Na etapie tworzenia koncepcji i planowania analizujesz elementy rozwiązania ML. Podczas zadania określania problemu przedstawiasz go w kontekście rozwiązania opartego na uczeniu maszynowym. Kurs Wprowadzenie do formułowania problemów w uczeniu maszynowym szczegółowo omawia te kroki. Podczas planowania szacujesz wykonalność rozwiązania, planujesz podejścia i ustalasz wskaźniki sukcesu.
Chociaż uczenie maszynowe może być teoretycznie dobrym rozwiązaniem, musisz oszacować jego wykonalność w rzeczywistości. Na przykład rozwiązanie może działać technicznie, ale być niepraktyczne lub niemożliwe do wdrożenia. Na wykonalność projektu wpływają te czynniki:
- Dostępność danych
- Poziom trudności problemu
- Jakość prognozy
- Wymagania techniczne
- Koszt
Dostępność danych
Modele ML są tak dobre, jak dane, na których są trenowane. Potrzebują one dużej ilości wysokiej jakości danych, aby generować trafne prognozy. Odpowiedzi na te pytania pomogą Ci ocenić, czy masz dane niezbędne do wytrenowania modelu:
Ilość Czy możesz uzyskać wystarczającą ilość danych o wysokiej jakości, aby wytrenować model? Czy oznaczone przykłady są rzadkie, trudne do zdobycia lub zbyt drogie? Na przykład uzyskanie oznaczonych obrazów medycznych lub tłumaczeń rzadkich języków jest niezwykle trudne. Aby tworzyć trafne prognozy, modele klasyfikacji wymagają wielu przykładów dla każdej etykiety. Jeśli zbiór danych treningowych zawiera niewiele przykładów dla niektórych etykiet, model nie może dokonywać dobrych prognoz.
Dostępność funkcji w momencie wyświetlania. Czy wszystkie funkcje użyte podczas trenowania będą dostępne w czasie obsługi? Zespoły poświęcają dużo czasu na trenowanie modeli, a potem okazuje się, że niektóre funkcje stają się dostępne dopiero kilka dni po tym, jak model ich potrzebuje.
Załóżmy na przykład, że model przewiduje, czy klient kliknie adres URL, a jedną z cech używanych do trenowania jest
user_age. Gdy jednak model generuje prognozę, wartośćuser_agejest niedostępna, być może dlatego, że użytkownik nie utworzył jeszcze konta.Przepisy Jakie przepisy i wymagania prawne obowiązują w zakresie pozyskiwania i wykorzystywania danych? Na przykład niektóre wymagania określają limity przechowywania i używania określonych typów danych.
Generatywna AI
Wytrenowane modele generatywnej AI często wymagają wyselekcjonowanych zbiorów danych, aby dobrze radzić sobie z zadaniami w określonych dziedzinach. Zbiory danych mogą być potrzebne w tych przypadkach:
-
inżynieria promptów,
dostrajanie konkretnych parametrów i
dostrajanie.
W zależności od przypadku użycia możesz potrzebować od 10 do 10 000 przykładów wysokiej jakości, aby jeszcze bardziej dopracować dane wyjściowe modelu. Jeśli na przykład model ma być dostrojony do wykonywania konkretnego zadania, takiego jak odpowiadanie na pytania medyczne, potrzebujesz wysokiej jakości zbioru danych, który będzie reprezentatywny dla rodzajów pytań, jakie będą mu zadawane, oraz rodzajów odpowiedzi, jakich powinien udzielać.
W tabeli poniżej znajdziesz szacunkową liczbę przykładów potrzebnych do ulepszenia danych wyjściowych modelu generatywnej AI w przypadku danej techniki:
-
Aktualne informacje Po wstępnym wytrenowaniu modele generatywnej AI mają stałą bazę wiedzy. Jeśli treści w domenie modelu często się zmieniają, musisz opracować strategię aktualizowania modelu, np.:
- dostrajanie,
- generowanie rozszerzone przez wyszukiwanie w zapisanych informacjach (RAG)
- okresowe wstępne trenowanie,
| Metoda | Liczba wymaganych przykładów |
|---|---|
| Prompty „zero-shot” | 0 |
| Prompty „few-shot” | ~10–100 s |
| Dostrajanie konkretnych parametrów1 | ~100–10 000 |
| Dostrajanie | ~1000–10 000 (lub więcej) |
Poziom trudności problemu
Trudność problemu może być trudna do oszacowania. To, co początkowo wydaje się wiarygodnym podejściem, może w rzeczywistości okazać się otwartym pytaniem badawczym, a to, co wydaje się praktyczne i wykonalne, może okazać się nierealne lub niewykonalne. Odpowiedzi na te pytania pomogą Ci ocenić trudność problemu:
Czy podobny problem został już rozwiązany? Na przykład czy zespoły w Twojej organizacji używały podobnych (lub identycznych) danych do tworzenia modeli? Czy osoby lub zespoły spoza Twojej organizacji rozwiązały podobne problemy, np. na platformach Kaggle lub TensorFlow Hub? Jeśli tak, prawdopodobnie będziesz w stanie wykorzystać części ich modelu do zbudowania własnego.
Czy problem jest trudny? Znajomość wyników testów przeprowadzonych na ludziach może pomóc w określeniu poziomu trudności zadania. Na przykład:
- Ludzie potrafią określić rodzaj zwierzęcia na zdjęciu z dokładnością około 95%.
- Ludzie potrafią klasyfikować odręcznie napisane cyfry z dokładnością około 99%.
Z powyższych danych wynika, że utworzenie modelu do klasyfikowania zwierząt jest trudniejsze niż utworzenie modelu do klasyfikowania odręcznie napisanych cyfr.
Czy istnieją potencjalnie nieuczciwe podmioty? Czy ktoś będzie aktywnie próbował wykorzystać Twój model? W takim przypadku będziesz musiał(-a) nieustannie aktualizować model, zanim będzie można go niewłaściwie wykorzystać. Na przykład filtry spamu nie mogą wykrywać nowych rodzajów spamu, gdy ktoś wykorzystuje model do tworzenia e-maili, które wyglądają na legalne.
Generatywna AI
Modele generatywnej AI mają potencjalne luki, które mogą zwiększać trudność problemu:
- Źródło sygnału Skąd będą pochodzić dane wejściowe? Czy prompty generowane przez użytkowników mogą ujawniać dane treningowe, materiały wstępne, zawartość bazy danych lub informacje o narzędziach?
- Wykorzystanie danych wyjściowych. Jak będą wykorzystywane wyniki? Czy model będzie generować treści w formie surowej, czy też będą podejmowane kroki pośrednie, które sprawdzą i zweryfikują, czy są one odpowiednie? Na przykład przekazywanie do wtyczek nieprzetworzonych danych wyjściowych może powodować wiele problemów z bezpieczeństwem.
- Dostrajanie. Dostrajanie z użyciem uszkodzonego zbioru danych może negatywnie wpłynąć na wagi modelu. W wyniku tego model może generować nieprawidłowe, szkodliwe lub stronnicze treści. Jak wspomnieliśmy wcześniej, dostrajanie wymaga zbioru danych, który został zweryfikowany pod kątem wysokiej jakości przykładów.
Jakość prognozy
Musisz dokładnie rozważyć wpływ prognoz modelu na użytkowników i określić wymaganą jakość prognoz.
Wymagana jakość prognozy zależy od jej typu. Na przykład jakość prognozowania wymagana w przypadku systemu rekomendacji nie będzie taka sama jak w przypadku modelu, który wykrywa naruszenia zasad. Polecanie nieodpowiedniego filmu może negatywnie wpłynąć na wrażenia użytkowników. Jednak błędne oznaczenie filmu jako naruszającego zasady platformy może generować koszty pomocy lub, co gorsza, opłaty prawne.
Czy Twój model musi mieć bardzo wysoką jakość prognozowania, ponieważ błędne prognozy są bardzo kosztowne? Ogólnie rzecz biorąc, im wyższa wymagana jakość prognozy, tym trudniejsze jest zadanie. Niestety w przypadku projektów często występuje zjawisko malejących przychodów, gdy próbujesz poprawić jakość. Na przykład zwiększenie precyzji modelu z 99,9% do 99,99% może oznaczać 10-krotny wzrost kosztów projektu (a nawet większy).
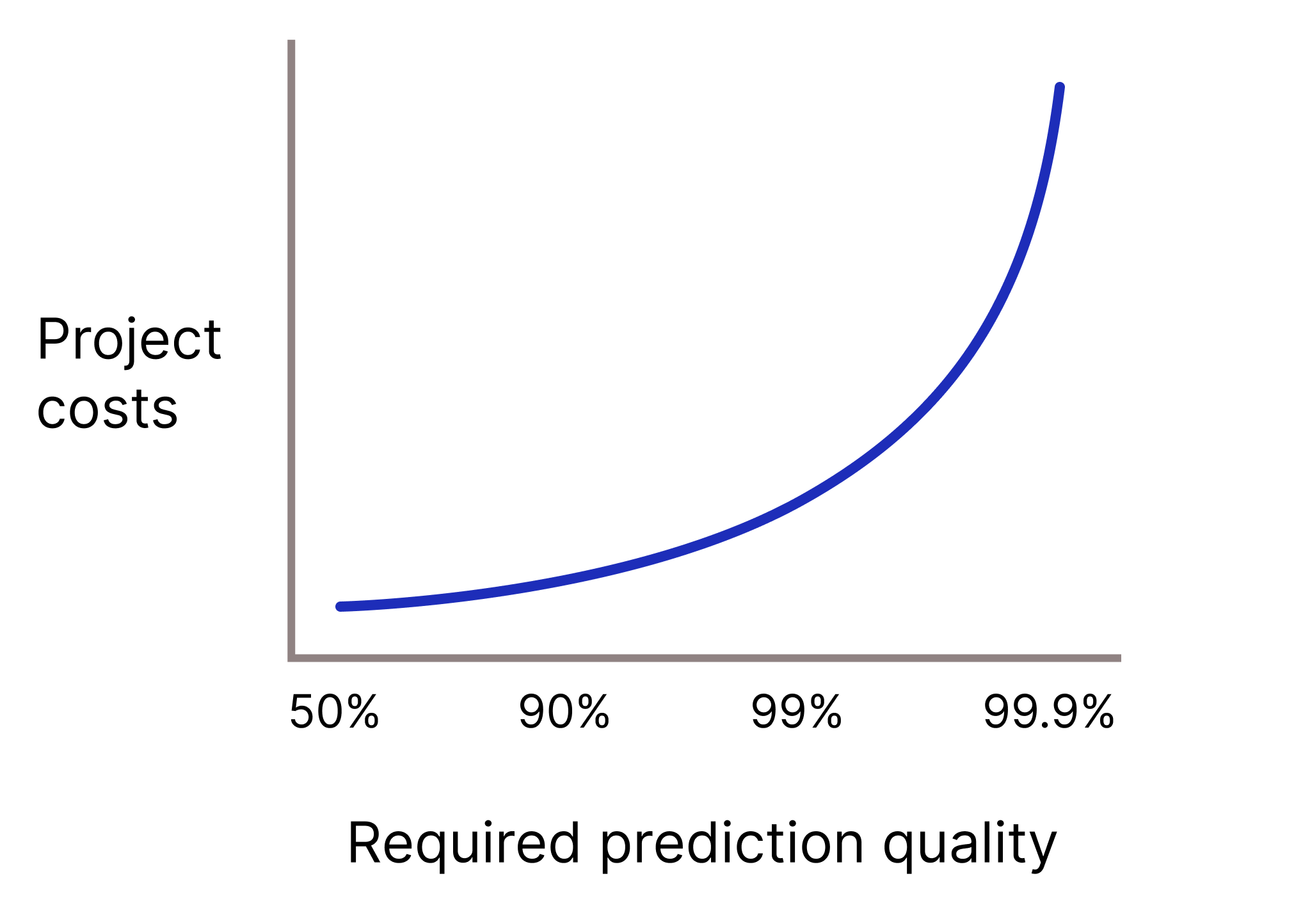
Rysunek 2. Wraz ze wzrostem wymaganej jakości prognozowania projekt ML zwykle wymaga coraz większej ilości zasobów.
Generatywna AI
Podczas analizowania danych wyjściowych generatywnej AI weź pod uwagę te kwestie:
-
Zgodność z prawdą Modele generatywnej AI mogą tworzyć płynne i spójne treści, ale nie ma gwarancji, że będą one zgodne z prawdą. Fałszywe stwierdzenia modeli generatywnej AI nazywane są konfabulacjami.
Modele generatywnej AI mogą na przykład zmyślać i tworzyć nieprawidłowe podsumowania tekstu, błędne odpowiedzi na pytania matematyczne lub fałszywe stwierdzenia dotyczące świata. Wiele przypadków użycia nadal wymaga weryfikacji przez człowieka wyników generatywnej AI przed użyciem w środowisku produkcyjnym, np. kodu wygenerowanego przez LLM.
Podobnie jak w przypadku tradycyjnego uczenia maszynowego, im większe wymagania dotyczące dokładności faktów, tym wyższe koszty opracowania i utrzymania.
- Jakość wyjściowa Jakie są prawne i finansowe konsekwencje (lub implikacje etyczne) nieprawidłowych wyników, takich jak treści stronnicze, plagiaty lub treści toksyczne?
Wymagania techniczne
Modele mają szereg wymagań technicznych, które wpływają na ich wykonalność. Oto główne wymagania techniczne, które musisz spełnić, aby określić wykonalność projektu:
- Opóźnienie. Jakie są wymagania dotyczące opóźnienia? Jak szybko mają być wyświetlane prognozy?
- Zapytania na sekundę (QPS) Jakie są wymagania dotyczące zapytań na sekundę?
- Wykorzystanie pamięci RAM Jakie są wymagania dotyczące pamięci RAM w przypadku trenowania i obsługi?
- Platforma Gdzie będzie działać model: online (zapytania wysyłane do serwera RPC), WebML (w przeglądarce internetowej), ODML (na telefonie lub tablecie) czy offline (prognozy zapisywane w tabeli)?
Interpretowalność Czy prognozy muszą być interpretowalne? Na przykład czy Twój produkt będzie musiał odpowiadać na pytania takie jak „Dlaczego konkretna treść została oznaczona jako spam?” lub „Dlaczego film został uznany za naruszający zasady platformy?”.
Częstotliwość ponownego trenowania Gdy dane bazowe modelu szybko się zmieniają, może być konieczne częste lub ciągłe ponowne trenowanie. Częste ponowne trenowanie może jednak wiązać się ze znacznymi kosztami, które mogą przewyższać korzyści wynikające z aktualizowania prognoz modelu.
W większości przypadków, aby zachować zgodność ze specyfikacjami technicznymi, prawdopodobnie będziesz musiał(-a) pójść na kompromis w kwestii jakości modelu. W takich przypadkach musisz określić, czy nadal możesz utworzyć model, który będzie wystarczająco dobry, aby wdrożyć go w środowisku produkcyjnym.
Generatywna AI
Podczas pracy z generatywną AI weź pod uwagę te wymagania techniczne:
- Platforma Wiele wstępnie wytrenowanych modeli jest dostępnych w różnych rozmiarach, dzięki czemu mogą działać na różnych platformach o różnych zasobach obliczeniowych. Na przykład wstępnie wytrenowane modele mogą być używane w centrach danych lub na telefonach. Wybierając rozmiar modelu, musisz wziąć pod uwagę ograniczenia dotyczące opóźnienia, prywatności i jakości produktu lub usługi. Te ograniczenia mogą często ze sobą kolidować. Na przykład ograniczenia dotyczące prywatności mogą wymagać, aby wnioskowanie odbywało się na urządzeniu użytkownika. Jakość wyjściowa może być jednak niska, ponieważ urządzenie nie ma wystarczających zasobów obliczeniowych, aby uzyskać dobre wyniki.
- Opóźnienie. Rozmiar danych wejściowych i wyjściowych modelu wpływa na czas oczekiwania. W szczególności rozmiar danych wyjściowych ma większy wpływ na opóźnienie niż rozmiar danych wejściowych. Modele mogą przetwarzać dane wejściowe równolegle, ale dane wyjściowe mogą generować tylko sekwencyjnie. Inaczej mówiąc, opóźnienie może być takie samo w przypadku danych wejściowych o długości 500 słów i 10 słów, ale wygenerowanie podsumowania o długości 500 słów zajmuje znacznie więcej czasu niż wygenerowanie podsumowania o długości 10 słów.
- Korzystanie z narzędzi i interfejsów API. Czy model będzie musiał używać narzędzi i interfejsów API, takich jak wyszukiwanie w internecie, kalkulator lub klient poczty e-mail, aby wykonać zadanie? Zwykle im więcej narzędzi jest potrzebnych do wykonania zadania, tym większe jest prawdopodobieństwo popełnienia błędów i zwiększenia podatności modelu na zagrożenia.
Koszt
Czy wdrożenie ML będzie warte poniesionych kosztów? Większość projektów związanych z uczeniem maszynowym nie zostanie zatwierdzona, jeśli wdrożenie i utrzymanie rozwiązania opartego na uczeniu maszynowym będzie droższe niż pieniądze, które generuje (lub oszczędza). Projekty ML generują koszty związane z pracą ludzi i maszyn.
Koszty związane z pracą ludzi. Ile osób będzie potrzebnych, aby projekt przeszedł od etapu weryfikacji koncepcji do produkcji? Wraz z rozwojem projektów ML wydatki zwykle rosną. Na przykład projekty ML wymagają więcej osób do wdrożenia i utrzymania systemu gotowego do produkcji niż do utworzenia prototypu. Spróbuj oszacować liczbę i rodzaje ról, które będą potrzebne w projekcie na każdym etapie.
Koszty maszyn Trenowanie, wdrażanie i utrzymywanie modeli wymaga dużej mocy obliczeniowej i pamięci. Możesz na przykład potrzebować limitu TPU do trenowania modeli i udostępniania prognoz, a także niezbędnej infrastruktury dla potoku danych. Może być konieczne zapłacenie za etykietowanie danych lub opłat licencyjnych za dane. Przed wytrenowaniem modelu warto oszacować koszty maszynowe związane z długoterminowym tworzeniem i utrzymywaniem funkcji uczenia maszynowego.
Koszt wnioskowania Czy model będzie musiał dokonywać setek lub tysięcy wnioskowań, które będą kosztować więcej niż wygenerowane przychody?
Pamiętaj
Problemy związane z którymkolwiek z powyższych tematów mogą utrudniać wdrażanie rozwiązania opartego na ML, ale krótkie terminy mogą jeszcze bardziej zwiększyć te trudności. Spróbuj zaplanować i przeznaczyć wystarczająco dużo czasu na podstawie postrzeganej trudności problemu, a następnie zarezerwuj jeszcze więcej czasu niż w przypadku projektu niezwiązanego z uczeniem maszynowym.
Sprawdź swoją wiedzę
Pracujesz w firmie zajmującej się ochroną przyrody i zarządzasz oprogramowaniem do identyfikacji roślin. Chcesz utworzyć model do klasyfikowania 60 gatunków roślin inwazyjnych, aby pomóc ekologom w zarządzaniu siedliskami zagrożonych zwierząt.
Znajdujesz przykładowy kod, który rozwiązuje podobny problem z rozpoznawaniem roślin, a szacowane koszty wdrożenia rozwiązania mieszczą się w budżecie projektu. Zbiór danych zawiera wiele przykładów treningowych, ale tylko kilka w przypadku 5 najbardziej inwazyjnych gatunków. Kierownictwo nie wymaga, aby prognozy modelu były interpretowalne, i nie wydaje się, aby złe prognozy miały negatywne konsekwencje. Czy Twoje rozwiązanie oparte na uczeniu maszynowym jest wykonalne?