Selama fase pemunculan ide dan perencanaan, Anda menyelidiki elemen solusi ML. Selama tugas pembentukan masalah, Anda membentuk masalah dalam hal solusi ML. Kursus Pengantar Pembentukan Masalah Machine Learning membahas langkah-langkah tersebut secara mendetail. Selama tugas perencanaan, Anda memperkirakan kelayakan solusi, merencanakan pendekatan, dan menetapkan metrik keberhasilan.
Meskipun ML mungkin merupakan solusi yang baik secara teoretis, Anda tetap perlu memperkirakan kelayakannya di dunia nyata. Misalnya, solusi mungkin berfungsi secara teknis, tetapi tidak praktis atau tidak mungkin diterapkan. Faktor-faktor berikut memengaruhi kelayakan project:
- Ketersediaan data
- Tingkat kesulitan masalah
- Kualitas prediksi
- Persyaratan teknis
- Biaya
Ketersediaan data
Kualitas model ML bergantung pada kualitas data yang digunakan untuk melatihnya. Model ini memerlukan banyak data berkualitas tinggi untuk membuat prediksi berkualitas tinggi. Menjawab pertanyaan berikut dapat membantu Anda menilai apakah Anda memiliki data yang diperlukan untuk melatih model:
Jumlah. Dapatkah Anda memperoleh data berkualitas tinggi yang cukup untuk melatih model? Apakah contoh berlabel langka, sulit didapatkan, atau terlalu mahal? Misalnya, mendapatkan gambar medis berlabel atau terjemahan bahasa yang jarang digunakan sangat sulit. Untuk membuat prediksi yang baik, model klasifikasi memerlukan banyak contoh untuk setiap label. Jika set data pelatihan berisi contoh terbatas untuk beberapa label, model tidak dapat membuat prediksi yang baik.
Ketersediaan fitur pada waktu penayangan. Apakah semua fitur yang digunakan dalam pelatihan akan tersedia pada waktu penayangan? Tim telah menghabiskan banyak waktu untuk melatih model, tetapi menyadari bahwa beberapa fitur baru tersedia beberapa hari setelah model tersebut membutuhkannya.
Misalnya, anggaplah model memprediksi apakah pelanggan akan mengklik URL, dan salah satu fitur yang digunakan dalam pelatihan mencakup
user_age. Namun, saat model menyajikan prediksi,user_agetidak tersedia, mungkin karena pengguna belum membuat akun.Peraturan. Apa saja peraturan dan persyaratan hukum untuk mendapatkan dan menggunakan data tersebut? Misalnya, beberapa persyaratan menetapkan batasan untuk menyimpan dan menggunakan jenis data tertentu.
AI Generatif
Model AI generatif terlatih sering kali memerlukan set data yang dikurasi agar dapat unggul dalam tugas khusus domain. Anda mungkin memerlukan set data untuk kasus penggunaan berikut:
-
Rekayasa perintah,
parameter-efficient tuning, dan
fine-tuning.
Bergantung pada kasus penggunaan, Anda mungkin memerlukan 10 hingga 10.000 contoh berkualitas tinggi
untuk lebih menyempurnakan output model. Misalnya, jika model perlu di-fine-tune agar unggul dalam tugas tertentu, seperti menjawab pertanyaan medis, Anda memerlukan set data berkualitas tinggi yang representatif dari jenis pertanyaan yang akan diajukan dan jenis jawaban yang harus diberikan.
Tabel berikut memberikan perkiraan jumlah contoh yang diperlukan untuk menyempurnakan output model AI generatif untuk teknik tertentu:
-
Informasi terbaru. Setelah dilatih, model AI generatif memiliki
pusat informasi tetap. Jika konten di domain model sering berubah,
Anda memerlukan strategi untuk menjaga model tetap terbaru, seperti:
- penyesuaian
- retrieval-augmented generation (RAG)
- pelatihan awal berkala
| Teknik | Jumlah contoh yang diperlukan |
|---|---|
| Zero-shot prompting | 0 |
| Few-shot prompting | ~10 dtk–100 dtk |
| Parameter-efficient tuning 1 | ~100–10.000 |
| Fine tuning | ~1.000–10.000 (atau lebih) |
Tingkat kesulitan masalah
Tingkat kesulitan masalah mungkin sulit diperkirakan. Apa yang awalnya tampak sebagai pendekatan yang masuk akal mungkin sebenarnya menjadi pertanyaan penelitian terbuka; apa yang tampak praktis dan dapat dilakukan mungkin ternyata tidak realistis atau tidak dapat dilakukan. Menjawab pertanyaan berikut dapat membantu mengukur tingkat kesulitan masalah:
Apakah masalah serupa sudah pernah diselesaikan? Misalnya, apakah tim di organisasi Anda telah menggunakan data serupa (atau identik) untuk membangun model? Apakah orang atau tim di luar organisasi Anda pernah memecahkan masalah serupa, misalnya, di Kaggle atau TensorFlow Hub? Jika demikian, kemungkinan Anda dapat menggunakan bagian model mereka untuk membangun model Anda.
Apakah sifat masalahnya sulit? Mengetahui tolok ukur manusia untuk tugas tersebut dapat menginformasikan tingkat kesulitan masalah. Contoh:
- Manusia dapat mengklasifikasikan jenis hewan dalam gambar dengan akurasi sekitar 95%.
- Manusia dapat mengklasifikasikan digit tulisan tangan dengan akurasi sekitar 99%.
Data sebelumnya menunjukkan bahwa membuat model untuk mengklasifikasikan hewan lebih sulit daripada membuat model untuk mengklasifikasikan digit tulisan tangan.
Apakah ada potensi pelaku kejahatan? Apakah orang akan secara aktif mencoba mengeksploitasi model Anda? Jika demikian, Anda akan terus berupaya memperbarui model sebelum model tersebut dapat disalahgunakan. Misalnya, filter spam tidak dapat mendeteksi jenis spam baru saat seseorang mengeksploitasi model untuk membuat email yang tampak sah.
AI Generatif
Model AI generatif memiliki potensi kerentanan yang dapat meningkatkan kesulitan masalah:
- Sumber input. Dari mana input akan berasal? Dapatkah perintah adversarial membocorkan data pelatihan, materi pengantar, konten database, atau informasi alat?
- Penggunaan output. Bagaimana output akan digunakan? Apakah model akan menghasilkan konten mentah atau akan ada langkah-langkah perantara yang menguji dan memverifikasi kesesuaiannya? Misalnya, memberikan output mentah ke plugin dapat menyebabkan sejumlah masalah keamanan.
- Fine-tuning. Penyesuaian dengan set data yang rusak dapat berdampak negatif pada bobot model. Kerusakan ini akan menyebabkan model menghasilkan konten yang salah, berbahaya, atau bias. Seperti yang disebutkan sebelumnya, penyesuaian memerlukan set data yang telah diverifikasi berisi contoh berkualitas tinggi.
Kualitas prediksi
Anda harus mempertimbangkan dengan cermat dampak prediksi model terhadap pengguna dan menentukan kualitas prediksi yang diperlukan untuk model.
Kualitas prediksi yang diperlukan bergantung pada jenis prediksi. Misalnya, kualitas prediksi yang diperlukan untuk sistem rekomendasi tidak akan sama dengan model yang menandai pelanggaran kebijakan. Merekomendasikan video yang salah dapat menciptakan pengalaman pengguna yang buruk. Namun, menandai video secara keliru sebagai melanggar kebijakan platform dapat menimbulkan biaya dukungan, atau lebih buruk lagi, biaya hukum.
Apakah model Anda perlu memiliki kualitas prediksi yang sangat tinggi karena prediksi yang salah sangat merugikan? Umumnya, makin tinggi kualitas prediksi yang diperlukan, makin sulit masalahnya. Sayangnya, proyek sering kali mencapai titik penurunan hasil saat Anda mencoba meningkatkan kualitas. Misalnya, meningkatkan presisi model dari 99,9% menjadi 99,99% dapat berarti peningkatan biaya project 10 kali lipat (atau lebih).
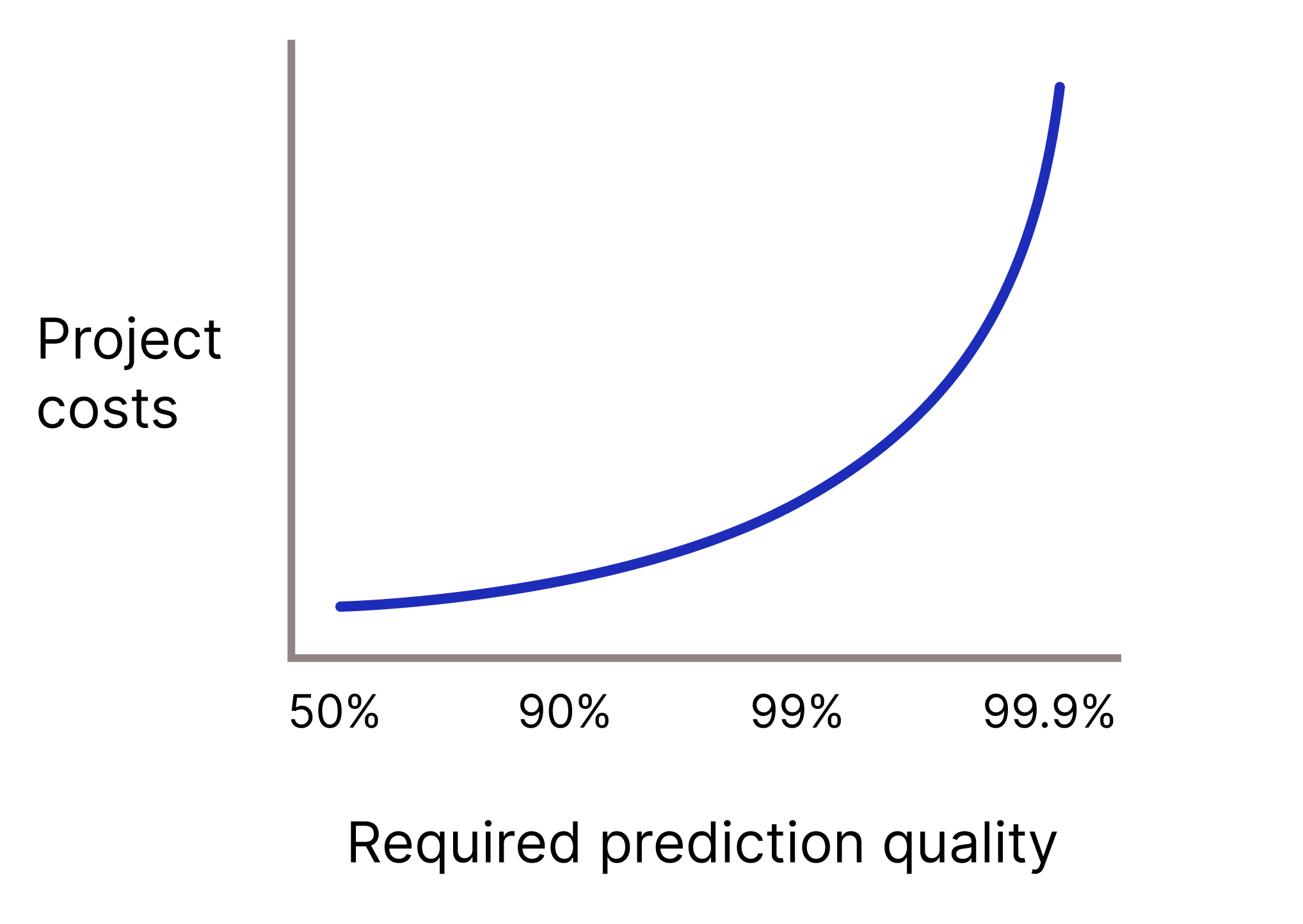
Gambar 2. Project ML biasanya memerlukan lebih banyak resource seiring dengan peningkatan kualitas prediksi yang diperlukan.
AI Generatif
Saat menganalisis output AI generatif, pertimbangkan hal-hal berikut:
-
Akurasi faktual. Meskipun model AI generatif dapat menghasilkan konten yang lancar
dan koheren, konten tersebut tidak dijamin faktual. Pernyataan salah dari model AI generatif disebut konfabulasi.
Misalnya, model AI generatif dapat berkonfabulasi dan menghasilkan
ringkasan teks yang salah, jawaban yang salah untuk pertanyaan matematika,
atau pernyataan palsu tentang dunia. Banyak kasus penggunaan masih memerlukan verifikasi manusia terhadap output AI generatif sebelum digunakan di lingkungan produksi, misalnya, kode yang dihasilkan LLM.
Seperti ML tradisional, makin tinggi persyaratan akurasi faktual, makin tinggi biaya pengembangan dan pemeliharaannya.
- Kualitas output. Apa konsekuensi hukum dan keuangan (atau implikasi etis) dari output yang buruk, seperti konten yang bias, diplagiasi, atau beracun?
Persyaratan teknis
Model memiliki sejumlah persyaratan teknis yang memengaruhi kelayakannya. Berikut adalah persyaratan teknis utama yang perlu Anda penuhi untuk menentukan kelayakan project:
- Latensi. Apa saja persyaratan latensi? Seberapa cepat prediksi harus ditayangkan?
- Kueri per detik (QPS). Apa persyaratan QPS?
- Penggunaan RAM. Berapa persyaratan RAM untuk pelatihan dan penayangan?
- Platform. Di mana model akan berjalan: Online (kueri dikirim ke server RPC), WebML (di dalam browser web), ODML (di ponsel atau tablet), atau offline (prediksi disimpan dalam tabel)?
Kemampuan untuk ditafsirkan. Apakah prediksi perlu dapat diinterpretasikan? Misalnya, apakah produk Anda perlu menjawab pertanyaan seperti, "Mengapa konten tertentu ditandai sebagai spam?" atau "Mengapa video ditentukan melanggar kebijakan platform?"
Frekuensi pelatihan ulang. Jika data pokok untuk model Anda berubah dengan cepat, pelatihan ulang yang sering atau berkelanjutan mungkin diperlukan. Namun, pelatihan ulang yang sering dapat menimbulkan biaya yang signifikan yang mungkin lebih besar daripada manfaat memperbarui prediksi model.
Dalam sebagian besar kasus, Anda mungkin harus mengorbankan kualitas model agar sesuai dengan spesifikasi teknisnya. Dalam kasus tersebut, Anda harus menentukan apakah Anda masih dapat membuat model yang cukup baik untuk digunakan dalam produksi.
AI Generatif
Pertimbangkan persyaratan teknis berikut saat menggunakan AI generatif:
- Platform. Banyak model terlatih yang tersedia dalam berbagai ukuran, sehingga dapat berfungsi di berbagai platform dengan resource komputasi yang berbeda. Misalnya, model terlatih dapat berkisar dari skala pusat data hingga dapat diakses di ponsel. Anda harus mempertimbangkan batasan latensi, privasi, dan kualitas produk atau layanan saat memilih ukuran model. Batasan ini sering kali bertentangan. Misalnya, batasan privasi mungkin mengharuskan inferensi dijalankan di perangkat pengguna. Namun, kualitas output mungkin buruk karena perangkat tidak memiliki sumber daya komputasi untuk menghasilkan hasil yang baik.
- Latensi. Ukuran input dan output model memengaruhi latensi. Khususnya, ukuran output memengaruhi latensi lebih besar daripada ukuran input. Meskipun model dapat memparalelkan inputnya, model hanya dapat menghasilkan output secara berurutan. Dengan kata lain, latensi mungkin sama untuk menyerap input 500 kata atau 10 kata, sementara pembuatan ringkasan 500 kata membutuhkan waktu yang jauh lebih lama daripada pembuatan ringkasan 10 kata.
- Penggunaan alat dan API. Apakah model perlu menggunakan alat dan API, seperti menelusuri internet, menggunakan kalkulator, atau mengakses program email untuk menyelesaikan tugas? Biasanya, semakin banyak alat yang diperlukan untuk menyelesaikan tugas, semakin besar peluang untuk menyebarkan kesalahan dan meningkatkan kerentanan model.
Biaya
Apakah penerapan ML sepadan dengan biayanya? Sebagian besar project ML tidak akan disetujui jika solusi ML lebih mahal untuk diterapkan dan dipertahankan daripada uang yang dihasilkan (atau dihemat). Project ML menimbulkan biaya manusia dan biaya mesin.
Biaya manusia. Berapa banyak orang yang dibutuhkan agar proyek tersebut dapat beralih dari bukti konsep ke produksi? Seiring berkembangnya project ML, pengeluaran biasanya meningkat. Misalnya, project ML memerlukan lebih banyak orang untuk men-deploy dan memelihara sistem yang siap produksi daripada membuat prototipe. Coba perkirakan jumlah dan jenis peran yang dibutuhkan proyek pada setiap fase.
Biaya mesin. Melatih, men-deploy, dan mengelola model memerlukan banyak komputasi dan memori. Misalnya, Anda mungkin memerlukan kuota TPU untuk melatih model dan menayangkan prediksi, beserta infrastruktur yang diperlukan untuk pipeline data Anda. Anda mungkin harus membayar untuk mendapatkan label data atau membayar biaya lisensi data. Sebelum melatih model, pertimbangkan untuk memperkirakan biaya mesin untuk membangun dan memelihara fitur ML dalam jangka panjang.
Biaya inferensi. Apakah model perlu membuat ratusan atau ribuan inferensi yang biayanya lebih besar daripada pendapatan yang dihasilkan?
Perhatikan
Menghadapi masalah terkait salah satu topik sebelumnya dapat membuat penerapan solusi ML menjadi tantangan, tetapi tenggat waktu yang ketat dapat memperburuk tantangan tersebut. Coba rencanakan dan anggarkan waktu yang cukup berdasarkan perkiraan kesulitan masalah, lalu coba sisihkan waktu tambahan yang lebih banyak daripada yang mungkin Anda lakukan untuk project non-ML.
Periksa Pemahaman Anda
Anda bekerja di perusahaan pelestarian alam dan mengelola software identifikasi tanaman perusahaan. Anda ingin membuat model untuk mengklasifikasikan 60 jenis spesies tanaman invasif untuk membantu ahli konservasi mengelola habitat hewan langka.
Anda menemukan contoh kode yang memecahkan masalah identifikasi tanaman serupa, dan perkiraan biaya untuk menerapkan solusi Anda sesuai dengan anggaran project. Meskipun memiliki banyak contoh pelatihan, set data ini hanya memiliki sedikit contoh untuk lima spesies invasif yang paling berbahaya. Pimpinan tidak mewajibkan prediksi model dapat diinterpretasikan, dan tampaknya tidak ada konsekuensi negatif terkait prediksi yang buruk. Apakah solusi ML Anda layak?