Pendant la phase d'idéation et de planification, vous examinez les éléments d'une solution de ML. Lors de la tâche de cadrage du problème, vous formulez un problème en termes de solution de ML. Le cours Introduction to Machine Learning Problem Framing (Introduction à la formulation des problèmes de machine learning) couvre ces étapes en détail. Lors de la tâche de planification, vous estimez la faisabilité d'une solution, planifiez les approches et définissez les métriques de réussite.
Bien que le ML puisse être une bonne solution théorique, vous devez tout de même estimer sa faisabilité dans le monde réel. Par exemple, une solution peut fonctionner techniquement, mais être impossible ou peu pratique à mettre en œuvre. Les facteurs suivants influencent la faisabilité d'un projet :
- Disponibilité des données
- Difficulté du problème
- Qualité de la prédiction
- Exigences techniques
- Coût
Disponibilité des données
L'efficacité des modèles de ML dépend des données sur lesquelles ils sont entraînés. Ils ont besoin de grandes quantités de données de haute qualité pour effectuer des prédictions de haute qualité. Répondre aux questions suivantes peut vous aider à déterminer si vous disposez des données nécessaires pour entraîner un modèle :
Quantité Pouvez-vous obtenir suffisamment de données de haute qualité pour entraîner un modèle ? Les exemples annotés sont-ils rares, difficiles à obtenir ou trop chers ? Par exemple, il est notoirement difficile d'obtenir des images médicales annotées ou des traductions de langues rares. Pour faire de bonnes prédictions, les modèles de classification nécessitent de nombreux exemples pour chaque libellé. Si l'ensemble de données d'entraînement contient un nombre limité d'exemples pour certains libellés, le modèle ne peut pas faire de bonnes prédictions.
Disponibilité des fonctionnalités au moment de la diffusion. Toutes les fonctionnalités utilisées lors de l'entraînement seront-elles disponibles au moment de la diffusion ? Les équipes ont passé beaucoup de temps à entraîner des modèles pour se rendre compte que certaines fonctionnalités n'étaient disponibles que plusieurs jours après que le modèle en avait besoin.
Par exemple, supposons qu'un modèle prédise si un client cliquera sur une URL et que l'une des caractéristiques utilisées dans l'entraînement inclut
user_age. Toutefois, lorsque le modèle fournit une prédiction,user_agen'est pas disponible, peut-être parce que l'utilisateur n'a pas encore créé de compte.Réglementations Quelles sont les réglementations et les exigences légales pour acquérir et utiliser les données ? Par exemple, certaines exigences fixent des limites pour le stockage et l'utilisation de certains types de données.
IA générative
Les modèles d'IA générative pré-entraînés nécessitent souvent des ensembles de données organisés pour exceller dans les tâches spécifiques à un domaine. Vous aurez peut-être besoin d'ensembles de données pour les cas d'utilisation suivants :
-
Ingénierie des prompts,
optimisation du réglage des paramètres et
affinage.
Selon le cas d'utilisation, vous aurez peut-être besoin de 10 à 10 000 exemples de haute qualité pour affiner davantage la sortie d'un modèle. Par exemple, si un modèle doit être affiné pour exceller dans une tâche particulière, comme répondre à des questions médicales, vous aurez besoin d'un ensemble de données de haute qualité qui soit représentatif des types de questions qui lui seront posées et des types de réponses qu'il devra fournir.
Le tableau suivant fournit des estimations du nombre d'exemples nécessaires pour affiner la sortie d'un modèle d'IA générative pour une technique donnée :
-
Informations à jour : Une fois pré-entraînés, les modèles d'IA générative disposent d'une base de connaissances fixe. Si le contenu du domaine du modèle change souvent, vous aurez besoin d'une stratégie pour le maintenir à jour, par exemple :
- affinage
- Génération augmentée par récupération (RAG)
- pré-entraînement périodique
| Technique | Nombre d'exemples requis |
|---|---|
| Prompt zero-shot | 0 |
| Prompt few-shot | ~10 s–100 s |
| Réglage des paramètres avec optimisation 1 | ~ 100 à 10 000 |
| Affinage | De quelques milliers à plusieurs dizaines de milliers (ou plus) |
Difficulté du problème
Il peut être difficile d'estimer la difficulté d'un problème. Ce qui semble être une approche plausible peut en fait s'avérer être une question de recherche ouverte. Ce qui semble pratique et réalisable peut s'avérer irréaliste ou impossible à mettre en œuvre. Les réponses aux questions suivantes peuvent vous aider à évaluer la difficulté d'un problème :
Un problème similaire a-t-il déjà été résolu ? Par exemple, les équipes de votre organisation ont-elles utilisé des données similaires (ou identiques) pour créer des modèles ? Des personnes ou des équipes externes à votre organisation ont-elles résolu des problèmes similaires, par exemple sur Kaggle ou TensorFlow Hub ? Si tel est le cas, vous pourrez probablement utiliser des parties de leur modèle pour créer le vôtre.
La nature du problème est-elle difficile ? Connaître les benchmarks humains pour la tâche peut vous aider à évaluer le niveau de difficulté du problème. Exemple :
- Les humains peuvent classer le type d'animal dans une image avec une précision d'environ 95 %.
- Les humains peuvent classer des chiffres écrits à la main avec une précision d'environ 99 %.
Les données précédentes suggèrent qu'il est plus difficile de créer un modèle pour classer les animaux que pour classer les chiffres manuscrits.
Existe-t-il des acteurs potentiellement malveillants ? Les utilisateurs vont-ils essayer d'exploiter activement votre modèle ? Si c'est le cas, vous devrez constamment vous efforcer de mettre à jour le modèle avant qu'il ne puisse être utilisé à mauvais escient. Par exemple, les filtres antispam ne peuvent pas détecter les nouveaux types de spam lorsqu'une personne exploite le modèle pour créer des e-mails qui semblent légitimes.
IA générative
Les modèles d'IA générative présentent des failles potentielles qui peuvent augmenter la difficulté d'un problème :
- Source d'entrée D'où proviendront les données d'entrée ? Les requêtes contradictoires peuvent-elles divulguer des données d'entraînement, des informations de préambule, du contenu de base de données ou des informations sur les outils ?
- Utilisation des résultats. Comment les sorties seront-elles utilisées ? Le modèle générera-t-il du contenu brut ou y aura-t-il des étapes intermédiaires pour tester et vérifier qu'il est approprié ? Par exemple, fournir des résultats bruts aux plug-ins peut entraîner un certain nombre de problèmes de sécurité.
- Affinage : L'affinage avec un ensemble de données corrompu peut avoir un impact négatif sur les pondérations du modèle. Cette corruption entraînerait la production de contenu incorrect, toxique ou biaisé par le modèle. Comme indiqué précédemment, le réglage fin nécessite un ensemble de données dont la qualité des exemples a été vérifiée.
Qualité de la prédiction
Vous devez examiner attentivement l'impact des prédictions d'un modèle sur vos utilisateurs et déterminer la qualité de prédiction nécessaire pour le modèle.
La qualité de prédiction requise dépend du type de prédiction. Par exemple, la qualité de prédiction requise pour un système de recommandation ne sera pas la même que pour un modèle qui signale les cas de non-respect des règles. Recommander la mauvaise vidéo peut nuire à l'expérience utilisateur. Toutefois, le signalement incorrect d'une vidéo comme enfreignant les règles d'une plate-forme peut générer des coûts d'assistance, voire des frais juridiques.
Votre modèle devra-t-il avoir une qualité de prédiction très élevée, car les prédictions incorrectes sont extrêmement coûteuses ? En général, plus la qualité de prédiction requise est élevée, plus le problème est difficile. Malheureusement, les projets atteignent souvent des rendements décroissants lorsque vous essayez d'améliorer la qualité. Par exemple, augmenter la précision d'un modèle de 99,9 % à 99,99 % peut multiplier le coût du projet par 10 (voire plus).
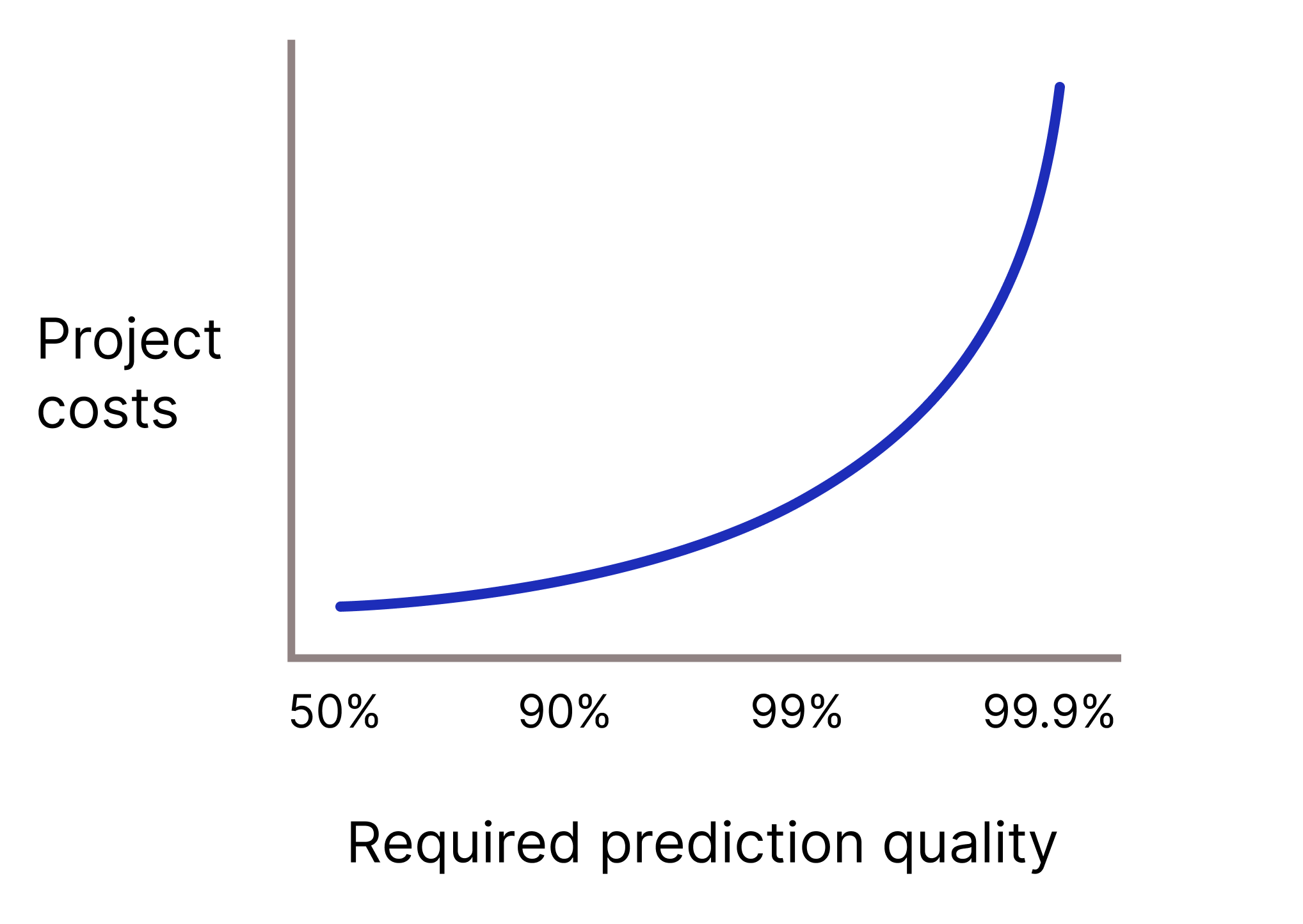
Figure 2 : Un projet de ML nécessite généralement de plus en plus de ressources à mesure que la qualité de prédiction requise augmente.
IA générative
Lorsque vous analysez les résultats de l'IA générative, tenez compte des points suivants :
-
Précision factuelle : Bien que les modèles d'IA générative puissent produire des contenus fluides et cohérents, ils ne sont pas garantis d'être factuels. Les fausses affirmations des modèles d'IA générative sont appelées confabulations.
Par exemple, les modèles d'IA générative peuvent confabuler et produire des résumés de texte incorrects, des réponses erronées à des questions de mathématiques ou des affirmations fausses sur le monde. De nombreux cas d'utilisation nécessitent encore une validation humaine des résultats de l'IA générative avant d'être utilisés dans un environnement de production (par exemple, le code généré par LLM).
Comme pour le ML traditionnel, plus l'exigence de précision factuelle est élevée, plus le coût de développement et de maintenance est élevé.
- Qualité des résultats. Quelles sont les conséquences juridiques et financières (ou les implications éthiques) de mauvais résultats, comme du contenu biaisé, plagié ou toxique ?
Exigences techniques
Les modèles sont soumis à un certain nombre d'exigences techniques qui ont un impact sur leur faisabilité. Voici les principales exigences techniques à prendre en compte pour déterminer la faisabilité de votre projet :
- Latence. Quelles sont les exigences de latence ? À quelle vitesse les prédictions doivent-elles être diffusées ?
- Requêtes par seconde (RPS) Quelles sont les exigences concernant les requêtes par seconde ?
- Utilisation de la RAM Quelles sont les exigences de RAM pour l'entraînement et le serving ?
- Plate-forme Où le modèle s'exécutera-t-il : en ligne (requêtes envoyées au serveur RPC), WebML (dans un navigateur Web), ODML (sur un téléphone ou une tablette) ou hors connexion (prédictions enregistrées dans un tableau) ?
Interprétabilité : Les prédictions devront-elles être interprétables ? Par exemple, votre produit devra-t-il répondre à des questions telles que "Pourquoi un contenu spécifique a-t-il été marqué comme spam ?" ou "Pourquoi une vidéo a-t-elle été jugée non conforme au règlement de la plate-forme ?"
Fréquence de réentraînement : Lorsque les données sous-jacentes de votre modèle changent rapidement, un réentraînement fréquent ou continu peut être nécessaire. Toutefois, un réentraînement fréquent peut entraîner des coûts importants qui peuvent dépasser les avantages de la mise à jour des prédictions du modèle.
Dans la plupart des cas, vous devrez probablement faire des compromis sur la qualité d'un modèle pour respecter ses spécifications techniques. Dans ce cas, vous devrez déterminer si vous pouvez toujours produire un modèle suffisamment performant pour être mis en production.
IA générative
Tenez compte des exigences techniques suivantes lorsque vous utilisez l'IA générative :
- Plate-forme De nombreux modèles pré-entraînés sont disponibles dans différentes tailles, ce qui leur permet de fonctionner sur diverses plates-formes avec différentes ressources de calcul. Par exemple, les modèles pré-entraînés peuvent aller de l'échelle d'un centre de données à celle d'un téléphone. Vous devrez tenir compte des contraintes de latence, de confidentialité et de qualité de votre produit ou service lorsque vous choisirez la taille d'un modèle. Ces contraintes peuvent souvent entrer en conflit. Par exemple, les contraintes de confidentialité peuvent exiger que les inférences s'exécutent sur l'appareil d'un utilisateur. Toutefois, la qualité de la sortie peut être médiocre, car l'appareil ne dispose pas des ressources de calcul nécessaires pour produire de bons résultats.
- Latence. La taille des entrées et des sorties du modèle affecte la latence. En particulier, la taille de la sortie affecte la latence plus que la taille de l'entrée. Bien que les modèles puissent paralléliser leurs entrées, ils ne peuvent générer des sorties que de manière séquentielle. En d'autres termes, la latence peut être la même pour ingérer une entrée de 500 mots ou de 10 mots, tandis que la génération d'un résumé de 500 mots prend beaucoup plus de temps que la génération d'un résumé de 10 mots.
- Utilisation de l'outil et de l'API Le modèle devra-t-il utiliser des outils et des API, comme effectuer une recherche sur Internet, utiliser une calculatrice ou accéder à un client de messagerie pour accomplir une tâche ? En règle générale, plus il faut d'outils pour accomplir une tâche, plus il y a de chances de propager des erreurs et d'accroître les vulnérabilités du modèle.
Coût
L'implémentation du ML vaudra-t-elle son coût ? La plupart des projets de ML ne seront pas approuvés si la solution de ML est plus coûteuse à implémenter et à maintenir que l'argent qu'elle génère (ou économise). Les projets de ML entraînent des coûts humains et machine.
Coûts humains : Combien de personnes seront nécessaires pour que le projet passe de la preuve de concept à la production ? À mesure que les projets de ML évoluent, les dépenses augmentent généralement. Par exemple, les projets de ML nécessitent plus de personnes pour déployer et gérer un système prêt pour la production que pour créer un prototype. Essayez d'estimer le nombre et les types de rôles dont le projet aura besoin à chaque phase.
Coûts des machines L'entraînement, le déploiement et la maintenance des modèles nécessitent beaucoup de puissance de calcul et de mémoire. Par exemple, vous pouvez avoir besoin d'un quota de TPU pour entraîner des modèles et diffuser des prédictions, ainsi que de l'infrastructure nécessaire pour votre pipeline de données. Vous devrez peut-être payer pour faire étiqueter vos données ou pour obtenir une licence de données. Avant d'entraîner un modèle, pensez à estimer les coûts machine pour la création et la maintenance des fonctionnalités de ML à long terme.
Coût de l'inférence : Le modèle devra-t-il effectuer des centaines ou des milliers d'inférences qui coûtent plus cher que les revenus générés ?
À retenir
Les problèmes liés à l'un des thèmes précédents peuvent rendre difficile l'implémentation d'une solution de ML, mais les délais serrés peuvent amplifier ces difficultés. Essayez de planifier et de budgétiser suffisamment de temps en fonction de la difficulté perçue du problème, puis essayez de réserver encore plus de temps que pour un projet non lié au ML.
Testez vos connaissances
Vous travaillez pour une entreprise de protection de la nature et vous gérez son logiciel d'identification des plantes. Vous souhaitez créer un modèle pour classer 60 types d'espèces végétales invasives afin d'aider les défenseurs de l'environnement à gérer les habitats des animaux en voie de disparition.
Vous avez trouvé un exemple de code qui résout un problème d'identification de plantes similaire, et les coûts estimés pour implémenter votre solution sont dans le budget du projet. Bien que l'ensemble de données comporte de nombreux exemples d'entraînement, il n'en contient que quelques-uns pour les cinq espèces les plus invasives. La direction n'exige pas que les prédictions du modèle soient interprétables, et il ne semble pas y avoir de conséquences négatives liées à de mauvaises prédictions. Votre solution de ML est-elle réalisable ?