In der Phase der Ideenentwicklung und Planung untersuchen Sie die Elemente einer ML-Lösung. Beim Problem-Framing formulieren Sie ein Problem im Hinblick auf eine ML-Lösung. Im Kurs Einführung in die Problemformulierung für maschinelles Lernen werden diese Schritte ausführlich behandelt. Bei der Planungsaufgabe schätzen Sie die Machbarkeit einer Lösung, planen Ansätze und legen Erfolgsmesswerte fest.
Auch wenn ML theoretisch eine gute Lösung sein mag, müssen Sie ihre Machbarkeit in der Praxis abschätzen. Eine Lösung kann beispielsweise technisch funktionieren, aber unpraktisch oder unmöglich umzusetzen sein. Die folgenden Faktoren beeinflussen die Machbarkeit eines Projekts:
- Datenverfügbarkeit
- Schwierigkeitsgrad des Problems
- Qualität der Vorhersage
- Technische Anforderungen
- Kosten
Datenverfügbarkeit
ML-Modelle sind nur so gut wie die Daten, mit denen sie trainiert werden. Sie benötigen viele hochwertige Daten, um qualitativ hochwertige Vorhersagen zu treffen. Wenn Sie die folgenden Fragen beantworten, können Sie besser beurteilen, ob Sie die erforderlichen Daten zum Trainieren eines Modells haben:
Menge: Können Sie genügend hochwertige Daten für das Training eines Modells erhalten? Sind beispielhafte Daten mit Labels rar, schwer zu beschaffen oder zu teuer? So ist es beispielsweise notorisch schwierig, gekennzeichnete medizinische Bilder oder Übersetzungen seltener Sprachen zu erhalten. Um gute Vorhersagen zu treffen, benötigen Klassifizierungsmodelle zahlreiche Beispiele für jedes Label. Wenn das Trainingsdataset nur wenige Beispiele für einige Labels enthält, kann das Modell keine guten Vorhersagen treffen.
Verfügbarkeit von Funktionen zum Zeitpunkt der Bereitstellung: Sind alle Funktionen, die beim Training verwendet wurden, auch bei der Bereitstellung verfügbar? Teams haben viel Zeit mit dem Trainieren von Modellen verbracht, nur um festzustellen, dass einige Funktionen erst Tage nach dem Zeitpunkt verfügbar wurden, an dem das Modell sie benötigte.
Angenommen, ein Modell sagt voraus, ob ein Kunde auf eine URL klickt, und eines der für das Training verwendeten Features ist
user_age. Wenn das Modell jedoch eine Vorhersage liefert, istuser_agenicht verfügbar, möglicherweise weil der Nutzer noch kein Konto erstellt hat.Bestimmungen Welche Vorschriften und rechtlichen Anforderungen gelten für die Erhebung und Nutzung der Daten? Einige Anforderungen legen beispielsweise Grenzen für die Speicherung und Verwendung bestimmter Datentypen fest.
Generative KI
Vortrainierte generative KI-Modelle erfordern oft kuratierte Datasets, um domänenspezifische Aufgaben zu bewältigen. Möglicherweise benötigen Sie Datasets für die folgenden Anwendungsfälle:
-
Prompt Engineering,
parametereffiziente Abstimmung und
Fine-Tuning.
Je nach Anwendungsfall benötigen Sie möglicherweise zwischen 10 und 10.000 hochwertige Beispiele, um die Ausgabe eines Modells weiter zu optimieren. Wenn ein Modell beispielsweise für eine bestimmte Aufgabe wie das Beantworten medizinischer Fragen optimiert werden muss, benötigen Sie einen hochwertigen Datensatz, der repräsentativ für die Arten von Fragen ist, die ihm gestellt werden, sowie für die Arten von Antworten, die es geben soll.
In der folgenden Tabelle finden Sie Schätzungen für die Anzahl der Beispiele, die erforderlich sind, um die Ausgabe eines generativen KI-Modells für eine bestimmte Technik zu optimieren:
-
Aktuelle Informationen Nach dem Vortraining haben generative KI-Modelle eine feste Wissensbasis. Wenn sich Inhalte in der Domäne des Modells häufig ändern, benötigen Sie eine Strategie, um das Modell auf dem neuesten Stand zu halten, z. B.:
- Abstimmung
- Retrieval-Augmented Generation (RAG)
- Regelmäßiges Vortraining
| Verfahren | Anzahl der erforderlichen Beispiele |
|---|---|
| Zero-Shot-Prompting | 0 |
| Few-Shot-Prompting | ~10–100 Sekunden |
| Parametereffiziente Abstimmung 1 | ~100 bis 10.000 |
| Abstimmung | ~1.000 bis 10.000 (oder mehr) |
Schwierigkeitsgrad des Problems
Der Schwierigkeitsgrad eines Problems lässt sich nur schwer einschätzen. Was anfangs als plausibler Ansatz erscheint, kann sich als offene Forschungsfrage herausstellen. Was praktisch und machbar erscheint, kann sich als unrealistisch oder undurchführbar erweisen. Anhand der folgenden Fragen können Sie den Schwierigkeitsgrad eines Problems einschätzen:
Wurde ein ähnliches Problem bereits gelöst? Haben Teams in Ihrer Organisation beispielsweise ähnliche oder identische Daten zum Erstellen von Modellen verwendet? Haben Personen oder Teams außerhalb Ihrer Organisation ähnliche Probleme gelöst, z. B. auf Kaggle oder im TensorFlow Hub? In diesem Fall können Sie wahrscheinlich Teile des Modells verwenden, um Ihr eigenes zu erstellen.
Ist das Problem schwierig? Wenn Sie die menschlichen Benchmarks für die Aufgabe kennen, können Sie den Schwierigkeitsgrad des Problems besser einschätzen. Beispiel:
- Menschen können die Art des Tieres auf einem Bild mit einer Genauigkeit von etwa 95% klassifizieren.
- Menschen können handschriftliche Ziffern mit einer Genauigkeit von etwa 99% klassifizieren.
Die vorherigen Daten deuten darauf hin, dass das Erstellen eines Modells zur Klassifizierung von Tieren schwieriger ist als das Erstellen eines Modells zur Klassifizierung handschriftlicher Ziffern.
Gibt es potenzielle böswillige Akteure? Werden Personen aktiv versuchen, Ihr Modell auszunutzen? In diesem Fall müssen Sie das Modell ständig aktualisieren, bevor es missbraucht werden kann. Spamfilter können beispielsweise neue Arten von Spam nicht erkennen, wenn jemand das Modell nutzt, um E‑Mails zu erstellen, die legitim aussehen.
Generative KI
Generative KI-Modelle haben potenzielle Schwachstellen, die die Schwierigkeit eines Problems erhöhen können:
- Eingabequelle: Woher kommen die Eingaben? Können durch feindselige Prompts Trainingsdaten, Präambelmaterial, Datenbankinhalte oder Toolinformationen offengelegt werden?
- Verwendung der Ausgabe: Wie werden die Ausgaben verwendet? Gibt das Modell Rohinhalte aus oder gibt es Zwischenschritte, in denen geprüft und bestätigt wird, dass die Inhalte angemessen sind? Wenn Sie beispielsweise Rohausgabe an Plugins weitergeben, kann dies eine Reihe von Sicherheitsproblemen verursachen.
- Optimierung: Das Fine-Tuning mit einem beschädigten Dataset kann sich negativ auf die Gewichte des Modells auswirken. Diese Beschädigung würde dazu führen, dass das Modell falsche, schädliche oder voreingenommene Inhalte ausgibt. Wie bereits erwähnt, ist für das Fine-Tuning ein Dataset erforderlich, das hochwertige Beispiele enthält.
Qualität der Vorhersage
Sie sollten sorgfältig abwägen, welche Auswirkungen die Vorhersagen eines Modells auf Ihre Nutzer haben, und die erforderliche Vorhersagequalität für das Modell festlegen.
Die erforderliche Vorhersagequalität hängt vom Typ der Vorhersage ab. Die für ein Empfehlungssystem erforderliche Vorhersagequalität ist beispielsweise nicht dieselbe wie für ein Modell, das Richtlinienverstöße kennzeichnet. Wenn das falsche Video empfohlen wird, kann das zu einer schlechten Nutzererfahrung führen. Wenn ein Video jedoch fälschlicherweise als Verstoß gegen die Richtlinien einer Plattform gekennzeichnet wird, können Supportkosten oder schlimmstenfalls Anwaltskosten entstehen.
Muss Ihr Modell eine sehr hohe Vorhersagequalität haben, weil falsche Vorhersagen extrem kostspielig sind? Je höher die erforderliche Vorhersagequalität, desto schwieriger ist das Problem. Leider erreichen Projekte oft einen Punkt, an dem sich die Qualität nicht mehr steigern lässt. Wenn Sie beispielsweise die Präzision eines Modells von 99,9% auf 99,99% erhöhen, können sich die Kosten des Projekts verzehnfachen (oder sogar noch mehr).
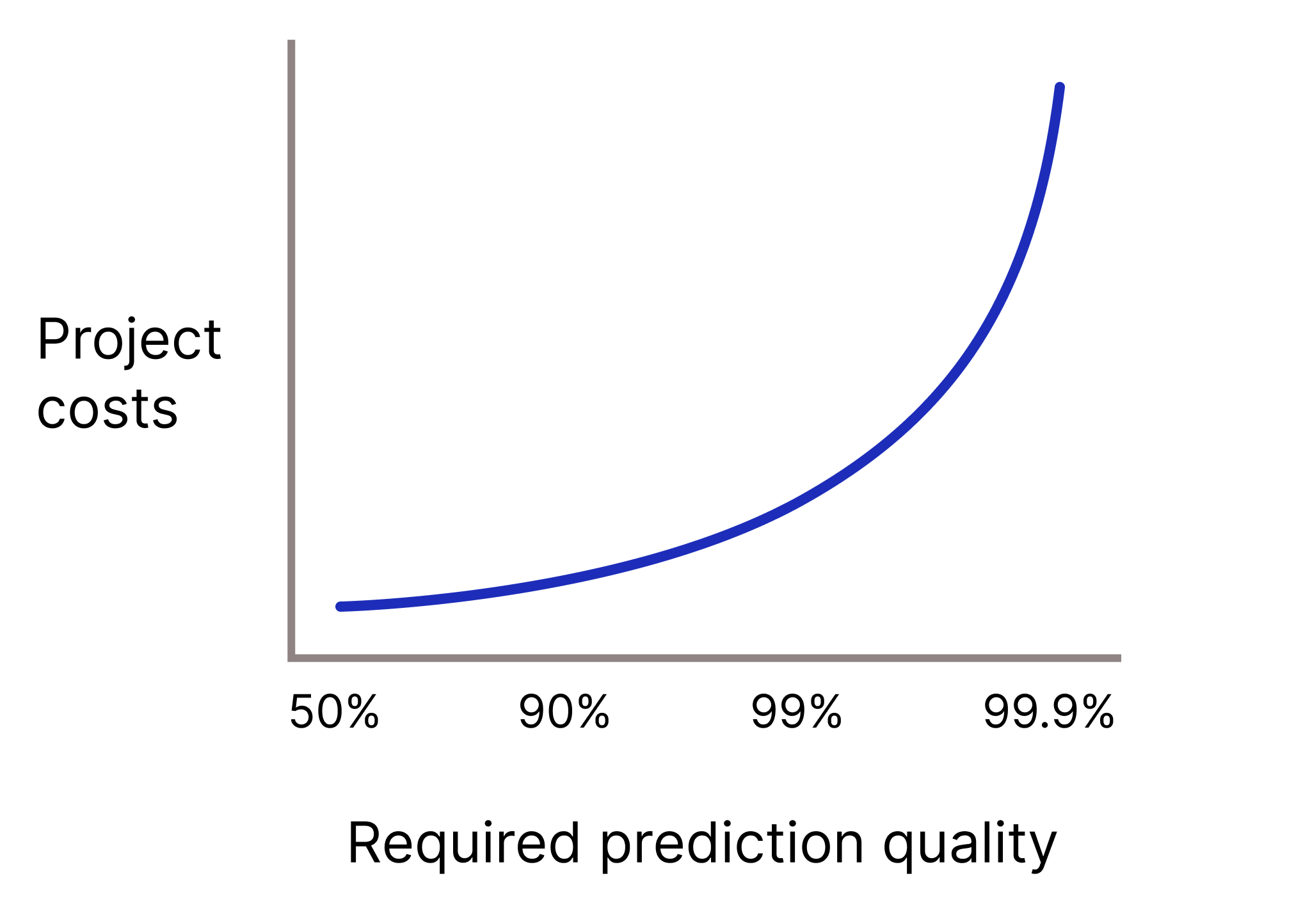
Abbildung 2. Für ein ML-Projekt sind in der Regel mehr und mehr Ressourcen erforderlich, je höher die erforderliche Vorhersagequalität ist.
Generative KI
Berücksichtigen Sie bei der Analyse von generativer KI-Ausgabe Folgendes:
-
Sachliche Richtigkeit: Generative KI-Modelle können zwar flüssige und kohärente Inhalte erstellen, aber es wird nicht garantiert, dass diese faktisch korrekt sind. Falsche Aussagen von Modellen der generativen KI werden als Konfabulationen bezeichnet.
Generative KI-Modelle können beispielsweise falsche Zusammenfassungen von Texten, falsche Antworten auf mathematische Fragen oder falsche Aussagen über die Welt liefern. Bei vielen Anwendungsfällen ist weiterhin eine manuelle Überprüfung der generativen KI-Ausgabe erforderlich, bevor sie in einer Produktionsumgebung verwendet werden kann, z. B. bei LLM-generiertem Code.
Wie beim herkömmlichen maschinellen Lernen gilt: Je höher die Anforderungen an die sachliche Richtigkeit, desto höher die Kosten für Entwicklung und Wartung.
- Qualität der Ausgabe: Welche rechtlichen und finanziellen Folgen (oder ethischen Auswirkungen) hat es, wenn die KI schlechte Ergebnisse liefert, z. B. voreingenommene, plagiierte oder schädliche Inhalte?
Technische Anforderungen
Für Modelle gelten eine Reihe technischer Anforderungen, die sich auf ihre Machbarkeit auswirken. Dies sind die wichtigsten technischen Anforderungen, die Sie berücksichtigen müssen, um die Machbarkeit Ihres Projekts zu ermitteln:
- Latenz: Welche Latenzanforderungen gelten? Wie schnell müssen Vorhersagen bereitgestellt werden?
- Abfragen pro Sekunde (Queries per Second, QPS) Welche Anforderungen gelten für QPS?
- RAM-Nutzung: Welche RAM-Anforderungen gelten für Training und Bereitstellung?
- Plattform: Wo wird das Modell ausgeführt: online (Anfragen an den RPC-Server gesendet), WebML (in einem Webbrowser), ODML (auf einem Smartphone oder Tablet) oder offline (Vorhersagen in einer Tabelle gespeichert)?
Interpretierbarkeit: Müssen Vorhersagen interpretierbar sein? Muss Ihr Produkt beispielsweise Fragen wie „Warum wurde ein bestimmter Inhalt als Spam markiert?“ oder „Warum wurde ein Video als Verstoß gegen die Richtlinien der Plattform eingestuft?“ beantworten?
Häufigkeit des erneuten Trainings: Wenn sich die zugrunde liegenden Daten für Ihr Modell schnell ändern, kann ein häufiges oder kontinuierliches erneutes Training erforderlich sein. Häufiges Trainieren kann jedoch zu erheblichen Kosten führen, die die Vorteile der Aktualisierung der Modellvorhersagen überwiegen können.
In den meisten Fällen müssen Sie wahrscheinlich Kompromisse bei der Qualität eines Modells eingehen, um die technischen Spezifikationen einzuhalten. In diesen Fällen müssen Sie entscheiden, ob Sie trotzdem ein Modell erstellen können, das für die Produktion geeignet ist.
Generative KI
Beachten Sie die folgenden technischen Anforderungen, wenn Sie generative KI verwenden:
- Plattform: Viele vortrainierte Modelle sind in verschiedenen Größen verfügbar, sodass sie auf einer Vielzahl von Plattformen mit unterschiedlichen Rechenressourcen eingesetzt werden können. Vortrainierte Modelle können beispielsweise von Rechenzentrumsskala bis hin zu einem Smartphone reichen. Bei der Auswahl einer Modellgröße müssen Sie die Latenz-, Datenschutz- und Qualitätsbeschränkungen Ihres Produkts oder Ihrer Dienstleistung berücksichtigen. Diese Einschränkungen können oft in Konflikt geraten. Datenschutzbeschränkungen können beispielsweise erfordern, dass Inferenzvorgänge auf dem Gerät eines Nutzers ausgeführt werden. Die Ausgabequalität ist jedoch möglicherweise schlecht, da dem Gerät die Rechenressourcen fehlen, um gute Ergebnisse zu erzielen.
- Latenz: Die Größe der Modelleingabe und ‑ausgabe wirkt sich auf die Latenz aus. Insbesondere wirkt sich die Ausgabegröße stärker auf die Latenz aus als die Eingabegröße. Modelle können ihre Eingaben zwar parallelisieren, aber Ausgaben nur sequenziell generieren. Mit anderen Worten: Die Latenz kann für die Aufnahme einer Eingabe mit 500 Wörtern oder 10 Wörtern gleich sein, während die Generierung einer Zusammenfassung mit 500 Wörtern wesentlich länger dauert als die Generierung einer Zusammenfassung mit 10 Wörtern.
- Tool- und API-Nutzung Muss das Modell Tools und APIs verwenden, z. B. das Internet durchsuchen, einen Taschenrechner verwenden oder auf einen E‑Mail-Client zugreifen, um eine Aufgabe zu erledigen? Je mehr Tools für die Ausführung einer Aufgabe erforderlich sind, desto größer ist die Wahrscheinlichkeit, dass Fehler weitergegeben werden und die Anfälligkeit des Modells zunimmt.
Kosten
Lohnt sich eine ML-Implementierung? Die meisten ML-Projekte werden nicht genehmigt, wenn die Implementierung und Wartung der ML-Lösung teurer ist als das Geld, das sie generiert oder spart. Für ML-Projekte fallen sowohl Kosten für Personal als auch für Maschinen an.
Personalkosten: Wie viele Personen sind erforderlich, um das Projekt vom Proof of Concept bis zur Produktion zu bringen? Im Laufe der Entwicklung von ML-Projekten steigen die Ausgaben in der Regel. Für ML-Projekte sind beispielsweise mehr Personen erforderlich, um ein produktionsreifes System bereitzustellen und zu warten, als um einen Prototyp zu erstellen. Schätzen Sie die Anzahl und Art der Rollen, die für das Projekt in jeder Phase erforderlich sind.
Maschinenkosten Für das Trainieren, Bereitstellen und Warten von Modellen sind viele Rechen- und Speicherressourcen erforderlich. Möglicherweise benötigen Sie beispielsweise TPU-Kontingent für das Trainieren von Modellen und die Bereitstellung von Vorhersagen sowie die erforderliche Infrastruktur für Ihre Datenpipeline. Möglicherweise müssen Sie für die Kennzeichnung von Daten oder für die Lizenzierung von Daten bezahlen. Bevor Sie ein Modell trainieren, sollten Sie die Kosten für die Erstellung und langfristige Wartung von ML-Funktionen schätzen.
Inferenzkosten. Muss das Modell Hunderte oder Tausende von Inferenzvorgängen durchführen, die mehr kosten als der generierte Umsatz?
Hinweis
Probleme in Bezug auf eines der oben genannten Themen können die Implementierung einer ML-Lösung erschweren. Enge Fristen können diese Herausforderungen noch verstärken. Planen Sie ausreichend Zeit ein, basierend auf der wahrgenommenen Schwierigkeit des Problems, und reservieren Sie dann noch mehr Zeit als für ein Projekt ohne ML.
Wissen testen
Sie arbeiten für ein Naturschutzunternehmen und verwalten die Software des Unternehmens zur Pflanzenidentifizierung. Sie möchten ein Modell erstellen, mit dem 60 Arten invasiver Pflanzen klassifiziert werden können, um Umweltschützern bei der Verwaltung der Lebensräume gefährdeter Tiere zu helfen.
Sie haben Beispielcode gefunden, mit dem ein ähnliches Problem bei der Pflanzenbestimmung gelöst werden kann, und die geschätzten Kosten für die Implementierung Ihrer Lösung liegen innerhalb des Projektbudgets. Das Dataset enthält zwar viele Trainingsbeispiele, aber nur wenige für die fünf invasivsten Arten. Die Führungsebene verlangt nicht, dass die Vorhersagen des Modells interpretierbar sind, und es scheint keine negativen Folgen im Zusammenhang mit schlechten Vorhersagen zu geben. Ist Ihre ML-Lösung umsetzbar?