在構思和規劃階段,您會調查 ML 解決方案的元素。在界定問題的工作中,您會從機器學習解決方案的角度界定問題。「機器學習問題界定簡介」課程會詳細說明這些步驟。在規劃工作期間,您會估算解決方案的可行性、規劃方法,並設定成功指標。
雖然機器學習在理論上是不錯的解決方案,但您仍需評估其在現實世界中的可行性。舉例來說,解決方案可能在技術上可行,但實際上難以或無法實作。下列因素會影響專案的可行性:
- 資料可用性
- 問題難度
- 預測品質
- 技術相關規定
- 費用
資料可用性
機器學習模型的品質取決於訓練資料。因此需要大量高品質資料,才能做出高品質的預測。回答下列問題有助於判斷您是否擁有訓練模型所需的資料:
數量。您是否能取得足夠的高品質資料來訓練模型?標示範例是否稀少、難以取得或太過昂貴?舉例來說,取得標示的醫療圖片或稀有語言的翻譯內容非常困難。如要做出準確預測,分類模型需要每個標籤的眾多範例。如果訓練資料集中某些標籤的範例有限,模型就無法做出準確的預測。
功能適用情況取決於放送時間。訓練時使用的所有特徵,是否都能在服務時使用?團隊花費大量時間訓練模型,卻發現模型需要某些功能時,這些功能要過幾天才能使用。
舉例來說,假設模型會預測顧客是否會點選網址,而訓練時使用的其中一項特徵包含
user_age。不過,當模型提供預測結果時,user_age可能無法使用,或許是因為使用者尚未建立帳戶。法規。取得及使用資料時,有哪些法規和法律規定?舉例來說,部分規定會限制特定類型資料的儲存和使用方式。
生成式 AI
預先訓練的 生成式 AI 模型通常需要經過精心挑選的資料集,才能擅長處理特定領域的工作。您可能需要資料集來處理下列用途:
-
提示工程、
高效參數調整和
微調。
視用途而定,您可能需要 10 到 10,000 個高品質範例,才能進一步改善模型輸出內容。舉例來說,如果需要微調模型,讓模型擅長回答醫療問題等特定工作,您需要高品質的資料集,其中包含模型會遇到的問題類型,以及模型應提供的答案類型。
下表提供估計值,說明使用特定技術時,需要多少範例才能改善生成式 AI 模型的輸出內容:
-
最新資訊。預先訓練完成後,生成式 AI 模型就會有固定的知識庫。如果模型網域中的內容經常變更,您需要採取策略來確保模型內容與時俱進,例如:
- 微調
- 檢索增強生成 (RAG)
- 定期訓練前準備
| 做法 | 所需範例數量 |
|---|---|
| 零樣本提示 | 0 |
| 少量樣本提示 | 約 10 秒至 100 秒 |
| 高效參數調整 1 | 約 100 個至 10,000 個 |
| 微調 | ~1000s–10,000s (或更多) |
問題難度
問題的難度可能難以估計。一開始看似可行的方法,可能實際上是開放式研究問題;看似實用且可行的做法,可能實際上不切實際或無法運作。回答下列問題有助於評估問題的難度:
是否已解決類似問題?舉例來說,貴機構的團隊是否曾使用類似 (或相同) 的資料建構模型?貴機構以外的人員或團隊是否曾解決類似問題,例如在 Kaggle 或 TensorFlow Hub 上?如果是,您可能可以運用他們的模型部分內容來建構自己的模型。
問題的性質是否很複雜?瞭解這項工作的基準,有助於判斷問題的難度。例如:
- 人類分類圖片中動物種類的準確率約為 95%。
- 人類分類手寫數字的準確率約為 99%。
上述資料顯示,建立動物分類模型比建立手寫數字分類模型更困難。
是否有潛在的惡意行為人?是否會有人積極嘗試利用您的模型?如果真是如此,您就必須不斷更新模型,以免遭到濫用。舉例來說,如果有人利用模型建立看似合法的電子郵件,垃圾內容篩選器就無法偵測到新型垃圾內容。
生成式 AI
生成式 AI 模型可能存在潛在的安全性漏洞,導致問題難度提高:
- 輸入來源:輸入內容的來源為何?惡意提示是否會洩漏訓練資料、前言資料、資料庫內容或工具資訊?
- 輸出內容的使用方式。輸出內容的用途為何?模型會輸出原始內容,還是會經過測試和驗證等中間步驟,確保內容適當?舉例來說,將原始輸出內容提供給外掛程式可能會導致多項安全問題。
- 微調。使用損毀的資料集進行微調,可能會對模型的權重造成負面影響。這類損毀會導致模型輸出不正確、有害或有偏見的內容。如先前所述,微調需要經過驗證的資料集,其中包含高品質的範例。
預測品質
請仔細考量模型預測結果對使用者的影響,並判斷模型所需的預測品質。
預測品質要求取決於預測類型。舉例來說,推薦系統所需的預測品質,與標記違規政策的模型不同。推薦錯誤的影片可能會導致使用者體驗不佳。不過,如果錯誤地將影片檢舉為違反平台政策,可能會產生支援費用,甚至更糟的情況,還可能產生法律費用。
如果預測錯誤的代價極高,模型是否需要極高的預測品質?一般來說,預測品質要求越高,問題就越難解決。很遺憾,專案通常會在您嘗試提升品質時,達到報酬遞減的階段。舉例來說,如果將模型的準確度從 99.9% 提高到 99.99%,專案的成本可能會增加 10 倍 (甚至更多)。
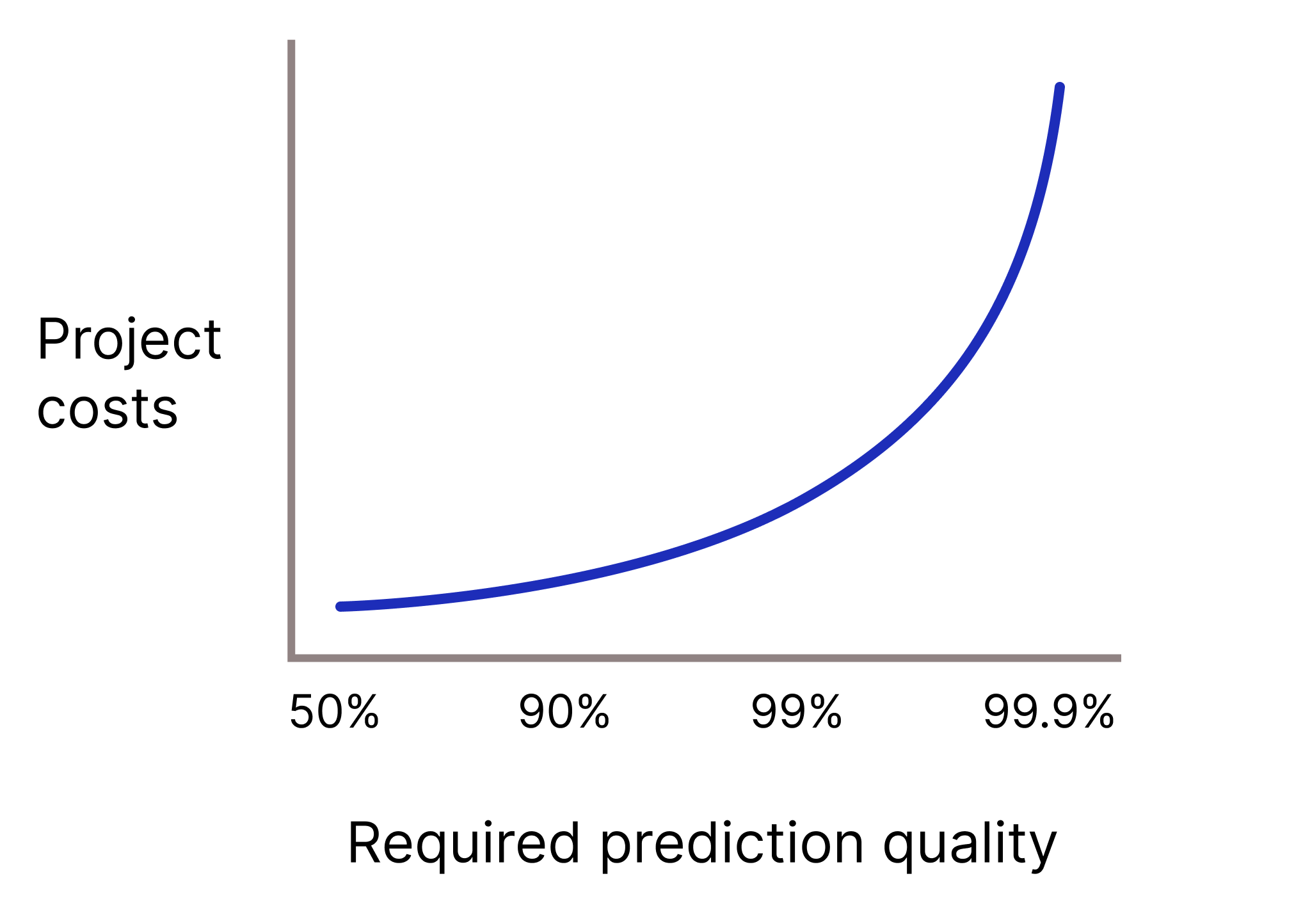
圖 2. 隨著預測品質要求提高,機器學習專案通常需要越來越多資源。
生成式 AI
分析生成式 AI 輸出內容時,請考量下列事項:
-
符合實情。雖然生成式 AI 模型可以生成流暢連貫的內容,但無法保證內容符合事實。生成式 AI 模型提供的錯誤陳述稱為捏造。舉例來說,生成式 AI 模型可能會捏造內容,生成不正確的文字摘要、數學問題的錯誤答案,或是關於世界的錯誤陳述。許多用途仍需人工驗證生成式 AI 的輸出內容,才能用於實際執行環境,例如 LLM 生成的程式碼。
與傳統機器學習一樣,事實準確度要求越高,開發和維護成本就越高。
- 輸出品質:如果生成內容不當 (例如有偏見、抄襲或有害),會造成哪些法律和財務後果 (或道德影響)?
技術相關規定
模型有許多技術相關規定,會影響可行性。以下是您需要解決的主要技術要求,以判斷專案的可行性:
- 延遲時間:延遲規定為何?預測結果的提供速度要求。
- 每秒查詢次數 (QPS)。QPS 規定為何?
- RAM 使用量。訓練和服務的 RAM 需求為何?
- 平台。模型將在哪裡執行:線上 (查詢傳送至 RPC 伺服器)、WebML (在網路瀏覽器中)、ODML (在手機或平板電腦上),還是離線 (預測結果儲存在資料表中)?
可解釋性。預測結果是否需要可解讀?舉例來說,您的產品是否需要回答「為何特定內容遭到標示為垃圾內容?」或「為何影片違反平台政策?」等問題?
重新訓練頻率:如果模型的基礎資料快速變更,可能就需要經常或持續重新訓練模型。不過,頻繁重新訓練可能會導致成本大幅增加,甚至超過更新模型預測所帶來的效益。
在多數情況下,您可能必須犧牲模型品質,才能符合技術規格。在這種情況下,您需要判斷是否仍可產生足夠優質的模型,以供正式版使用。
生成式 AI
使用生成式 AI 時,請考量下列技術需求:
- 平台。許多預先訓練模型都有不同大小,因此可在各種平台運作,並使用不同的運算資源。舉例來說,預先訓練模型的大小從資料中心規模到適合手機的都有。選擇模型大小時,請務必考量產品或服務的延遲、隱私權和品質限制。這些限制通常會互相衝突。舉例來說,隱私權限制可能要求推論作業在使用者裝置上執行。不過,由於裝置缺乏運算資源,可能無法產生優質結果,因此輸出品質可能不佳。
- 延遲時間:模型輸入和輸出大小會影響延遲時間。特別是輸出大小對延遲的影響,大於輸入大小。模型可以平行處理輸入內容,但只能依序生成輸出內容。換句話說,輸入 500 字或 10 字的延遲時間可能相同,但產生 500 字摘要所需的時間,會比產生 10 字摘要的時間長得多。
- 工具和 API 使用。模型是否需要使用工具和 API (例如搜尋網際網路、使用計算機或存取電子郵件用戶端) 來完成工作?一般來說,完成工作所需的工具越多,傳播錯誤的機會就越大,模型也越容易受到攻擊。
費用
導入機器學習技術是否值得?如果機器學習解決方案的實作和維護成本高於產生的 (或節省的) 金額,大部分的機器學習專案都不會獲得核准。機器學習專案會產生人力和機器費用。
人為成本。專案從概念驗證到實際工作環境需要多少人?隨著機器學習專案的演進,支出通常會增加。舉例來說,相較於建立原型,機器學習專案需要更多人手來部署及維護可供正式環境使用的系統。請盡量估算專案在各階段需要多少角色,以及需要哪些類型的角色。
機器費用。訓練、部署及維護模型需要大量運算和記憶體資源。舉例來說,您可能需要 TPU 配額來訓練模型和提供預測結果,以及資料管道所需的基礎架構。您可能需要支付資料標註費用或資料授權費。訓練模型前,請先估算長期建構及維護機器學習功能的機器成本。
推論成本。模型是否需要進行數百或數千次推論,但成本卻高於產生的收益?
注意事項
如果遇到與上述任何主題相關的問題,實作機器學習解決方案就會是一項挑戰,而緊迫的期限可能會加劇這些挑戰。請根據問題的難度,規劃並預估足夠的時間,然後盡量預留比非機器學習專案更多的時間。
隨堂測驗
你任職於自然保育公司,負責管理公司的植物辨識軟體。您想建立模型,將 60 種入侵植物物種分類,協助保育人士管理瀕危動物的棲息地。
您找到可解決類似植物辨識問題的範例程式碼,且實作解決方案的預估費用在專案預算內。雖然資料集有許多訓練範例,但五種最具侵入性的物種只有少數範例。領導階層並未要求模型預測結果可解讀,而且不良預測結果似乎不會造成負面影響。您的機器學習解決方案是否可行?