Durante a fase de ideação e planejamento, você investiga os elementos de uma solução de ML. Durante a tarefa de definição do problema, você o define em termos de uma solução de ML. O curso Introdução à definição de problemas de aprendizado de máquina aborda essas etapas em detalhes. Durante a tarefa de planejamento, você estima a viabilidade de uma solução, planeja abordagens e define métricas de sucesso.
Embora o ML possa ser uma boa solução teórica, ainda é necessário estimar a viabilidade dele no mundo real. Por exemplo, uma solução pode funcionar tecnicamente, mas ser impraticável ou impossível de implementar. Os seguintes fatores influenciam a viabilidade de um projeto:
- Disponibilidade de dados
- Dificuldade do problema
- Qualidade da previsão
- Requisitos técnicos
- Custo
Disponibilidade de dados
A qualidade dos modelos de ML depende dos dados usados no treinamento deles. Eles precisam de muitos dados de alta qualidade para fazer previsões de alta qualidade. Responder às seguintes perguntas pode ajudar você a julgar se tem os dados necessários para treinar um modelo:
Quantidade. Você consegue dados de alta qualidade suficientes para treinar um modelo? Os exemplos rotulados são escassos, difíceis de conseguir ou muito caros? Por exemplo, é muito difícil conseguir imagens médicas rotuladas ou traduções de idiomas raros. Para fazer boas previsões, os modelos de classificação exigem vários exemplos para cada rótulo. Se o conjunto de dados de treinamento tiver poucos exemplos para alguns rótulos, o modelo não poderá fazer boas previsões.
Disponibilidade de recursos no momento da veiculação. Todos os recursos usados no treinamento estarão disponíveis no momento da veiculação? As equipes gastaram muito tempo treinando modelos apenas para perceber que alguns recursos não ficaram disponíveis até dias depois que o modelo precisou deles.
Por exemplo, suponha que um modelo preveja se um cliente vai clicar em um URL, e um dos recursos usados no treinamento inclua
user_age. No entanto, quando o modelo veicula uma previsão,user_agenão está disponível, talvez porque o usuário ainda não tenha criado uma conta.Regulamentações. Quais são as regulamentações e os requisitos legais para adquirir e usar os dados? Por exemplo, alguns requisitos definem limites para o armazenamento e uso de determinados tipos de dados.
IA generativa
Os modelos de IA generativa pré-treinados geralmente exigem conjuntos de dados selecionados para se destacar em tarefas específicas do domínio. Talvez você precise de conjuntos de dados para os seguintes casos de uso:
-
Engenharia de comando,
ajuste com eficiência de parâmetros e
ajuste fino.
Dependendo do caso de uso, talvez seja necessário ter entre 10 e 10.000 exemplos de alta qualidade para refinar ainda mais a saída de um modelo. Por exemplo, se um modelo precisar ser ajustado para se destacar em uma tarefa específica, como responder a perguntas médicas, você vai precisar de um conjunto de dados de alta qualidade que seja representativo dos tipos de perguntas que serão feitas e das respostas que ele deve dar.
A tabela a seguir fornece estimativas do número de exemplos necessários para refinar a saída de um modelo de IA generativa para uma determinada técnica:
-
Informações atualizadas. Depois de pré-treinados, os modelos de IA generativa têm uma base de conhecimento fixa. Se o conteúdo no domínio do modelo mudar com frequência, você vai precisar de uma estratégia para manter o modelo atualizado, como:
- ajuste de detalhes
- geração aumentada de recuperação (RAG)
- pré-treinamento periódico
| Técnica | Número de exemplos obrigatórios |
|---|---|
| Comandos zero-shot | 0 |
| Comandos de poucos disparos (few-shot) | ~10s–100s |
| Ajuste com eficiência de parâmetros 1 | ~100 a 10.000 |
| Ajuste de detalhes | ~1.000 a 10.000 (ou mais) |
Dificuldade do problema
A dificuldade de um problema pode ser difícil de estimar. O que parece ser uma abordagem plausível pode se tornar uma questão de pesquisa em aberto. O que parece prático e viável pode se tornar irrealista ou inviável. Responder às perguntas a seguir pode ajudar a avaliar a dificuldade de um problema:
Um problema semelhante já foi resolvido? Por exemplo, as equipes da sua organização usaram dados semelhantes (ou idênticos) para criar modelos? Pessoas ou equipes fora da sua organização já resolveram problemas semelhantes, por exemplo, no Kaggle ou no TensorFlow Hub? Se for o caso, é provável que você possa usar partes do modelo deles para criar o seu.
A natureza do problema é difícil? Conhecer os comparativos humanos para a tarefa pode informar o nível de dificuldade do problema. Exemplo:
- Os humanos podem classificar o tipo de animal em uma imagem com cerca de 95% de acurácia.
- Os humanos podem classificar dígitos manuscritos com uma precisão de cerca de 99%.
Os dados anteriores sugerem que criar um modelo para classificar animais é mais difícil do que criar um modelo para classificar dígitos manuscritos.
Há usuários de má-fé em potencial? As pessoas vão tentar ativamente explorar seu modelo? Nesse caso, você vai precisar atualizar o modelo constantemente antes que ele seja usado de forma indevida. Por exemplo, os filtros de spam não conseguem detectar novos tipos de spam quando alguém explora o modelo para criar e-mails que parecem legítimos.
IA generativa
Os modelos de IA generativa têm possíveis vulnerabilidades que podem aumentar a dificuldade de um problema:
- Origem da entrada. De onde virá a entrada? As solicitações adversárias podem vazar dados de treinamento, material de preâmbulo, conteúdo de banco de dados ou informações da ferramenta?
- Uso da saída. Como as saídas serão usadas? O modelo vai gerar conteúdo bruto ou haverá etapas intermediárias para testar e verificar se ele é adequado? Por exemplo, fornecer saída bruta para plug-ins pode causar vários problemas de segurança.
- Ajuste de detalhes. O ajuste fino com um conjunto de dados corrompido pode afetar negativamente os pesos do modelo. Essa corrupção faria com que o modelo gerasse conteúdo incorreto, tóxico ou tendencioso. Como observado anteriormente, o ajuste refinado exige um conjunto de dados que foi verificado para conter exemplos de alta qualidade.
Qualidade da previsão
É importante considerar cuidadosamente o impacto que as previsões de um modelo terão nos usuários e determinar a qualidade de previsão necessária para o modelo.
A qualidade de previsão necessária depende do tipo de previsão. Por exemplo, a qualidade de previsão necessária para um sistema de recomendação não é a mesma para um modelo que sinaliza violações da política. Recomendar o vídeo errado pode criar uma experiência ruim para o usuário. No entanto, sinalizar um vídeo incorretamente como violador das políticas de uma plataforma pode gerar custos de suporte ou, pior, taxas legais.
Seu modelo precisa ter uma qualidade de previsão muito alta porque previsões erradas são extremamente caras? Em geral, quanto maior a qualidade de previsão necessária, mais difícil é o problema. Infelizmente, os projetos costumam atingir retornos decrescentes à medida que você tenta melhorar a qualidade. Por exemplo, aumentar a precisão de um modelo de 99,9% para 99,99% pode significar um aumento de 10 vezes no custo do projeto (ou mais).
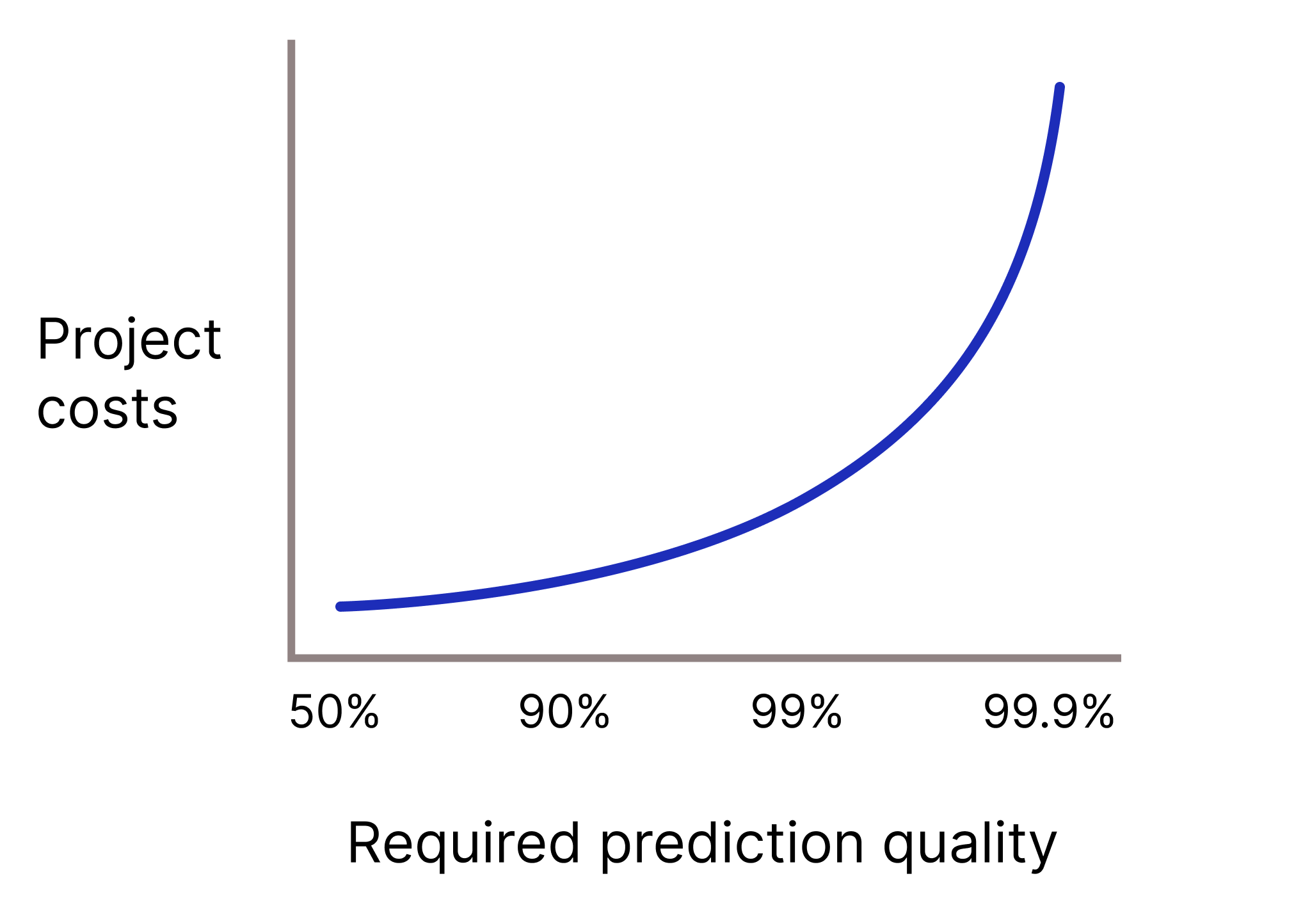
Figura 2. Um projeto de ML geralmente exige mais recursos à medida que a qualidade de previsão necessária aumenta.
IA generativa
Ao analisar a saída da IA generativa, considere o seguinte:
-
Precisão factual. Embora os modelos de IA generativa possam produzir conteúdo fluente e coerente, não há garantia de que ele seja factual. As declarações falsas de modelos de IA generativa são chamadas de confabulações.
Por exemplo, os modelos de IA generativa podem inventar e produzir
resumos incorretos de texto, respostas erradas para perguntas de matemática
ou declarações falsas sobre o mundo. Muitos casos de uso ainda exigem verificação humana da saída da IA generativa antes de serem usados em um ambiente de produção, por exemplo, código gerado por LLM.
Assim como no ML tradicional, quanto maior a necessidade de precisão factual, maior o custo de desenvolvimento e manutenção.
- Qualidade da saída. Quais são as consequências financeiras e jurídicas (ou implicações éticas) de saídas ruins, como conteúdo tendencioso, plagiado ou tóxico?
Requisitos técnicos
Os modelos têm vários requisitos técnicos que afetam a viabilidade deles. Estes são os principais requisitos técnicos que você precisa atender para determinar a viabilidade do seu projeto:
- Latência. Quais são os requisitos de latência? Com que rapidez as previsões precisam ser veiculadas?
- Consultas por segundo (QPS). Quais são os requisitos de QPS?
- Uso de RAM. Quais são os requisitos de RAM para treinamento e disponibilização?
- Plataforma. Onde o modelo será executado: on-line (consultas enviadas ao servidor RPC), WebML (em um navegador da Web), ODML (em um smartphone ou tablet) ou off-line (previsões salvas em uma tabela)?
Interpretabilidade. As previsões precisam ser interpretáveis? Por exemplo, seu produto vai precisar responder a perguntas como "Por que um conteúdo específico foi marcado como spam?" ou "Por que um vídeo foi considerado uma violação da política da plataforma?"
Frequência de retreinamento. Quando os dados subjacentes do modelo mudam rapidamente, pode ser necessário fazer um retreinamento frequente ou contínuo. No entanto, o retreinamento frequente pode gerar custos significativos que podem superar os benefícios de atualizar as previsões do modelo.
Na maioria dos casos, você provavelmente terá que comprometer a qualidade de um modelo para aderir às especificações técnicas dele. Nesses casos, você precisa determinar se ainda é possível produzir um modelo bom o suficiente para entrar em produção.
IA generativa
Considere os seguintes requisitos técnicos ao trabalhar com IA generativa:
- Plataforma. Muitos modelos pré-treinados vêm em vários tamanhos, permitindo que eles funcionem em diversas plataformas com diferentes recursos computacionais. Por exemplo, os modelos pré-treinados podem variar de escala de data center até caber em um smartphone. Ao escolher o tamanho de um modelo, considere as restrições de latência, privacidade e qualidade do seu produto ou serviço. Essas restrições podem entrar em conflito. Por exemplo, restrições de privacidade podem exigir que as inferências sejam executadas no dispositivo de um usuário. No entanto, a qualidade da saída pode ser ruim porque o dispositivo não tem os recursos computacionais necessários para produzir bons resultados.
- Latência. O tamanho da entrada e da saída do modelo afeta a latência. Em particular, o tamanho da saída afeta a latência mais do que o tamanho da entrada. Embora os modelos possam paralelizar as entradas, eles só podem gerar saídas sequencialmente. Em outras palavras, a latência pode ser a mesma para ingerir uma entrada de 500 ou 10 palavras, mas gerar um resumo de 500 palavras leva muito mais tempo do que gerar um resumo de 10 palavras.
- Uso de ferramentas e APIs O modelo vai precisar usar ferramentas e APIs, como pesquisar na Internet, usar uma calculadora ou acessar um cliente de e-mail para concluir uma tarefa? Normalmente, quanto mais ferramentas forem necessárias para concluir uma tarefa, mais chances haverá de propagar erros e aumentar as vulnerabilidades do modelo.
Custo
Uma implementação de ML vai valer a pena? A maioria dos projetos de ML não será aprovada se a solução de ML for mais cara de implementar e manter do que o dinheiro que ela gera (ou economiza). Os projetos de ML geram custos humanos e de máquina.
Custos humanos. Quantas pessoas serão necessárias para que o projeto passe da prova de conceito à produção? À medida que os projetos de ML evoluem, as despesas geralmente aumentam. Por exemplo, os projetos de ML exigem mais pessoas para implantar e manter um sistema pronto para produção do que para criar um protótipo. Tente estimar o número e os tipos de funções que o projeto vai precisar em cada fase.
Custos de máquina. O treinamento, a implantação e a manutenção de modelos exigem muita computação e memória. Por exemplo, talvez você precise de cota de TPU para treinar modelos e veicular previsões, além da infraestrutura necessária para seu pipeline de dados. Talvez seja necessário pagar para rotular dados ou pagar taxas de licenciamento de dados. Antes de treinar um modelo, estime os custos de máquina para criar e manter recursos de ML a longo prazo.
Custo de inferência. O modelo precisará fazer centenas ou milhares de inferências que custam mais do que a receita gerada?
Observação importante
Encontrar problemas relacionados a qualquer um dos tópicos anteriores pode dificultar a implementação de uma solução de ML, mas prazos apertados podem aumentar os desafios. Tente planejar e orçar tempo suficiente com base na dificuldade percebida do problema e reserve ainda mais tempo do que faria para um projeto que não é de ML.
Teste seu conhecimento
Você trabalha para uma empresa de preservação da natureza e gerencia o software de identificação de plantas da empresa. Você quer criar um modelo para classificar 60 tipos de espécies de plantas invasoras e ajudar os conservacionistas a gerenciar os habitats de animais em extinção.
Você encontrou um exemplo de código que resolve um problema semelhante de identificação de plantas, e os custos estimados para implementar sua solução estão dentro do orçamento do projeto. Embora o conjunto de dados tenha muitos exemplos de treinamento, ele tem apenas alguns para as cinco espécies mais invasivas. A liderança não exige que as previsões do modelo sejam interpretáveis, e não parece haver consequências negativas relacionadas a previsões ruins. Sua solução de ML é viável?