Üretim makine öğreniminde amaç tek bir model oluşturup dağıtmak değildir. Amaç, zaman içinde modelleri geliştirme, test etme ve dağıtma için otomatik işlem hatları oluşturmaktır. Neden? Dünya değiştikçe verilerdeki trendler de değişir ve bu durum, üretimdeki modellerin eskimesine neden olur. Modellerin uzun vadede yüksek kaliteli tahminler sunmaya devam edebilmesi için genellikle güncel verilerle yeniden eğitilmesi gerekir. Başka bir deyişle, eski modelleri yenileriyle değiştirmek isteyeceksiniz.
İşlem hatları olmadan eski bir modeli değiştirmek hataya açık bir süreçtir. Örneğin, bir model kötü tahminler sunmaya başladığında yeni verilerin manuel olarak toplanıp işlenmesi, yeni bir modelin eğitilmesi, kalitesinin doğrulanması ve son olarak dağıtılması gerekir. Makine öğrenimi ardışık düzenleri, bu tekrarlayan süreçlerin çoğunu otomatikleştirerek modellerin yönetimini ve bakımını daha verimli ve güvenilir hale getirir.
Ardışık düzenler oluşturma
Makine öğrenimi işlem hatları, modelleri oluşturma ve dağıtma adımlarını iyi tanımlanmış görevler halinde düzenler. İşlem hatlarının iki işlevinden biri tahmin sunmak, diğeri ise modeli güncellemektedir.
Tahminleri yayınlama
Sunum işlem hattı tahminler sunar. Modelinizi gerçek dünyaya sunarak kullanıcılarınızın erişimine açar. Örneğin, bir kullanıcı tahmin istediğinde (yarın hava nasıl olacak, havaalanına gitmek kaç dakika sürecek veya önerilen videoların listesi) yayın ardışık düzeni, kullanıcının verilerini alır ve işler, bir tahminde bulunur ve ardından bunu kullanıcıya iletir.
Modeli güncelleme
Modeller, üretime alındıktan hemen sonra eski hale gelme eğilimindedir. Bu nedenle, eski bilgileri kullanarak tahminlerde bulunurlar. Eğitim veri kümeleri, bir gün önce veya bazı durumlarda bir saat önce dünyadaki durumu yakaladı. Dünya kaçınılmaz olarak değişti: Bir kullanıcı daha fazla video izledi ve yeni bir öneri listesine ihtiyaç duyuyor; yağmur trafiği yavaşlattı ve kullanıcıların varış zamanlarıyla ilgili güncellenmiş tahminlere ihtiyacı var; popüler bir trend, perakendecilerin belirli öğeler için güncellenmiş envanter tahminleri istemesine neden oluyor.
Genellikle ekipler, üretim modeli eskimeye başlamadan çok önce yeni modelleri eğitir. Bazı durumlarda ekipler, sürekli eğitim ve dağıtım döngüsünde her gün yeni modeller eğitip dağıtır. İdeal olarak, yeni modelin eğitimi, üretim modelinin eskimesinden çok önce yapılmalıdır.
Yeni bir modeli eğitmek için aşağıdaki işlem hatları birlikte çalışır:
- Veri ardışık düzeni. Veri ardışık düzeni, eğitim ve test veri kümeleri oluşturmak için kullanıcı verilerini işler.
- Eğitim ardışık düzeni. Eğitim ardışık düzeni, veri ardışık düzeninden gelen yeni eğitim veri kümelerini kullanarak modelleri eğitir.
- Doğrulama ardışık düzeni. Doğrulama ardışık düzeni, veri ardışık düzeni tarafından oluşturulan test veri kümelerini kullanarak eğitilmiş modeli üretim modeliyle karşılaştırarak doğrular.
Şekil 4'te her makine öğrenimi ardışık düzeninin girişleri ve çıkışları gösterilmektedir.
ML işlem hatları
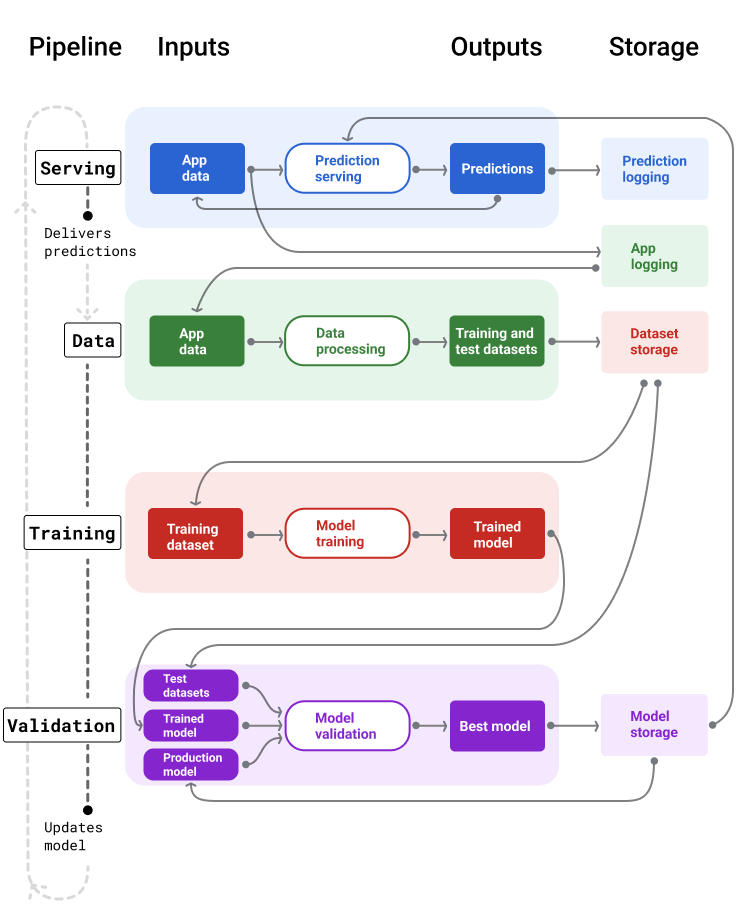
Şekil 4. Makine öğrenimi ardışık düzenleri, modellerin geliştirilmesi ve bakımıyla ilgili birçok süreci otomatikleştirir. Her ardışık düzende girişler ve çıkışlar gösterilir.
Genel olarak, işlem hatlarının üretimde güncel bir model tutma şekli şöyledir:
Öncelikle bir model üretime alınır ve yayınlama işlem hattı tahminler sunmaya başlar.
Veri ardışık düzeni, yeni eğitim ve test veri kümeleri oluşturmak için hemen veri toplamaya başlar.
Eğitim ve doğrulama ardışık düzenleri, bir programa veya tetikleyiciye göre veri ardışık düzeni tarafından oluşturulan veri kümelerini kullanarak yeni bir modeli eğitir ve doğrular.
Doğrulama işlem hattı, yeni modelin üretim modelinden daha kötü olmadığını onayladığında yeni model dağıtılır.
Bu işlem sürekli olarak tekrarlanır.
Modelin güncelliğini yitirmesi ve eğitim sıklığı
Neredeyse tüm modeller eskiyor. Bazı modeller diğerlerinden daha hızlı eskiyor. Örneğin, kıyafet öneren modeller, tüketici tercihleri sık sık değiştiği için genellikle kısa sürede güncelliğini yitirir. Öte yandan, çiçekleri tanımlayan modeller hiçbir zaman eski hale gelmeyebilir. Çiçeğin tanımlayıcı özellikleri sabit kalır.
Çoğu model, üretime alındıktan hemen sonra eskimeye başlar. Verilerinizin yapısını yansıtan bir eğitim sıklığı belirlemeniz gerekir. Veriler dinamikse sık sık eğitim yapın. Daha az dinamikse o kadar sık eğitmeniz gerekmez.
Modelleri eski hale gelmeden önce eğitin. Erken eğitim, olası sorunları çözmek için bir tampon sağlar. Örneğin, veriler veya eğitim işlem hattı başarısız olursa ya da model kalitesi düşük olursa.
Önerilen en iyi uygulama, yeni modelleri günlük olarak eğitmek ve dağıtmaktır. Günlük derleme ve yayınlama süreci olan normal yazılım projelerinde olduğu gibi, eğitim ve doğrulama için makine öğrenimi işlem hatları da genellikle günlük olarak çalıştırıldığında en iyi sonucu verir.
Anlayıp anlamadığınızı kontrol etme
Sunma ardışık düzeni
Yayın ardışık düzeni, tahminleri iki şekilde oluşturup sunar: online veya offline.
Online tahminler. Online tahminler genellikle bir online sunucuya istek gönderilip tahmin döndürülerek gerçek zamanlı olarak yapılır. Örneğin, bir kullanıcı tahmin istediğinde kullanıcının verileri modele gönderilir ve model tahmini döndürür.
Çevrimdışı tahminler. Çevrimdışı tahminler önceden hesaplanır ve önbelleğe alınır. Uygulama, bir tahmini yayınlamak için veritabanında önbelleğe alınmış tahmini bulur ve döndürür. Örneğin, aboneliğe dayalı bir hizmet, aboneleri için müşteri kaybı oranını tahmin edebilir. Model, her abone için müşteri kaybı olasılığını tahmin eder ve bunu önbelleğe alır. Uygulama, tahmine ihtiyaç duyduğunda (ör. kullanıcıları elde tutmak için) önceden hesaplanmış tahmini arar.
Şekil 5'te online ve çevrimdışı tahminlerin nasıl oluşturulup sunulduğu gösterilmektedir.
Online ve çevrimdışı tahminler
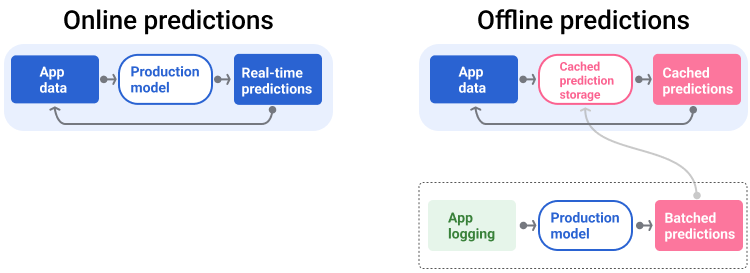
Şekil 5. Online tahminler, tahminleri anlık olarak sunar. Çevrimdışı tahminler önbelleğe alınır ve yayın sırasında aranır.
Tahmin işleme sonrası
Genellikle tahminler, teslim edilmeden önce sonradan işlenir. Örneğin, tahminler, zararlı veya taraflı içeriklerin kaldırılması için sonradan işlenebilir. Sınıflandırma sonuçları, modelin ham çıkışını göstermek yerine sonuçları yeniden sıralamak için oynama kullanabilir. Örneğin, daha yetkili içerikleri öne çıkarmak, çeşitli sonuçlar sunmak, belirli sonuçları (tıklama tuzağı gibi) alt sıralara yerleştirmek veya yasal nedenlerle sonuçları kaldırmak için bu yöntem kullanılabilir.
Şekil 6'da bir yayın hattı ve tahminlerin yayınlanmasıyla ilgili tipik görevler gösterilmektedir.
İşleme sonrası tahminler
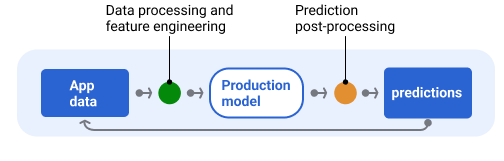
Şekil 6. Tahmin sunmak için gereken tipik görevleri gösteren yayınlama işlem hattı.
Özellik mühendisliği adımının genellikle modelin içinde oluşturulduğunu ve ayrı, bağımsız bir süreç olmadığını unutmayın. Sunum ardışık düzenindeki veri işleme kodu, genellikle veri ardışık düzeninin eğitim ve test veri kümeleri oluşturmak için kullandığı veri işleme koduyla neredeyse aynıdır.
Öğeler ve meta veri depolama alanı
Yayınlama işlem hattı, model tahminlerini ve mümkünse kesin referansı kaydetmek için bir depo içermelidir.
Model tahminlerini günlüğe kaydetme, modelinizin kalitesini izlemenizi sağlar. Tahminleri toplayarak modelinizin genel kalitesini izleyebilir ve kalitesini kaybetmeye başlayıp başlamadığını belirleyebilirsiniz. Genel olarak, üretim modelinin tahminlerinin ortalaması, eğitim veri kümesindeki etiketlerin ortalamasıyla aynı olmalıdır. Daha fazla bilgi için tahmin yanlılığı konusuna bakın.
Kesin referansı yakalama
Bazı durumlarda, gerçek veriler ancak çok daha sonra kullanılabilir. Örneğin, bir hava durumu uygulaması altı hafta sonraki hava durumunu tahmin ediyorsa gerçek hava durumu (hava durumunun gerçekte nasıl olduğu) altı hafta boyunca kullanılamaz.
Mümkün olduğunda, uygulamaya geri bildirim mekanizmaları ekleyerek kullanıcıların gerçek durumu bildirmesini sağlayın. Bir posta uygulaması, kullanıcılar gelen kutularındaki postaları spam klasörüne taşıdığında kullanıcı geri bildirimlerini dolaylı olarak yakalayabilir. Ancak bu özellik yalnızca kullanıcı postalarını doğru şekilde sınıflandırdığında çalışır. Kullanıcılar, spam olduğunu bildikleri ve hiç açmadıkları için gelen kutularında spam iletiler bıraktığında eğitim verileri yanlış hale gelir. Söz konusu posta, "spam" olması gerekirken "spam değil" olarak etiketlenir. Başka bir deyişle, her zaman gerçekleri yakalamanın ve kaydetmenin yollarını bulmaya çalışın ancak geri bildirim mekanizmalarında olabilecek eksikliklerin farkında olun.
Şekil 7'de, kullanıcılara sunulan ve bir depoya kaydedilen tahminler gösterilmektedir.
Tahminleri günlüğe kaydetme
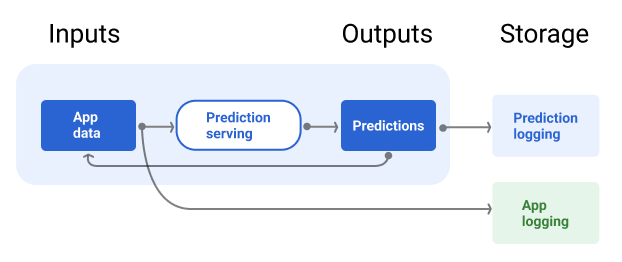
Şekil 7 Model kalitesini izlemek için tahminleri günlüğe kaydedin.
Veri ardışık düzenleri
Veri ardışık düzenleri, uygulama verilerinden eğitim ve test veri kümeleri oluşturur. Eğitim ve doğrulama ardışık düzenleri daha sonra yeni modelleri eğitmek ve doğrulamak için veri kümelerini kullanır.
Veri işlem hattı, modeli eğitmek için kullanılan özellikler ve etiketle aynı olan ancak daha yeni bilgiler içeren eğitim ve test veri kümeleri oluşturur. Örneğin, bir harita uygulaması, milyonlarca kullanıcının noktalar arasındaki son seyahat sürelerinden eğitim ve test veri kümeleri oluşturur. Ayrıca hava durumu gibi diğer ilgili verileri de kullanır.
Video önerisi uygulaması, kullanıcının önerilen listeden tıkladığı videoları (tıklanmayanlarla birlikte) ve izleme geçmişi gibi diğer alakalı verileri içeren eğitim ve test veri kümeleri oluşturur.
Şekil 8'de, eğitim ve test veri kümeleri oluşturmak için uygulama verilerini kullanan veri ardışık düzeni gösterilmektedir.
Veri ardışık düzeni
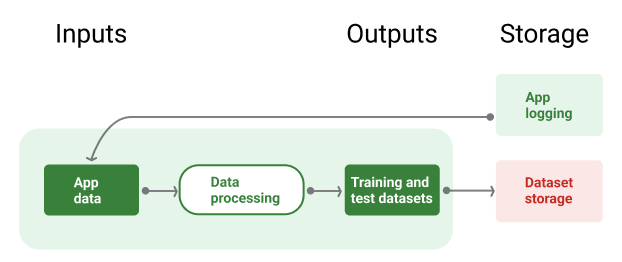
Şekil 8 Veri ardışık düzeni, eğitim ve doğrulama ardışık düzenleri için veri kümeleri oluşturmak üzere uygulama verilerini işler.
Veri toplama ve işleme
Veri işlem hatlarındaki veri toplama ve işleme görevleri muhtemelen deneme aşamasından (çözümünüzün uygulanabilir olduğunu belirlediğiniz aşama) farklı olacaktır:
Veri toplama. Deneme sırasında veri toplamak genellikle kayıtlı verilere erişmeyi gerektirir. Veri ardışık düzenlerinde veri toplamak için akış günlükleri verilerine erişmek üzere keşif yapılması ve onay alınması gerekebilir.
İnsan tarafından etiketlenmiş verilere (ör. tıbbi görüntüler) ihtiyacınız varsa bu verileri toplama ve güncelleme süreciniz de olmalıdır.
Veri işleme. Deneme sırasında, doğru özellikler deneme veri kümelerinin kazınması, birleştirilmesi ve örneklenmesiyle elde edildi. Veri işlem hatları için aynı özelliklerin oluşturulması tamamen farklı süreçler gerektirebilir. Ancak, aynı matematiksel işlemleri özelliklere ve etiketlere uygulayarak deneme aşamasındaki veri dönüşümlerini kopyaladığınızdan emin olun.
Öğeler ve meta veri depolama alanı
Eğitim ve test veri kümelerinizi depolama, sürüm oluşturma ve yönetme sürecine ihtiyacınız vardır. Sürüm kontrollü depolar aşağıdaki avantajları sağlar:
Yeniden üretilebilirlik (Reproducibility). Model eğitimi ortamlarını yeniden oluşturup standart hale getirin ve farklı modeller arasındaki tahmin kalitesini karşılaştırın.
Uygunluk. Denetlenebilirlik ve şeffaflıkla ilgili yasal uygunluk şartlarına uyun.
Elde tutma Verilerin ne kadar süre saklanacağını belirlemek için veri saklama değerlerini ayarlayın.
Erişim yönetimi. Ayrıntılı izinler sayesinde verilerinize kimlerin erişebileceğini yönetebilirsiniz.
Veri bütünlüğü. Veri kümelerindeki değişiklikleri zaman içinde izleyip anlayarak verilerinizle veya modelinizle ilgili sorunları teşhis etmeyi kolaylaştırın.
Keşfedilebilirlik. Diğer kullanıcıların veri kümelerinizi ve özelliklerinizi kolayca bulmasını sağlayın. Diğer ekipler daha sonra bu araçların kendi amaçları için faydalı olup olmayacağına karar verebilir.
Verilerinizi belgeleme
İyi bir doküman, diğer kullanıcıların verilerinizle ilgili temel bilgileri (ör. türü, kaynağı, boyutu ve diğer önemli meta veriler) anlamasına yardımcı olur. Çoğu durumda, verilerinizi bir tasarım dokümanında belgelemeniz yeterlidir. Verilerinizi paylaşmayı veya yayınlamayı planlıyorsanız bilgileri yapılandırmak için veri kartlarını kullanın. Veri kartları, diğer kullanıcıların veri kümelerinizi keşfetmesini ve anlamasını kolaylaştırır.
Eğitim ve doğrulama ardışık düzenleri
Eğitim ve doğrulama işlem hatları, üretim modelleri eski hale gelmeden önce bunların yerine geçecek yeni modeller üretir. Yeni modellerin sürekli olarak eğitilmesi ve doğrulanması, her zaman en iyi modelin üretimde olmasını sağlar.
Eğitim ardışık düzeni, eğitim veri kümelerinden yeni bir model oluşturur. Doğrulama ardışık düzeni ise test veri kümelerini kullanarak yeni modelin kalitesini üretimdeki modelle karşılaştırır.
Şekil 9'da, yeni bir modeli eğitmek için eğitim veri kümesi kullanılan eğitim ardışık düzeni gösterilmektedir.
Eğitim ardışık düzeni
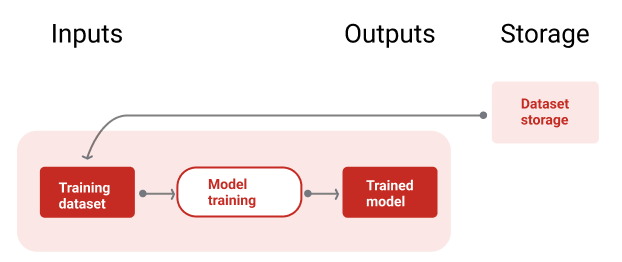
Şekil 9. Eğitim ardışık düzeni, en son eğitim veri kümesini kullanarak yeni modelleri eğitir.
Model eğitildikten sonra doğrulama ardışık düzeni, üretim modelinin kalitesini eğitilmiş modelle karşılaştırmak için test veri kümelerini kullanır.
Genel olarak, eğitilmiş model üretim modelinden anlamlı bir şekilde daha kötü değilse üretime alınır. Eğitilmiş model daha kötüyse izleme altyapısı bir uyarı oluşturmalıdır. Tahmin kalitesi daha düşük olan eğitilmiş modeller, verilerle veya doğrulama işlem hatlarıyla ilgili olası sorunlara işaret edebilir. Bu yaklaşım, en yeni verilerle eğitilmiş en iyi modelin her zaman üretimde olmasını sağlar.
Öğeler ve meta veri depolama alanı
Modeller ve meta verileri, model dağıtımlarını düzenlemek ve izlemek için sürüm oluşturulmuş depolarda saklanmalıdır. Model depoları aşağıdaki avantajları sağlar:
İzleme ve değerlendirme. Üretimdeki modelleri izleyin ve değerlendirme ile tahmin kalitesi metriklerini anlayın.
Model yayınlama süreci. Modelleri kolayca inceleyebilir, onaylayabilir, yayınlayabilir veya geri alabilirsiniz.
Yeniden üretilebilirlik ve hata ayıklama. Bir modelin veri kümelerini ve dağıtımlar arasındaki bağımlılıklarını izleyerek model sonuçlarını yeniden üretin ve sorunları daha etkili bir şekilde ayıklayın.
Keşfedilebilirlik. Başkalarının modelinizi bulmasını kolaylaştırın. Diğer ekipler daha sonra modelinizin (veya modelinizin bir bölümünün) kendi amaçları için kullanılıp kullanılamayacağını belirleyebilir.
Şekil 10'da, bir model deposunda saklanan doğrulanmış bir model gösterilmektedir.
Model depolama
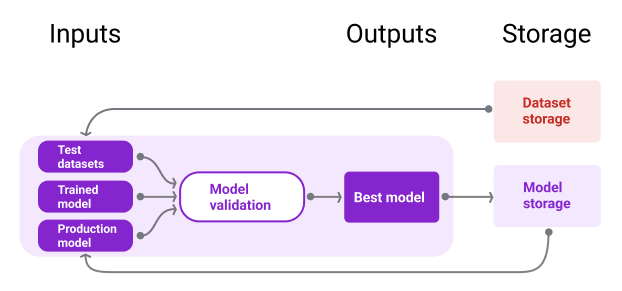
Şekil 10. Doğrulanmış modeller, izleme ve bulunabilirlik için bir model deposunda saklanır.
Modelinizle ilgili temel bilgileri (ör. amacı, mimarisi, donanım gereksinimleri, değerlendirme metrikleri) belgelemek ve paylaşmak için model kartlarını kullanın.
Anlayıp anlamadığınızı kontrol etme
Ardışık düzen oluşturmayla ilgili zorluklar
İşlem hatları oluştururken aşağıdaki zorluklarla karşılaşabilirsiniz:
İhtiyacınız olan verilere erişme. Veri erişimi için neden ihtiyacınız olduğunu açıklamanız gerekebilir. Örneğin, verilerin nasıl kullanılacağını açıklamanız ve kimliği tanımlayabilecek bilgiler (PII) ile ilgili sorunların nasıl çözüleceğini netleştirmeniz gerekebilir. Modelinizin belirli türdeki verilere erişerek nasıl daha iyi tahminler yaptığını gösteren bir konsept kanıtı sunmaya hazır olun.
Doğru özellikleri kullanma Bazı durumlarda, deneme aşamasında kullanılan özellikler gerçek zamanlı verilerde kullanılamaz. Bu nedenle, deneme yaparken üretimde aynı özellikleri kullanabileceğinizi onaylamaya çalışın.
Verilerin nasıl toplandığını ve gösterildiğini anlama. Verilerin nasıl toplandığını, kimin topladığını ve nasıl toplandığını (diğer sorunlarla birlikte) öğrenmek zaman ve çaba gerektirebilir. Verileri iyice anlamak önemlidir. Üretime girebilecek bir modeli eğitmek için güvenmediğiniz verileri kullanmayın.
Çaba, maliyet ve model kalitesi arasındaki ödünleşimleri anlama. Yeni bir özelliği veri ardışık düzenine dahil etmek çok fazla çaba gerektirebilir. Ancak ek özellik, modelin kalitesini yalnızca biraz iyileştirebilir. Diğer durumlarda ise yeni bir özellik eklemek kolay olabilir. Ancak, bu özelliği edinme ve saklama kaynakları çok pahalı olabilir.
İşlem gücü edinme. Yeniden eğitme için TPU'lara ihtiyacınız varsa gerekli kotayı almak zor olabilir. Ayrıca, TPU'ları yönetmek de karmaşıktır. Örneğin, modelinizin veya verilerinizin bazı bölümlerinin, birden fazla TPU çipine bölünerek TPU'lar için özel olarak tasarlanması gerekebilir.
Doğru altın veri kümesini bulma. Veriler sık sık değişiyorsa tutarlı ve doğru etiketlere sahip altın veri kümeleri elde etmek zor olabilir.
Bu tür sorunları deneme sırasında tespit etmek zaman kazandırır. Örneğin, en iyi özellikleri ve modeli geliştirip bunların üretimde uygun olmadığını öğrenmek istemezsiniz. Bu nedenle, çözümünüzün üretim ortamının kısıtlamaları dahilinde çalışacağını mümkün olduğunca erken onaylamaya çalışın. İşlem hattı aşamasında aşılması zor sorunlar ortaya çıktığı için deneme aşamasına geri dönmek zorunda kalmak yerine, çözümün işe yaradığını doğrulamak için zaman harcamak daha iyidir.