สูญพันธุ์
คุณพบโค้ดตัวอย่างที่แก้ปัญหาการระบุพืชที่คล้ายกัน และค่าใช้จ่ายโดยประมาณในการใช้โซลูชันของคุณอยู่ในงบประมาณของโปรเจ็กต์ แม้ว่าชุดข้อมูลจะมีตัวอย่างการฝึกมากมาย แต่ก็มีตัวอย่างของ สายพันธุ์ที่รุกรานมากที่สุด 5 ชนิดเพียงไม่กี่ตัวอย่าง ฝ่ายบริหารไม่ได้กำหนดให้ การคาดการณ์ของโมเดลต้องตีความได้ และดูเหมือนว่า จะไม่มีผลเสียที่เกี่ยวข้องกับการคาดการณ์ที่ไม่ดี โซลูชัน ML ของคุณ เป็นไปได้ไหม