На этапе формирования идеи и планирования вы исследуете элементы решения на основе машинного обучения. В ходе формулирования проблемы вы формулируете проблему в терминах решения на основе машинного обучения. Курс «Введение в формулирование проблем в машинном обучении» подробно рассматривает эти этапы. В ходе планирования вы оцениваете осуществимость решения, разрабатываете подходы и устанавливаете метрики успеха.
Хотя машинное обучение теоретически может быть хорошим решением, вам всё равно необходимо оценить его практическую осуществимость. Например, решение может быть технически работоспособным, но непрактичным или невозможным для реализации. На осуществимость проекта влияют следующие факторы:
- Доступность данных
- Сложность проблемы
- Качество прогноза
- Технические требования
- Расходы
Доступность данных
Качество моделей машинного обучения напрямую зависит от качества данных, на которых они обучены. Для получения качественных прогнозов им требуется большой объём высококачественных данных. Ответы на следующие вопросы помогут вам оценить наличие необходимых данных для обучения модели:
Количество. Сможете ли вы получить достаточно качественных данных для обучения модели? Редко ли, сложно ли получить или слишком ли дорого размеченные примеры ? Например, получение размеченных медицинских изображений или переводов с редких языков — это, как известно, сложная задача. Для получения хороших прогнозов моделям классификации требуется множество примеров для каждой метки . Если обучающий набор данных содержит ограниченное количество примеров для некоторых меток, модель не сможет делать качественные прогнозы.
Доступность функций на момент подачи заявки. Будут ли все функции, использованные при обучении, доступны на момент подачи заявки? Команды потратили значительное количество времени на обучение моделей, но обнаружили, что некоторые функции стали доступны только через несколько дней после того, как они потребовались модели.
Например, предположим, что модель предсказывает, нажмёт ли пользователь на URL-адрес, и один из признаков, используемых при обучении, включает
user_age. Однако при составлении прогноза модельuser_ageнедоступна, возможно, потому что пользователь ещё не создал учётную запись.Правила. Каковы правила и юридические требования к получению и использованию данных? Например, некоторые правила устанавливают ограничения на хранение и использование определённых типов данных.
Генеративный ИИ
Предварительно обученные модели генеративного ИИ часто требуют тщательно подобранных наборов данных для эффективного решения задач, специфичных для конкретной предметной области. Наборы данных могут понадобиться вам в следующих случаях:
- Быстрая разработка , эффективная настройка параметров и тонкая настройка . В зависимости от варианта использования, для дальнейшего уточнения выходных данных модели может потребоваться от 10 до 10 000 высококачественных примеров. Например, если модель необходимо настроить для достижения наилучших результатов в решении конкретной задачи, например, для ответа на медицинские вопросы, вам потребуется высококачественный набор данных, репрезентативный для типов вопросов, которые ей будут задавать, и типов ответов, которые она должна давать.
В следующей таблице приведены оценки количества примеров, необходимых для уточнения выходных данных генеративной модели ИИ для заданной методики:
- Актуальная информация. После предобучения генеративные модели ИИ имеют фиксированную базу знаний. Если контент в предметной области модели часто меняется, вам потребуется стратегия для поддержания её актуальности, например:
- тонкая настройка
- генерация дополненной поисковой информации (RAG)
- периодическая предварительная подготовка
| Техника | Количество требуемых примеров |
|---|---|
| Подсказка для нулевого выстрела | 0 |
| Подсказка с несколькими кадрами | ~10–100 с |
| Эффективная настройка параметров 1 | ~100–10 000 с |
| Тонкая настройка | ~1000–10 000 с (или более) |
Сложность проблемы
Сложность проблемы бывает сложно оценить. То, что поначалу кажется правдоподобным подходом, может на самом деле оказаться открытым исследовательским вопросом; то, что кажется практичным и выполнимым, может оказаться нереалистичным или невыполнимым. Ответы на следующие вопросы помогут оценить сложность проблемы:
Была ли уже решена похожая проблема? Например, использовали ли команды в вашей организации похожие (или идентичные) данные для построения моделей? Решали ли подобные задачи другие люди или команды, например, в Kaggle или TensorFlow Hub ? Если да, то, вероятно, вы сможете использовать части их модели для построения своей.
Сложность проблемы? Знание человеческих возможностей для решения задачи может помочь определить её уровень сложности. Например:
- Люди могут классифицировать тип животного на изображении с точностью около 95%.
- Люди могут классифицировать рукописные цифры с точностью около 99%.
Приведенные выше данные свидетельствуют о том, что создание модели для классификации животных сложнее, чем создание модели для классификации рукописных цифр.
Есть ли потенциально недобросовестные пользователи? Будут ли люди активно пытаться использовать вашу модель в своих целях? Если да, вам придётся постоянно обновлять модель, чтобы предотвратить её несанкционированное использование. Например, спам-фильтры не смогут отлавливать новые виды спама, когда кто-то использует модель для создания писем, которые выглядят как настоящие.
Генеративный ИИ
Генеративные модели ИИ имеют потенциальные уязвимости, которые могут повысить сложность проблемы:
- Источник входных данных. Откуда будут поступать входные данные? Могут ли вредоносные подсказки привести к утечке обучающих данных, вводной части, содержимого базы данных или информации об инструментах?
- Использование выходных данных. Как будут использоваться выходные данные? Будет ли модель выводить необработанный контент или будут промежуточные этапы для проверки и подтверждения его пригодности? Например, предоставление необработанных выходных данных плагинам может вызвать ряд проблем безопасности.
- Тонкая настройка. Тонкая настройка с использованием повреждённого набора данных может негативно повлиять на весовые коэффициенты модели. Из-за этого модель может выдавать некорректный, токсичный или предвзятый контент. Как отмечалось ранее, для тонкой настройки требуется набор данных, который был проверен на наличие высококачественных примеров.
Качество прогноза
Вам необходимо тщательно продумать влияние прогнозов модели на ваших пользователей и определить необходимое качество прогнозов, требуемое для модели.
Требуемое качество прогнозирования зависит от типа прогноза. Например, качество прогнозирования, необходимое для рекомендательной системы, будет отличаться от качества прогнозирования модели, отмечающей нарушения правил. Рекомендация неподходящего видео может создать негативный пользовательский опыт. Однако ошибочное отметка видео как нарушающего правила платформы может привести к расходам на поддержку или, что ещё хуже, к судебным издержкам.
Должна ли ваша модель обладать очень высоким качеством прогнозирования, поскольку неверные прогнозы обходятся чрезвычайно дорого? Как правило, чем выше требуемое качество прогнозирования, тем сложнее задача. К сожалению, проекты часто теряют эффективность по мере повышения качества. Например, повышение точности модели с 99,9% до 99,99% может привести к десятикратному (если не больше) увеличению стоимости проекта.
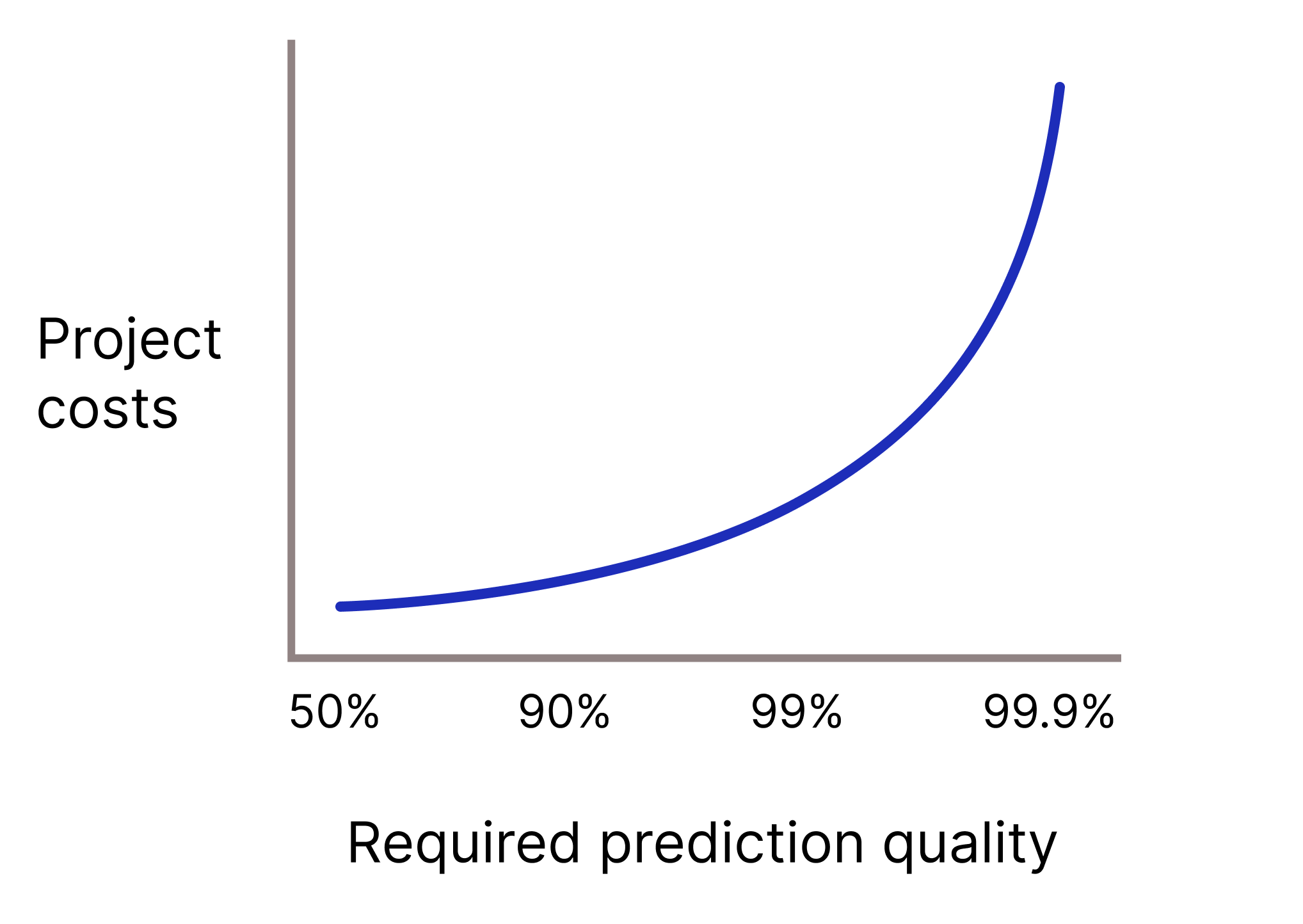
Рисунок 2. Проект машинного обучения обычно требует все больше ресурсов по мере повышения требуемого качества прогнозирования.
Генеративный ИИ
При анализе результатов генеративного ИИ необходимо учитывать следующее:
- Фактическая точность. Хотя генеративные модели ИИ могут создавать связный и связный контент, его достоверность не гарантируется. Ложные утверждения, создаваемые генеративными моделями ИИ, называются конфабуляциями . Например, генеративные модели ИИ могут создавать конфабуляцию и создавать неверные пересказы текста, неверные ответы на математические вопросы или ложные утверждения о мире. Во многих случаях использования по-прежнему требуется верификация результатов работы генеративного ИИ человеком перед их использованием в рабочей среде, например, кода, сгенерированного LLM.
Как и в традиционном МО, чем выше требования к фактической точности, тем выше затраты на разработку и поддержку.
- Качество продукции. Каковы юридические и финансовые последствия (или этические аспекты) некачественной продукции, например, предвзятого, плагиатного или токсичного контента?
Технические требования
Модели предъявляют ряд технических требований, влияющих на их осуществимость. Ниже перечислены основные технические требования, которые необходимо учитывать для определения осуществимости вашего проекта:
- Задержка. Каковы требования к задержке? Насколько быстро должны предоставляться прогнозы?
- Запросов в секунду (QPS). Каковы требования к QPS?
- Использование оперативной памяти. Каковы требования к объёму оперативной памяти для обучения и обслуживания?
- Платформа. Где будет работать модель: онлайн (запросы отправляются на RPC-сервер), WebML (в веб-браузере), ODML (на телефоне или планшете) или офлайн (прогнозы сохраняются в таблице)?
Интерпретируемость. Должны ли прогнозы быть интерпретируемыми ? Например, должен ли ваш продукт отвечать на такие вопросы, как: «Почему определённый контент был отмечен как спам?» или «Почему видео было определено как нарушающее политику платформы?»
Частота переобучения . При быстром изменении базовых данных модели может потребоваться частое или непрерывное переобучение. Однако частое переобучение может привести к значительным затратам, которые могут перевесить выгоды от обновления прогнозов модели.
В большинстве случаев вам, вероятно, придётся пойти на компромисс в отношении качества модели, чтобы соответствовать её техническим характеристикам. В таких случаях вам нужно будет определить, сможете ли вы всё ещё производить модель, достаточно хорошую для запуска в производство.
Генеративный ИИ
При работе с генеративным ИИ учитывайте следующие технические требования:
- Платформа. Многие предобученные модели доступны в различных размерах, что позволяет им работать на различных платформах с различными вычислительными ресурсами. Например, предобученные модели могут быть масштабированы как до уровня центра обработки данных, так и поместиться на телефоне. При выборе размера модели необходимо учитывать ограничения по задержке, конфиденциальности и качеству вашего продукта или услуги. Эти ограничения часто могут противоречить друг другу. Например, ограничения конфиденциальности могут требовать, чтобы выводы выполнялись на устройстве пользователя. Однако качество выходных данных может быть низким из-за нехватки вычислительных ресурсов устройства для получения хороших результатов.
- Задержка. Размер входных и выходных данных модели влияет на задержку. В частности, размер выходных данных влияет на задержку сильнее, чем размер входных данных. Хотя модели могут распараллеливать входные данные, они могут генерировать выходные данные только последовательно. Другими словами, задержка может быть одинаковой для обработки входных данных из 500 и 10 слов, в то время как создание резюме из 500 слов занимает значительно больше времени, чем создание резюме из 10 слов.
- Использование инструментов и API. Потребуются ли модели инструменты и API, например, поиск в интернете, использование калькулятора или доступ к почтовому клиенту для выполнения задачи? Как правило, чем больше инструментов требуется для выполнения задачи, тем выше вероятность распространения ошибок и повышения уязвимости модели.
Расходы
Оправдает ли внедрение МО свои затраты? Большинство проектов МО не будут одобрены, если внедрение и поддержка решения МО обходятся дороже, чем получаемые (или экономимые) от него деньги. Проекты МО требуют как человеческих, так и технических затрат.
Человеческие затраты. Сколько человек потребуется для перехода проекта от стадии проверки концепции к стадии производства? По мере развития проектов МО расходы обычно растут. Например, для развёртывания и поддержки готовой к производству системы требуется больше людей, чем для создания прототипа. Попробуйте оценить количество и типы ролей, которые потребуются проекту на каждом этапе.
Стоимость оборудования. Обучение, развёртывание и поддержка моделей требуют значительных вычислительных ресурсов и памяти. Например, вам может потребоваться квота TPU для обучения моделей и обслуживания прогнозов, а также необходимая инфраструктура для конвейера данных. Возможно, вам придётся платить за разметку данных или лицензионные сборы. Перед обучением модели рассмотрите возможность оценки стоимости оборудования для создания и поддержки функций машинного обучения в долгосрочной перспективе.
Стоимость вывода. Потребуется ли модели делать сотни или тысячи выводов , стоимость которых превысит полученный доход?
Иметь в виду
Возникновение проблем, связанных с любой из предыдущих тем, может усложнить реализацию решения на основе машинного обучения, а сжатые сроки могут усугубить трудности. Постарайтесь запланировать и выделить достаточно времени, исходя из предполагаемой сложности проблемы, а затем постарайтесь зарезервировать даже больше времени на дополнительные расходы, чем на проект без машинного обучения.
Проверьте свое понимание
Вы работаете в природоохранной компании и управляете её программным обеспечением для идентификации растений. Вы хотите создать модель для классификации 60 видов инвазивных растений, чтобы помочь специалистам по охране природы управлять местообитаниями исчезающих видов животных.
Вы нашли пример кода, решающего похожую задачу идентификации растений, и предполагаемая стоимость внедрения вашего решения укладывается в бюджет проекта. Хотя в наборе данных много обучающих примеров, для пяти наиболее инвазивных видов их всего несколько. Руководство не требует, чтобы прогнозы модели были интерпретируемыми, и, по всей видимости, неверные прогнозы не приводят к негативным последствиям. Реализуемо ли ваше решение на основе машинного обучения?