आइडिया बनाने और प्लान करने के चरण में, एमएल समाधान के कॉम्पोनेंट की जांच की जाती है. समस्या को फ़्रेम करने के टास्क के दौरान, समस्या को एमएल के समाधान के तौर पर फ़्रेम किया जाता है. मशीन लर्निंग की समस्या को फ़्रेम करने के बारे में जानकारी कोर्स में, इन चरणों के बारे में पूरी जानकारी दी गई है. प्लानिंग के दौरान, किसी समाधान के व्यवहार्यता का अनुमान लगाया जाता है, प्लान बनाने के तरीके तय किए जाते हैं, और सफलता के मेट्रिक सेट किए जाते हैं.
एमएल, सैद्धांतिक तौर पर एक अच्छा समाधान हो सकता है. हालांकि, आपको यह अनुमान लगाना होगा कि यह असल दुनिया में कितना कारगर होगा. उदाहरण के लिए, ऐसा हो सकता है कि कोई समाधान तकनीकी तौर पर काम करे, लेकिन उसे लागू करना मुश्किल हो या मुमकिन न हो. किसी प्रोजेक्ट के फ़ायदेमंद होने पर इन बातों का असर पड़ता है:
- डेटा की उपलब्धता
- समस्या का लेवल
- अनुमान की क्वालिटी
- तकनीकी ज़रूरतें
- लागत
डेटा की उपलब्धता
एमएल मॉडल से मिलने वाले नतीजे, उन्हें उपलब्ध कराए गए डेटा पर निर्भर करते हैं. इन्हें अच्छी क्वालिटी के अनुमान लगाने के लिए, अच्छी क्वालिटी के डेटा की ज़रूरत होती है. इन सवालों के जवाब देने से, आपको यह तय करने में मदद मिल सकती है कि आपके पास मॉडल को ट्रेन करने के लिए ज़रूरी डेटा है या नहीं:
संख्या. क्या आपके पास मॉडल को ट्रेन करने के लिए, अच्छी क्वालिटी का ज़रूरत के मुताबिक डेटा है? क्या लेबल किए गए उदाहरण कम हैं, उन्हें पाना मुश्किल है या वे बहुत महंगे हैं? उदाहरण के लिए, मेडिकल इमेज को लेबल करना या कम बोली जाने वाली भाषाओं का अनुवाद करना बहुत मुश्किल होता है. अच्छे अनुमान लगाने के लिए, क्लासिफ़िकेशन मॉडल को हर लेबल के लिए कई उदाहरणों की ज़रूरत होती है. अगर ट्रेनिंग डेटासेट में कुछ लेबल के लिए सीमित उदाहरण शामिल हैं, तो मॉडल सटीक अनुमान नहीं लगा सकता.
विज्ञापन दिखाने के समय सुविधा की उपलब्धता. क्या ट्रेनिंग के दौरान इस्तेमाल की गई सभी सुविधाएं, विज्ञापन दिखाने के समय उपलब्ध होंगी? टीमों ने मॉडल को ट्रेनिंग देने में काफ़ी समय बिताया. हालांकि, उन्हें बाद में पता चला कि कुछ सुविधाएं, मॉडल को उनकी ज़रूरत पड़ने के कई दिनों बाद उपलब्ध हुईं.
उदाहरण के लिए, मान लें कि कोई मॉडल यह अनुमान लगाता है कि कोई ग्राहक किसी यूआरएल पर क्लिक करेगा या नहीं. साथ ही, ट्रेनिंग में इस्तेमाल की गई सुविधाओं में से एक
user_ageहै. हालांकि, जब मॉडल अनुमान दिखाता है, तबuser_ageउपलब्ध नहीं होता. ऐसा इसलिए हो सकता है, क्योंकि उपयोगकर्ता ने अब तक खाता नहीं बनाया है.रेगुलेशन. डेटा को इकट्ठा करने और उसका इस्तेमाल करने के लिए, कौनसे कानून और कानूनी शर्तें लागू होती हैं? उदाहरण के लिए, कुछ ज़रूरी शर्तों में, कुछ खास तरह के डेटा को सेव करने और इस्तेमाल करने की सीमाएं तय की गई हैं.
जनरेटिव एआई
प्री-ट्रेन किए गए जनरेटिव एआई मॉडल को अक्सर, डोमेन के हिसाब से खास टास्क पूरे करने के लिए, चुने गए डेटासेट की ज़रूरत होती है. आपको इन इस्तेमाल के उदाहरणों के लिए डेटासेट की ज़रूरत पड़ सकती है:
-
प्रॉम्प्ट इंजीनियरिंग,
पैरामीटर के हिसाब से ट्यूनिंग, और
फ़ाइन-ट्यूनिंग.
इस्तेमाल के उदाहरण के आधार पर, आपको किसी मॉडल के आउटपुट को और बेहतर बनाने के लिए, 10 से 10,000 अच्छी क्वालिटी वाले उदाहरणों की ज़रूरत पड़ सकती है. उदाहरण के लिए, अगर किसी मॉडल को किसी खास काम को बेहतर तरीके से करने के लिए फ़ाइन-ट्यून करने की ज़रूरत है, जैसे कि मेडिकल से जुड़े सवालों के जवाब देना, तो आपको एक अच्छी क्वालिटी वाले डेटासेट की ज़रूरत होगी. इसमें ऐसे सवाल होने चाहिए जो मॉडल से पूछे जाएंगे. साथ ही, इसमें ऐसे जवाब होने चाहिए जो मॉडल को देने चाहिए.
यहां दी गई टेबल में, जनरेटिव एआई मॉडल के आउटपुट को बेहतर बनाने के लिए, अलग-अलग तकनीकों के हिसाब से ज़रूरी उदाहरणों की संख्या का अनुमान दिया गया है:
-
अप-टू-डेट जानकारी. पहले से ट्रेन किए गए जनरेटिव एआई मॉडल के पास, जानकारी का एक तय डेटाबेस होता है. अगर मॉडल के डोमेन में मौजूद कॉन्टेंट अक्सर बदलता रहता है, तो आपको मॉडल को अप-टू-डेट रखने के लिए एक रणनीति की ज़रूरत होगी. जैसे:
- फ़ाइन-ट्यूनिंग
- रिट्रीवल-ऑगमेंटेड जनरेशन (आरएजी)
- समय-समय पर प्री-ट्रेनिंग
| तकनीक | ज़रूरी उदाहरणों की संख्या |
|---|---|
| ज़ीरो-शॉट प्रॉम्प्ट | 0 |
| उदाहरण के साथ डाले गए प्रॉम्प्ट | ~10 से 100 सेकंड |
| पैरामीटर के हिसाब से कम खर्च में ट्यूनिंग 1 | ~100 से 10,000 |
| फ़ाइन-ट्यूनिंग | ~1,000 से 10,000 (या इससे ज़्यादा) |
समस्या का लेवल
किसी समस्या के मुश्किल होने का अनुमान लगाना मुश्किल हो सकता है. ऐसा हो सकता है कि शुरुआत में आपको कोई तरीका सही लगे, लेकिन बाद में पता चले कि वह रिसर्च का एक खुला सवाल है. ऐसा भी हो सकता है कि आपको कोई तरीका व्यावहारिक और लागू करने लायक लगे, लेकिन बाद में पता चले कि वह अवास्तविक है या काम नहीं करता. इन सवालों के जवाब देने से, समस्या की गंभीरता का पता लगाया जा सकता है:
क्या मिलती-जुलती समस्या पहले ही हल हो चुकी है? उदाहरण के लिए, क्या आपके संगठन की टीमों ने मॉडल बनाने के लिए, एक जैसा (या मिलता-जुलता) डेटा इस्तेमाल किया है? क्या आपके संगठन से बाहर के लोगों या टीमों ने इस तरह की समस्याओं को हल किया है? उदाहरण के लिए, Kaggle या TensorFlow Hub पर? अगर ऐसा है, तो हो सकता है कि आपको अपना मॉडल बनाने के लिए, उनके मॉडल के कुछ हिस्सों का इस्तेमाल करने की अनुमति मिल जाए.
क्या समस्या का समाधान करना मुश्किल है? टास्क के लिए, मैन्युअल तरीके से किए गए आकलन के बेंचमार्क से, समस्या के मुश्किल लेवल के बारे में जानकारी मिल सकती है. उदाहरण के लिए:
- इंसान, किसी इमेज में मौजूद जानवर की प्रजाति की पहचान 95% सटीकता के साथ कर सकते हैं.
- हाथ से लिखे गए अंकों को, इंसान करीब 99% सटीकता के साथ पहचान सकते हैं.
ऊपर दिए गए डेटा से पता चलता है कि जानवरों को कैटगरी में बांटने वाला मॉडल बनाना, हाथ से लिखे गए अंकों को कैटगरी में बांटने वाले मॉडल बनाने की तुलना में ज़्यादा मुश्किल है.
क्या ऐसे लोग हैं जो नुकसान पहुंचा सकते हैं? क्या लोग आपके मॉडल का गलत इस्तेमाल करने की कोशिश करेंगे? अगर ऐसा होता है, तो आपको मॉडल को अपडेट करने के लिए लगातार काम करना होगा, ताकि उसका गलत इस्तेमाल न हो. उदाहरण के लिए, जब कोई व्यक्ति मॉडल का इस्तेमाल करके ऐसे ईमेल बनाता है जो असली लगते हैं, तो स्पैम फ़िल्टर नए तरह के स्पैम का पता नहीं लगा पाते.
जनरेटिव एआई
जनरेटिव एआई मॉडल में कुछ कमियां हो सकती हैं. इनकी वजह से, किसी समस्या को हल करने में मुश्किल हो सकती है:
- इनपुट का सोर्स. इनपुट कहां से मिलेगा? क्या विरोध में तैयार किए गए प्रॉम्प्ट से, ट्रेनिंग डेटा, प्रस्तावना वाला कॉन्टेंट, डेटाबेस कॉन्टेंट या टूल की जानकारी लीक हो सकती है?
- आउटपुट का इस्तेमाल. आउटपुट का इस्तेमाल कैसे किया जाएगा? क्या मॉडल से मिलने वाले आउटपुट में रॉ कॉन्टेंट होगा या इसमें ऐसे चरण शामिल होंगे जिनसे यह जांच की जा सके कि कॉन्टेंट सही है या नहीं? उदाहरण के लिए, प्लगिन को रॉ आउटपुट देने से सुरक्षा से जुड़ी कई समस्याएं हो सकती हैं.
- फ़ाइन-ट्यूनिंग. खराब डेटासेट के साथ फ़ाइन-ट्यून करने से, मॉडल के वेट पर बुरा असर पड़ सकता है. इस तरह के डेटा से मॉडल, गलत, आपत्तिजनक या पक्षपात वाला कॉन्टेंट जनरेट कर सकता है. जैसा कि पहले बताया गया है, फ़ाइन-ट्यूनिंग के लिए ऐसे डेटासेट की ज़रूरत होती है जिसकी पुष्टि हो चुकी हो और जिसमें अच्छी क्वालिटी के उदाहरण शामिल हों.
अनुमान की क्वालिटी
आपको इस बात पर ध्यान देना होगा कि मॉडल की अनुमानित वैल्यू का आपके उपयोगकर्ताओं पर क्या असर पड़ेगा. साथ ही, आपको यह तय करना होगा कि मॉडल के लिए अनुमानित वैल्यू की क्वालिटी कितनी ज़रूरी है.
अनुमान की ज़रूरी क्वालिटी, अनुमान के टाइप पर निर्भर करती है. उदाहरण के लिए, सुझाव देने वाले सिस्टम के लिए ज़रूरी अनुमान की क्वालिटी, नीति के उल्लंघनों को फ़्लैग करने वाले मॉडल के लिए एक जैसी नहीं होगी. गलत वीडियो का सुझाव देने से, उपयोगकर्ता को खराब अनुभव मिल सकता है. हालांकि, किसी वीडियो को गलत तरीके से फ़्लैग करने पर, सहायता के लिए शुल्क देना पड़ सकता है. इसके अलावा, कानूनी शुल्क भी देना पड़ सकता है.
क्या आपके मॉडल को अनुमान लगाने की बहुत अच्छी क्वालिटी की ज़रूरत है, क्योंकि गलत अनुमान लगाने पर बहुत ज़्यादा नुकसान हो सकता है? आम तौर पर, अनुमान लगाने की क्वालिटी जितनी बेहतर होगी, समस्या उतनी ही मुश्किल होगी. माफ़ करें, क्वालिटी को बेहतर बनाने की कोशिश करने पर, अक्सर प्रोजेक्ट के फ़ायदे कम हो जाते हैं. उदाहरण के लिए, किसी मॉडल की सटीकता को 99.9% से बढ़ाकर 99.99% करने पर, प्रोजेक्ट की लागत 10 गुना बढ़ सकती है.
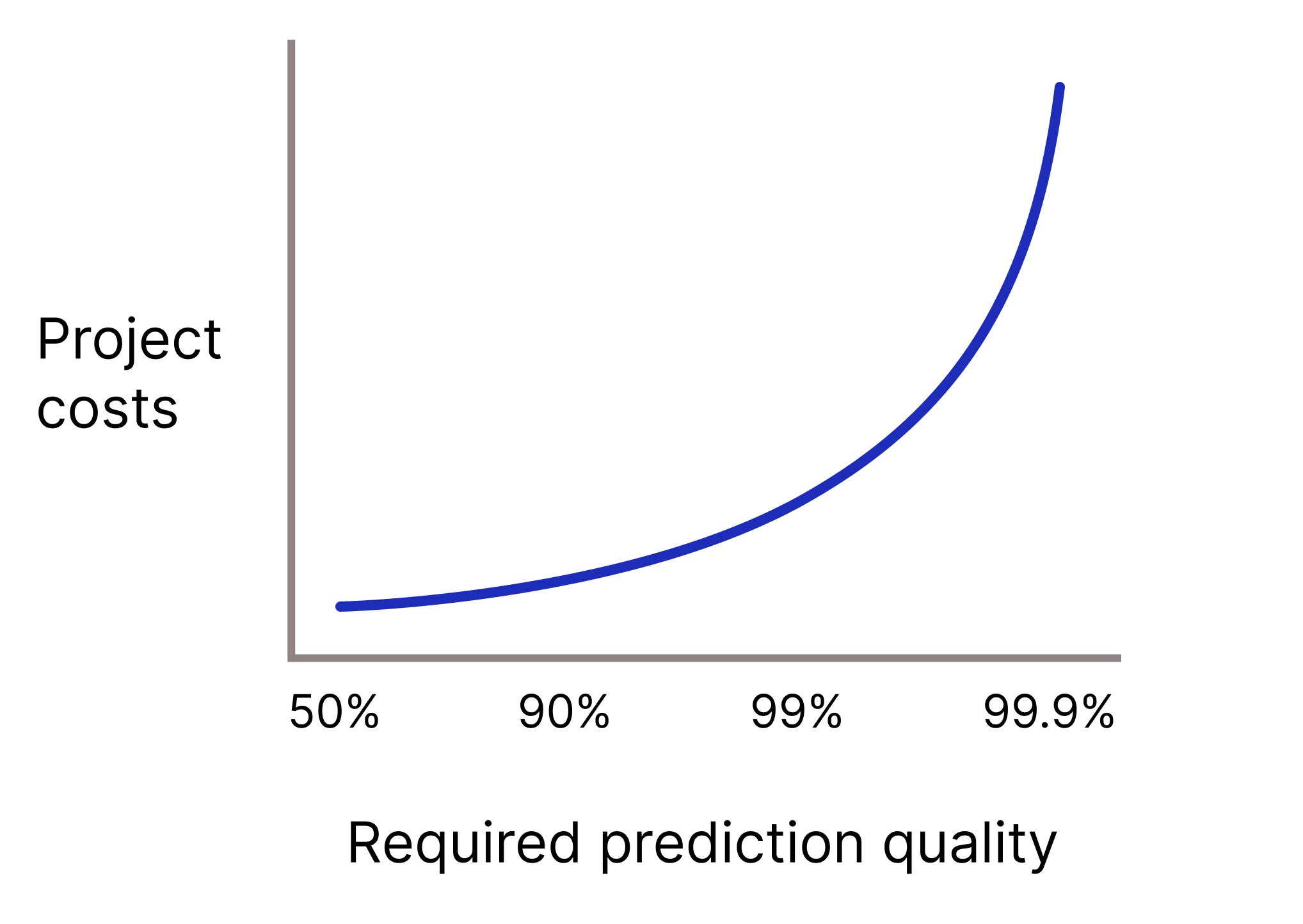
दूसरी इमेज. आम तौर पर, एमएल प्रोजेक्ट के लिए ज़्यादा से ज़्यादा संसाधनों की ज़रूरत होती है, क्योंकि अनुमान लगाने की ज़रूरी क्वालिटी बढ़ती जाती है.
जनरेटिव एआई
जनरेटिव एआई के आउटपुट का विश्लेषण करते समय, इन बातों का ध्यान रखें:
-
तथ्यों का सही होना. जनरेटिव एआई मॉडल, आसानी से समझ में आने वाला और सिलसिलेवार कॉन्टेंट जनरेट कर सकते हैं. हालांकि, यह ज़रूरी नहीं है कि यह कॉन्टेंट तथ्यों के हिसाब से सही हो. जनरेटिव एआई मॉडल से मिलने वाले गलत जवाबों को फ़ैब्रिकेशन कहा जाता है.
उदाहरण के लिए, जनरेटिव एआई मॉडल, टेक्स्ट की गलत जानकारी दे सकते हैं. साथ ही, गणित के सवालों के गलत जवाब दे सकते हैं या दुनिया के बारे में गलत जानकारी दे सकते हैं. अब भी कई मामलों में, जनरेटिव एआई के आउटपुट की पुष्टि इंसान से करानी पड़ती है. इसके बाद ही, उसे प्रोडक्शन एनवायरमेंट में इस्तेमाल किया जा सकता है. उदाहरण के लिए, एलएलएम से जनरेट किया गया कोड.
पारंपरिक एमएल की तरह ही, तथ्यों के सटीक होने की ज़रूरत जितनी ज़्यादा होगी, उसे डेवलप और बनाए रखने की लागत उतनी ही ज़्यादा होगी.
- आउटपुट की क्वालिटी. पक्षपात करने वाले, साहित्यिक चोरी करने वाले या आपत्तिजनक कॉन्टेंट जैसे खराब आउटपुट के कानूनी और वित्तीय नतीजे (या नैतिक निहितार्थ) क्या हैं?
तकनीकी ज़रूरतें
मॉडल के लिए कई तकनीकी शर्तें होती हैं, जिनसे उनकी व्यवहार्यता पर असर पड़ता है. अपने प्रोजेक्ट की व्यवहार्यता का पता लगाने के लिए, आपको इन मुख्य तकनीकी ज़रूरी शर्तों को पूरा करना होगा:
- इंतज़ार का समय. लेटेंसी से जुड़ी ज़रूरी शर्तें क्या हैं? पूर्वानुमान कितनी तेज़ी से दिखाए जाने चाहिए?
- क्वेरी प्रति सेकंड (क्यूपीएस). क्यूपीएस से जुड़ी ज़रूरी शर्तें क्या हैं?
- रैम का इस्तेमाल. ट्रेनिंग और सर्विंग के लिए, रैम की क्या ज़रूरतें हैं?
- प्लैटफ़ॉर्म. मॉडल कहां चलेगा: ऑनलाइन (RPC सर्वर को भेजी गई क्वेरी), WebML (वेब ब्राउज़र में), ODML (फ़ोन या टैबलेट पर) या ऑफ़लाइन (टेबल में सेव किए गए अनुमान)?
व्याख्या करने की क्षमता. क्या अनुमानों को समझने लायक होना चाहिए? उदाहरण के लिए, क्या आपके प्रॉडक्ट को ऐसे सवालों के जवाब देने होंगे, "किसी कॉन्टेंट को स्पैम के तौर पर क्यों मार्क किया गया?" या "किसी वीडियो को प्लैटफ़ॉर्म की नीति का उल्लंघन करने वाला क्यों माना गया?"
फिर से ट्रेनिंग देने की फ़्रीक्वेंसी. अगर आपके मॉडल का मौजूदा डेटा तेज़ी से बदलता है, तो हो सकता है कि आपको उसे बार-बार या लगातार फिर से ट्रेन करना पड़े. हालांकि, बार-बार ट्रेनिंग देने से काफ़ी लागत लग सकती है. यह लागत, मॉडल की अनुमानित वैल्यू को अपडेट करने के फ़ायदों से ज़्यादा हो सकती है.
ज़्यादातर मामलों में, आपको मॉडल की क्वालिटी से समझौता करना पड़ सकता है, ताकि उसके तकनीकी स्पेसिफ़िकेशन का पालन किया जा सके. ऐसे मामलों में, आपको यह तय करना होगा कि क्या अब भी ऐसा मॉडल बनाया जा सकता है जो प्रोडक्शन के लिए काफ़ी अच्छा हो.
जनरेटिव एआई
जनरेटिव एआई का इस्तेमाल करते समय, इन तकनीकी शर्तों का ध्यान रखें:
- प्लैटफ़ॉर्म. पहले से ट्रेन किए गए कई मॉडल अलग-अलग साइज़ में उपलब्ध होते हैं. इससे उन्हें अलग-अलग कंप्यूटेशनल संसाधनों के साथ, अलग-अलग प्लैटफ़ॉर्म पर काम करने में मदद मिलती है. उदाहरण के लिए, पहले से ट्रेन किए गए मॉडल, डेटा सेंटर के हिसाब से बड़े हो सकते हैं या फ़ोन में फ़िट होने के हिसाब से छोटे हो सकते हैं. मॉडल का साइज़ चुनते समय, आपको अपने प्रॉडक्ट या सेवा की लेटेन्सी, निजता, और क्वालिटी से जुड़ी पाबंदियों का ध्यान रखना होगा. अक्सर इन शर्तों में टकराव हो सकता है. उदाहरण के लिए, निजता से जुड़ी पाबंदियों के तहत यह ज़रूरी हो सकता है कि अनुमान, उपयोगकर्ता के डिवाइस पर लगाए जाएं. हालांकि, आउटपुट की क्वालिटी खराब हो सकती है, क्योंकि डिवाइस में अच्छे नतीजे जनरेट करने के लिए कंप्यूटेशनल संसाधन नहीं हैं.
- इंतज़ार का समय. मॉडल के इनपुट और आउटपुट के साइज़ से लेटेन्सी पर असर पड़ता है. खास तौर पर, आउटपुट साइज़ का असर, इनपुट साइज़ की तुलना में लेटेन्सी पर ज़्यादा पड़ता है. मॉडल, अपने इनपुट को पैरलल कर सकते हैं. हालांकि, वे आउटपुट को सिर्फ़ क्रम से जनरेट कर सकते हैं. दूसरे शब्दों में, 500 शब्दों या 10 शब्दों वाले इनपुट को प्रोसेस करने में लगने वाला समय एक जैसा हो सकता है. हालांकि, 500 शब्दों वाली खास जानकारी जनरेट करने में, 10 शब्दों वाली खास जानकारी जनरेट करने की तुलना में ज़्यादा समय लगता है.
- टूल और एपीआई का इस्तेमाल. क्या मॉडल को किसी टास्क को पूरा करने के लिए, टूल और एपीआई का इस्तेमाल करना होगा? जैसे, इंटरनेट पर खोजना, कैलकुलेटर का इस्तेमाल करना या ईमेल क्लाइंट को ऐक्सेस करना? आम तौर पर, किसी टास्क को पूरा करने के लिए जितने ज़्यादा टूल की ज़रूरत होती है, उतनी ही ज़्यादा गड़बड़ियां होने की आशंका होती है. साथ ही, मॉडल की कमज़ोरियां भी बढ़ जाती हैं.
लागत
क्या एमएल को लागू करने में आने वाली लागत सही है? अगर एमएल समाधान को लागू करने और बनाए रखने में उतना खर्च आता है जितना वह जनरेट करता है (या बचाता है), तो ज़्यादातर एमएल प्रोजेक्ट को मंज़ूरी नहीं मिलेगी. मशीन लर्निंग प्रोजेक्ट में, इंसानों और मशीन, दोनों की लागत लगती है.
मानवीय लागत. प्रोजेक्ट को कॉन्सेप्ट के सबूत से प्रोडक्शन तक ले जाने के लिए, कितने लोगों की ज़रूरत होगी? एमएल प्रोजेक्ट के बढ़ने के साथ-साथ, आम तौर पर खर्च भी बढ़ता है. उदाहरण के लिए, एमएल प्रोजेक्ट के लिए, प्रोटोटाइप बनाने के मुकाबले प्रोडक्शन-रेडी सिस्टम को डिप्लॉय और बनाए रखने के लिए ज़्यादा लोगों की ज़रूरत होती है. यह अनुमान लगाने की कोशिश करें कि प्रोजेक्ट के हर चरण में, कितनी और किस तरह की भूमिकाओं की ज़रूरत होगी.
मशीन की लागत. मॉडल को ट्रेन करने, डिप्लॉय करने, और बनाए रखने के लिए, बहुत ज़्यादा कंप्यूटिंग और मेमोरी की ज़रूरत होती है. उदाहरण के लिए, आपको मॉडल को ट्रेन करने और अनुमान देने के लिए टीपीयू कोटे की ज़रूरत पड़ सकती है. साथ ही, आपको अपनी डेटा पाइपलाइन के लिए ज़रूरी इन्फ़्रास्ट्रक्चर की भी ज़रूरत पड़ सकती है. डेटा को लेबल करने या डेटा लाइसेंसिंग के लिए आपको शुल्क चुकाना पड़ सकता है. मॉडल को ट्रेन करने से पहले, मशीन लर्निंग की सुविधाओं को लंबे समय तक बनाने और बनाए रखने की लागत का अनुमान लगाएं.
अनुमान लगाने की लागत. क्या मॉडल को सैकड़ों या हज़ारों अनुमान लगाने होंगे, जिनकी लागत जनरेट हुए रेवेन्यू से ज़्यादा होगी?
ध्यान रखें
इनमें से किसी भी विषय से जुड़ी समस्याओं की वजह से, एमएल समाधान को लागू करना मुश्किल हो सकता है. हालांकि, समयसीमा कम होने से ये समस्याएं और बढ़ सकती हैं. समस्या की मुश्किल के हिसाब से, प्लान बनाने और बजट तय करने के लिए काफ़ी समय दें. इसके बाद, एमएल से जुड़े प्रोजेक्ट के लिए तय किए गए समय से ज़्यादा समय रिज़र्व करें.
देखें कि आपको कितना समझ आया
आपको प्रकृति संरक्षण के लिए काम करने वाली कंपनी में काम करना है. साथ ही, आपको कंपनी के पौधों की पहचान करने वाले सॉफ़्टवेयर को मैनेज करना है. आपको 60 तरह के इनवेसिव पौधों की प्रजातियों को क्लासिफ़ाई करने के लिए एक मॉडल बनाना है. इससे संरक्षणवादियों को, विलुप्त होने के खतरे का सामना कर रहे जानवरों के हैबिटैट को मैनेज करने में मदद मिलेगी.
आपको एक ऐसा सैंपल कोड मिला है जो पौधों की पहचान करने से जुड़ी समस्या को हल करता है. साथ ही, आपके समाधान को लागू करने की अनुमानित लागत, प्रोजेक्ट के बजट के अंदर है. डेटासेट में ट्रेनिंग के लिए कई उदाहरण मौजूद हैं. हालांकि, इसमें पांच सबसे ज़्यादा नुकसान पहुंचाने वाली प्रजातियों के लिए सिर्फ़ कुछ उदाहरण हैं. लीडरशिप को यह ज़रूरी नहीं लगता कि मॉडल के अनुमानों को समझा जा सके. साथ ही, ख़राब अनुमानों से जुड़े कोई भी बुरे नतीजे नहीं दिखते. क्या आपका एमएल समाधान लागू किया जा सकता है?