W produkcyjnym ML nie chodzi o utworzenie jednego modelu i jego wdrożenie. Celem jest stworzenie zautomatyzowanych potoków do opracowywania, testowania i wdrażania modeli w czasie. Dlaczego? Świat się zmienia, a trendy w danych ulegają przesunięciu, co powoduje, że modele wdrożone w produkcji stają się nieaktualne. Aby modele mogły nadal dostarczać wysokiej jakości prognozy w dłuższej perspektywie, zwykle wymagają ponownego trenowania z użyciem aktualnych danych. Innymi słowy, musisz mieć możliwość zastępowania nieaktualnych modeli nowymi.
Bez potoków zastąpienie nieaktualnego modelu jest procesem podatnym na błędy. Gdy na przykład model zacznie generować nieprawidłowe prognozy, ktoś będzie musiał ręcznie zebrać i przetworzyć nowe dane, wytrenować nowy model, sprawdzić jego jakość, a następnie go wdrożyć. Potoki ML automatyzują wiele z tych powtarzalnych procesów, dzięki czemu zarządzanie modelami i ich utrzymywanie jest bardziej wydajne i niezawodne.
Tworzenie potoków
Potoki ML porządkują kroki tworzenia i wdrażania modeli w dobrze zdefiniowane zadania. Potoki mają jedną z 2 funkcji: dostarczanie prognoz lub aktualizowanie modelu.
Dostarczanie prognoz
Potok obsługi dostarcza prognozy. Udostępnia on model w rzeczywistym świecie, dzięki czemu jest on dostępny dla użytkowników. Jeśli na przykład użytkownik chce uzyskać prognozę pogody na jutro, dowiedzieć się, ile czasu zajmie mu dojazd na lotnisko, lub otrzymać listę polecanych filmów, potok obsługi otrzymuje i przetwarza dane użytkownika, tworzy prognozę, a następnie dostarcza ją użytkownikowi.
Aktualizowanie modelu
Modele zwykle tracą aktualność niemal natychmiast po wdrożeniu. W zasadzie dokonują prognoz na podstawie starych informacji. Zbiory danych używane do trenowania tych modeli odzwierciedlają stan świata sprzed dnia lub, w niektórych przypadkach, sprzed godziny. Świat się zmienia: użytkownik obejrzał więcej filmów i potrzebuje nowej listy rekomendacji; deszcz spowodował spowolnienie ruchu, więc użytkownicy potrzebują zaktualizowanych szacunków czasu przyjazdu; popularny trend sprawia, że sprzedawcy detaliczni proszą o zaktualizowane prognozy dotyczące zapasów określonych produktów.
Zespoły zwykle trenują nowe modele na długo przed tym, zanim model produkcyjny stanie się nieaktualny. W niektórych przypadkach zespoły trenują i wdrażają nowe modele codziennie w ramach ciągłego cyklu trenowania i wdrażania. Najlepiej wytrenować nowy model na długo przed tym, zanim model produkcyjny stanie się nieaktualny.
Te potoki współpracują ze sobą, aby wytrenować nowy model:
- Potok danych Potok danych przetwarza dane użytkowników, aby utworzyć zbiory danych szkoleniowych i testowych.
- Potok trenowania. Potok trenowania trenuje modele przy użyciu nowych zbiorów danych treningowych z potoku danych.
- Potok weryfikacji Potok weryfikacyjny weryfikuje wytrenowany model, porównując go z modelem produkcyjnym za pomocą testowych zbiorów danych wygenerowanych przez potok danych.
Rysunek 4 przedstawia dane wejściowe i wyjściowe każdego potoku ML.
Potoki ML
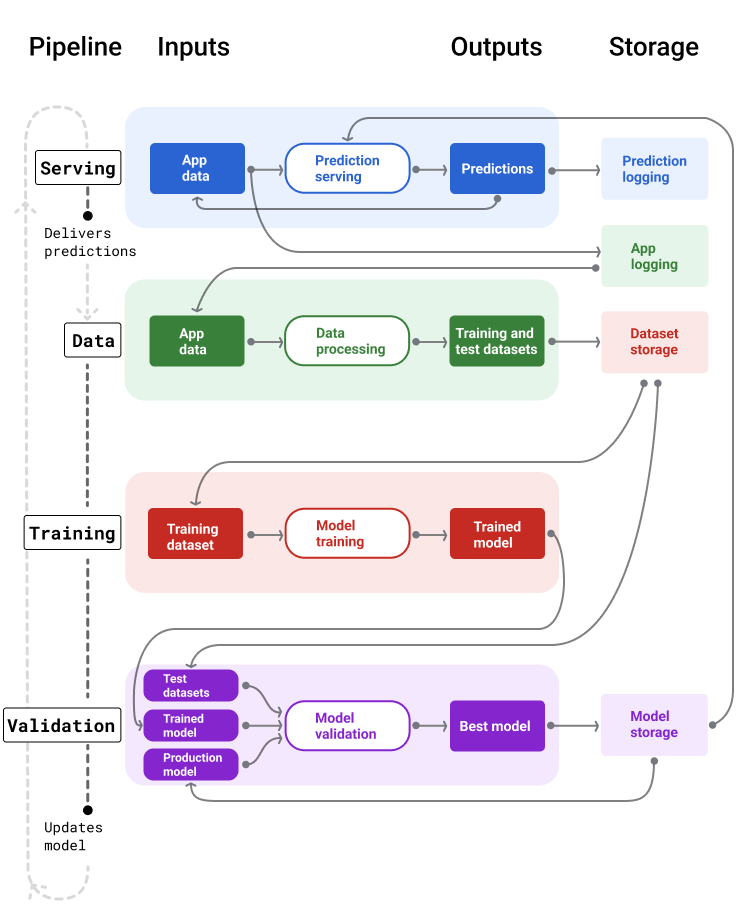
Rysunek 4. Potoki ML automatyzują wiele procesów związanych z opracowywaniem i utrzymywaniem modeli. Każdy potok pokazuje swoje dane wejściowe i wyjściowe.
Ogólnie rzecz biorąc, potoki utrzymują aktualny model w środowisku produkcyjnym w ten sposób:
Najpierw model trafia do środowiska produkcyjnego, a potem potok obsługi zaczyna dostarczać prognozy.
Potok danych od razu rozpoczyna zbieranie danych, aby wygenerować nowe zbiory danych treningowych i testowych.
Na podstawie harmonogramu lub wyzwalacza potoki trenowania i weryfikacji trenują i weryfikują nowy model przy użyciu zbiorów danych wygenerowanych przez potok danych.
Gdy potok weryfikacji potwierdzi, że nowy model nie jest gorszy od modelu produkcyjnego, zostanie on wdrożony.
Ten proces powtarza się w nieskończoność.
Nieaktualność modelu i częstotliwość trenowania
Prawie wszystkie modele stają się nieaktualne. Niektóre modele szybciej się dezaktualizują. Na przykład modele, które rekomendują ubrania, szybko stają się nieaktualne, ponieważ preferencje konsumentów często się zmieniają. Z drugiej strony modele, które rozpoznają kwiaty, mogą nigdy się nie zestarzeć. Cechy identyfikacyjne kwiatu pozostają niezmienne.
Większość modeli zaczyna się starzeć natychmiast po wdrożeniu. Ustal częstotliwość trenowania, która odzwierciedla charakter Twoich danych. Jeśli dane są dynamiczne, trenuj często. Jeśli jest mniej dynamiczny, nie musisz go tak często trenować.
Trenuj modele, zanim staną się nieaktualne. Wczesne trenowanie zapewnia bufor na wypadek potencjalnych problemów, np. gdy dane lub potok trenowania ulegną awarii albo jakość modelu będzie niska.
Zalecamy trenowanie i wdrażanie nowych modeli codziennie. Podobnie jak w przypadku zwykłych projektów oprogramowania, w których codziennie tworzy się kompilacje i wersje, potoki ML do trenowania i weryfikacji często działają najlepiej, gdy są uruchamiane codziennie.
Sprawdź swoją wiedzę
Potok obsługi
Potok obsługi generuje i dostarcza prognozy na 2 sposoby: online lub offline.
Podpowiedzi online Prognozowanie online odbywa się w czasie rzeczywistym, zwykle poprzez wysłanie żądania do serwera online i zwrócenie prognozy. Na przykład, gdy użytkownik chce uzyskać prognozę, jego dane są wysyłane do modelu, a model zwraca prognozę.
Prognozy offline Prognozy offline są wstępnie obliczane i zapisywane w pamięci podręcznej. Aby wyświetlić prognozę, aplikacja wyszukuje w bazie danych prognozę zapisaną w pamięci podręcznej i ją zwraca. Na przykład usługa oparta na subskrypcji może prognozować wskaźnik rezygnacji subskrybentów. Model przewiduje prawdopodobieństwo rezygnacji każdego subskrybenta i zapisuje je w pamięci podręcznej. Gdy aplikacja potrzebuje prognozy – np. aby zachęcić użytkowników, którzy mogą zrezygnować z usługi – wystarczy, że wyszuka wstępnie obliczoną prognozę.
Na rysunku 5 widać, jak generowane i dostarczane są prognozy online i offline.
Prognozy online i offline
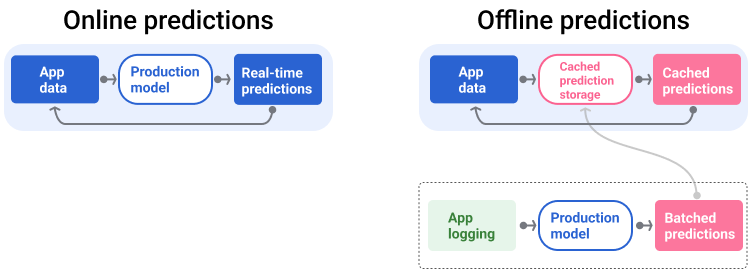
Rysunek 5. Prognozowanie online zapewnia prognozy w czasie rzeczywistym. Prognozy offline są zapisywane w pamięci podręcznej i wyszukiwane w momencie wyświetlania.
Przetwarzanie końcowe prognoz
Zazwyczaj prognozy są przetwarzane po ich wygenerowaniu, zanim zostaną dostarczone. Na przykład prognozy mogą być przetwarzane końcowo w celu usunięcia toksycznych lub stronniczych treści. Wyniki klasyfikacji mogą w celu zmiany kolejności wyników zamiast wyświetlania surowych danych wyjściowych modelu, np. aby promować bardziej wiarygodne treści, prezentować różnorodne wyniki, obniżać pozycję określonych wyników (np. clickbaitu) lub usuwać wyniki z przyczyn prawnych.
Ilustracja 6 przedstawia potok obsługi i typowe zadania związane z dostarczaniem prognoz.
Przetwarzanie końcowe prognoz
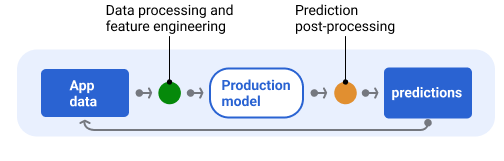
Rysunek 6. Potok obsługi ilustrujący typowe zadania związane z dostarczaniem prognoz.
Pamiętaj, że etap inżynierii cech jest zwykle wbudowany w model i nie jest oddzielnym, samodzielnym procesem. Kod przetwarzania danych w potoku udostępniania jest często niemal identyczny z kodem przetwarzania danych, którego potok danych używa do tworzenia zbiorów danych treningowych i testowych.
Przechowywanie zasobów i metadanych
Potok obsługi powinien zawierać repozytorium do rejestrowania prognoz modelu i, jeśli to możliwe, rzeczywistych wartości.
Logowanie prognoz modelu umożliwia monitorowanie jakości modelu. Dzięki agregowaniu prognoz możesz monitorować ogólną jakość modelu i sprawdzać, czy nie zaczyna się ona pogarszać. Ogólnie rzecz biorąc, prognozy modelu produkcyjnego powinny mieć taką samą średnią jak etykiety ze zbioru danych treningowych. Więcej informacji znajdziesz w artykule o obciążeniu prognozy.
Zbieranie danych podstawowych
W niektórych przypadkach prawdziwe dane stają się dostępne znacznie później. Jeśli na przykład aplikacja pogodowa prognozuje pogodę na 6 tygodni do przodu, rzeczywiste dane (czyli jaka będzie pogoda) nie będą dostępne przez 6 tygodni.
Jeśli to możliwe, zachęcaj użytkowników do zgłaszania rzeczywistych informacji, dodając do aplikacji mechanizmy opinii. Aplikacja poczty e-mail może niejawnie rejestrować opinie użytkowników, gdy przenoszą oni wiadomości ze skrzynki odbiorczej do folderu ze spamem. Działa to jednak tylko wtedy, gdy użytkownik prawidłowo kategoryzuje pocztę. Jeśli użytkownicy pozostawiają spam w skrzynce odbiorczej (ponieważ wiedzą, że to spam i nigdy go nie otwierają), dane szkoleniowe stają się niedokładne. Taka wiadomość zostanie oznaczona jako „nie spam”, mimo że powinna być oznaczona jako „spam”. Innymi słowy, zawsze staraj się znaleźć sposoby na rejestrowanie danych podstawowych, ale pamiętaj o niedoskonałościach, które mogą występować w mechanizmach opinii.
Ilustracja 7 przedstawia prognozy dostarczane użytkownikowi i zapisywane w repozytorium.
Rejestrowanie podpowiedzi
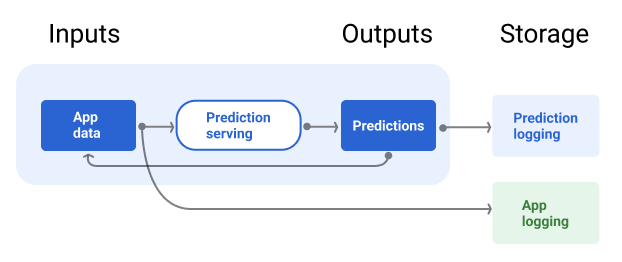
Rysunek 7. Rejestruj prognozy, aby monitorować jakość modelu.
Potoki danych
Potoki danych generują z danych aplikacji zbiory danych treningowych i testowych. Potem potoki trenowania i weryfikacji używają zbiorów danych do trenowania i weryfikowania nowych modeli.
Potok danych tworzy zbiory danych treningowych i testowych z tymi samymi cechami i etykietami, które były pierwotnie używane do trenowania modelu, ale z nowszymi informacjami. Na przykład aplikacja do map generuje zbiory danych treningowych i testowych na podstawie ostatnich czasów podróży między punktami dla milionów użytkowników oraz innych istotnych danych, takich jak pogoda.
Aplikacja do rekomendowania filmów generuje zbiory danych treningowych i testowych, które zawierają filmy, w które użytkownik kliknął na liście rekomendacji (oraz te, w które nie kliknął), a także inne istotne dane, takie jak historia oglądania.
Ilustracja 8 przedstawia potok danych wykorzystujący dane aplikacji do generowania zbiorów danych treningowych i testowych.
Potok danych
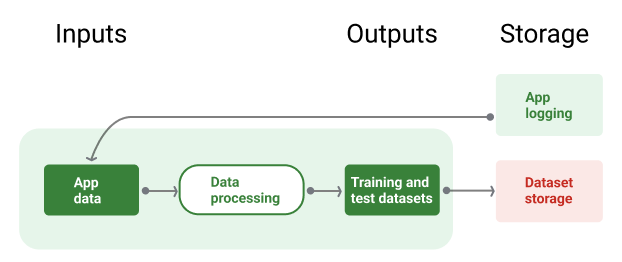
Rysunek 8. Potok danych przetwarza dane aplikacji, aby utworzyć zbiory danych dla potoków trenowania i weryfikacji.
Zbieranie i przetwarzanie danych
Zadania związane z zbieraniem i przetwarzaniem danych w potokach danych będą prawdopodobnie inne niż w fazie eksperymentowania (w której stwierdzono, że rozwiązanie jest wykonalne):
Zbieranie danych Podczas eksperymentowania zbieranie danych zwykle wymaga dostępu do zapisanych danych. W przypadku potoków danych zbieranie danych może wymagać wykrycia i uzyskania zgody na dostęp do danych logów przesyłanych strumieniowo.
Jeśli potrzebujesz danych oznaczonych przez ludzi (np. obrazów medycznych), musisz mieć też proces ich zbierania i aktualizowania.
Przetwarzanie danych Podczas eksperymentu odpowiednie cechy pochodziły z przetwarzania, łączenia i próbkowania zbiorów danych eksperymentalnych. W przypadku potoków danych generowanie tych samych funkcji może wymagać zupełnie innych procesów. Pamiętaj jednak, aby powielić przekształcenia danych z fazy eksperymentowania, stosując te same operacje matematyczne do cech i etykiet.
Przechowywanie zasobów i metadanych
Musisz mieć proces przechowywania, wersjonowania i zarządzania zbiorami danych treningowych i testowych. Repozytoria z kontrolą wersji zapewniają te korzyści:
Powtarzalność Odtwarzaj i standaryzuj środowiska trenowania modeli oraz porównuj jakość prognozowania w różnych modelach.
Zgodność z przepisami Przestrzegaj wymagań dotyczących zgodności z przepisami w zakresie możliwości audytu i przejrzystości.
Utrzymanie Ustaw wartości przechowywania danych, aby określić, jak długo mają być przechowywane dane.
Zarządzanie dostępem Zarządzaj tym, kto ma dostęp do Twoich danych, za pomocą szczegółowych uprawnień.
Integralność danych. śledzić i analizować zmiany w zbiorach danych na przestrzeni czasu, co ułatwia diagnozowanie problemów z danymi lub modelem;
Wykrywalność Ułatw innym znajdowanie Twoich zbiorów danych i funkcji. Inne zespoły mogą wtedy określić, czy będą one przydatne do ich celów.
Dokumentowanie danych
Dobra dokumentacja pomaga innym zrozumieć kluczowe informacje o Twoich danych, takie jak ich typ, źródło, rozmiar i inne istotne metadane. W większości przypadków wystarczy udokumentować dane w dokumencie projektowym . Jeśli planujesz udostępniać lub publikować dane, użyj kart danych, aby uporządkować informacje.Karty danych ułatwiają innym odkrywanie i zrozumienie Twoich zbiorów danych.
Potoki trenowania i walidacji
Potoki trenowania i weryfikacji tworzą nowe modele, które zastępują modele produkcyjne, zanim te się zestarzeją. Ciągłe trenowanie i weryfikowanie nowych modeli zapewnia, że w produkcji zawsze jest najlepszy model.
Potok trenowania generuje nowy model na podstawie zbiorów danych treningowych, a potok weryfikacji porównuje jakość nowego modelu z modelem produkcyjnym za pomocą zbiorów danych testowych.
Ilustracja 9 przedstawia potok trenowania, który wykorzystuje zbiór danych treningowych do trenowania nowego modelu.
Potok trenowania
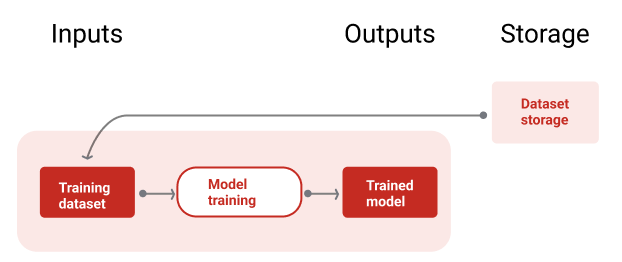
Rysunek 9. Potok trenowania trenuje nowe modele przy użyciu najnowszego zbioru danych treningowych.
Po wytrenowaniu modelu potok weryfikacji używa zbiorów danych testowych do porównania jakości modelu produkcyjnego z jakością wytrenowanego modelu.
Ogólnie rzecz biorąc, jeśli wytrenowany model nie jest znacząco gorszy od modelu produkcyjnego, jest wdrażany w środowisku produkcyjnym. Jeśli wytrenowany model jest gorszy, infrastruktura monitorowania powinna utworzyć alert. Wytrenowane modele o gorszej jakości prognozowania mogą wskazywać potencjalne problemy z danymi lub potokami weryfikacji. Takie podejście zapewnia, że w produkcji zawsze jest najlepszy model wytrenowany na najnowszych danych.
Przechowywanie zasobów i metadanych
Modele i ich metadane powinny być przechowywane w repozytoriach z wersjami, aby organizować i śledzić wdrożenia modeli. Repozytoria modeli zapewniają te korzyści:
Śledzenie i ocena Śledź modele w produkcji i poznawaj ich dane dotyczące oceny i jakości prognoz.
Proces udostępniania modelu Łatwo przeglądaj, zatwierdzaj, publikuj i wycofuj modele.
Powtarzalność i debugowanie Odtwarzaj wyniki modelu i skuteczniej debuguj problemy, śledząc zbiory danych i zależności modelu w różnych wdrożeniach.
Wykrywalność Ułatw innym znalezienie Twojego modelu. Inne zespoły mogą wtedy określić, czy Twój model (lub jego części) może być używany do ich celów.
Ilustracja 10 przedstawia zweryfikowany model przechowywany w repozytorium modeli.
Miejsce na dane modelu
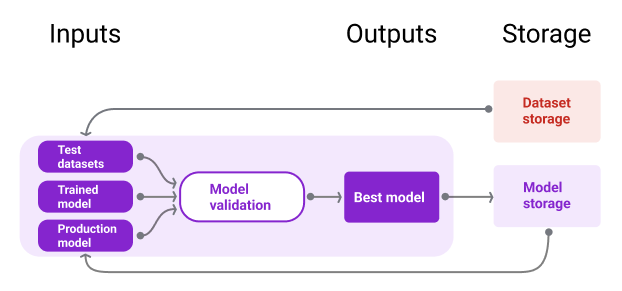
Rysunek 10. Sprawdzone modele są przechowywane w repozytorium modeli, aby można było je śledzić i wyszukiwać.
Używaj kart modeli, aby dokumentować i udostępniać kluczowe informacje o modelu, takie jak jego przeznaczenie, architektura, wymagania sprzętowe, dane oceny itp.
Sprawdź swoją wiedzę
Trudności związane z tworzeniem potoków
Podczas tworzenia potoków możesz napotkać te problemy:
Uzyskiwanie dostępu do potrzebnych danych Dostęp do danych może wymagać uzasadnienia, dlaczego ich potrzebujesz. Może być na przykład konieczne wyjaśnienie, w jaki sposób dane będą wykorzystywane, oraz wyjaśnienie, jak zostaną rozwiązane problemy związane z informacjami umożliwiającymi identyfikację. Przygotuj się na przedstawienie dowodu koncepcji, który pokaże, jak Twój model generuje lepsze prognozy dzięki dostępowi do określonych rodzajów danych.
Odpowiednie funkcje. W niektórych przypadkach funkcje używane w fazie eksperymentowania nie będą dostępne w danych w czasie rzeczywistym. Dlatego podczas eksperymentowania staraj się potwierdzić, że w środowisku produkcyjnym będziesz mieć dostęp do tych samych funkcji.
Zrozumienie, jak dane są zbierane i prezentowane. Dowiedzenie się, jak dane zostały zebrane, kto je zebrał i w jaki sposób (wraz z innymi kwestiami), może wymagać czasu i wysiłku. Ważne jest, aby dokładnie zrozumieć dane. Do trenowania modelu, który może zostać wdrożony w środowisku produkcyjnym, nie używaj danych, do których nie masz zaufania.
Zrozumienie kompromisów między nakładem pracy, kosztem a jakością modelu. Wprowadzenie nowej funkcji do potoku danych może wymagać dużego nakładu pracy. Dodatkowa funkcja może jednak tylko nieznacznie poprawić jakość modelu. W innych przypadkach dodanie nowej funkcji może być proste. Jednak zasoby potrzebne do uzyskania i przechowywania tej funkcji mogą być zbyt drogie.
Uzyskiwanie mocy obliczeniowej Jeśli potrzebujesz TPU do ponownego trenowania, może być trudno uzyskać wymagany limit. Zarządzanie układami TPU jest też skomplikowane. Na przykład niektóre części modelu lub dane mogą wymagać specjalnego zaprojektowania pod kątem procesorów TPU poprzez podzielenie ich na kilka układów TPU.
Znajdowanie odpowiedniego złotego zbioru danych Jeśli dane często się zmieniają, uzyskanie złotych zbiorów danych z spójnymi i dokładnymi etykietami może być trudne.
Wykrywanie tego typu problemów podczas eksperymentowania pozwala zaoszczędzić czas. Na przykład nie chcesz opracowywać najlepszych funkcji i modeli, aby potem dowiedzieć się, że nie nadają się one do wdrożenia w środowisku produkcyjnym. Dlatego jak najszybciej potwierdź, że Twoje rozwiązanie będzie działać w środowisku produkcyjnym. Lepiej poświęcić czas na sprawdzenie, czy rozwiązanie działa, niż wracać do fazy eksperymentowania, ponieważ faza potoku ujawniła nierozwiązywalne problemy.