No ML de produção, o objetivo não é criar e implantar um único modelo. O objetivo é criar pipelines automatizados para desenvolver, testar e implantar modelos ao longo do tempo. Por quê? À medida que o mundo muda, as tendências nos dados mudam, fazendo com que os modelos em produção fiquem desatualizados. Normalmente, os modelos precisam ser retreinados com dados atualizados para continuar oferecendo previsões de alta qualidade a longo prazo. Em outras palavras, você vai querer uma maneira de substituir modelos desatualizados por novos.
Sem pipelines, substituir um modelo desatualizado é um processo sujeito a erros. Por exemplo, quando um modelo começa a veicular previsões ruins, alguém precisa coletar e processar manualmente novos dados, treinar um novo modelo, validar a qualidade dele e, por fim, implantá-lo. Os pipelines de ML automatizam muitos desses processos repetitivos, tornando o gerenciamento e a manutenção de modelos mais eficientes e confiáveis.
Como criar pipelines
Os pipelines de ML organizam as etapas de criação e implantação de modelos em tarefas bem definidas. Os pipelines têm uma de duas funções: fornecer previsões ou atualizar o modelo.
Como disponibilizar previsões
O pipeline de exibição gera previsões. Ele expõe seu modelo ao mundo real, tornando-o acessível aos usuários. Por exemplo, quando um usuário quer uma previsão (como vai estar o tempo amanhã, quantos minutos vai levar para chegar ao aeroporto ou uma lista de vídeos recomendados), o pipeline de veiculação recebe e processa os dados do usuário, faz uma previsão e a entrega para ele.
Atualizar o modelo
Os modelos tendem a ficar desatualizados quase imediatamente após entrarem em produção. Em essência, eles fazem previsões usando informações antigas. Os conjuntos de dados de treinamento capturaram o estado do mundo há um dia ou, em alguns casos, há uma hora. Inevitavelmente, o mundo mudou: um usuário assistiu mais vídeos e precisa de uma nova lista de recomendações; a chuva fez o trânsito ficar lento e os usuários precisam de estimativas atualizadas dos horários de chegada; uma tendência popular faz com que os varejistas peçam previsões de inventário atualizadas para determinados itens.
Normalmente, as equipes treinam novos modelos muito antes de o modelo de produção ficar desatualizado. Em alguns casos, as equipes treinam e implantam novos modelos diariamente em um ciclo contínuo de treinamento e implantação. O ideal é que o treinamento de um novo modelo aconteça bem antes de o modelo de produção ficar desatualizado.
Os pipelines a seguir trabalham juntos para treinar um novo modelo:
- Pipeline de dados. O pipeline de dados processa dados do usuário para criar conjuntos de dados de treinamento e teste.
- Pipeline de treinamento. O pipeline de treinamento treina modelos usando os novos conjuntos de dados de treinamento do pipeline de dados.
- Pipeline de validação. O pipeline de validação compara o modelo treinado com o modelo de produção usando conjuntos de dados de teste gerados pelo pipeline de dados.
A Figura 4 ilustra as entradas e saídas de cada pipeline de ML.
Pipelines de ML
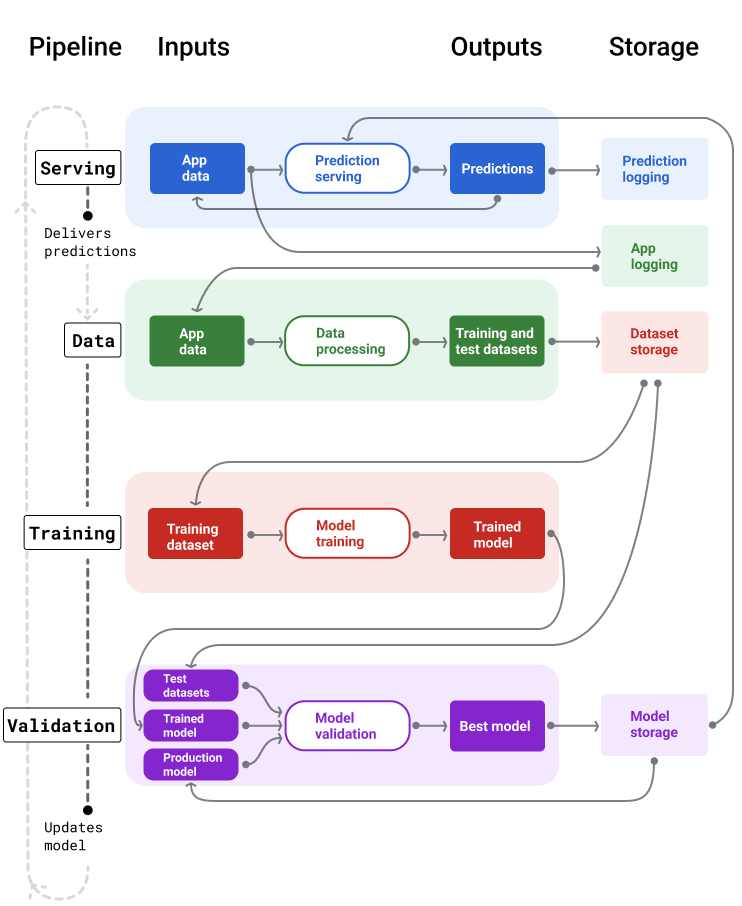
Figura 4. Os pipelines de ML automatizam muitos processos para desenvolver e manter modelos. Cada pipeline mostra as entradas e saídas.
De modo geral, veja como os pipelines mantêm um modelo atualizado em produção:
Primeiro, um modelo entra em produção, e o pipeline de disponibilização começa a gerar previsões.
O pipeline de dados começa imediatamente a coletar dados para gerar novos conjuntos de dados de treinamento e teste.
Com base em uma programação ou um gatilho, os pipelines de treinamento e validação treinam e validam um novo modelo usando os conjuntos de dados gerados pelo pipeline de dados.
Quando o pipeline de validação confirma que o novo modelo não é pior do que o modelo de produção, ele é implantado.
Esse processo se repete continuamente.
Inatividade do modelo e frequência de treinamento
Quase todos os modelos ficam desatualizados. Alguns modelos ficam desatualizados mais rápido do que outros. Por exemplo, os modelos que recomendam roupas geralmente ficam desatualizados rapidamente porque as preferências dos consumidores mudam com frequência. Por outro lado, os modelos que identificam flores nunca ficam desatualizados. As características de identificação de uma flor permanecem estáveis.
A maioria dos modelos começa a ficar desatualizada imediatamente após a entrada em produção. Estabeleça uma frequência de treinamento que reflita a natureza dos seus dados. Se os dados forem dinâmicos, treine com frequência. Se for menos dinâmica, talvez não seja necessário treinar com tanta frequência.
Treine modelos antes que eles fiquem desatualizados. O treinamento antecipado oferece um buffer para resolver possíveis problemas, por exemplo, se os dados ou o pipeline de treinamento falhar ou se a qualidade do modelo for baixa.
Uma prática recomendada é treinar e implantar novos modelos diariamente. Assim como projetos de software comuns que têm um processo diário de build e lançamento, os pipelines de ML para treinamento e validação geralmente funcionam melhor quando executados diariamente.
Teste seu conhecimento
Pipeline de veiculação
O pipeline de exibição gera e entrega previsões de uma das duas maneiras: on-line ou off-line.
Previsões on-line. As previsões on-line acontecem em tempo real, normalmente enviando uma solicitação a um servidor on-line e retornando uma previsão. Por exemplo, quando um usuário quer uma previsão, os dados dele são enviados ao modelo, que retorna a previsão.
Previsões off-line. As previsões off-line são pré-computadas e armazenadas em cache. Para disponibilizar uma previsão, o app encontra a previsão em cache no banco de dados e a retorna. Por exemplo, um serviço baseado em assinatura pode prever a taxa de desistência dos assinantes. O modelo prevê a probabilidade de desistência para cada assinante e a armazena em cache. Quando o app precisa da previsão, por exemplo, para incentivar usuários que podem estar prestes a desistir, ele apenas procura a previsão pré-calculada.
A Figura 5 mostra como as previsões on-line e off-line são geradas e entregues.
Previsões on-line e off-line
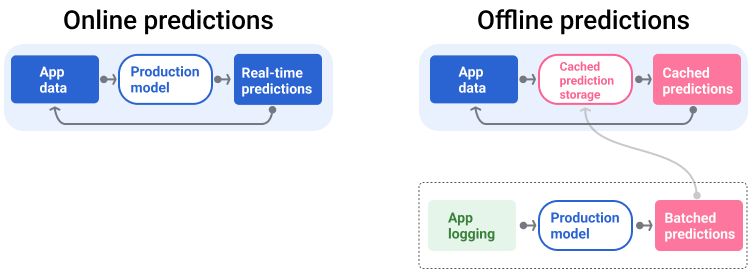
Figura 5. As previsões on-line são feitas em tempo real. As previsões off-line são armazenadas em cache e pesquisadas no momento da veiculação.
Pós-processamento de previsão
Normalmente, as previsões são pós-processadas antes da entrega. Por exemplo, as previsões podem ser pós-processadas para remover conteúdo tóxico ou tendencioso. Os resultados da classificação podem passar por um processo para reordenar os resultados em vez de mostrar a saída bruta do modelo, por exemplo, para impulsionar conteúdo mais confiável, apresentar uma diversidade de resultados, rebaixar resultados específicos (como clickbait) ou remover resultados por motivos legais.
A Figura 6 mostra um pipeline de exibição e as tarefas típicas envolvidas na entrega de previsões.
Previsões de pós-processamento
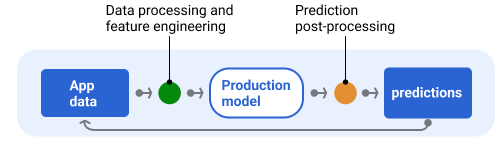
Figura 6. Pipeline de exibição ilustrando as tarefas típicas envolvidas para entregar previsões.
A etapa de engenharia de recursos geralmente é criada no modelo, não como um processo separado e independente. O código de processamento de dados no pipeline de serviço geralmente é quase idêntico ao código de processamento de dados que o pipeline de dados usa para criar conjuntos de dados de treinamento e teste.
Armazenamento de recursos e metadados
O pipeline de exibição precisa incorporar um repositório para registrar as previsões do modelo e, se possível, as informações empíricas.
O registro em log das previsões do modelo permite monitorar a qualidade dele. Ao agregar previsões, você pode monitorar a qualidade geral do modelo e determinar se ele está começando a perder qualidade. Em geral, as previsões do modelo de produção precisam ter a mesma média que os rótulos do conjunto de dados de treinamento. Para mais informações, consulte vício de previsão.
Capturar informações empíricas
Em alguns casos, a variável de verdade só fica disponível muito depois. Por exemplo, se um app de clima prevê o tempo para seis semanas no futuro, a verdade fundamental (como o clima realmente está) não estará disponível por seis semanas.
Quando possível, peça aos usuários para informar a verdade fundamental adicionando mecanismos de feedback ao app. Um app de e-mail pode capturar implicitamente o feedback do usuário quando ele move e-mails da caixa de entrada para a pasta de spam. No entanto, isso só funciona quando o usuário categoriza corretamente o e-mail. Quando os usuários deixam spam na caixa de entrada (porque sabem que é spam e nunca abrem), os dados de treinamento ficam imprecisos. Essa correspondência específica será rotulada como "não é spam" quando deveria ser "spam". Em outras palavras, sempre tente encontrar maneiras de capturar e registrar as informações empíricas, mas esteja ciente das deficiências que podem existir nos mecanismos de feedback.
A Figura 7 mostra as previsões sendo entregues a um usuário e registradas em um repositório.
Como gerar registros de previsões
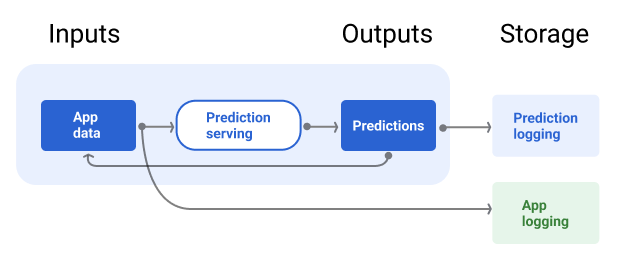
Figura 7. Registrar previsões para monitorar a qualidade do modelo.
Pipelines de dados
Os pipelines de dados geram conjuntos de dados de treinamento e teste com base nos dados do aplicativo. Os pipelines de treinamento e validação usam os conjuntos de dados para treinar e validar novos modelos.
O pipeline de dados cria conjuntos de dados de treinamento e teste com os mesmos recursos e rótulo usados originalmente para treinar o modelo, mas com informações mais recentes. Por exemplo, um app de mapas geraria conjuntos de dados de treinamento e teste com base nos tempos de viagem recentes entre pontos para milhões de usuários, além de outros dados relevantes, como o clima.
Um app de recomendação de vídeos geraria conjuntos de dados de treinamento e teste que incluíssem os vídeos em que um usuário clicou na lista de recomendados (junto com os que não foram clicados), além de outros dados relevantes, como o histórico de exibição.
A Figura 8 ilustra o pipeline de dados usando dados de aplicativos para gerar conjuntos de dados de treinamento e teste.
Pipeline de dados
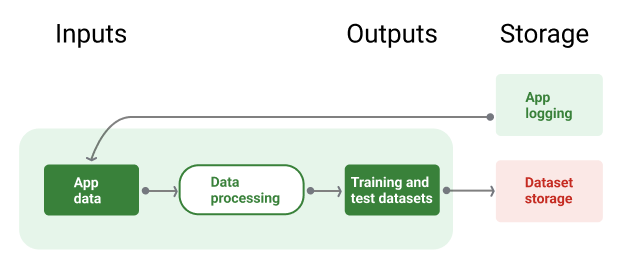
Figura 8. O pipeline de dados processa dados de aplicativos para criar conjuntos de dados para os pipelines de treinamento e validação.
Coleta e tratamento de dados
As tarefas de coleta e processamento de dados em pipelines de dados provavelmente serão diferentes da fase de experimentação (em que você determinou que sua solução era viável):
Coleta de dados. Durante a experimentação, a coleta de dados geralmente exige o acesso a dados salvos. Para pipelines de dados, a coleta pode exigir a descoberta e a aprovação para acessar dados de registros de streaming.
Se você precisar de dados rotulados por humanos (como imagens médicas), também vai precisar de um processo para coletar e atualizar esses dados.
Tratamento de dados. Durante a experimentação, os recursos certos vieram da raspagem, da junção e da amostragem dos conjuntos de dados de experimentação. Para os pipelines de dados, gerar esses mesmos recursos pode exigir processos completamente diferentes. No entanto, duplique as transformações de dados da fase de experimentação aplicando as mesmas operações matemáticas aos recursos e rótulos.
Armazenamento de recursos e metadados
Você vai precisar de um processo para armazenar, controlar versões e gerenciar seus conjuntos de dados de treinamento e teste. Os repositórios com controle de versões oferecem os seguintes benefícios:
Reprodutibilidade. Recrie e padronize ambientes de treinamento de modelos e compare a qualidade da previsão entre diferentes modelos.
Conformidade. Obedeça aos requisitos de conformidade regulatória para auditabilidade e transparência.
Retenção. Defina os valores de retenção de dados para determinar por quanto tempo eles serão armazenados.
Gerenciamento de acesso. Gerencie quem pode acessar seus dados com permissões granulares.
Integridade dos dados. Acompanhe e entenda as mudanças nos conjuntos de dados ao longo do tempo, facilitando o diagnóstico de problemas com seus dados ou seu modelo.
Capacidade de descoberta. Facilite para que outras pessoas encontrem seus conjuntos de dados e recursos. Outras equipes podem determinar se eles seriam úteis para os propósitos delas.
Documentar seus dados
Uma boa documentação ajuda outras pessoas a entender informações importantes sobre seus dados, como tipo, origem, tamanho e outros metadados essenciais. Na maioria dos casos, documentar seus dados em um documento de design é suficiente. Se você planeja compartilhar ou publicar seus dados, use cards de dados para estruturar as informações. Com os cards de dados, fica mais fácil para outras pessoas descobrirem e entenderem seus conjuntos de dados.
Pipelines de treinamento e validação
Os pipelines de treinamento e validação produzem novos modelos para substituir os de produção antes que eles fiquem obsoletos. O treinamento e a validação contínuos de novos modelos garantem que o melhor modelo esteja sempre em produção.
O pipeline de treinamento gera um novo modelo com base nos conjuntos de dados de treinamento, e o pipeline de validação compara a qualidade do novo modelo com o que está em produção usando conjuntos de dados de teste.
A Figura 9 ilustra o pipeline de treinamento usando um conjunto de dados para treinar um novo modelo.
Pipeline de treinamento
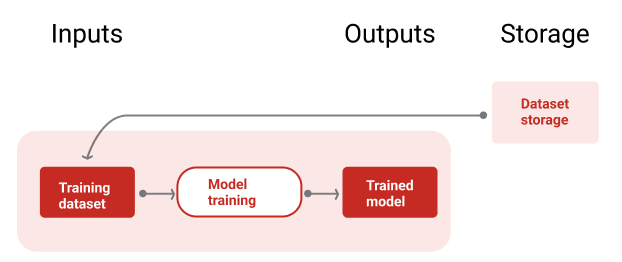
Figura 9. O pipeline de treinamento treina novos modelos usando o conjunto de dados de treinamento mais recente.
Depois que o modelo é treinado, o pipeline de validação usa conjuntos de dados de teste para comparar a qualidade do modelo de produção com o modelo treinado.
Em geral, se o modelo treinado não for significativamente pior do que o modelo de produção, ele será colocado em produção. Se o modelo treinado for pior, a infraestrutura de monitoramento vai criar um alerta. Modelos treinados com qualidade de previsão pior podem indicar possíveis problemas com os pipelines de dados ou validação. Essa abordagem garante que o melhor modelo, treinado com os dados mais recentes, esteja sempre em produção.
Armazenamento de recursos e metadados
Os modelos e os metadados precisam ser armazenados em repositórios com controle de versões para organizar e rastrear implantações de modelos. Os repositórios de modelos oferecem os seguintes benefícios:
Acompanhamento e avaliação. Acompanhe os modelos em produção e entenda as métricas de qualidade de avaliação e previsão.
Processo de lançamento de modelos. Revise, aprove, lance ou reverta modelos com facilidade.
Reprodutibilidade e depuração. Reproduza resultados de modelos e depure problemas com mais eficiência rastreando os conjuntos de dados e as dependências de um modelo em todas as implantações.
Capacidade de descoberta. Facilite a descoberta do seu modelo. Outras equipes podem determinar se o modelo (ou partes dele) pode ser usado para as finalidades delas.
A Figura 10 ilustra um modelo validado armazenado em um repositório de modelos.
Armazenamento de modelos
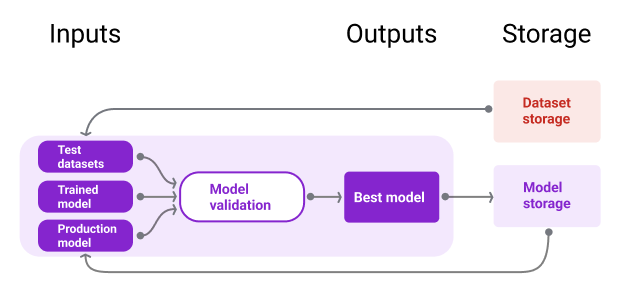
Figura 10. Os modelos validados são armazenados em um repositório para rastreamento e capacidade de descoberta.
Use cards de modelo para documentar e compartilhar informações importantes sobre seu modelo, como finalidade, arquitetura, requisitos de hardware, métricas de avaliação etc.
Teste seu conhecimento
Desafios na criação de pipelines
Ao criar pipelines, você pode enfrentar os seguintes desafios:
Acessar os dados necessários. O acesso a dados pode exigir uma justificativa. Por exemplo, talvez seja necessário explicar como os dados serão usados e esclarecer como os problemas de informações de identificação pessoal (PII) serão resolvidos. Prepare-se para mostrar uma prova de conceito demonstrando como seu modelo faz previsões melhores com acesso a determinados tipos de dados.
Como usar os recursos certos. Em alguns casos, os recursos usados na fase de experimentação não estarão disponíveis nos dados em tempo real. Portanto, ao fazer testes, tente confirmar que você poderá ter os mesmos recursos em produção.
Entender como os dados são coletados e representados. Aprender como os dados foram coletados, quem os coletou e como eles foram coletados (além de outros problemas) pode levar tempo e esforço. É importante entender os dados completamente. Não use dados em que você não confia para treinar um modelo que possa entrar em produção.
Entender as compensações entre esforço, custo e qualidade do modelo. Incorporar um novo recurso a um pipeline de dados pode exigir muito esforço. No entanto, o atributo adicional pode melhorar apenas um pouco a qualidade do modelo. Em outros casos, adicionar um novo recurso pode ser fácil. No entanto, os recursos para receber e armazenar o recurso podem ser muito caros.
Como conseguir computação. Se você precisar de TPUs para retreinamento, talvez seja difícil conseguir a cota necessária. Além disso, o gerenciamento de TPUs é complicado. Por exemplo, algumas partes do modelo ou dos dados podem precisar ser projetadas especificamente para TPUs dividindo partes delas em vários chips de TPU.
Encontrar o conjunto de dados de referência certo. Se os dados mudam com frequência, pode ser difícil conseguir conjuntos de dados de ouro com rótulos consistentes e precisos.
Detectar esses tipos de problemas durante a experimentação economiza tempo. Por exemplo, não é bom desenvolver os melhores recursos e modelos apenas para descobrir que eles não são viáveis em produção. Portanto, tente confirmar o mais cedo possível que sua solução vai funcionar dentro das restrições de um ambiente de produção. É melhor gastar tempo verificando se uma solução funciona do que precisar voltar à fase de experimentação porque a fase de pipeline descobriu problemas insuperáveis.