Dalam ML produksi, tujuannya bukan untuk membangun satu model dan men-deploy-nya. Tujuannya adalah membangun pipeline otomatis untuk mengembangkan, menguji, dan men-deploy model dari waktu ke waktu. Mengapa? Seiring perubahan dunia, tren dalam data berubah, sehingga menyebabkan model dalam produksi menjadi usang. Model biasanya perlu dilatih ulang dengan data terbaru agar dapat terus memberikan prediksi berkualitas tinggi dalam jangka panjang. Dengan kata lain, Anda memerlukan cara untuk mengganti model yang sudah tidak berlaku dengan model yang baru.
Tanpa pipeline, mengganti model yang sudah tidak berlaku adalah proses yang rentan terhadap error. Misalnya, setelah model mulai memberikan prediksi yang buruk, seseorang harus mengumpulkan dan memproses data baru secara manual, melatih model baru, memvalidasi kualitasnya, lalu men-deploy-nya. Pipeline ML mengotomatiskan banyak proses berulang ini, sehingga pengelolaan dan pemeliharaan model menjadi lebih efisien dan andal.
Membangun pipeline
Pipeline ML mengatur langkah-langkah untuk membangun dan men-deploy model menjadi tugas yang ditentukan dengan baik. Pipeline memiliki salah satu dari dua fungsi: memberikan prediksi atau mengupdate model.
Menayangkan prediksi
Pipeline penayangan memberikan prediksi. Hal ini akan mengekspos model Anda ke dunia nyata, sehingga dapat diakses oleh pengguna Anda. Misalnya, saat pengguna menginginkan prediksi—seperti cuaca besok, atau berapa menit waktu yang dibutuhkan untuk pergi ke bandara, atau daftar video yang direkomendasikan—pipeline penayangan menerima dan memproses data pengguna, membuat prediksi, lalu memberikannya kepada pengguna.
Memperbarui model
Model cenderung menjadi tidak relevan segera setelah digunakan dalam produksi. Pada dasarnya, mereka membuat prediksi menggunakan informasi lama. Kumpulan data pelatihan mereka merekam status dunia sehari yang lalu, atau dalam beberapa kasus, satu jam yang lalu. Dunia telah berubah: pengguna telah menonton lebih banyak video dan memerlukan daftar rekomendasi baru; hujan telah menyebabkan lalu lintas melambat dan pengguna memerlukan perkiraan waktu kedatangan yang diperbarui; tren populer menyebabkan retailer meminta prediksi inventaris yang diperbarui untuk item tertentu.
Biasanya, tim melatih model baru jauh sebelum model produksi menjadi tidak relevan. Dalam beberapa kasus, tim melatih dan men-deploy model baru setiap hari dalam siklus pelatihan dan deployment berkelanjutan. Idealnya, pelatihan model baru harus dilakukan jauh sebelum model produksi menjadi tidak relevan.
Pipeline berikut bekerja sama untuk melatih model baru:
- Pipeline data. Pipeline data memproses data pengguna untuk membuat set data pelatihan dan pengujian.
- Pipeline pelatihan. Pipeline pelatihan melatih model menggunakan set data pelatihan baru dari pipeline data.
- Pipeline validasi. Pipeline validasi memvalidasi model terlatih dengan membandingkannya dengan model produksi menggunakan set data pengujian yang dihasilkan oleh pipeline data.
Gambar 4 menggambarkan input dan output setiap pipeline ML.
Pipeline ML
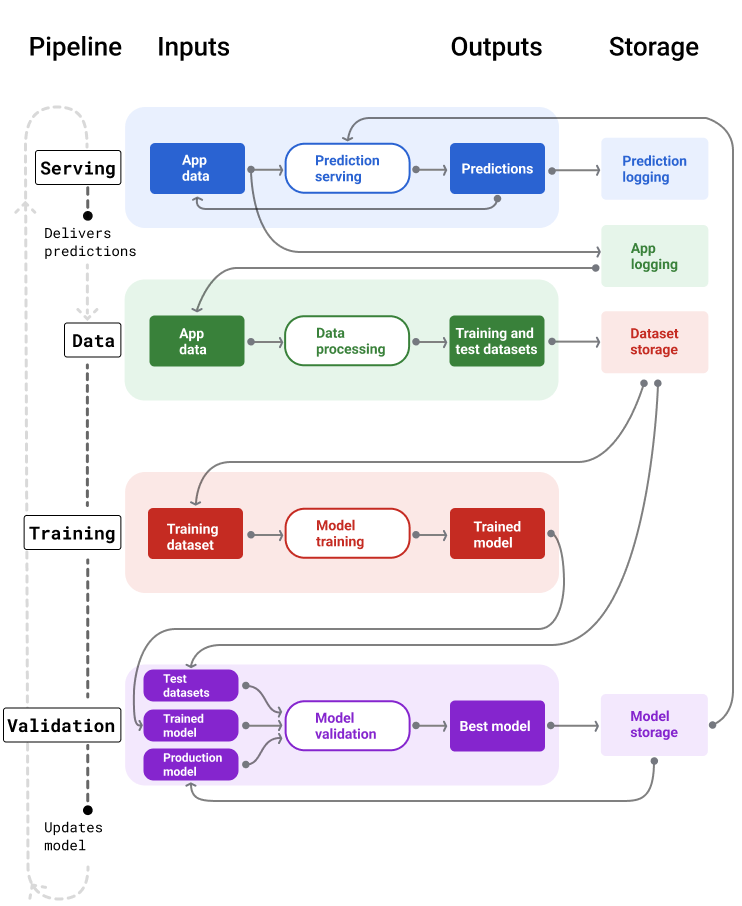
Gambar 4. Pipeline ML mengotomatiskan banyak proses untuk mengembangkan dan memelihara model. Setiap pipeline menampilkan input dan outputnya.
Pada tingkat yang sangat umum, berikut cara agar pipeline mempertahankan model baru dalam produksi:
Pertama, model masuk ke produksi, dan pipeline penayangan mulai memberikan prediksi.
Pipeline data akan segera mulai mengumpulkan data untuk membuat set data pelatihan dan pengujian baru.
Berdasarkan jadwal atau pemicu, pipeline pelatihan dan validasi melatih dan memvalidasi model baru menggunakan set data yang dihasilkan oleh pipeline data.
Saat pipeline validasi mengonfirmasi bahwa model baru tidak lebih buruk daripada model produksi, model baru akan di-deploy.
Proses ini berulang terus-menerus.
Data model yang tidak berlaku dan frekuensi pelatihan
Hampir semua model menjadi tidak valid. Beberapa model menjadi tidak relevan lebih cepat daripada yang lain. Misalnya, model yang merekomendasikan pakaian biasanya cepat menjadi tidak relevan karena preferensi konsumen terkenal sering berubah. Di sisi lain, model yang mengidentifikasi bunga mungkin tidak akan pernah menjadi usang. Karakteristik identifikasi bunga tetap stabil.
Sebagian besar model mulai menjadi tidak relevan segera setelah diterapkan ke produksi. Anda harus menetapkan frekuensi pelatihan yang mencerminkan sifat data Anda. Jika data bersifat dinamis, lakukan pelatihan secara rutin. Jika kurang dinamis, Anda mungkin tidak perlu sering melatihnya.
Latih model sebelum menjadi tidak valid. Pelatihan awal memberikan buffer untuk mengatasi potensi masalah, misalnya, jika data atau pipeline pelatihan gagal, atau kualitas model buruk.
Praktik terbaik yang direkomendasikan adalah melatih dan men-deploy model baru setiap hari. Sama seperti project software biasa yang memiliki proses build dan rilis harian, pipeline ML untuk pelatihan dan validasi sering kali berfungsi paling baik jika dijalankan setiap hari.
Periksa Pemahaman Anda
Pipeline penayangan
Pipeline penayangan menghasilkan dan mengirimkan prediksi dengan salah satu dari dua cara: online atau offline.
Prediksi online. Prediksi online terjadi secara real time, biasanya dengan mengirim permintaan ke server online dan menampilkan prediksi. Misalnya, saat pengguna menginginkan prediksi, data pengguna dikirim ke model dan model akan menampilkan prediksi.
Prediksi offline. Prediksi offline telah dihitung sebelumnya dan di-cache. Untuk menyajikan prediksi, aplikasi menemukan prediksi yang di-cache dalam database dan menampilkannya. Misalnya, layanan berbasis langganan dapat memprediksi rasio penghentian langganan pelanggannya. Model memprediksi kemungkinan churn untuk setiap pelanggan dan menyimpannya dalam cache. Saat aplikasi memerlukan prediksi—misalnya, untuk memberikan insentif kepada pengguna yang mungkin akan berhenti menggunakan aplikasi—aplikasi hanya akan mencari prediksi yang telah dihitung sebelumnya.
Gambar 5 menunjukkan cara prediksi online dan offline dibuat dan ditayangkan.
Prediksi online dan offline
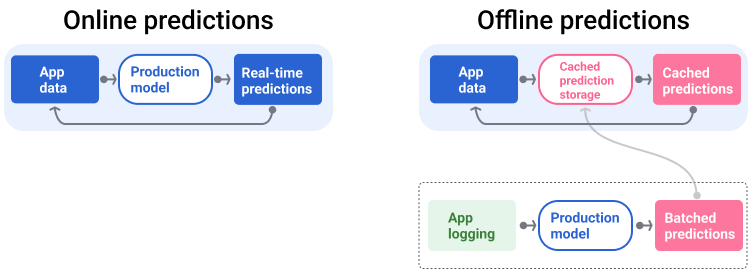
Gambar 5. Prediksi online memberikan prediksi secara real time. Prediksi offline di-cache dan dicari pada waktu penayangan.
Pasca-pemrosesan prediksi
Biasanya, prediksi diproses lebih lanjut sebelum dikirim. Misalnya, prediksi dapat diproses pasca-pemrosesan untuk menghapus konten yang tidak baik atau bias. Hasil klasifikasi mungkin melalui proses untuk mengurutkan ulang hasil, bukan menampilkan output mentah model, misalnya, untuk meningkatkan konten yang lebih kredibel, menyajikan beragam hasil, menurunkan hasil tertentu (seperti clickbait), atau menghapus hasil karena alasan hukum.
Gambar 6 menunjukkan pipeline penayangan dan tugas umum yang terlibat dalam memberikan prediksi.
Prediksi pasca-pemrosesan
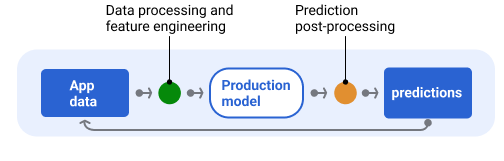
Gambar 6. Pipeline penayangan yang menggambarkan tugas umum yang terlibat untuk memberikan prediksi.
Perhatikan bahwa langkah rekayasa fitur biasanya dibuat dalam model dan bukan proses terpisah yang mandiri. Kode pemrosesan data di pipeline penayangan sering kali hampir identik dengan kode pemrosesan data yang digunakan pipeline data untuk membuat set data pelatihan dan pengujian.
Penyimpanan aset dan metadata
Pipeline penayangan harus menyertakan repositori untuk mencatat prediksi model dan, jika memungkinkan, kebenaran dasar.
Dengan mencatat prediksi model, Anda dapat memantau kualitas model. Dengan menggabungkan prediksi, Anda dapat memantau kualitas umum model dan menentukan apakah kualitasnya mulai menurun. Umumnya, prediksi model produksi harus memiliki rata-rata yang sama dengan label dari set data pelatihan. Untuk mengetahui informasi selengkapnya, lihat bias prediksi.
Merekam kebenaran dasar
Dalam beberapa kasus, kebenaran dasar baru tersedia jauh kemudian. Misalnya, jika aplikasi cuaca memprediksi cuaca enam minggu ke depan, kebenaran dasarnya (cuaca sebenarnya) tidak akan tersedia selama enam minggu.
Jika memungkinkan, minta pengguna melaporkan data sebenarnya dengan menambahkan mekanisme masukan ke dalam aplikasi. Aplikasi email dapat secara implisit merekam masukan pengguna saat pengguna memindahkan email dari kotak masuk ke folder spam. Namun, fitur ini hanya berfungsi jika pengguna mengategorikan email mereka dengan benar. Jika pengguna membiarkan spam di kotak masuk mereka (karena mereka tahu itu adalah spam dan tidak pernah membukanya), data pelatihan akan menjadi tidak akurat. Email tertentu tersebut akan diberi label "bukan spam" padahal seharusnya "spam". Dengan kata lain, selalu coba temukan cara untuk merekam dan mencatat data sebenarnya, tetapi ketahui kekurangan yang mungkin ada dalam mekanisme masukan.
Gambar 7 menunjukkan prediksi yang dikirimkan kepada pengguna dan dicatat ke repositori.
Mencatat prediksi
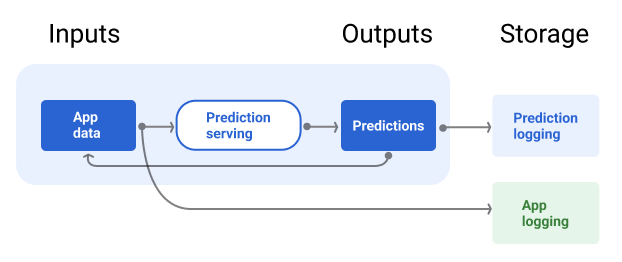
Gambar 7. Mencatat prediksi untuk memantau kualitas model.
Data Pipelines
Pipeline data menghasilkan set data pelatihan dan pengujian dari data aplikasi. Pipeline pelatihan dan validasi kemudian menggunakan set data untuk melatih dan memvalidasi model baru.
Pipeline data membuat set data pelatihan dan pengujian dengan fitur dan label yang sama yang awalnya digunakan untuk melatih model, tetapi dengan informasi yang lebih baru. Misalnya, aplikasi peta akan membuat set data pelatihan dan pengujian dari waktu tempuh terbaru antar-titik untuk jutaan pengguna, beserta data relevan lainnya, seperti cuaca.
Aplikasi rekomendasi video akan membuat set data pelatihan dan pengujian yang mencakup video yang diklik pengguna dari daftar rekomendasi (bersama dengan video yang tidak diklik), serta data relevan lainnya, seperti histori tontonan.
Gambar 8 mengilustrasikan pipeline data menggunakan data aplikasi untuk membuat set data pelatihan dan pengujian.
Pipeline data
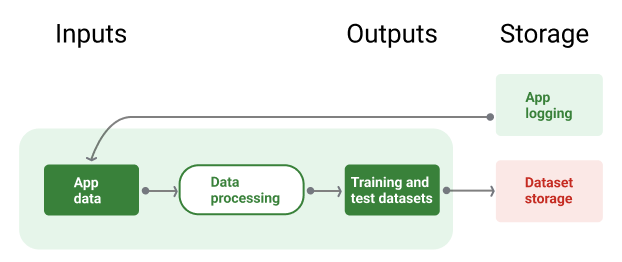
Gambar 8. Pipeline data memproses data aplikasi untuk membuat set data bagi pipeline pelatihan dan validasi.
Pengumpulan dan pemrosesan data
Tugas untuk mengumpulkan dan memproses data di pipeline data mungkin berbeda dengan fase eksperimen (tempat Anda menentukan bahwa solusi Anda layak):
Pengumpulan data. Selama eksperimen, pengumpulan data biasanya memerlukan akses ke data tersimpan. Untuk pipeline data, pengumpulan data mungkin memerlukan penemuan dan mendapatkan persetujuan untuk mengakses data log streaming.
Jika Anda memerlukan data berlabel manual (seperti gambar medis), Anda juga memerlukan proses untuk mengumpulkan dan memperbaruinya.
Pemrosesan data. Selama eksperimen, fitur yang tepat berasal dari scraping, penggabungan, dan pengambilan sampel set data eksperimen. Untuk pipeline data, pembuatan fitur yang sama mungkin memerlukan proses yang sama sekali berbeda. Namun, pastikan untuk menduplikasi transformasi data dari fase eksperimen dengan menerapkan operasi matematika yang sama ke fitur dan label.
Penyimpanan aset dan metadata
Anda memerlukan proses untuk menyimpan, membuat versi, dan mengelola set data pelatihan dan pengujian. Repositori yang dikontrol versinya memberikan manfaat berikut:
Reproduksibilitas. Buat ulang dan standarisasi lingkungan pelatihan model serta bandingkan kualitas prediksi di antara berbagai model.
Kepatuhan. Mematuhi persyaratan kepatuhan terhadap peraturan untuk auditabilitas dan transparansi.
Retensi. Tetapkan nilai retensi data untuk durasi penyimpanan data.
Pengelolaan akses. Kelola siapa yang dapat mengakses data Anda melalui izin yang sangat terperinci.
Integritas data. Lacak dan pahami perubahan pada set data dari waktu ke waktu, sehingga lebih mudah mendiagnosis masalah pada data atau model Anda.
Visibilitas. Permudah orang lain menemukan set data dan fitur Anda. Tim lain kemudian dapat menentukan apakah fitur tersebut berguna untuk tujuan mereka.
Mendokumentasikan data Anda
Dokumentasi yang baik membantu orang lain memahami informasi penting tentang data Anda, seperti jenis, sumber, ukuran, dan metadata penting lainnya. Dalam sebagian besar kasus, mendokumentasikan data Anda dalam dokumen desain sudah cukup. Jika Anda berencana membagikan atau memublikasikan data, gunakan kartu data untuk menyusun informasi. Kartu data memudahkan orang lain menemukan dan memahami set data Anda.
Pipeline pelatihan dan validasi
Pipeline pelatihan dan validasi menghasilkan model baru untuk menggantikan model produksi sebelum model tersebut menjadi tidak berlaku. Melatih dan memvalidasi model baru secara berkelanjutan memastikan model terbaik selalu dalam produksi.
Pipeline pelatihan menghasilkan model baru dari set data pelatihan, dan pipeline validasi membandingkan kualitas model baru dengan model dalam produksi menggunakan set data pengujian.
Gambar 9 mengilustrasikan pipeline pelatihan menggunakan set data pelatihan untuk melatih model baru.
Pipeline pelatihan
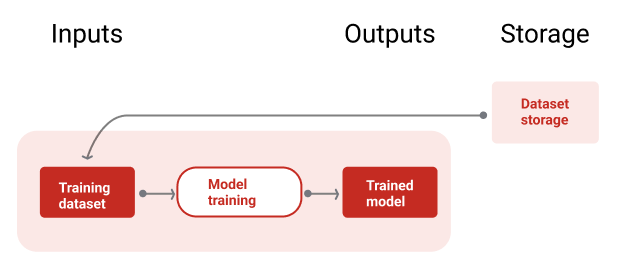
Gambar 9. Pipeline pelatihan melatih model baru menggunakan set data pelatihan terbaru.
Setelah model dilatih, pipeline validasi menggunakan set data pengujian untuk membandingkan kualitas model produksi dengan model yang dilatih.
Secara umum, jika model terlatih tidak jauh lebih buruk daripada model produksi, model terlatih akan masuk ke produksi. Jika model terlatih lebih buruk, infrastruktur pemantauan harus membuat pemberitahuan. Model terlatih dengan kualitas prediksi yang lebih buruk dapat menunjukkan potensi masalah pada data atau pipeline validasi. Pendekatan ini berfungsi untuk memastikan model terbaik, yang dilatih berdasarkan data terbaru, selalu dalam produksi.
Penyimpanan aset dan metadata
Model dan metadatanya harus disimpan di repositori yang diberi versi untuk mengatur dan melacak deployment model. Repositori model memberikan manfaat berikut:
Pelacakan dan evaluasi. Lacak model dalam produksi dan pahami metrik kualitas evaluasi dan prediksinya.
Proses rilis model. Tinjau, setujui, rilis, atau kembalikan model dengan mudah.
Reproduksibilitas dan proses debug. Mereproduksi hasil model dan men-debug masalah secara lebih efektif dengan melacak set data dan dependensi model di seluruh deployment.
Visibilitas. Permudah orang lain menemukan model Anda. Tim lain kemudian dapat menentukan apakah model Anda (atau sebagian model) dapat digunakan untuk tujuan mereka.
Gambar 10 mengilustrasikan model yang divalidasi dan disimpan di repositori model.
Penyimpanan model
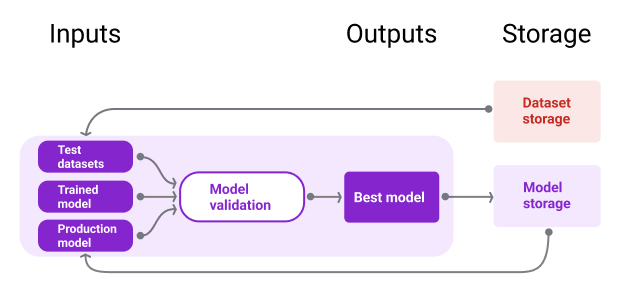
Gambar 10. Model yang divalidasi disimpan di repositori model untuk pelacakan dan penemuan.
Gunakan kartu model untuk mendokumentasikan dan membagikan informasi penting tentang model Anda, seperti tujuan, arsitektur, persyaratan hardware, metrik evaluasi, dll.
Periksa Pemahaman Anda
Tantangan dalam membangun pipeline
Saat membangun pipeline, Anda mungkin menghadapi tantangan berikut:
Mendapatkan akses ke data yang Anda butuhkan. Akses data mungkin memerlukan pembenaran mengapa Anda memerlukannya. Misalnya, Anda mungkin perlu menjelaskan cara data akan digunakan dan mengklarifikasi cara masalah informasi identitas pribadi (PII) akan diselesaikan. Bersiaplah untuk menunjukkan bukti konsep yang mendemonstrasikan cara model Anda membuat prediksi yang lebih baik dengan akses ke jenis data tertentu.
Mendapatkan fitur yang tepat. Dalam beberapa kasus, fitur yang digunakan dalam fase eksperimen tidak akan tersedia dari data real-time. Oleh karena itu, saat bereksperimen, coba konfirmasi bahwa Anda akan bisa mendapatkan fitur yang sama dalam produksi.
Memahami cara data dikumpulkan dan ditampilkan. Mempelajari cara data dikumpulkan, siapa yang mengumpulkannya, dan bagaimana data tersebut dikumpulkan (bersama dengan masalah lainnya) dapat memerlukan waktu dan upaya. Penting untuk memahami data secara menyeluruh. Jangan gunakan data yang tidak Anda yakini untuk melatih model yang mungkin akan digunakan dalam produksi.
Memahami penyesuaian antara upaya, biaya, dan kualitas model. Menggabungkan fitur baru ke dalam pipeline data dapat memerlukan banyak upaya. Namun, fitur tambahan tersebut mungkin hanya sedikit meningkatkan kualitas model. Dalam kasus lain, menambahkan fitur baru mungkin mudah. Namun, resource untuk mendapatkan dan menyimpan fitur tersebut mungkin sangat mahal.
Mendapatkan compute. Jika Anda memerlukan TPU untuk melatih ulang model, mungkin sulit untuk mendapatkan kuota yang diperlukan. Selain itu, mengelola TPU juga rumit. Misalnya, beberapa bagian model atau data Anda mungkin perlu dirancang khusus untuk TPU dengan membagi bagian-bagiannya di beberapa chip TPU.
Menemukan set data keemasan yang tepat. Jika data sering berubah, mendapatkan set data standar dengan label yang konsisten dan akurat bisa menjadi tantangan.
Menemukan jenis masalah ini selama eksperimen akan menghemat waktu. Misalnya, Anda tidak ingin mengembangkan fitur dan model terbaik hanya untuk mengetahui bahwa fitur dan model tersebut tidak layak dalam produksi. Oleh karena itu, cobalah untuk mengonfirmasi sedini mungkin bahwa solusi Anda akan berfungsi dalam batasan lingkungan produksi. Lebih baik menghabiskan waktu untuk memverifikasi bahwa solusi berfungsi daripada harus kembali ke fase eksperimen karena fase pipeline menemukan masalah yang tidak dapat diatasi.