ב-ML בסביבת ייצור, המטרה היא לא ליצור מודל יחיד ולפרוס אותו. המטרה היא ליצור צינורות עיבוד נתונים אוטומטיים לפיתוח, לבדיקה ולפריסה של מודלים לאורך זמן. למה? העולם משתנה, המגמות בנתונים משתנות, והמודלים בייצור מתיישנים. בדרך כלל, כדי שהמודלים ימשיכו לספק תחזיות איכותיות לאורך זמן, צריך לאמן אותם מחדש עם נתונים עדכניים. במילים אחרות, תצטרכו דרך להחליף מודלים ישנים במודלים חדשים.
בלי צינורות עיבוד נתונים, החלפת מודל ישן היא תהליך שמועד לשגיאות. לדוגמה, אם מודל מתחיל לספק תחזיות לא טובות, מישהו יצטרך לאסוף ולעבד נתונים חדשים באופן ידני, לאמן מודל חדש, לאמת את האיכות שלו ואז לפרוס אותו. צינורות עיבוד נתונים של למידת מכונה הופכים הרבה מהתהליכים החוזרים האלה לאוטומטיים, וכך הניהול והתחזוקה של המודלים הופכים ליעילים ואמינים יותר.
פיתוח של צינורות עיבוד נתונים
צינורות ML מארגנים את השלבים ליצירה ולפריסה של מודלים למשימות מוגדרות היטב. לצינורות יש אחת משתי פונקציות: אספקת תחזיות או עדכון המודל.
הצגת חיזויים
צינור העיבוד של התחזיות מספק תחזיות. הפעולה הזו חושפת את המודל שלכם לעולם האמיתי, ומאפשרת למשתמשים שלכם לגשת אליו. לדוגמה, כשמשתמש רוצה לקבל תחזית – מה יהיה מזג האוויר מחר, כמה דקות ייקח להגיע לשדה התעופה או רשימה של סרטונים מומלצים – צינור העברת הנתונים מקבל את הנתונים של המשתמש ומעבד אותם, יוצר תחזית ואז מעביר אותה למשתמש.
עדכון המודל
המודלים נוטים להתיישן כמעט מיד אחרי שהם עוברים לסביבת ייצור. במילים אחרות, הם מנבאים תוצאות על סמך מידע ישן. מערכי הנתונים לאימון שלהם תיעדו את מצב העולם לפני יום, או במקרים מסוימים, לפני שעה. העולם משתנה כל הזמן: משתמש צפה ביותר סרטונים וצריך רשימה חדשה של המלצות; גשם גרם להאטה בתנועה והמשתמשים צריכים הערכות מעודכנות של זמני ההגעה שלהם; טרנד פופולרי גורם לקמעונאים לבקש תחזיות מעודכנות של מלאי לפריטים מסוימים.
בדרך כלל, צוותים מאמנים מודלים חדשים הרבה לפני שהמודל בסביבת הייצור מתיישן. במקרים מסוימים, צוותים מאמנים ופורסים מודלים חדשים מדי יום במחזור אימון ופריסה רציף. מומלץ לאמן מודל חדש הרבה לפני שהמודל בסביבת הייצור מתיישן.
צינורות הנתונים הבאים פועלים יחד כדי לאמן מודל חדש:
- צינור נתונים. צינור עיבוד הנתונים מעבד את נתוני המשתמשים כדי ליצור מערכי נתונים לאימון ולבדיקה.
- צינור עיבוד נתונים לאימון. צינור האימון מאמן מודלים באמצעות מערכי האימון החדשים מצינור הנתונים.
- צינור אימות. צינור האימות מאמת את המודל שאומן על ידי השוואה שלו עם מודל הייצור באמצעות מערכי נתונים לבדיקה שנוצרו על ידי צינור הנתונים.
איור 4 מציג את נתוני הקלט והפלט של כל צינור עיבוד נתונים של ML.
צינורות עיבוד נתונים של למידת מכונה
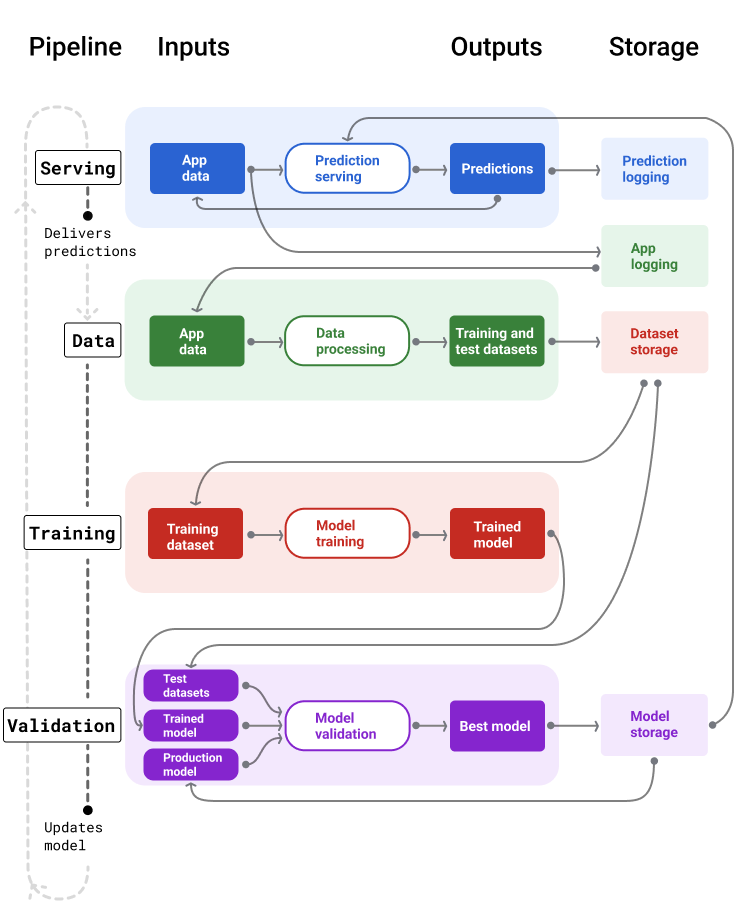
איור 4. צינורות עיבוד נתונים של למידת מכונה הופכים תהליכים רבים לפיתוח ולתחזוקה של מודלים לאוטומטיים. בכל צינור עיבוד נתונים מוצגים הקלטים והפלטים שלו.
ברמה כללית מאוד, כך צינורות העיבוד שומרים על מודל עדכני בסביבת הייצור:
קודם, מודל עובר לסביבת הייצור, וצינור ההעברה מתחיל להעביר תחזיות.
צינור הנתונים מתחיל מיד לאסוף נתונים כדי ליצור מערכי נתונים חדשים לאימון ולבדיקה.
על סמך לוח זמנים או טריגר, צינורות האימון והאימות מאמנים ומאמתים מודל חדש באמצעות מערכי הנתונים שנוצרו על ידי צינור הנתונים.
כאשר צינור האימות מאשר שהמודל החדש לא גרוע יותר מהמודל הפועל, המודל החדש נפרס.
התהליך הזה חוזר על עצמו שוב ושוב.
התיישנות המודל ותדירות האימון
כמעט כל המודלים מתיישנים. חלק מהמודלים מתיישנים מהר יותר מאחרים. לדוגמה, מודלים שממליצים על בגדים מתיישנים בדרך כלל מהר כי ההעדפות של הצרכנים משתנות בתדירות גבוהה. לעומת זאת, יכול להיות שמודלים שמזהים פרחים אף פעם לא יתיישנו. המאפיינים המזהים של הפרח נשארים יציבים.
רוב המודלים מתחילים להתיישן מיד אחרי שהם מועברים לייצור. מומלץ להגדיר תדירות אימון שתשקף את אופי הנתונים. אם הנתונים דינמיים, כדאי לאמן את המודל לעיתים קרובות. אם הוא פחות דינמי, יכול להיות שלא תצטרכו לאמן אותו בתדירות גבוהה.
כדאי לאמן מודלים לפני שהם מתיישנים. אימון מוקדם מספק חיץ לפתרון בעיות פוטנציאליות, למשל, אם הנתונים או צינור האימון נכשלים, או אם איכות המודל ירודה.
השיטה המומלצת היא לאמן ולפרוס מודלים חדשים על בסיס יומי. בדומה לפרויקטים רגילים של תוכנה שיש להם תהליך יומי של בנייה ושחרור, צינורות ML לאימון ואימות פועלים בצורה הכי טובה כשמריצים אותם מדי יום.
בדיקת ההבנה
צינור עיבוד נתונים להצגת מודעות
צינור העיבוד של התחזיות יוצר ומספק תחזיות באחת משתי דרכים: אונליין או אופליין.
תחזיות אונליין. חיזוי אונליין מתבצע בזמן אמת, בדרך כלל על ידי שליחת בקשה לשרת אונליין והחזרת חיזוי. לדוגמה, כשמשתמש רוצה לקבל תחזית, הנתונים של המשתמש נשלחים למודל והמודל מחזיר את התחזית.
חיזויים אופליין. תחזיות אופליין מחושבות מראש ונשמרות במטמון. כדי להציג תחזית, האפליקציה מאתרת את התחזית ששמורה במטמון במסד הנתונים ומחזירה אותה. לדוגמה, שירות שמבוסס על מינוי יכול לחזות את שיעור הנטישה של המנויים שלו. המודל חוזה את הסבירות לנטישה עבור כל מנוי ומאחסן את הנתונים במטמון. כשהאפליקציה צריכה את התחזית – למשל, כדי לתת תמריץ למשתמשים שעומדים לבטל את המינוי – היא פשוט מחפשת את התחזית שחושבה מראש.
באיור 5 מוצג תהליך היצירה וההצגה של חיזויים אונליין ואופליין.
תחזיות אונליין ואופליין
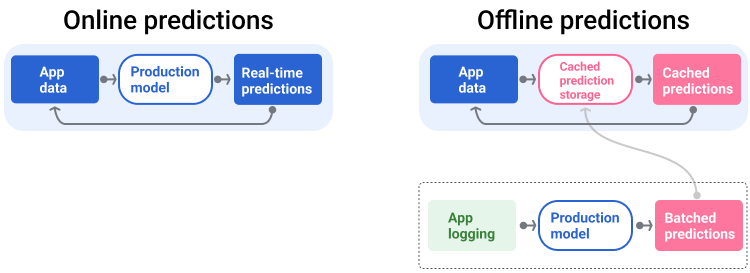
איור 5. חיזויים אונליין מספקים חיזויים בזמן אמת. תחזיות אופליין נשמרות במטמון ומבוצע חיפוש שלהן בזמן הצגת המודעה.
עיבוד נתונים אחרי חיזוי
בדרך כלל, המערכת מבצעת עיבוד לאחר מכן לתחזיות לפני שהיא מספקת אותן. לדוגמה, יכול להיות שנעבד את התחזיות כדי להסיר תוכן רעיל או מוטה. יכול להיות שהתוצאות של הסיווג כדי לשנות את הסדר שלהן במקום להציג את הפלט הגולמי של המודל. לדוגמה, כדי להציג תוכן מהימן יותר, להציג מגוון תוצאות, להוריד את הדירוג של תוצאות מסוימות (כמו קליקבייט) או להסיר תוצאות מסיבות משפטיות.
איור 6 מציג צינור להצגת נתונים ואת המשימות האופייניות שקשורות להצגת תחזיות.
עיבוד שלאחר החיזוי
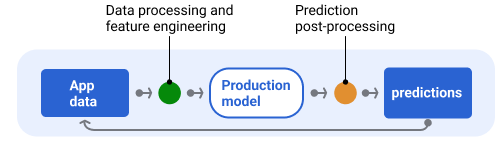
איור 6. צינור עיבוד נתונים להצגת מודל שממחיש את המשימות הטיפוסיות שנדרשות כדי לספק תחזיות.
חשוב לדעת ששלב הנדסת התכונות בדרך כלל מובנה בתוך המודל ולא מתבצע כתהליך נפרד ועצמאי. קוד עיבוד הנתונים בצינור ההגשה זהה כמעט תמיד לקוד עיבוד הנתונים שצינור הנתונים משתמש בו כדי ליצור מערכי נתונים לאימון ולבדיקה.
אחסון נכסים ומטא-נתונים
צינור העיבוד של הצגת המודל צריך לכלול מאגר לרישום של התחזיות של המודל, ואם אפשר, גם את נתוני האמת.
רישום של חיזויים של מודלים מאפשר לכם לעקוב אחרי איכות המודל. על ידי צבירת תחזיות, אפשר לעקוב אחרי האיכות הכללית של המודל ולקבוע אם האיכות שלו מתחילה לרדת. באופן כללי, הממוצע של התחזיות של מודל הייצור צריך להיות זהה לממוצע של התוויות ממערך הנתונים לאימון. מידע נוסף זמין במאמר בנושא הטיה בחיזוי.
איסוף נתוני אמת
במקרים מסוימים, הנתונים המאומתים זמינים רק הרבה יותר מאוחר. לדוגמה, אם אפליקציית מזג אוויר חוזה את מזג האוויר שישה שבועות קדימה, נתוני האמת (מה מזג האוויר בפועל) לא יהיו זמינים במשך שישה שבועות.
אם אפשר, כדאי להוסיף לאפליקציה מנגנונים למשוב כדי שהמשתמשים יוכלו לדווח על האמת. אפליקציית אימייל יכולה לתעד משוב משתמשים באופן מרומז כשהמשתמשים מעבירים אימייל מתיבת הדואר הנכנס לתיקיית הספאם. עם זאת, זה עובד רק אם המשתמשים מסווגים את האימיילים שלהם בצורה נכונה. אם משתמשים משאירים ספאם בתיבת הדואר הנכנס שלהם (כי הם יודעים שזה ספאם והם אף פעם לא פותחים אותו), נתוני האימון הופכים ללא מדויקים. הודעת האימייל הספציפית הזו תסומן כ'לא ספאם' במקום כ'ספאם'. במילים אחרות, תמיד כדאי לחפש דרכים לתעד את האמת הבסיסית, אבל חשוב להיות מודעים לחסרונות שעלולים להיות במנגנוני המשוב.
באיור 7 מוצגים חיזויים שמועברים למשתמש ונרשמים במאגר.
רישום חיזויים ביומן
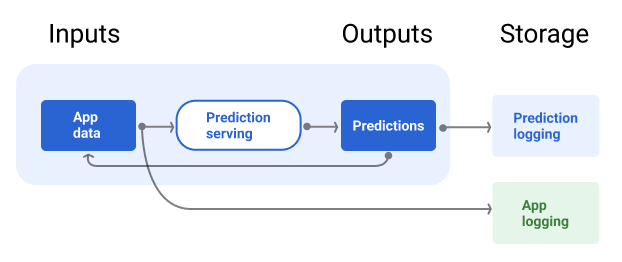
איור 7. מתעדים את התחזיות כדי לעקוב אחרי איכות המודל.
צינורות נתונים
צינורות נתונים יוצרים מערכי נתונים לאימון ולבדיקה מנתוני האפליקציה. לאחר מכן, צינורות האימון והאימות משתמשים במערכי הנתונים כדי לאמן ולאמת מודלים חדשים.
צינור הנתונים יוצר מערכי נתונים לאימון ולבדיקה עם אותן תכונות ותווית ששימשו במקור לאימון המודל, אבל עם מידע חדש יותר. לדוגמה, אפליקציית מפות תיצור מערכי נתונים לאימון ולבדיקה מנתוני זמני נסיעה עדכניים בין נקודות של מיליוני משתמשים, יחד עם נתונים רלוונטיים אחרים, כמו מזג האוויר.
אפליקציה להמלצות על סרטונים תיצור מערכי נתונים לאימון ולבדיקה שיכללו את הסרטונים שהמשתמש לחץ עליהם מתוך רשימת ההמלצות (יחד עם הסרטונים שהוא לא לחץ עליהם), וגם נתונים רלוונטיים אחרים, כמו היסטוריית הצפייה.
איור 8 ממחיש את צינור עיבוד הנתונים באמצעות נתוני האפליקציה כדי ליצור מערכי נתונים לאימון ולבדיקה.
צינור נתונים
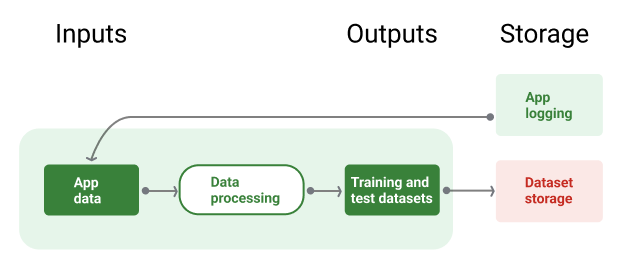
איור 8. צינור עיבוד הנתונים מעבד את נתוני האפליקציה כדי ליצור מערכי נתונים לצינורות האימון והאימות.
איסוף ועיבוד נתונים
המשימות לאיסוף ולעיבוד נתונים בצינורות נתונים כנראה יהיו שונות מאלה של שלב הניסוי (שבו קבעתם שהפתרון שלכם אפשרי):
איסוף נתונים. במהלך הניסוי, בדרך כלל צריך לגשת לנתונים השמורים כדי לאסוף נתונים. בצינורות עיבוד נתונים, יכול להיות שאיסוף הנתונים יצריך גילוי וקבלת אישור לגישה לנתוני יומנים של סטרימינג.
אם אתם צריכים נתונים עם תוויות שנוצרו על ידי בני אדם (כמו תמונות רפואיות), תצטרכו גם תהליך לאיסוף ולעדכון שלהם.
עיבוד נתונים. במהלך הניסוי, התכונות הנכונות הגיעו מגירוד, מאיחוד ומדגימה של מערכי הנתונים של הניסוי. יכול להיות שיידרשו תהליכים שונים לגמרי כדי ליצור את אותם מאפיינים בצינורות להעברת נתונים. עם זאת, חשוב לשכפל את טרנספורמציות הנתונים משלב הניסוי על ידי הפעלת אותן פעולות מתמטיות על התכונות והתוויות.
אחסון נכסים ומטא-נתונים
תצטרכו תהליך לאחסון, לניהול ולשמירת גרסאות של מערכי הנתונים לאימון ולבדיקה. מאגרי מידע עם בקרת גרסאות מספקים את היתרונות הבאים:
שחזור. ליצור מחדש סביבות לאימון מודלים ולקבוע סטנדרט אחיד להן, ולהשוות בין איכות התחזיות של מודלים שונים.
תאימות. עמידה בדרישות של תקנות בנושא שקיפות ויכולת ביקורת.
שימור משתמשים. הגדרת ערכים של שמירת נתונים כדי לקבוע כמה זמן הנתונים יישמרו.
ניהול גישה. ניהול הגישה לנתונים באמצעות הרשאות מפורטות.
תקינות נתונים. לעקוב אחרי שינויים במערכי נתונים לאורך זמן ולהבין אותם, וכך לאבחן בקלות רבה יותר בעיות בנתונים או במודל.
יכולת הגילוי. כדאי להקל על אחרים למצוא את מערכי הנתונים והתכונות שלכם. צוותים אחרים יכולים לקבוע אם הם שימושיים למטרות שלהם.
תיעוד הנתונים
תיעוד טוב עוזר לאחרים להבין מידע חשוב על הנתונים שלכם, כמו הסוג, המקור, הגודל ומטא-נתונים חיוניים אחרים. ברוב המקרים, מספיק לתעד את הנתונים במסמך תכנון . אם אתם מתכננים לשתף או לפרסם את הנתונים, כדאי להשתמש ב כרטיסי נתונים כדי לארגן את המידע. כרטיסי נתונים מקלים על אחרים לגלות ולהבין את מערכי הנתונים שלכם.
צינורות עיבוד נתונים לאימון ולאימות
צינורות האימון והאימות יוצרים מודלים חדשים שיחליפו את מודלי הייצור לפני שהם יתיישנו. אנחנו מאמנים ומאמתים מודלים חדשים באופן רציף כדי לוודא שהמודל הכי טוב נמצא תמיד בייצור.
צינור האימון יוצר מודל חדש ממערכי הנתונים לאימון, וצינור האימות משווה בין איכות המודל החדש לבין המודל שנמצא בייצור באמצעות מערכי נתונים לבדיקה.
איור 9 ממחיש את צינור האימון באמצעות מערך נתונים לאימון כדי לאמן מודל חדש.
צינור עיבוד נתונים לאימון
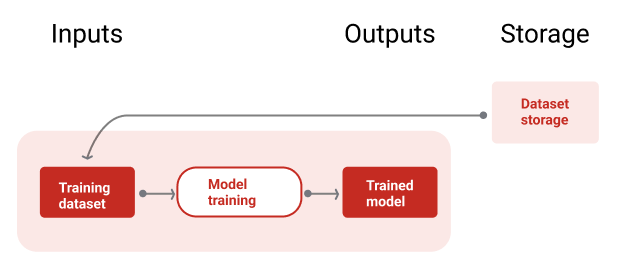
איור 9. צינור האימון מאמן מודלים חדשים באמצעות מערך הנתונים העדכני ביותר לאימון.
אחרי שהמודל עובר אימון, צינור האימות משתמש במערכי נתוני בדיקה כדי להשוות בין איכות המודל בייצור לבין המודל שעבר אימון.
באופן כללי, אם המודל שאומן לא גרוע משמעותית מהמודל בסביבת הייצור, המודל שאומן עובר לסביבת הייצור. אם המודל המאומן גרוע יותר, תשתית המעקב צריכה ליצור התראה. מודלים שעברו אימון עם איכות חיזוי נמוכה יותר יכולים להצביע על בעיות פוטנציאליות בנתונים או בצינורות האימות. הגישה הזו מבטיחה שהמודל הטוב ביותר, שאומן על הנתונים העדכניים ביותר, תמיד יהיה בייצור.
אחסון נכסים ומטא-נתונים
כדי לארגן ולעקוב אחרי פריסות של מודלים, צריך לאחסן את המודלים ואת המטא-נתונים שלהם במאגרי מידע עם ניהול גרסאות. מאגרי מודלים מספקים את היתרונות הבאים:
מעקב והערכה. לעקוב אחרי מודלים בייצור ולהבין את מדדי ההערכה ואיכות החיזוי שלהם.
תהליך השקת המודל. אפשר לבדוק, לאשר, להשיק או לבטל בקלות מודלים.
שחזור וניפוי באגים. לשחזר תוצאות של מודלים ועוד לפתור בעיות בצורה יעילה יותר על ידי מעקב אחרי מערכי נתונים ותלות של מודלים בפריסות.
יכולת הגילוי. כך יהיה קל יותר לאנשים אחרים למצוא את המודל שלכם. צוותים אחרים יוכלו לקבוע אם אפשר להשתמש במודל שלכם (או בחלקים ממנו) למטרות שלהם.
איור 10 מציג מודל שעבר אימות ומאוחסן במאגר מודלים.
אחסון מודלים
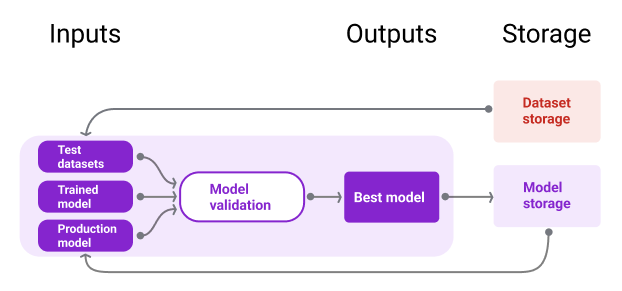
איור 10. מודלים שעברו אימות מאוחסנים במאגר מודלים לצורך מעקב ואיתור.
אפשר להשתמש ב כרטיסי מודל כדי לתעד ולשתף מידע חשוב על המודל, כמו המטרה שלו, הארכיטקטורה, דרישות החומרה, מדדי ההערכה וכו'.
בדיקת ההבנה
אתגרים בפיתוח צינורות עיבוד נתונים
כשמפתחים צינורות עיבוד נתונים, יכול להיות שתיתקלו באתגרים הבאים:
קבלת גישה לנתונים שאתם צריכים. יכול להיות שתצטרכו לנמק למה אתם צריכים גישה לנתונים. לדוגמה, יכול להיות שתצטרכו להסביר איך הנתונים ישמשו ולפרט איך ייפתרו בעיות שקשורות לפרטים אישיים מזהים (PII). צריך להיות מוכנים להציג הוכחת קונספט שמראה איך המודל שלכם יוצר תחזיות טובות יותר עם גישה לסוגים מסוימים של נתונים.
קבלת התכונות הנכונות. במקרים מסוימים, התכונות שבהן נעשה שימוש בשלב הניסוי לא יהיו זמינות מהנתונים בזמן אמת. לכן, כשעורכים ניסויים, כדאי לוודא שאפשר יהיה להשתמש באותן תכונות בסביבת הייצור.
הסבר על אופן האיסוף וההצגה של הנתונים כדי להבין איך הנתונים נאספו, מי אסף אותם ואיך הם נאספו (בנוסף לבעיות אחרות), צריך להשקיע זמן ומאמץ. חשוב להבין את הנתונים לעומק. אל תשתמשו בנתונים שאתם לא בטוחים בהם כדי לאמן מודל שאולי יעבור לסביבת ייצור.
הסבר על האיזון בין המאמץ, העלות ואיכות המודל. שילוב תכונה חדשה בצינור נתונים יכול לדרוש הרבה מאמץ. עם זאת, יכול להיות שהתכונה הנוספת תשפר רק במעט את איכות המודל. במקרים אחרים, הוספת תכונה חדשה עשויה להיות קלה. עם זאת, יכול להיות שהמשאבים שנדרשים כדי להשיג ולאחסן את התכונה יהיו יקרים מדי.
קבלת משאבי מחשוב. אם אתם צריכים יחידות TPU לאימון מחדש, יכול להיות שיהיה קשה לקבל את המכסה הנדרשת. בנוסף, הניהול של יחידות TPU הוא מורכב. לדוגמה, יכול להיות שיהיה צורך לתכנן חלקים מסוימים במודל או בנתונים במיוחד עבור TPU, על ידי פיצול חלקים שלהם בין כמה שבבי TPU.
איך מוצאים את מערך הזהב המתאים אם הנתונים משתנים לעיתים קרובות, יכול להיות שיהיה קשה להשיג מערכי נתונים מושלמים עם תוויות עקביות ומדויקות.
זיהוי בעיות מהסוג הזה במהלך הניסוי חוסך זמן. לדוגמה, לא כדאי לפתח את התכונות והמודל הכי טובים רק כדי לגלות שהם לא מתאימים לייצור. לכן, כדאי לנסות לאשר מוקדם ככל האפשר שהפתרון שלכם יפעל במסגרת המגבלות של סביבת ייצור. עדיף להשקיע זמן באימות הפתרון כדי לוודא שהוא עובד, במקום לחזור לשלב הניסוי כי בשלב צינור עיבוד הנתונים התגלו בעיות שלא ניתן לפתור.