En el AA de producción, el objetivo no es compilar un solo modelo y, luego, implementarlo. El objetivo es crear canalizaciones automatizadas para desarrollar, probar e implementar modelos con el tiempo. ¿Por qué? A medida que el mundo cambia, las tendencias en los datos se modifican, lo que provoca que los modelos en producción queden obsoletos. Por lo general, los modelos deben volver a entrenarse con datos actualizados para seguir ofreciendo predicciones de alta calidad a largo plazo. En otras palabras, querrás una forma de reemplazar los modelos obsoletos por modelos nuevos.
Sin canalizaciones, reemplazar un modelo desactualizado es un proceso propenso a errores. Por ejemplo, una vez que un modelo comienza a entregar predicciones incorrectas, alguien deberá recopilar y procesar datos nuevos de forma manual, entrenar un modelo nuevo, validar su calidad y, luego, implementarlo. Las canalizaciones de AA automatizan muchos de estos procesos repetitivos, lo que hace que la administración y el mantenimiento de los modelos sean más eficientes y confiables.
Compilación de canalizaciones
Las canalizaciones de AA organizan los pasos para compilar e implementar modelos en tareas bien definidas. Las canalizaciones tienen una de las siguientes dos funciones: entregar predicciones o actualizar el modelo.
Entrega de predicciones
La canalización de entrega proporciona predicciones. Expone tu modelo al mundo real, lo que lo hace accesible para tus usuarios. Por ejemplo, cuando un usuario quiere una predicción (cómo estará el clima mañana, cuántos minutos tardará en llegar al aeropuerto o una lista de videos recomendados), la canalización de publicación recibe y procesa los datos del usuario, hace una predicción y, luego, se la entrega al usuario.
Actualización del modelo
Los modelos tienden a volverse obsoletos casi inmediatamente después de que se implementan en producción. En esencia, hacen predicciones con información antigua. Sus conjuntos de datos de entrenamiento capturaron el estado del mundo hace un día o, en algunos casos, hace una hora. Inevitablemente, el mundo cambió: un usuario miró más videos y necesita una nueva lista de recomendaciones; la lluvia provocó que el tráfico se ralentizara y los usuarios necesitan estimaciones actualizadas de sus horas de llegada; una tendencia popular hace que los minoristas soliciten predicciones de inventario actualizadas para ciertos artículos.
Por lo general, los equipos entrenan modelos nuevos mucho antes de que el modelo de producción quede obsoleto. En algunos casos, los equipos entrenan y, luego, implementan modelos nuevos a diario en un ciclo continuo de entrenamiento e implementación. Lo ideal es entrenar un modelo nuevo mucho antes de que el modelo de producción se vuelva obsoleto.
Las siguientes canalizaciones funcionan en conjunto para entrenar un modelo nuevo:
- Canalización de datos. La canalización de datos procesa los datos del usuario para crear conjuntos de datos de entrenamiento y prueba.
- Canalización de entrenamiento. La canalización de entrenamiento entrena modelos con los nuevos conjuntos de datos de entrenamiento de la canalización de datos.
- Canalización de validación La canalización de validación valida el modelo entrenado comparándolo con el modelo de producción a través de conjuntos de datos de prueba generados por la canalización de datos.
En la figura 4, se ilustran las entradas y salidas de cada canalización de AA.
Canalizaciones de AA
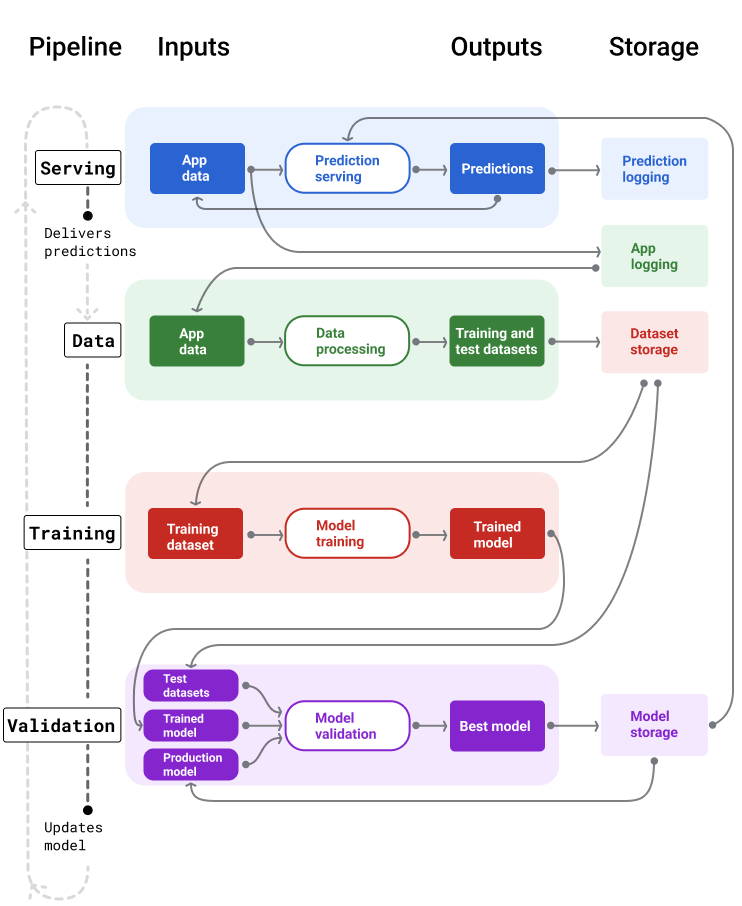
Figura 4. Las canalizaciones de AA automatizan muchos procesos para desarrollar y mantener modelos. Cada canalización muestra sus entradas y salidas.
A un nivel muy general, así es como las canalizaciones mantienen un modelo actualizado en producción:
Primero, un modelo se pone en producción y la canalización de entrega comienza a proporcionar predicciones.
La canalización de datos comienza de inmediato a recopilar datos para generar nuevos conjuntos de datos de entrenamiento y prueba.
Según un programa o un activador, las canalizaciones de entrenamiento y validación entrenan y validan un modelo nuevo con los conjuntos de datos que genera la canalización de datos.
Cuando la canalización de validación confirma que el modelo nuevo no es peor que el modelo de producción, se implementa el modelo nuevo.
Este proceso se repite continuamente.
Inactividad del modelo y frecuencia de entrenamiento
Casi todos los modelos se vuelven obsoletos. Algunos modelos se vuelven obsoletos más rápido que otros. Por ejemplo, los modelos que recomiendan ropa suelen volverse obsoletos rápidamente porque las preferencias de los consumidores cambian con frecuencia. Por otro lado, los modelos que identifican flores tal vez nunca queden inactivos. Las características de identificación de una flor permanecen estables.
La mayoría de los modelos comienzan a volverse obsoletos inmediatamente después de que se ponen en producción. Te recomendamos que establezcas una frecuencia de entrenamiento que refleje la naturaleza de tus datos. Si los datos son dinámicos, entrena el modelo con frecuencia. Si es menos dinámico, es posible que no necesites entrenar con tanta frecuencia.
Entrena los modelos antes de que se vuelvan obsoletos. El entrenamiento anticipado proporciona un búfer para resolver posibles problemas, por ejemplo, si fallan los datos o la canalización de entrenamiento, o si la calidad del modelo es deficiente.
Una práctica recomendada es entrenar e implementar modelos nuevos a diario. Al igual que los proyectos de software normales que tienen un proceso diario de compilación y lanzamiento, las canalizaciones de AA para el entrenamiento y la validación suelen funcionar mejor cuando se ejecutan a diario.
Comprueba tu comprensión
Canalización de procesamiento
La canalización de entrega genera y proporciona predicciones de dos maneras: en línea o sin conexión.
Predicciones en línea Las predicciones en línea se realizan en tiempo real, por lo general, mediante el envío de una solicitud a un servidor en línea y la devolución de una predicción. Por ejemplo, cuando un usuario quiere una predicción, sus datos se envían al modelo, y este devuelve la predicción.
Predicciones sin conexión Las predicciones sin conexión se calculan previamente y se almacenan en caché. Para entregar una predicción, la app busca la predicción almacenada en caché en la base de datos y la devuelve. Por ejemplo, un servicio basado en suscripciones podría predecir la tasa de deserción de sus suscriptores. El modelo predice la probabilidad de abandono para cada suscriptor y la almacena en caché. Cuando la app necesita la predicción (por ejemplo, para incentivar a los usuarios que podrían abandonar la plataforma), solo busca la predicción precalculada.
En la figura 5, se muestra cómo se generan y entregan las predicciones en línea y sin conexión.
Predicciones en línea y sin conexión
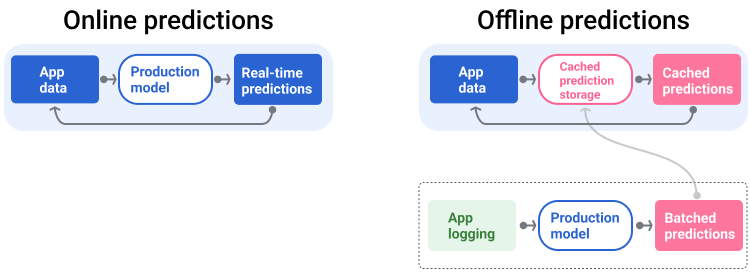
Figura 5. Las predicciones en línea entregan predicciones en tiempo real. Las predicciones sin conexión se almacenan en caché y se consultan en el momento de la publicación.
Posprocesamiento de la predicción
Por lo general, las predicciones se procesan posteriormente antes de entregarse. Por ejemplo, es posible que se procesen las predicciones después de generarlas para quitar el contenido tóxico o sesgado. Los resultados de clasificación puedenpara reordenarse en lugar de mostrar el resultado sin procesar del modelo, por ejemplo, para impulsar el contenido más autorizado, presentar una diversidad de resultados, degradar resultados particulares (como el clickbait) o quitar resultados por motivos legales.
En la figura 6, se muestra una canalización de entrega y las tareas típicas que implica la entrega de predicciones.
Predicciones de posprocesamiento
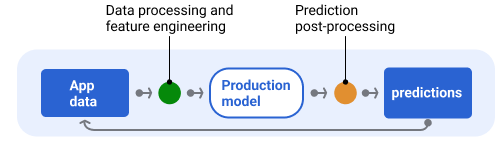
Figura 6. Canalización de entrega que ilustra las tareas típicas involucradas en la entrega de predicciones.
Ten en cuenta que el paso de ingeniería de funciones suele incorporarse al modelo y no es un proceso independiente. El código de procesamiento de datos en la canalización de entrega suele ser casi idéntico al código de procesamiento de datos que usa la canalización de datos para crear conjuntos de datos de entrenamiento y prueba.
Almacenamiento de recursos y metadatos
La canalización de entrega debe incorporar un repositorio para registrar las predicciones del modelo y, si es posible, la verdad fundamental.
El registro de las predicciones del modelo te permite supervisar su calidad. Si agregas las predicciones, puedes supervisar la calidad general de tu modelo y determinar si está comenzando a perder calidad. En general, las predicciones del modelo de producción deben tener el mismo promedio que las etiquetas del conjunto de datos de entrenamiento. Para obtener más información, consulta sesgo de predicción.
Cómo capturar la verdad fundamental
En algunos casos, la verdad fundamental solo está disponible mucho después. Por ejemplo, si una app del clima predice el clima con seis semanas de anticipación, la verdad fundamental (cómo es realmente el clima) no estará disponible durante seis semanas.
Cuando sea posible, haz que los usuarios informen la verdad fundamental agregando mecanismos de comentarios en la app. Una app de correo puede capturar de forma implícita los comentarios de los usuarios cuando estos mueven correos de su carpeta Recibidos a la carpeta de spam. Sin embargo, esto solo funciona cuando el usuario categoriza correctamente su correo. Cuando los usuarios dejan spam en su carpeta Recibidos (porque saben que es spam y nunca lo abren), los datos de entrenamiento se vuelven imprecisos. Ese correo en particular se etiquetará como "no es spam" cuando debería ser "spam". En otras palabras, siempre intenta encontrar formas de capturar y registrar la verdad fundamental, pero ten en cuenta las deficiencias que podrían existir en los mecanismos de comentarios.
En la figura 7, se muestran las predicciones que se entregan a un usuario y se registran en un repositorio.
Registro de predicciones
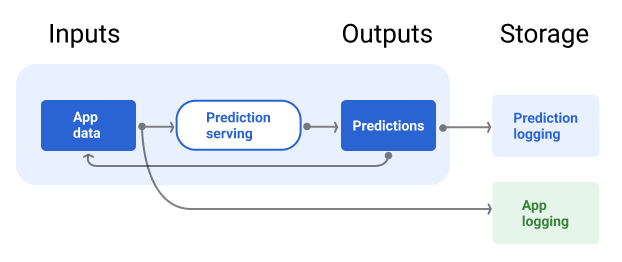
Figura 7. Registra las predicciones para supervisar la calidad del modelo.
Canalizaciones de datos
Las canalizaciones de datos generan conjuntos de datos de entrenamiento y prueba a partir de los datos de la aplicación. Luego, las canalizaciones de entrenamiento y validación usan los conjuntos de datos para entrenar y validar modelos nuevos.
La canalización de datos crea conjuntos de datos de entrenamiento y prueba con las mismas características y etiquetas que se usaron originalmente para entrenar el modelo, pero con información más reciente. Por ejemplo, una app de mapas generaría conjuntos de datos de entrenamiento y prueba a partir de los tiempos de viaje recientes entre puntos para millones de usuarios, junto con otros datos relevantes, como el clima.
Una app de recomendaciones de videos generaría conjuntos de datos de entrenamiento y prueba que incluirían los videos en los que un usuario hizo clic desde la lista de recomendaciones (junto con los que no se hicieron clic), así como otros datos relevantes, como el historial de reproducciones.
En la figura 8, se ilustra la canalización de datos que usa datos de la aplicación para generar conjuntos de datos de entrenamiento y prueba.
Canalización de datos
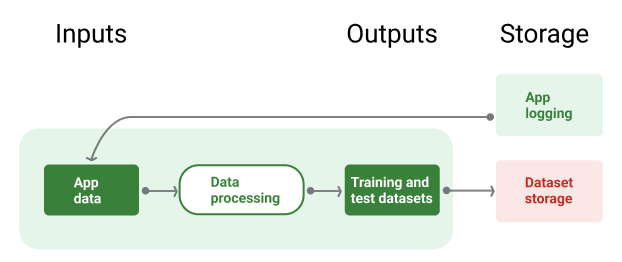
Figura 8. La canalización de datos procesa los datos de la aplicación para crear conjuntos de datos para las canalizaciones de entrenamiento y validación.
Recopilación y procesamiento de datos
Las tareas para recopilar y procesar datos en las canalizaciones de datos probablemente difieran de las de la fase de experimentación (en la que determinaste que tu solución era factible):
Recopilación de datos. Durante la experimentación, la recopilación de datos suele requerir el acceso a los datos guardados. En el caso de las canalizaciones de datos, la recopilación de datos puede requerir el descubrimiento y la obtención de aprobación para acceder a los datos de los registros de transmisión.
Si necesitas datos etiquetados por personas (como imágenes médicas), también necesitarás un proceso para recopilarlos y actualizarlos.
Tratamiento de datos. Durante la experimentación, las funciones adecuadas se obtuvieron a partir del scraping, la unión y el muestreo de los conjuntos de datos de experimentación. En el caso de las canalizaciones de datos, generar esos mismos atributos podría requerir procesos completamente diferentes. Sin embargo, asegúrate de duplicar las transformaciones de datos de la fase de experimentación aplicando las mismas operaciones matemáticas a las etiquetas y los atributos.
Almacenamiento de recursos y metadatos
Necesitarás un proceso para almacenar, controlar las versiones y administrar tus conjuntos de datos de entrenamiento y prueba. Los repositorios con control de versión proporcionan los siguientes beneficios:
Reproducibilidad. Recrea y estandariza los entornos de entrenamiento de modelos, y compara la calidad de las predicciones entre diferentes modelos.
Cumplimiento. Cumple con los requisitos de cumplimiento normativo para la auditabilidad y la transparencia.
Retención. Establece los valores de retención de datos para determinar durante cuánto tiempo se almacenarán los datos.
Administración de acceso Administra quién puede acceder a tus datos a través de permisos detallados.
Integridad de los datos. Realiza un seguimiento de los cambios en los conjuntos de datos a lo largo del tiempo y comprendelos, lo que facilita el diagnóstico de problemas con tus datos o tu modelo.
Descubrimiento. Facilita que otras personas encuentren tus conjuntos de datos y funciones. Luego, otros equipos pueden determinar si serían útiles para sus propósitos.
Cómo documentar tus datos
Una buena documentación ayuda a otras personas a comprender información clave sobre tus datos, como su tipo, fuente, tamaño y otros metadatos esenciales. En la mayoría de los casos, es suficiente con documentar tus datos en un documento de diseño . Si planeas compartir o publicar tus datos, usa tarjetas de datos para estructurar la información. Las tarjetas de datos facilitan que otros usuarios descubran y comprendan tus conjuntos de datos.
Canalizaciones de entrenamiento y validación
Las canalizaciones de entrenamiento y validación producen modelos nuevos para reemplazar los modelos de producción antes de que queden obsoletos. El entrenamiento y la validación continuos de modelos nuevos garantizan que el mejor modelo esté siempre en producción.
La canalización de entrenamiento genera un modelo nuevo a partir de los conjuntos de datos de entrenamiento, y la canalización de validación compara la calidad del modelo nuevo con el que se encuentra en producción usando conjuntos de datos de prueba.
En la figura 9, se ilustra la canalización de entrenamiento con un conjunto de datos de entrenamiento para entrenar un modelo nuevo.
Canalización de entrenamiento
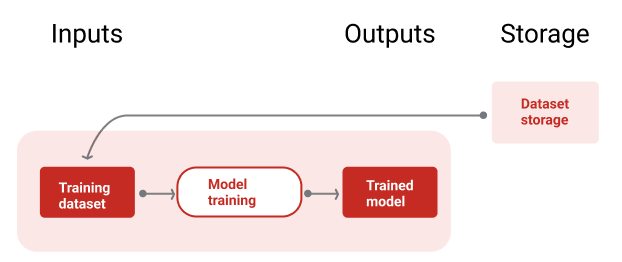
Figura 9. La canalización de entrenamiento entrena modelos nuevos con el conjunto de datos de entrenamiento más reciente.
Después de entrenar el modelo, la canalización de validación usa conjuntos de datos de prueba para comparar la calidad del modelo de producción con la del modelo entrenado.
En general, si el modelo entrenado no es significativamente peor que el modelo de producción, se pone en producción. Si el modelo entrenado es peor, la infraestructura de supervisión debería crear una alerta. Los modelos entrenados con una calidad de predicción inferior podrían indicar posibles problemas con las canalizaciones de datos o validación. Este enfoque garantiza que el mejor modelo, entrenado con los datos más recientes, siempre esté en producción.
Almacenamiento de recursos y metadatos
Los modelos y sus metadatos deben almacenarse en repositorios con versiones para organizar y hacer un seguimiento de las implementaciones de modelos. Los repositorios de modelos proporcionan los siguientes beneficios:
Seguimiento y evaluación. Hacer un seguimiento de los modelos en producción y comprender sus métricas de calidad de evaluación y predicción
Proceso de lanzamiento del modelo. Revisa, aprueba, lanza o revierte modelos con facilidad.
Reproducibilidad y depuración. Reproduce los resultados del modelo y depura los problemas de manera más eficaz haciendo un seguimiento de los conjuntos de datos y las dependencias de un modelo en todas las implementaciones.
Descubrimiento. Haz que sea fácil para otras personas encontrar tu modelo. Luego, otros equipos pueden determinar si tu modelo (o partes de él) se puede usar para sus propósitos.
En la Figura 10, se ilustra un modelo validado almacenado en un repositorio de modelos.
Almacenamiento de modelos
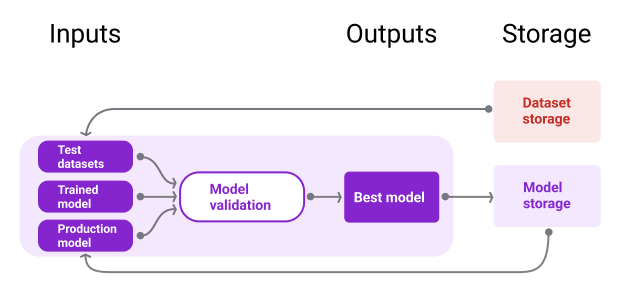
Figura 10: Los modelos validados se almacenan en un repositorio de modelos para el seguimiento y la detección.
Usa tarjetas de modelo para documentar y compartir información clave sobre tu modelo, como su propósito, arquitectura, requisitos de hardware, métricas de evaluación, etcétera.
Comprueba tu comprensión
Desafíos de la compilación de canalizaciones
Cuando crees canalizaciones, es posible que te encuentres con los siguientes desafíos:
Cómo obtener acceso a los datos que necesitas Es posible que debas justificar por qué necesitas acceder a los datos. Por ejemplo, es posible que debas explicar cómo se usarán los datos y aclarar cómo se resolverán los problemas relacionados con la información de identificación personal (PII). Prepárate para mostrar una prueba de concepto que demuestre cómo tu modelo realiza mejores predicciones con acceso a ciertos tipos de datos.
Obtener las funciones adecuadas En algunos casos, las funciones que se usan en la fase de experimentación no estarán disponibles en los datos en tiempo real. Por lo tanto, cuando experimentes, intenta confirmar que podrás obtener las mismas funciones en producción.
Comprender cómo se recopilan y representan los datos Aprender cómo se recopilaron los datos, quién los recopiló y cómo se recopilaron (junto con otros problemas) puede llevar tiempo y esfuerzo. Es importante comprender los datos a fondo. No uses datos en los que no confíes para entrenar un modelo que podría pasar a producción.
Comprender las compensaciones entre el esfuerzo, el costo y la calidad del modelo Incorporar una nueva función en una canalización de datos puede requerir mucho esfuerzo. Sin embargo, es posible que la función adicional solo mejore ligeramente la calidad del modelo. En otros casos, agregar una función nueva puede ser fácil. Sin embargo, los recursos para obtener y almacenar la función pueden ser prohibitivamente costosos.
Cómo obtener recursos de procesamiento Si necesitas TPU para volver a entrenar el modelo, es posible que sea difícil obtener la cuota requerida. Además, administrar las TPU es complicado. Por ejemplo, es posible que algunas partes de tu modelo o datos deban diseñarse específicamente para las TPU dividiendo partes de ellas en varios chips de TPU.
Cómo encontrar el conjunto de datos de referencia adecuado Si los datos cambian con frecuencia, puede ser difícil obtener conjuntos de datos de referencia con etiquetas coherentes y precisas.
Detectar este tipo de problemas durante la experimentación ahorra tiempo. Por ejemplo, no querrás desarrollar los mejores atributos y el mejor modelo solo para descubrir que no son viables en la producción. Por lo tanto, intenta confirmar lo antes posible que tu solución funcionará dentro de las limitaciones de un entorno de producción. Es mejor dedicar tiempo a verificar que una solución funcione en lugar de tener que volver a la fase de experimentación porque la fase de canalización reveló problemas insuperables.