Bei ML in der Produktion geht es nicht darum, ein einzelnes Modell zu erstellen und bereitzustellen. Ziel ist es, automatisierte Pipelines für die Entwicklung, das Testen und die Bereitstellung von Modellen im Laufe der Zeit zu erstellen. Warum? Wenn sich die Welt verändert, verschieben sich auch die Datentrends, sodass Modelle in der Produktion veralten. Modelle müssen in der Regel mit aktuellen Daten neu trainiert werden, damit sie langfristig weiterhin hochwertige Vorhersagen liefern können. Mit anderen Worten: Sie benötigen eine Möglichkeit, veraltete Modelle durch neue zu ersetzen.
Ohne Pipelines ist das Ersetzen eines veralteten Modells ein fehleranfälliger Prozess. Wenn ein Modell beispielsweise schlechte Vorhersagen liefert, müssen neue Daten manuell erhoben und verarbeitet, ein neues Modell trainiert, seine Qualität validiert und es schließlich bereitgestellt werden. ML-Pipelines automatisieren viele dieser sich wiederholenden Prozesse und machen die Verwaltung und Wartung von Modellen effizienter und zuverlässiger.
Pipelines erstellen
In ML-Pipelines werden die Schritte zum Erstellen und Bereitstellen von Modellen in genau definierten Aufgaben organisiert. Pipelines haben eine von zwei Funktionen: Vorhersagen liefern oder das Modell aktualisieren.
Vorhersagen bereitstellen
Die Bereitstellungspipeline liefert Vorhersagen. Dadurch wird Ihr Modell der realen Welt ausgesetzt und für Ihre Nutzer zugänglich gemacht. Wenn ein Nutzer beispielsweise eine Vorhersage wünscht – wie das Wetter morgen wird, wie viele Minuten die Fahrt zum Flughafen dauert oder eine Liste empfohlener Videos –, empfängt und verarbeitet die Serving-Pipeline die Daten des Nutzers, trifft eine Vorhersage und liefert sie dann an den Nutzer.
Modell aktualisieren
Modelle werden in der Regel fast unmittelbar nach der Produktionsaufnahme veraltet. Im Grunde treffen sie Vorhersagen anhand alter Informationen. Die Trainingsdatensätze haben den Zustand der Welt vor einem Tag oder in einigen Fällen vor einer Stunde erfasst. Die Welt hat sich verändert: Ein Nutzer hat sich mehr Videos angesehen und benötigt eine neue Liste mit Empfehlungen. Regen hat dazu geführt, dass der Verkehr langsamer ist, und Nutzer benötigen aktualisierte Schätzungen für ihre Ankunftszeiten. Ein beliebter Trend führt dazu, dass Einzelhändler aktualisierte Bestandsprognosen für bestimmte Artikel anfordern.
In der Regel trainieren Teams neue Modelle lange bevor das Produktionsmodell veraltet ist. In einigen Fällen trainieren und stellen Teams täglich neue Modelle in einem kontinuierlichen Trainings- und Bereitstellungszyklus bereit. Idealerweise sollte ein neues Modell lange vor dem Ablauf des Produktionsmodells trainiert werden.
Die folgenden Pipelines arbeiten zusammen, um ein neues Modell zu trainieren:
- Datenpipeline In der Datenpipeline werden Nutzerdaten verarbeitet, um Trainings- und Testdatasets zu erstellen.
- Trainingspipeline In der Trainingspipeline werden Modelle mit den neuen Trainingsdatasets aus der Datenpipeline trainiert.
- Validierungspipeline: In der Validierungspipeline wird das trainierte Modell validiert, indem es mit dem Produktionsmodell verglichen wird. Dazu werden Test-Datasets verwendet, die von der Datenpipeline generiert werden.
Abbildung 4 zeigt die Ein- und Ausgaben der einzelnen ML-Pipelines.
ML-Pipelines
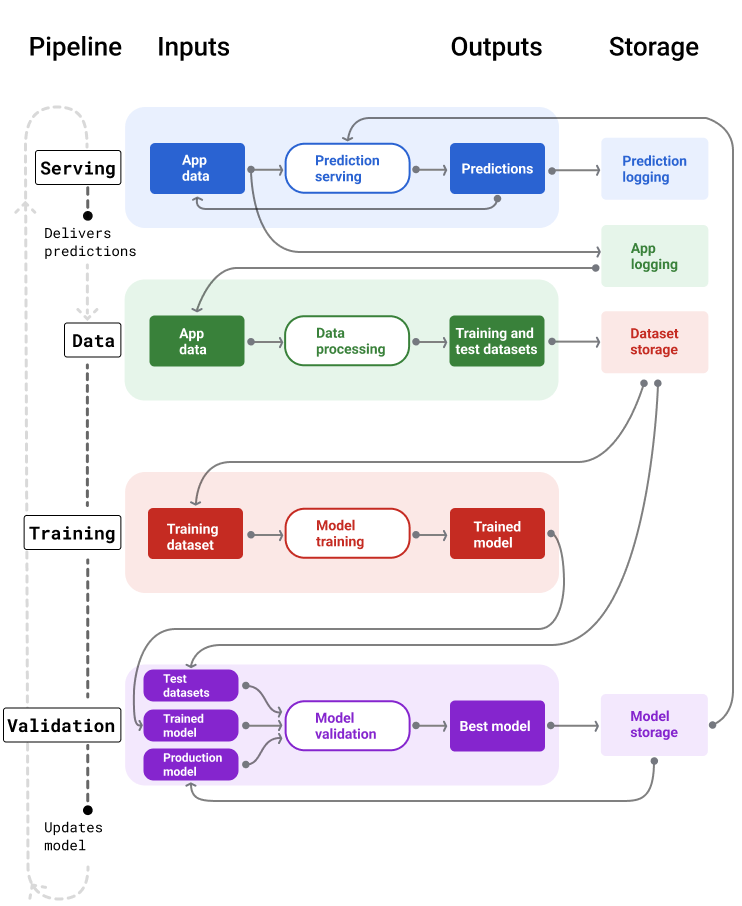
Abbildung 4. ML-Pipelines automatisieren viele Prozesse für die Entwicklung und Wartung von Modellen. Für jede Pipeline werden die Ein- und Ausgaben angezeigt.
Ganz allgemein funktioniert das so:
Zuerst wird ein Modell in die Produktion überführt und die Bereitstellungspipeline beginnt mit der Bereitstellung von Vorhersagen.
Die Datenpipeline beginnt sofort mit der Erhebung von Daten, um neue Trainings- und Test-Datasets zu generieren.
Anhand eines Zeitplans oder eines Triggers werden mit den Trainings- und Validierungspipelines ein neues Modell mit den von der Datenpipeline generierten Datasets trainiert und validiert.
Wenn die Validierungspipeline bestätigt, dass das neue Modell nicht schlechter als das Produktionsmodell ist, wird es bereitgestellt.
Dieser Vorgang wird kontinuierlich wiederholt.
Modellveralterung und Trainingshäufigkeit
Fast alle Modelle werden irgendwann veraltet. Einige Modelle werden schneller veraltet als andere. Modelle, die beispielsweise Kleidung empfehlen, sind in der Regel schnell veraltet, da sich die Vorlieben der Verbraucher häufig ändern. Andererseits können Modelle, die Blumen identifizieren, nie veralten. Die charakteristischen Merkmale einer Blume bleiben stabil.
Die meisten Modelle werden sofort nach der Produktionsaufnahme veraltet. Sie sollten eine Trainingshäufigkeit festlegen, die der Art Ihrer Daten entspricht. Wenn die Daten dynamisch sind, sollten Sie das Modell häufig trainieren. Wenn sie weniger dynamisch ist, musst du möglicherweise nicht so oft trainieren.
Modelle trainieren, bevor sie veralten. Ein frühzeitiges Training bietet einen Puffer, um potenzielle Probleme zu beheben, z. B. wenn die Daten oder die Trainingspipeline fehlschlagen oder die Modellqualität schlecht ist.
Es wird empfohlen, täglich neue Modelle zu trainieren und bereitzustellen. Genau wie bei regulären Softwareprojekten mit einem täglichen Build- und Releaseprozess ist es oft am besten, ML-Pipelines für das Training und die Validierung täglich auszuführen.
Wissen testen
Bereitstellungspipeline
Die Bereitstellungspipeline generiert und liefert Vorhersagen auf zwei Arten: online oder offline.
Onlinevorhersagen: Onlinevorhersagen erfolgen in Echtzeit, in der Regel durch Senden einer Anfrage an einen Onlineserver und Zurückgeben einer Vorhersage. Wenn ein Nutzer beispielsweise eine Vorhersage wünscht, werden seine Daten an das Modell gesendet und das Modell gibt die Vorhersage zurück.
Offlinevorhersagen: Offlinevorhersagen werden vorab berechnet und im Cache gespeichert. Um eine Vorhersage bereitzustellen, sucht die App in der Datenbank nach der im Cache gespeicherten Vorhersage und gibt sie zurück. Ein abobasierter Dienst kann beispielsweise die Abwanderungsrate für seine Abonnenten vorhersagen. Das Modell sagt die Wahrscheinlichkeit einer Abwanderung für jeden Abonnenten voraus und speichert sie im Cache. Wenn die App die Vorhersage benötigt, z. B. um Nutzer, die möglicherweise kurz vor dem Abwandern stehen, zu motivieren, wird einfach die vorab berechnete Vorhersage abgerufen.
Abbildung 5 zeigt, wie Online- und Offlinevorhersagen generiert und bereitgestellt werden.
Online- und Offlinevorhersagen
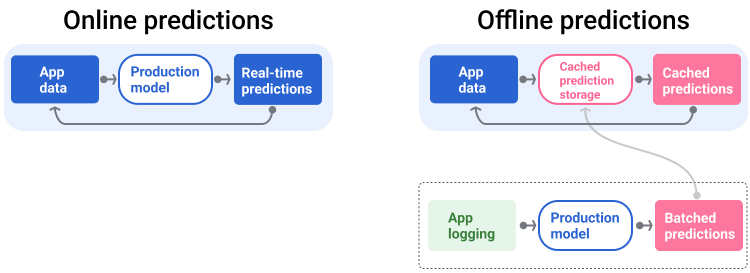
Abbildung 5. Bei Onlinevorhersagen werden Vorhersagen in Echtzeit bereitgestellt. Offlinevorhersagen werden im Cache gespeichert und zur Bereitstellungszeit nachgeschlagen.
Nachbearbeitung von Vorhersagen
In der Regel werden Vorhersagen nach der Verarbeitung noch einmal bearbeitet, bevor sie ausgegeben werden. Beispielsweise können Vorhersagen nachbearbeitet werden, um schädliche oder voreingenommene Inhalte zu entfernen. Klassifizierungsergebnisse können einen Prozess durchlaufen um Ergebnisse neu anzuordnen, anstatt die Rohausgabe des Modells anzuzeigen, z. B. um maßgebliche Inhalte zu fördern, eine Vielfalt von Ergebnissen zu präsentieren, bestimmte Ergebnisse (z. B. Clickbait) herabzustufen oder Ergebnisse aus rechtlichen Gründen zu entfernen.
Abbildung 6 zeigt eine Serving-Pipeline und die typischen Aufgaben, die mit der Bereitstellung von Vorhersagen verbunden sind.
Vorhersagen nach der Verarbeitung
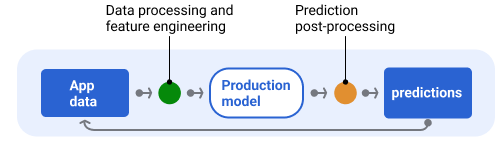
Abbildung 6. Bereitstellungspipeline, die die typischen Aufgaben zur Bereitstellung von Vorhersagen veranschaulicht.
Der Schritt Feature-Engineering ist in der Regel im Modell enthalten und kein separater, eigenständiger Prozess. Der Code für die Datenverarbeitung in der Serving-Pipeline ist oft nahezu identisch mit dem Code für die Datenverarbeitung, der in der Datenpipeline zum Erstellen von Trainings- und Test-Datasets verwendet wird.
Speicher von Assets und Metadaten
Die Bereitstellungspipeline sollte ein Repository enthalten, in dem Modellvorhersagen und, falls möglich, die Ground Truth protokolliert werden.
Wenn Sie Modellvorhersagen protokollieren, können Sie die Qualität Ihres Modells überwachen. Durch das Aggregieren von Vorhersagen können Sie die allgemeine Qualität Ihres Modells im Blick behalten und feststellen, ob die Qualität nachlässt. Im Allgemeinen sollten die Vorhersagen des Produktionsmodells denselben Durchschnittswert wie die Labels aus dem Trainingsdataset haben. Weitere Informationen finden Sie unter Vorhersagebias.
Grundwahrheit erfassen
In einigen Fällen ist die Grundwahrheit erst viel später verfügbar. Wenn eine Wetter-App beispielsweise das Wetter für sechs Wochen in der Zukunft vorhersagt, sind die tatsächlichen Wetterdaten erst nach sechs Wochen verfügbar.
Wenn möglich, sollten Sie Nutzer dazu anregen, die Ground Truth zu melden, indem Sie Feedbackmechanismen in die App einbauen. Eine E‑Mail-App kann Nutzerfeedback implizit erfassen, wenn Nutzer E‑Mails aus ihrem Posteingang in den Spamordner verschieben. Das funktioniert jedoch nur, wenn Nutzer ihre E‑Mails richtig kategorisieren. Wenn Nutzer Spam in ihrem Posteingang lassen, weil sie wissen, dass es sich um Spam handelt, und ihn nie öffnen, werden die Trainingsdaten ungenau. Diese E‑Mail wird als „Kein Spam“ gekennzeichnet, obwohl sie als „Spam“ gekennzeichnet werden sollte. Mit anderen Worten: Versuchen Sie immer, die Ground Truth zu erfassen und aufzuzeichnen, aber seien Sie sich der Einschränkungen bewusst, die bei Feedbackmechanismen auftreten können.
Abbildung 7 zeigt, wie Vorhersagen an einen Nutzer gesendet und in einem Repository protokolliert werden.
Vorhersagen protokollieren
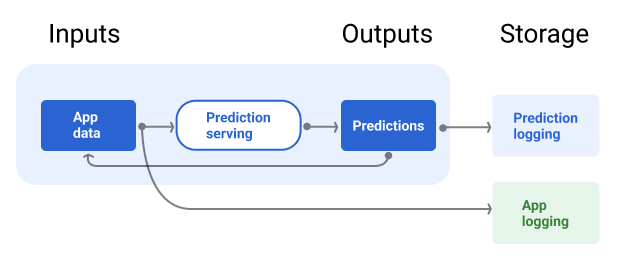
Abbildung 7. Vorhersagen protokollieren, um die Modellqualität zu überwachen
Datenpipelines
Mit Datenpipelines werden Trainings- und Test-Datasets aus Anwendungsdaten generiert. Die Trainings- und Validierungspipelines verwenden die Datasets dann zum Trainieren und Validieren neuer Modelle.
In der Datenpipeline werden Trainings- und Test-Datasets mit denselben Features und demselben Label erstellt, die ursprünglich zum Trainieren des Modells verwendet wurden, jedoch mit neueren Informationen. Eine Karten-App würde beispielsweise Trainings- und Test-Datasets aus den aktuellen Reisezeiten zwischen Punkten für Millionen von Nutzern sowie anderen relevanten Daten wie dem Wetter generieren.
Eine App für Videoempfehlungen würde Trainings- und Testdatensätze generieren, die die Videos enthalten, auf die ein Nutzer in der Empfehlungsliste geklickt hat (sowie die Videos, auf die er nicht geklickt hat), und andere relevante Daten wie den Wiedergabeverlauf.
Abbildung 8 zeigt die Datenpipeline, in der Anwendungsdaten verwendet werden, um Trainings- und Testdatasets zu generieren.
Datenpipeline
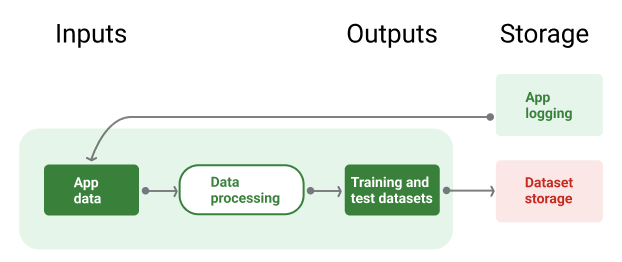
Abbildung 8. In der Datenpipeline werden Anwendungsdaten verarbeitet, um Datasets für die Trainings- und Validierungspipelines zu erstellen.
Datenerhebung und ‑verarbeitung
Die Aufgaben zum Erheben und Verarbeiten von Daten in Datenpipelines unterscheiden sich wahrscheinlich von denen in der Testphase, in der Sie festgestellt haben, dass Ihre Lösung machbar ist:
Datenerhebung. Bei Tests ist in der Regel der Zugriff auf gespeicherte Daten erforderlich. Bei Datenpipelines kann es erforderlich sein, Streaming-Logdaten zu ermitteln und die Genehmigung für den Zugriff darauf einzuholen.
Wenn Sie Daten mit menschlichen Labels benötigen, z. B. medizinische Bilder, benötigen Sie auch einen Prozess zum Erheben und Aktualisieren dieser Daten.
Datenverarbeitung. Während der Tests wurden die richtigen Funktionen durch Scraping, Zusammenführen und Sampling der Test-Datasets ermittelt. Für die Datenpipelines sind möglicherweise ganz andere Prozesse erforderlich, um dieselben Features zu generieren. Achten Sie jedoch darauf, die Datentransformationen aus der Testphase zu duplizieren, indem Sie dieselben mathematischen Operationen auf die Features und Labels anwenden.
Speicher von Assets und Metadaten
Sie benötigen einen Prozess zum Speichern, Verwalten von Versionen und Verwalten Ihrer Trainings- und Test-Datasets. Versionskontrollierte Repositories bieten folgende Vorteile:
Reproduzierbarkeit: Modelltrainingsumgebungen neu erstellen und standardisieren und die Vorhersagequalität verschiedener Modelle vergleichen.
Compliance. Einhaltung der Compliance-Anforderungen für Prüfbarkeit und Transparenz
Aufbewahrung: Legen Sie Werte für die Datenaufbewahrung fest, um anzugeben, wie lange die Daten gespeichert werden sollen.
Zugriffsverwaltung Mit detaillierten Berechtigungen können Sie festlegen, wer auf Ihre Daten zugreifen darf.
Datenintegrität: Sie können Änderungen an Datasets im Zeitverlauf nachvollziehen und so Probleme mit Ihren Daten oder Ihrem Modell leichter diagnostizieren.
Sichtbarkeit: Machen Sie es anderen leicht, Ihre Datasets und Funktionen zu finden. Andere Teams können dann entscheiden, ob sie für ihre Zwecke nützlich sind.
Daten dokumentieren
Eine gute Dokumentation hilft anderen, wichtige Informationen zu Ihren Daten zu verstehen, z. B. Typ, Quelle, Größe und andere wichtige Metadaten. In den meisten Fällen reicht es aus, Ihre Daten in einem Design-Dokument zu dokumentieren. Wenn Sie Ihre Daten freigeben oder veröffentlichen möchten, verwenden Sie Datenkarten , um die Informationen zu strukturieren. Mit Datenkarten können andere Ihre Datasets leichter finden und verstehen.
Trainings- und Validierungspipelines
Mit den Trainings- und Validierungspipelines werden neue Modelle erstellt, um Produktionsmodelle zu ersetzen, bevor sie veralten. Durch das kontinuierliche Trainieren und Validieren neuer Modelle ist immer das beste Modell in der Produktion.
In der Trainingspipeline wird ein neues Modell aus den Trainingsdatasets generiert. In der Validierungspipeline wird die Qualität des neuen Modells anhand von Test-Datasets mit dem Produktionsmodell verglichen.
Abbildung 9 zeigt die Trainingspipeline, in der ein Trainingsdataset zum Trainieren eines neuen Modells verwendet wird.
Trainingspipeline
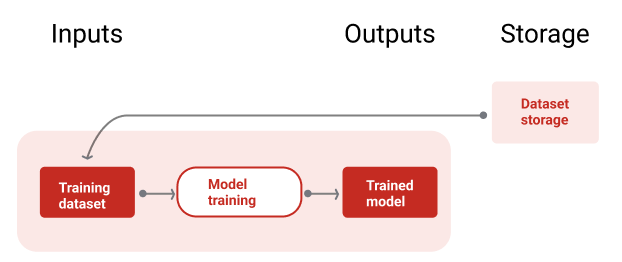
Abbildung 9. In der Trainingspipeline werden neue Modelle mit dem neuesten Trainingsdataset trainiert.
Nach dem Training des Modells werden in der Validierungspipeline Test-Datasets verwendet, um die Qualität des Produktionsmodells mit der des trainierten Modells zu vergleichen.
Im Allgemeinen wird das trainierte Modell in der Produktion eingesetzt, wenn es nicht wesentlich schlechter als das Produktionsmodell ist. Wenn das trainierte Modell schlechter ist, sollte die Monitoring-Infrastruktur eine Benachrichtigung erstellen. Modelle mit schlechterer Vorhersagequalität können auf potenzielle Probleme mit den Daten oder Validierungspipelines hinweisen. So wird dafür gesorgt, dass immer das beste Modell, das mit den neuesten Daten trainiert wurde, in der Produktion eingesetzt wird.
Speicher von Assets und Metadaten
Modelle und ihre Metadaten sollten in versionierten Repositorys gespeichert werden, um Modelldistributionen zu organisieren und nachzuverfolgen. Modell-Repositories bieten die folgenden Vorteile:
Tracking und Auswertung Modelle in der Produktion im Blick behalten und ihre Metriken für die Bewertungs- und Vorhersagequalität nachvollziehen.
Prozess für die Modellveröffentlichung Modelle lassen sich ganz einfach überprüfen, genehmigen, freigeben oder zurücksetzen.
Reproduzierbarkeit und Debugging: Modellergebnisse reproduzieren und Probleme effektiver beheben, indem Sie die Datasets und Abhängigkeiten eines Modells über Bereitstellungen hinweg nachvollziehen.
Sichtbarkeit: Anderen das Auffinden Ihres Modells erleichtern Andere Teams können dann entscheiden, ob Ihr Modell (oder Teile davon) für ihre Zwecke verwendet werden kann.
Abbildung 10 zeigt ein validiertes Modell, das in einem Modell-Repository gespeichert ist.
Modellspeicher
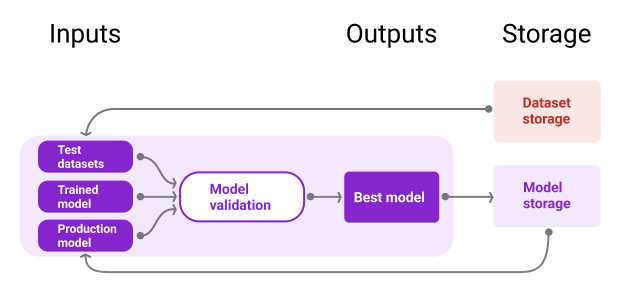
Abbildung 10. Validierte Modelle werden in einem Modell-Repository gespeichert, um sie nachzuverfolgen und auffindbar zu machen.
Verwenden Sie>Modellkarten , um wichtige Informationen zu Ihrem Modell zu dokumentieren und zu teilen, z. B. den Zweck, die Architektur, die Hardwareanforderungen und die Bewertungsmetriken.
Wissen testen
Herausforderungen beim Erstellen von Pipelines
Beim Erstellen von Pipelines können folgende Probleme auftreten:
Zugriff auf die benötigten Daten erhalten Für den Datenzugriff müssen Sie möglicherweise begründen, warum Sie ihn benötigen. Sie müssen beispielsweise erklären, wie die Daten verwendet werden, und klarstellen, wie Probleme mit personenidentifizierbaren Informationen gelöst werden. Sie müssen einen Proof of Concept vorlegen, der zeigt, wie Ihr Modell mit Zugriff auf bestimmte Arten von Daten bessere Vorhersagen trifft.
Die richtigen Funktionen nutzen: In einigen Fällen sind die Funktionen, die in der Testphase verwendet werden, nicht in den Echtzeitdaten verfügbar. Achten Sie daher bei Tests darauf, dass Sie die gleichen Funktionen auch in der Produktion nutzen können.
Wie Daten erhoben und dargestellt werden Es kann Zeit und Mühe kosten, herauszufinden, wie die Daten erhoben wurden, wer sie erhoben hat und wie sie erhoben wurden (neben anderen Problemen). Es ist wichtig, die Daten genau zu verstehen. Verwenden Sie keine Daten, bei denen Sie sich nicht sicher sind, um ein Modell zu trainieren, das in der Produktion eingesetzt werden soll.
Die Abwägungen zwischen Aufwand, Kosten und Modellqualität verstehen: Das Einbinden eines neuen Features in eine Datenpipeline kann sehr aufwendig sein. Die zusätzliche Funktion kann die Qualität des Modells jedoch nur geringfügig verbessern. In anderen Fällen ist das Hinzufügen einer neuen Funktion möglicherweise ganz einfach. Die Ressourcen zum Abrufen und Speichern des Features sind jedoch möglicherweise zu teuer.
Compute-Ressourcen abrufen Wenn Sie TPUs für das erneute Training benötigen, ist es möglicherweise schwierig, das erforderliche Kontingent zu erhalten. Außerdem ist die Verwaltung von TPUs kompliziert. Beispielsweise müssen einige Teile Ihres Modells oder Ihrer Daten möglicherweise speziell für TPUs konzipiert werden, indem sie auf mehrere TPU-Chips aufgeteilt werden.
Das richtige Golden Dataset finden: Wenn sich die Daten häufig ändern, kann es schwierig sein, Gold-Datasets mit einheitlichen und genauen Labels zu erhalten.
Wenn Sie diese Arten von Problemen während des Tests erkennen, sparen Sie Zeit. Sie möchten beispielsweise nicht die besten Funktionen und das beste Modell entwickeln, nur um dann festzustellen, dass sie in der Produktion nicht praktikabel sind. Bestätigen Sie daher so früh wie möglich, dass Ihre Lösung innerhalb der Einschränkungen einer Produktionsumgebung funktioniert. Es ist besser, Zeit damit zu verbringen, eine Lösung zu überprüfen, als zur Experimentierphase zurückkehren zu müssen, weil in der Pipelinephase unüberwindliche Probleme aufgetreten sind.