בשלב של יצירת רעיונות ותכנון, בודקים את האלמנטים של פתרון למידת מכונה. במהלך המשימה של הגדרת הבעיה, מגדירים בעיה במונחים של פתרון ML. השלבים האלה מוסברים בפירוט בקורס מבוא להגדרת בעיות בלמידת מכונה. במהלך משימת התכנון, מעריכים את היתכנות הפתרון, מתכננים גישות ומגדירים מדדי הצלחה.
יכול להיות שלמידת מכונה היא פתרון טוב מבחינה תיאורטית, אבל עדיין צריך להעריך את ההיתכנות שלה בעולם האמיתי. לדוגמה, יכול להיות שפתרון מסוים יעבוד מבחינה טכנית, אבל יהיה לא פרקטי או בלתי אפשרי ליישום. הגורמים הבאים משפיעים על הכדאיות של פרויקט:
- זמינות הנתונים
- רמת הקושי של הבעיה
- איכות החיזוי
- דרישות טכניות
- עלות
זמינות הנתונים
איכות התוצאות של מודלים של למידת מכונה תלויה באיכות הנתונים שמזינים. כדי לספק תחזיות באיכות גבוהה, הם צריכים הרבה נתונים באיכות גבוהה. התשובות לשאלות הבאות יעזרו לכם להעריך אם יש לכם את הנתונים הדרושים לאימון מודל:
כמות. האם אפשר להשיג מספיק נתונים באיכות גבוהה כדי לאמן מודל? האם יש מעט דוגמאות עם תוויות, קשה להשיג אותן או שהן יקרות מדי? לדוגמה, קשה מאוד לקבל תמונות רפואיות מתויגות או תרגומים של שפות נדירות. כדי ליצור חיזויים טובים, מודלים של סיווג צריכים דוגמאות רבות לכל תווית. אם מערך הנתונים לאימון מכיל דוגמאות מוגבלות לחלק מהתוויות, המודל לא יוכל לספק תחזיות טובות.
זמינות התכונות בזמן הצגת המודעות האם כל התכונות שנעשה בהן שימוש באימון יהיו זמינות בזמן ההצגה? צוותים השקיעו זמן רב באימון מודלים, ורק לאחר מכן הבינו שחלק מהתכונות לא זמינות עד כמה ימים אחרי שהמודל נזקק להן.
לדוגמה, נניח שמודל מנבא אם לקוח ילחץ על כתובת URL, ואחת מהתכונות שמשמשות לאימון כוללת את
user_age. עם זאת, כשהמודל מציג תחזית,user_ageלא זמין, אולי כי המשתמש עדיין לא יצר חשבון.תקנות. מהן התקנות והדרישות המשפטיות לאיסוף הנתונים ולשימוש בהם? לדוגמה, חלק מהדרישות מגבילות את האחסון והשימוש בסוגים מסוימים של נתונים.
AI גנרטיבי
מודלים של AI גנרטיבי שעברו אימון מראש דורשים לעיתים קרובות מערכי נתונים שנאספו בקפידה כדי להצטיין במשימות ספציפיות לתחום. יכול להיות שתצטרכו מערכי נתונים בתרחישי השימוש הבאים:
-
הנדסת הנחיות,
כוונון יעיל בפרמטרים ו
כוונון עדין.
בהתאם לתרחיש השימוש, יכול להיות שתצטרכו בין 10 ל-10,000 דוגמאות באיכות גבוהה כדי לשפר את הפלט של המודל. לדוגמה, אם צריך לבצע כוונון עדין של מודל כדי להצטיין במשימה מסוימת, כמו מענה על שאלות רפואיות, תצטרכו מערך נתונים איכותי שמייצג את סוגי השאלות שיוצגו למודל ואת סוגי התשובות שהוא צריך לספק.
בטבלה הבאה מפורטות הערכות לגבי מספר הדוגמאות שצריך כדי לשפר את הפלט של מודל AI גנרטיבי בטכניקה מסוימת:
-
מידע עדכני. אחרי האימון המקדים, למודלים של AI גנרטיבי יש מאגר ידע קבוע. אם התוכן בדומיין של המודל משתנה לעיתים קרובות,
תצטרכו אסטרטגיה כדי שהמודל יהיה עדכני, למשל:
- כוונון עדין
- retrieval-augmented generation (RAG)
- אימון מראש תקופתי
| טכניקה | מספר הדוגמאות הנדרשות |
|---|---|
| הנחיה ישירה (Zero-shot) | 0 |
| מתן הנחיות בשיטת few-shot | ~10 שניות עד 100 שניות |
| כוונון יעיל בפרמטרים 1 | ~100 עד 10,000 |
| כוונון עדין | ~1,000 עד 10,000 (או יותר) |
רמת הקושי של הבעיה
קשה להעריך את רמת הקושי של בעיה. מה שנראה בהתחלה כגישה סבירה עשוי להתברר כשאלה מחקרית פתוחה, ומה שנראה כמעשי ובר ביצוע עשוי להתברר כלא מציאותי או כלא ישים. כדי להעריך את רמת הקושי של הבעיה, אפשר לענות על השאלות הבאות:
האם בעיה דומה כבר נפתרה? לדוגמה, האם צוותים בארגון שלך השתמשו בנתונים דומים (או זהים) כדי לבנות מודלים? האם אנשים או צוותים מחוץ לארגון שלכם פתרו בעיות דומות, למשל ב-Kaggle או ב-TensorFlow Hub? אם כן, סביר להניח שתוכלו להשתמש בחלקים מהמודל שלהם כדי לבנות את המודל שלכם.
האם אופי הבעיה מורכב? השוואה לביצועים של בני אדם במשימה יכולה לתת לכם מושג לגבי רמת הקושי של הבעיה. לדוגמה:
- בני אדם יכולים לסווג את סוג בעל החיים בתמונה ברמת דיוק של כ-95%.
- אנשים יכולים לסווג ספרות בכתב יד ברמת דיוק של כ-99%.
הנתונים שלמעלה מצביעים על כך שיצירת מודל לסיווג בעלי חיים היא משימה מורכבת יותר מיצירת מודל לסיווג של ספרות בכתב יד.
האם יש משתתפים בעייתיים? האם אנשים ינסו באופן פעיל לנצל את המודל? אם כן, תצטרכו כל הזמן לעדכן את המודל לפני שמישהו ישתמש בו לרעה. לדוגמה, מסנני ספאם לא יכולים לזהות סוגים חדשים של ספאם כשמישהו מנצל את המודל כדי ליצור אימיילים שנראים לגיטימיים.
AI גנרטיבי
למודלים של AI גנרטיבי יש נקודות חולשה פוטנציאליות שיכולות להקשות על פתרון בעיה:
- מקור הקלט. מאיפה יגיע הקלט? האם הנחיות מתנגדות יכולות לגרום לדליפת נתוני אימון, חומרים מקדימים, תוכן של מסד נתונים או מידע על כלי?
- שימוש בפלט. איך ייעשה שימוש בפלט? האם המודל יפיק תוכן גולמי או שיהיו שלבי ביניים לבדיקה ולאימות של התוכן כדי לוודא שהוא הולם? לדוגמה, מתן פלט גולמי לתוספים עלול לגרום למספר בעיות אבטחה.
- כוונון עדין. כוונון עדין עם מערך נתונים פגום עלול להשפיע באופן שלילי על המשקלים של המודל. השחיתות הזו תגרום למודל להפיק תוכן שגוי, רעיל או מוטה. כמו שצוין קודם, כדי לבצע התאמה עדינה צריך מערך נתונים שאומת כמכיל דוגמאות באיכות גבוהה.
איכות החיזוי
חשוב לשקול בקפידה את ההשפעה של התחזיות של המודל על המשתמשים, ולקבוע את איכות התחזיות הנדרשת למודל.
איכות החיזוי הנדרשת תלויה בסוג החיזוי. לדוגמה, איכות החיזוי הנדרשת למערכת המלצות לא תהיה זהה לאיכות החיזוי הנדרשת למודל שמסמן הפרות מדיניות. המלצה על סרטון לא מתאים עלולה לפגוע בחוויית המשתמש. עם זאת, סימון שגוי של סרטון כהפרה של כללי המדיניות של הפלטפורמה עלול ליצור עלויות תמיכה, או גרוע מכך, עלויות משפטיות.
האם המודל צריך לספק תחזיות באיכות גבוהה מאוד כי תחזיות שגויות עלולות להיות יקרות מאוד? באופן כללי, ככל שאיכות התחזית הנדרשת גבוהה יותר, כך הבעיה קשה יותר. לצערנו, כשמנסים לשפר את האיכות של פרויקטים, לעיתים קרובות מגיעים לנקודה שבה התועלת הנוספת הולכת ופוחתת. לדוגמה, שיפור הדיוק של מודל מ-99.9% ל-99.99% יכול להוביל לעלייה של פי 10 בעלות הפרויקט (ואולי יותר).
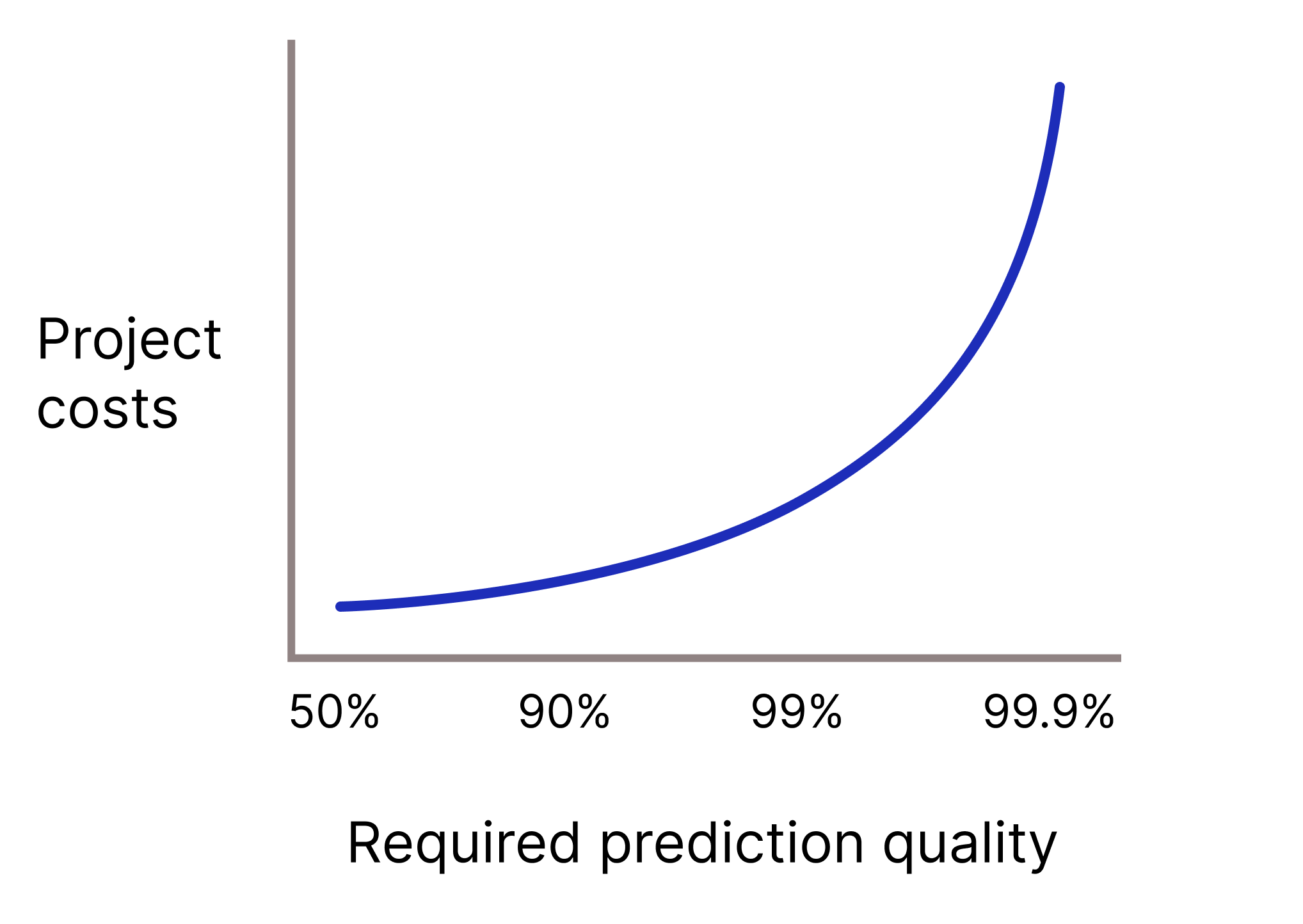
איור 2. בדרך כלל, פרויקט ML דורש יותר ויותר משאבים ככל שאיכות התחזית הנדרשת עולה.
AI גנרטיבי
כשמנתחים פלט של בינה מלאכותית גנרטיבית, חשוב לשים לב לנקודות הבאות:
-
דיוק עובדתי. מודלים של AI גנרטיבי יכולים ליצור תוכן שוטף ועקבי, אבל לא בטוח שהתוכן יהיה עובדתי. טענות שקריות ממודלים של בינה מלאכותית גנרטיבית נקראות המצאות.
לדוגמה, מודלים של AI גנרטיבי יכולים להמציא מידע ולספק סיכומים שגויים של טקסט, תשובות שגויות לשאלות במתמטיקה או הצהרות שקריות על העולם. במקרים רבים עדיין נדרש אימות אנושי של פלט AI גנרטיבי לפני השימוש בו בסביבת ייצור, למשל קוד שנוצר על ידי LLM.
בדומה ל-ML מסורתי, ככל שהדרישה לדיוק עובדתי גבוהה יותר, כך העלות של פיתוח ותחזוקה גבוהה יותר.
- איכות הפלט. מהן ההשלכות המשפטיות והפיננסיות (או ההשלכות האתיות) של תוצאות גרועות, כמו תוכן מוטה, תוכן שהועתק או תוכן רעיל?
דרישות טכניות
למודלים יש מספר דרישות טכניות שמשפיעות על ההיתכנות שלהם. אלה הדרישות הטכניות העיקריות שצריך להתייחס אליהן כדי לקבוע את היתכנות הפרויקט:
- זמן אחזור. מהן הדרישות לגבי זמן האחזור? באיזו מהירות צריך להציג את התחזיות?
- שאילתות לשנייה (QPS). מהן הדרישות לגבי QPS?
- השימוש ב-RAM מהן דרישות ה-RAM לאימון ולשימוש?
- פלטפורמה איפה המודל יפעל: אונליין (שאילתות שנשלחות לשרת RPC), WebML (בתוך דפדפן אינטרנט), ODML (בטלפון או בטאבלט) או אופליין (תחזיות שנשמרות בטבלה)?
יכולת פירוש. האם החיזויים צריכים להיות ניתנים לפירוש? לדוגמה, האם המוצר שלכם יצטרך לענות על שאלות כמו 'למה תוכן מסוים סומן כספאם?' או 'למה נקבע שסרטון מסוים מפר את מדיניות הפלטפורמה?'
תדירות האימון מחדש. אם הנתונים הבסיסיים של המודל משתנים במהירות, יכול להיות שיהיה צורך לבצע אימון מחדש לעיתים קרובות או באופן רציף. עם זאת, אימון מחדש בתדירות גבוהה עלול להוביל לעלויות משמעותיות, שעשויות להיות גבוהות יותר מהיתרונות של עדכון התחזיות של המודל.
ברוב המקרים, כנראה שתצטרכו להתפשר על איכות המודל כדי לעמוד במפרט הטכני שלו. במקרים כאלה, תצטרכו להחליט אם עדיין אפשר ליצור מודל שיהיה מספיק טוב כדי להעביר אותו לסביבת הייצור.
AI גנרטיבי
כשעובדים עם AI גנרטיבי, חשוב לשים לב לדרישות הטכניות הבאות:
- פלטפורמה מודלים רבים שאומנו מראש מגיעים במגוון גדלים, מה שמאפשר להם לפעול במגוון פלטפורמות עם משאבי מחשוב שונים. לדוגמה, מודלים שאומנו מראש יכולים להיות מגוונים – החל ממודלים שמתאימים לשימוש במרכזי נתונים ועד למודלים שמתאימים לשימוש בטלפון. כשבוחרים את גודל המודל, צריך לקחת בחשבון את מגבלות ההשהיה, הפרטיות והאיכות של המוצר או השירות. לפעמים יש סתירה בין האילוצים האלה. לדוגמה, מגבלות פרטיות עשויות לדרוש שהסקת המסקנות תתבצע במכשיר של המשתמש. עם זאת, יכול להיות שהאיכות של הפלט תהיה נמוכה כי אין למכשיר את המשאבים הדרושים כדי להפיק תוצאות טובות.
- זמן אחזור. גודל הקלט והפלט של המודל משפיע על זמן האחזור. בפרט, גודל הפלט משפיע על זמן האחזור יותר מגודל הקלט. מודלים יכולים להריץ את הקלט שלהם במקביל, אבל הם יכולים ליצור פלט רק באופן רציף. במילים אחרות, יכול להיות שהשהייה תהיה זהה כשמעבדים קלט של 500 מילים או של 10 מילים, אבל ייקח הרבה יותר זמן ליצור סיכום של 500 מילים מאשר ליצור סיכום של 10 מילים.
- שימוש בכלים ובממשקי API. האם המודל יצטרך להשתמש בכלים ובממשקי API, כמו חיפוש באינטרנט, שימוש במחשבון או גישה ללקוח אימייל כדי להשלים משימה? בדרך כלל, ככל שצריך יותר כלים כדי להשלים משימה, כך גדל הסיכוי להפצת טעויות ולהגברת נקודות החולשה של המודל.
עלות
האם הטמעה של ML תהיה משתלמת? רוב הפרויקטים של למידת מכונה לא יאושרו אם הפתרון של למידת המכונה יקר יותר ליישום ולתחזוקה מהכסף שהוא מייצר (או חוסך). בפרויקטים של ML יש עלויות של בני אדם ושל מכונות.
עלויות כוח אדם. כמה אנשים יידרשו כדי שהפרויקט יעבור משלב הוכחת ההיתכנות לשלב הייצור? ככל שהפרויקטים של ML מתפתחים, ההוצאות בדרך כלל גדלות. לדוגמה, פרויקטים של ML דורשים יותר אנשים כדי לפרוס ולתחזק מערכת מוכנה לייצור מאשר כדי ליצור אב טיפוס. נסו להעריך את מספר התפקידים ואת סוגי התפקידים שיידרשו בפרויקט בכל שלב.
עלויות של מכונות. אימון, פריסה ותחזוקה של מודלים דורשים הרבה כוח מחשוב וזיכרון. לדוגמה, יכול להיות שתצטרכו מכסת TPU לאימון מודלים ולהצגת תחזיות, וגם את התשתית הדרושה לצינור הנתונים שלכם. יכול להיות שתצטרכו לשלם כדי לקבל נתונים עם תוויות או לשלם דמי רישוי על נתונים. לפני שמבצעים אימון של מודל, כדאי להעריך את עלויות המכונה לבנייה ולתחזוקה של תכונות ML לטווח הארוך.
עלות ההסקה. האם המודל יצטרך לבצע מאות או אלפי הסקות שיעלו יותר מההכנסה שנוצרה?
חשוב לזכור
בעיות שקשורות לאחד מהנושאים הקודמים יכולות להקשות על הטמעת פתרון ML, אבל מועדים צפופים יכולים להחמיר את הבעיות. נסו לתכנן ולהקצות מספיק זמן בהתאם לרמת הקושי של הבעיה, ואז נסו להקצות עוד זמן מעבר למה שאתם מקצים בדרך כלל לפרויקט שלא קשור ל-ML.
בדיקת ההבנה
אתה עובד בחברה לשימור הטבע ומנהל את תוכנת זיהוי הצמחים של החברה. אתם רוצים ליצור מודל לסיווג של 60 סוגים של מיני צמחים פולשניים, כדי לעזור לאנשי שימור לנהל את בתי הגידול של בעלי חיים בסכנת הכחדה.
מצאתם קוד לדוגמה שפותר בעיה דומה של זיהוי צמחים, והעלויות המשוערות של הטמעת הפתרון הן במסגרת התקציב של הפרויקט. למרות שיש במערך הנתונים הרבה דוגמאות לאימון, יש רק כמה דוגמאות לגבי חמשת המינים הפולשים הנפוצים ביותר. ההנהלה לא דורשת שהתחזיות של המודל יהיו ניתנות לפירוש, ולא נראה שיש השלכות שליליות שקשורות לתחזיות שגויות. האם פתרון ה-ML בר-ביצוע?