प्रोडक्शन एमएल में, सिर्फ़ एक मॉडल बनाना और उसे डिप्लॉय करना मकसद नहीं होता. इसका मकसद, समय के साथ मॉडल को डेवलप करने, टेस्ट करने, और डिप्लॉय करने के लिए ऑटोमेटेड पाइपलाइन बनाना है. क्यों? दुनिया में बदलाव होने की वजह से, डेटा के ट्रेंड में बदलाव होता है. इससे प्रोडक्शन में मौजूद मॉडल पुराने हो जाते हैं. आम तौर पर, मॉडल को अप-टू-डेट डेटा के साथ फिर से ट्रेनिंग देने की ज़रूरत होती है, ताकि वे लंबे समय तक अच्छी क्वालिटी के अनुमान देना जारी रख सकें. दूसरे शब्दों में कहें, तो आपको पुराने मॉडल को नए मॉडल से बदलने का तरीका चाहिए होगा.
पाइपलाइन के बिना, पुराने मॉडल को बदलना एक मुश्किल प्रोसेस है. उदाहरण के लिए, जब कोई मॉडल गलत अनुमान लगाने लगता है, तो किसी व्यक्ति को नए डेटा को मैन्युअल तरीके से इकट्ठा और प्रोसेस करना होगा. साथ ही, एक नया मॉडल ट्रेन करना होगा, उसकी क्वालिटी की पुष्टि करनी होगी, और आखिर में उसे डिप्लॉय करना होगा. एमएल पाइपलाइन, बार-बार होने वाली इनमें से कई प्रोसेस को ऑटोमेट करती हैं. इससे मॉडल को मैनेज करना और उन्हें अपडेट करना ज़्यादा असरदार और भरोसेमंद हो जाता है.
पाइपलाइन बनाना
एमएल पाइपलाइन, मॉडल बनाने और उन्हें डिप्लॉय करने के चरणों को अच्छी तरह से तय किए गए टास्क में व्यवस्थित करती हैं. पाइपलाइन के दो फ़ंक्शन होते हैं: अनुमान देना या मॉडल को अपडेट करना.
अनुमानों को डिलीवर करना
सर्विंग पाइपलाइन, अनुमानों को डिलीवर करती है. इससे आपका मॉडल, असली दुनिया के लिए उपलब्ध हो जाता है. साथ ही, यह आपके उपयोगकर्ताओं के लिए ऐक्सेस किया जा सकता है. उदाहरण के लिए, जब किसी उपयोगकर्ता को कोई अनुमान चाहिए—जैसे, कल मौसम कैसा होगा, एयरपोर्ट पहुंचने में कितना समय लगेगा या सुझाए गए वीडियो की सूची—तो अनुमान लगाने वाली पाइपलाइन, उपयोगकर्ता का डेटा इकट्ठा करके उसे प्रोसेस करती है. इसके बाद, अनुमान लगाकर उपयोगकर्ता को नतीजे दिखाती है.
मॉडल को अपडेट करना
मॉडल, प्रोडक्शन में जाने के तुरंत बाद पुराने हो जाते हैं. असल में, वे पुरानी जानकारी का इस्तेमाल करके अनुमान लगा रहे हैं. इनके ट्रेनिंग डेटासेट में, एक दिन पहले या कुछ मामलों में एक घंटे पहले की दुनिया की स्थिति को कैप्चर किया गया था. दुनिया में बदलाव हो रहे हैं: किसी उपयोगकर्ता ने ज़्यादा वीडियो देखे हैं और उसे सुझावों की नई सूची चाहिए; बारिश की वजह से ट्रैफ़िक कम हो गया है और लोगों को पहुंचने के समय के अपडेट किए गए अनुमान चाहिए; किसी लोकप्रिय ट्रेंड की वजह से खुदरा दुकानदारों को कुछ सामान के लिए, इन्वेंट्री के अनुमानों को अपडेट करने का अनुरोध करना है.
आम तौर पर, टीमें प्रोडक्शन मॉडल के पुराने होने से पहले ही नए मॉडल को ट्रेन कर लेती हैं. कुछ मामलों में, टीमें लगातार ट्रेनिंग और डिप्लॉयमेंट साइकल में, हर दिन नए मॉडल को ट्रेन और डिप्लॉय करती हैं. आदर्श रूप से, प्रोडक्शन मॉडल के पुराने होने से पहले ही, नए मॉडल को ट्रेन कर लेना चाहिए.
किसी नए मॉडल को ट्रेन करने के लिए, ये पाइपलाइन एक साथ काम करती हैं:
- डेटा पाइपलाइन. डेटा पाइपलाइन, उपयोगकर्ता के डेटा को प्रोसेस करके ट्रेनिंग और टेस्ट डेटासेट बनाती है.
- ट्रेनिंग पाइपलाइन. ट्रेनिंग पाइपलाइन, डेटा पाइपलाइन से मिले नए ट्रेनिंग डेटासेट का इस्तेमाल करके मॉडल को ट्रेन करती है.
- पुष्टि करने वाली पाइपलाइन. पुष्टि करने वाली पाइपलाइन, ट्रेन किए गए मॉडल की पुष्टि करती है. इसके लिए, वह प्रॉडक्शन मॉडल से इसकी तुलना करती है. यह तुलना, डेटा पाइपलाइन से जनरेट किए गए टेस्ट डेटासेट का इस्तेमाल करके की जाती है.
इमेज 4 में, हर एमएल पाइपलाइन के इनपुट और आउटपुट दिखाए गए हैं.
मशीन लर्निंग पाइपलाइन
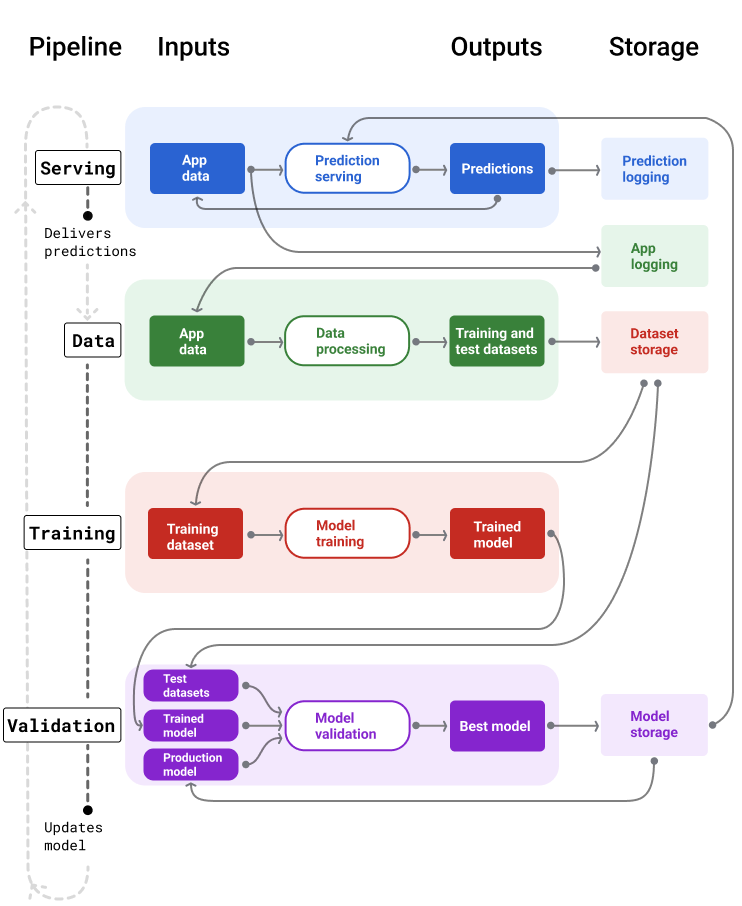
चौथी इमेज. एमएल पाइपलाइन, मॉडल डेवलप करने और उन्हें बनाए रखने की कई प्रोसेस को ऑटोमेट करती हैं. हर पाइपलाइन में उसके इनपुट और आउटपुट दिखाए जाते हैं.
सामान्य तौर पर, पाइपलाइनें प्रोडक्शन में नए मॉडल को इस तरह से बनाए रखती हैं:
सबसे पहले, मॉडल को प्रोडक्शन में ले जाया जाता है. इसके बाद, अनुमान देने वाली पाइपलाइन, अनुमान देना शुरू करती है.
डेटा पाइपलाइन, ट्रेनिंग और टेस्ट के लिए नए डेटासेट जनरेट करने के लिए तुरंत डेटा इकट्ठा करना शुरू कर देती है.
शेड्यूल या ट्रिगर के आधार पर, ट्रेनिंग और पुष्टि करने वाली पाइपलाइन, डेटा पाइपलाइन से जनरेट किए गए डेटासेट का इस्तेमाल करके नए मॉडल को ट्रेन और उसकी पुष्टि करती हैं.
जब पुष्टि करने वाली पाइपलाइन यह पुष्टि कर देती है कि नया मॉडल, प्रोडक्शन मॉडल से बेहतर है, तब नए मॉडल को डिप्लॉय कर दिया जाता है.
यह प्रोसेस लगातार चलती रहती है.
मॉडल के अपडेट होने की फ़्रीक्वेंसी और ट्रेनिंग की फ़्रीक्वेंसी
लगभग सभी मॉडल पुराने हो जाते हैं. कुछ मॉडल, दूसरों की तुलना में ज़्यादा तेज़ी से पुराने हो जाते हैं. उदाहरण के लिए, कपड़े के सुझाव देने वाले मॉडल आम तौर पर बहुत जल्दी पुराने हो जाते हैं. ऐसा इसलिए होता है, क्योंकि उपभोक्ताओं की पसंद अक्सर बदलती रहती है. वहीं दूसरी ओर, फूलों की पहचान करने वाले मॉडल कभी पुराने नहीं होते. किसी फूल की पहचान करने वाली विशेषताएं स्थिर रहती हैं.
ज़्यादातर मॉडल, प्रोडक्शन में इस्तेमाल होने के तुरंत बाद पुराने हो जाते हैं. आपको ट्रेनिंग की ऐसी फ़्रीक्वेंसी सेट करनी होगी जो आपके डेटा के हिसाब से सही हो. अगर डेटा डाइनैमिक है, तो मॉडल को बार-बार ट्रेन करें. अगर यह कम डाइनैमिक है, तो आपको इसे बार-बार ट्रेन करने की ज़रूरत नहीं पड़ सकती.
मॉडल को अपडेट करते रहें, ताकि वे पुराने न हो जाएं. शुरुआती ट्रेनिंग से संभावित समस्याओं को हल करने में मदद मिलती है. उदाहरण के लिए, अगर डेटा या ट्रेनिंग पाइपलाइन काम नहीं करती है या मॉडल की क्वालिटी खराब है.
हमारा सुझाव है कि नए मॉडल को हर दिन ट्रेन और डिप्लॉय करें. सॉफ़्टवेयर के सामान्य प्रोजेक्ट की तरह ही, ट्रेनिंग और पुष्टि करने के लिए एमएल पाइपलाइन को रोज़ाना चलाने से अक्सर बेहतर नतीजे मिलते हैं. इन प्रोजेक्ट में रोज़ाना बिल्ड और रिलीज़ करने की प्रोसेस होती है.
देखें कि आपको कितना समझ आया
विज्ञापन दिखाने की पाइपलाइन
सर्विस देने वाली पाइपलाइन, दो तरीकों से अनुमान जनरेट करती है और उन्हें डिलीवर करती है: ऑनलाइन या ऑफ़लाइन.
ऑनलाइन सुझाव. ऑनलाइन अनुमान रीयल टाइम में लगाए जाते हैं. इसके लिए, आम तौर पर ऑनलाइन सर्वर को अनुरोध भेजा जाता है और अनुमान वापस भेजा जाता है. उदाहरण के लिए, जब कोई उपयोगकर्ता अनुमानित जानकारी पाना चाहता है, तो उसके डेटा को मॉडल को भेजा जाता है. इसके बाद, मॉडल अनुमानित जानकारी दिखाता है.
ऑफ़लाइन सुझाव. ऑफ़लाइन अनुमान पहले से ही कैलकुलेट किए जाते हैं और कैश किए जाते हैं. अनुमान दिखाने के लिए, ऐप्लिकेशन डेटाबेस में सेव किए गए अनुमान को ढूंढता है और उसे दिखाता है. उदाहरण के लिए, सदस्यता पर आधारित सेवा देने वाली कोई कंपनी, अपने सदस्यों के लिए चर्न रेट का अनुमान लगा सकती है. यह मॉडल, हर सदस्य के लिए सदस्यता रद्द करने की संभावना का अनुमान लगाता है और उसे कैश मेमोरी में सेव करता है. जब ऐप्लिकेशन को अनुमान की ज़रूरत होती है, तब वह पहले से ही अनुमानित किए गए डेटा को देखता है. उदाहरण के लिए, अगर ऐप्लिकेशन को उन उपयोगकर्ताओं को इंसेंटिव देना है जो ऐप्लिकेशन छोड़ सकते हैं, तो वह पहले से ही अनुमानित किए गए डेटा को देखता है.
पांचवें फ़िगर में दिखाया गया है कि ऑनलाइन और ऑफ़लाइन अनुमान कैसे जनरेट होते हैं और डिलीवर किए जाते हैं.
ऑनलाइन और ऑफ़लाइन अनुमान
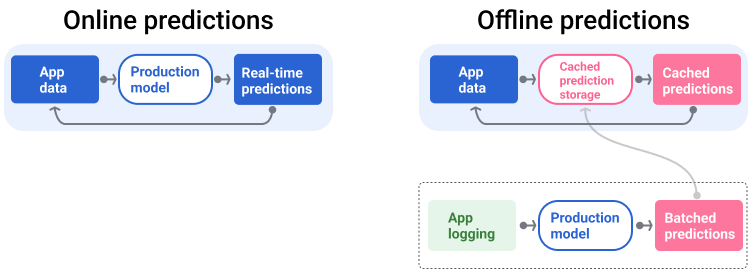
पांचवीं इमेज. ऑनलाइन अनुमान लगाने की सुविधा, रीयल टाइम में अनुमान देती है. ऑफ़लाइन अनुमानों को कैश मेमोरी में सेव किया जाता है और विज्ञापन दिखाने के समय उन्हें देखा जाता है.
सुझाव मिलने के बाद की प्रोसेस
आम तौर पर, अनुमानों को डिलीवर करने से पहले, पोस्ट-प्रोसेस किया जाता है. उदाहरण के लिए, ज़हरीले या पक्षपात वाले कॉन्टेंट को हटाने के लिए, अनुमानों को प्रोसेस किया जा सकता है. क्लासिफ़िकेशन के नतीजों में या नतीजों को फिर से क्रम में लगाने के लिए, किसी प्रोसेस से गुज़ारा जा सकता है. ऐसा मॉडल के रॉ आउटपुट को दिखाने के बजाय किया जाता है. उदाहरण के लिए, ज़्यादा भरोसेमंद कॉन्टेंट को बढ़ावा देने, अलग-अलग तरह के नतीजे दिखाने, कुछ नतीजों (जैसे, क्लिकबेट) को कम दिखाने या कानूनी वजहों से नतीजों को हटाने के लिए ऐसा किया जाता है.
छठी इमेज में, अनुमान देने वाली पाइपलाइन और अनुमान देने में शामिल सामान्य टास्क दिखाए गए हैं.
पोस्ट-प्रोसेसिंग से जुड़े सुझाव
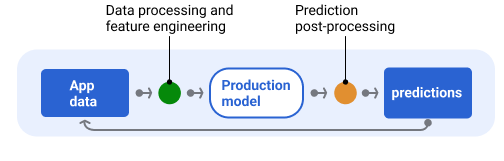
छठी इमेज. सर्विंग पाइपलाइन में, अनुमान देने के लिए किए जाने वाले सामान्य टास्क दिखाए गए हैं.
ध्यान दें कि फ़ीचर इंजीनियरिंग का चरण आम तौर पर मॉडल में ही शामिल होता है. यह कोई अलग प्रोसेस नहीं है. डेटा प्रोसेसिंग के लिए, सर्विंग पाइपलाइन में इस्तेमाल किया जाने वाला कोड अक्सर डेटा प्रोसेसिंग के लिए, डेटा पाइपलाइन में इस्तेमाल किए जाने वाले कोड जैसा ही होता है. डेटा पाइपलाइन, ट्रेनिंग और टेस्ट डेटासेट बनाने के लिए इस कोड का इस्तेमाल करती है.
ऐसेट और मेटाडेटा का स्टोरेज
सर्विंग पाइपलाइन में एक रिपॉज़िटरी शामिल होनी चाहिए, ताकि मॉडल की अनुमानित वैल्यू और अगर हो सके, तो असल वैल्यू को लॉग किया जा सके.
मॉडल के अनुमानों को लॉग करने से, आपको अपने मॉडल की क्वालिटी पर नज़र रखने में मदद मिलती है. अनुमानों को इकट्ठा करके, अपने मॉडल की सामान्य क्वालिटी को मॉनिटर किया जा सकता है. साथ ही, यह पता लगाया जा सकता है कि मॉडल की क्वालिटी खराब हो रही है या नहीं. आम तौर पर, प्रोडक्शन मॉडल की अनुमानित वैल्यू का औसत, ट्रेनिंग डेटासेट के लेबल के औसत के बराबर होना चाहिए. ज़्यादा जानकारी के लिए, पूर्वानुमान में पक्षपात लेख पढ़ें.
ग्राउंड ट्रुथ कैप्चर करना
कुछ मामलों में, ग्राउंड ट्रुथ की जानकारी बहुत बाद में उपलब्ध होती है. उदाहरण के लिए, अगर कोई मौसम का ऐप्लिकेशन छह हफ़्ते बाद के मौसम का अनुमान लगाता है, तो छह हफ़्तों तक मौसम की असल जानकारी उपलब्ध नहीं होगी.
जब भी मुमकिन हो, उपयोगकर्ताओं से सही जानकारी रिपोर्ट करने के लिए कहें. इसके लिए, ऐप्लिकेशन में सुझाव/राय देने या शिकायत करने के तरीके जोड़ें. जब उपयोगकर्ता अपने इनबॉक्स से किसी ईमेल को स्पैम फ़ोल्डर में ले जाते हैं, तो ईमेल ऐप्लिकेशन अपने-आप उपयोगकर्ता के सुझाव/राय या शिकायत को कैप्चर कर लेता है. हालांकि, यह सुविधा सिर्फ़ तब काम करती है, जब उपयोगकर्ता अपने ईमेल को सही तरीके से कैटगरी में बांटता है. जब लोग अपने इनबॉक्स में स्पैम छोड़ देते हैं, तो ट्रेनिंग डेटा गलत हो जाता है. ऐसा इसलिए होता है, क्योंकि उन्हें पता होता है कि यह स्पैम है और वे इसे कभी नहीं खोलते. उस ईमेल को "स्पैम नहीं है" के तौर पर लेबल किया जाएगा, जबकि उसे "स्पैम" के तौर पर लेबल किया जाना चाहिए. दूसरे शब्दों में कहें, तो हमेशा यह पता लगाने की कोशिश करें कि ग्राउंड ट्रुथ को कैसे कैप्चर और रिकॉर्ड किया जाए. हालांकि, फ़ीडबैक के तरीकों में मौजूद कमियों के बारे में भी पता होना चाहिए.
सातवीं इमेज में, किसी उपयोगकर्ता को अनुमान दिखाए जाने और उन्हें किसी रिपॉज़िटरी में लॉग किए जाने की प्रोसेस दिखाई गई है.
अनुमानों को लॉग करना
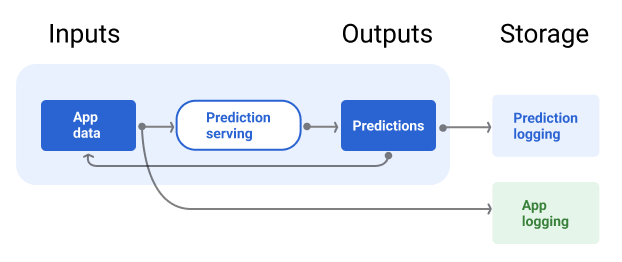
सातवीं इमेज. मॉडल की क्वालिटी को मॉनिटर करने के लिए, अनुमानों को लॉग करें.
डेटा पाइपलाइन
डेटा पाइपलाइन, ऐप्लिकेशन के डेटा से ट्रेनिंग और टेस्ट डेटासेट जनरेट करती हैं. इसके बाद, ट्रेनिंग और पुष्टि करने वाली पाइपलाइन, डेटासेट का इस्तेमाल करके नए मॉडल को ट्रेन करती हैं और उनकी पुष्टि करती हैं.
डेटा पाइपलाइन, ट्रेनिंग और टेस्ट डेटासेट बनाती है. इनमें वे ही सुविधाएं और लेबल होते हैं जिनका इस्तेमाल मॉडल को ट्रेनिंग देने के लिए किया गया था. हालांकि, इनमें नई जानकारी होती है. उदाहरण के लिए, कोई मैप ऐप्लिकेशन, लाखों उपयोगकर्ताओं के लिए दो जगहों के बीच यात्रा में लगे समय के हाल ही के डेटा से ट्रेनिंग और टेस्ट डेटासेट जनरेट करेगा. साथ ही, मौसम जैसे अन्य काम के डेटा का भी इस्तेमाल करेगा.
वीडियो का सुझाव देने वाला ऐप्लिकेशन, ट्रेनिंग और टेस्ट डेटासेट जनरेट करेगा. इनमें वे वीडियो शामिल होंगे जिन पर किसी उपयोगकर्ता ने सुझावों की सूची में क्लिक किया था. साथ ही, वे वीडियो भी शामिल होंगे जिन पर क्लिक नहीं किया गया था. इसके अलावा, इसमें काम का अन्य डेटा भी शामिल होगा, जैसे कि वीडियो देखने का इतिहास.
आठवीं इमेज में, ट्रेनिंग और टेस्ट डेटासेट जनरेट करने के लिए ऐप्लिकेशन डेटा का इस्तेमाल करने वाली डेटा पाइपलाइन दिखाई गई है.
डेटा पाइपलाइन
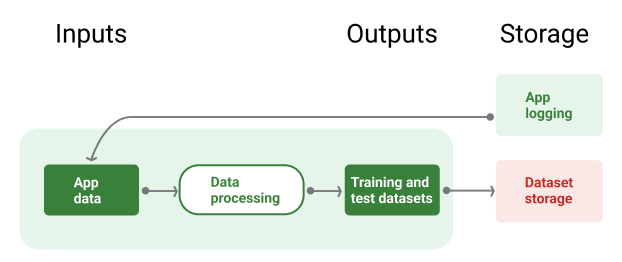
आठवीं इमेज. डेटा पाइपलाइन, ऐप्लिकेशन के डेटा को प्रोसेस करके ट्रेनिंग और पुष्टि करने वाली पाइपलाइन के लिए डेटासेट बनाती है.
डेटा इकट्ठा करना और उसे प्रोसेस करना
डेटा पाइपलाइन में डेटा इकट्ठा करने और उसे प्रोसेस करने के टास्क, एक्सपेरिमेंट के चरण से अलग होंगे. इस चरण में, आपने यह तय किया था कि आपका समाधान काम कर सकता है:
डेटा कलेक्शन. एक्सपेरिमेंट के दौरान, डेटा इकट्ठा करने के लिए आम तौर पर सेव किए गए डेटा को ऐक्सेस करना ज़रूरी होता है. डेटा पाइपलाइन के लिए, डेटा इकट्ठा करने के लिए स्ट्रीमिंग लॉग डेटा को ढूंढना और उसे ऐक्सेस करने की अनुमति पाना ज़रूरी हो सकता है.
अगर आपको इंसानों के लेबल किए गए डेटा (जैसे, मेडिकल इमेज) की ज़रूरत है, तो आपको इसे इकट्ठा करने और अपडेट करने की प्रोसेस भी बनानी होगी.
डेटा प्रोसेसिंग. एक्सपेरिमेंट के दौरान, सही सुविधाएं एक्सपेरिमेंट के डेटासेट को स्क्रैप करने, जोड़ने, और सैंपलिंग करने से मिलीं. डेटा पाइपलाइन के लिए, इन सुविधाओं को जनरेट करने के लिए पूरी तरह से अलग प्रोसेस की ज़रूरत पड़ सकती है. हालांकि, एक्सपेरिमेंट के दौरान किए गए डेटा ट्रांसफ़ॉर्मेशन को डुप्लीकेट करना न भूलें. इसके लिए, सुविधाओं और लेबल पर एक जैसे गणितीय ऑपरेशन लागू करें.
ऐसेट और मेटाडेटा का स्टोरेज
आपको ट्रेनिंग और टेस्ट डेटासेट को सेव करने, वर्शन करने, और मैनेज करने के लिए एक प्रोसेस की ज़रूरत होगी. वर्शन कंट्रोल की सुविधा वाली रिपॉज़िटरी से ये फ़ायदे मिलते हैं:
दोहराने की क्षमता. मॉडल ट्रेनिंग के एनवायरमेंट को फिर से बनाएं और उन्हें स्टैंडर्ड बनाएं. साथ ही, अलग-अलग मॉडल के अनुमान की क्वालिटी की तुलना करें.
पेमेंट से पहले की जाने वाली पुष्टि के लिए रोक. लेखापरीक्षा और पारदर्शिता के लिए, नियमों के अनुपालन से जुड़ी ज़रूरी शर्तों का पालन करें.
निजी डेटा का रखरखाव. डेटा को कितने समय तक सेव रखना है, इसके लिए निजी डेटा के रखरखाव की वैल्यू सेट करें.
ऐक्सेस मैनेजमेंट. ज़्यादा बेहतर अनुमतियों की मदद से, यह मैनेज करें कि आपका डेटा कौन ऐक्सेस कर सकता है.
डेटा का रखरखाव. समय के साथ डेटासेट में हुए बदलावों को ट्रैक और समझा जा सकता है. इससे, डेटा या मॉडल से जुड़ी समस्याओं का पता लगाना आसान हो जाता है.
खोजे जाने की सुविधा. दूसरों के लिए, अपने डेटासेट और सुविधाओं को खोजना आसान बनाएं. इसके बाद, अन्य टीमें यह तय कर सकती हैं कि ये उनके काम के हैं या नहीं.
अपने डेटा का दस्तावेज़ बनाना
अच्छे दस्तावेज़ से, दूसरों को आपके डेटा के बारे में अहम जानकारी मिलती है. जैसे, डेटा का टाइप, सोर्स, साइज़, और अन्य ज़रूरी मेटाडेटा. ज़्यादातर मामलों में, अपने डेटा को डिज़ाइन डॉक में शामिल करना काफ़ी होता है. अगर आपको अपना डेटा शेयर या पब्लिश करना है, तो जानकारी को व्यवस्थित करने के लिए, डेटा कार्ड का इस्तेमाल करें. डेटा कार्ड की मदद से, दूसरे लोग आपके डेटासेट को आसानी से ढूंढ सकते हैं और उन्हें समझ सकते हैं.
ट्रेनिंग और पुष्टि करने वाली पाइपलाइन
ट्रेनिंग और पुष्टि करने वाली पाइपलाइनें, प्रोडक्शन मॉडल के पुराने होने से पहले उन्हें बदलने के लिए नए मॉडल बनाती हैं. नए मॉडल को लगातार ट्रेन करने और उनकी पुष्टि करने से, यह पक्का किया जाता है कि सबसे अच्छा मॉडल हमेशा प्रोडक्शन में रहे.
ट्रेनिंग पाइपलाइन, ट्रेनिंग डेटासेट से एक नया मॉडल जनरेट करती है. साथ ही, पुष्टि करने वाली पाइपलाइन, टेस्ट डेटासेट का इस्तेमाल करके, नए मॉडल की क्वालिटी की तुलना प्रोडक्शन में मौजूद मॉडल से करती है.
आंकड़े 9 में, ट्रेनिंग पाइपलाइन के बारे में बताया गया है. इसमें ट्रेनिंग डेटासेट का इस्तेमाल करके, नए मॉडल को ट्रेन किया जाता है.
ट्रेनिंग पाइपलाइन
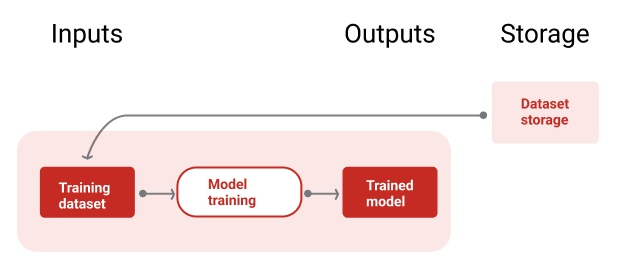
नौवीं इमेज. ट्रेनिंग पाइपलाइन, सबसे नए ट्रेनिंग डेटासेट का इस्तेमाल करके नए मॉडल को ट्रेन करती है.
मॉडल को ट्रेन करने के बाद, पुष्टि करने वाली पाइपलाइन, टेस्ट डेटासेट का इस्तेमाल करती है. इससे प्रोडक्शन मॉडल की क्वालिटी की तुलना, ट्रेन किए गए मॉडल से की जाती है.
आम तौर पर, अगर ट्रेन किए गए मॉडल की परफ़ॉर्मेंस, प्रोडक्शन मॉडल की परफ़ॉर्मेंस से बहुत ज़्यादा खराब नहीं है, तो ट्रेन किए गए मॉडल को प्रोडक्शन में शामिल कर दिया जाता है. अगर ट्रेन किया गया मॉडल खराब है, तो निगरानी करने वाले इन्फ़्रास्ट्रक्चर को सूचना बनानी चाहिए. जिन मॉडल को ट्रेनिंग दी गई है और जिनकी अनुमान लगाने की क्वालिटी खराब है उनसे डेटा या पुष्टि करने वाली पाइपलाइन से जुड़ी संभावित समस्याओं का पता चल सकता है. इस तरीके से यह पक्का किया जाता है कि सबसे नए डेटा पर ट्रेन किया गया सबसे अच्छा मॉडल हमेशा प्रोडक्शन में रहे.
ऐसेट और मेटाडेटा का स्टोरेज
मॉडल और उनके मेटाडेटा को वर्शन वाली रिपॉज़िटरी में सेव किया जाना चाहिए, ताकि मॉडल डिप्लॉयमेंट को व्यवस्थित और ट्रैक किया जा सके. मॉडल रिपॉज़िटरी के ये फ़ायदे हैं:
ट्रैकिंग और आकलन. प्रोडक्शन में मौजूद मॉडल को ट्रैक करें. साथ ही, उनके आकलन और अनुमान की क्वालिटी मेट्रिक को समझें.
मॉडल रिलीज़ करने की प्रोसेस. मॉडल की आसानी से समीक्षा करें, उन्हें स्वीकार करें, रिलीज़ करें या पहले जैसा करें.
डीबग करना और दोबारा बनाना. मॉडल के नतीजों को फिर से जनरेट करें. साथ ही, डिप्लॉयमेंट के दौरान मॉडल के डेटासेट और डिपेंडेंसी को ट्रैक करके, समस्याओं को ज़्यादा असरदार तरीके से ठीक करें.
खोजे जाने की सुविधा. अपने मॉडल को दूसरों के लिए आसानी से ढूंढने लायक बनाएं. इसके बाद, अन्य टीमें यह तय कर सकती हैं कि आपके मॉडल (या इसके कुछ हिस्सों) का इस्तेमाल उनके मकसद के लिए किया जा सकता है या नहीं.
इस इमेज में, मॉडल रिपॉज़िटरी में सेव किए गए ऐसे मॉडल के बारे में बताया गया है जिसकी पुष्टि हो चुकी है.
मॉडल स्टोरेज
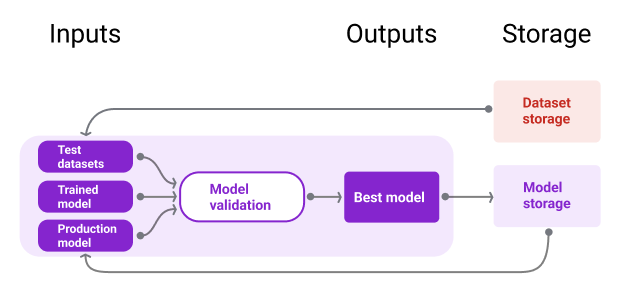
दसवीं इमेज. पुष्टि किए गए मॉडल को मॉडल रिपॉज़िटरी में सेव किया जाता है, ताकि उन्हें ट्रैक किया जा सके और खोजा जा सके.
अपने मॉडल के बारे में मुख्य जानकारी को दस्तावेज़ में शामिल करने और उसे शेयर करने के लिए, मॉडल कार्ड का इस्तेमाल करें. जैसे, मॉडल का मकसद, आर्किटेक्चर, हार्डवेयर की ज़रूरी शर्तें, आकलन की मेट्रिक वगैरह.
देखें कि आपको कितना समझ आया
पाइपलाइन बनाने से जुड़ी समस्याएं
पाइपलाइन बनाते समय, आपको इन समस्याओं का सामना करना पड़ सकता है:
ज़रूरी डेटा का ऐक्सेस पाना. डेटा ऐक्सेस करने के लिए, आपको यह बताना पड़ सकता है कि आपको इसकी ज़रूरत क्यों है. उदाहरण के लिए, आपको यह बताना पड़ सकता है कि डेटा का इस्तेमाल कैसे किया जाएगा. साथ ही, यह साफ़ तौर पर बताना होगा कि व्यक्तिगत पहचान से जुड़ी जानकारी (पीआईआई) की समस्याओं को कैसे हल किया जाएगा. कॉन्सेप्ट का सबूत दिखाने के लिए तैयार रहें. इससे यह पता चलेगा कि आपका मॉडल, कुछ तरह के डेटा का ऐक्सेस मिलने पर बेहतर अनुमान कैसे लगाता है.
सही सुविधाएं पाना. कुछ मामलों में, एक्सपेरिमेंट के दौरान इस्तेमाल की गई सुविधाएँ, रीयल-टाइम डेटा में उपलब्ध नहीं होंगी. इसलिए, एक्सपेरिमेंट करते समय यह पक्का करें कि आपको प्रोडक्शन में भी वही सुविधाएं मिलेंगी.
डेटा को इकट्ठा करने और दिखाने के तरीके को समझना. डेटा कैसे इकट्ठा किया गया, इसे किसने इकट्ठा किया, और इसे कैसे इकट्ठा किया गया (अन्य समस्याओं के साथ) जैसी जानकारी पाने में समय और मेहनत लग सकती है. डेटा को अच्छी तरह से समझना ज़रूरी है. ऐसे डेटा का इस्तेमाल न करें जिस पर आपको भरोसा नहीं है. इसका इस्तेमाल, प्रोडक्शन में जाने वाले मॉडल को ट्रेनिंग देने के लिए किया जा सकता है.
मॉडल को बनाने में लगने वाले समय, लागत, और मॉडल की क्वालिटी के बीच ट्रेडऑफ़ को समझना. डेटा पाइपलाइन में नई सुविधा को शामिल करने के लिए, काफ़ी मेहनत करनी पड़ सकती है. हालांकि, अतिरिक्त सुविधा से मॉडल की क्वालिटी में मामूली सुधार हो सकता है. अन्य मामलों में, नई सुविधा जोड़ना आसान हो सकता है. हालांकि, इस सुविधा को पाने और सेव करने के लिए ज़रूरी संसाधन बहुत महंगे हो सकते हैं.
कंप्यूट की सुविधा पाना. अगर आपको फिर से ट्रेनिंग देने के लिए टीपीयू की ज़रूरत है, तो हो सकता है कि आपको ज़रूरी कोटा न मिले. साथ ही, टीपीयू को मैनेज करना भी मुश्किल होता है. उदाहरण के लिए, आपके मॉडल या डेटा के कुछ हिस्सों को खास तौर पर टीपीयू के लिए डिज़ाइन करना पड़ सकता है. इसके लिए, उनके हिस्सों को कई टीपीयू चिप में बांटना होगा.
सही गोल्डन डेटासेट ढूंढना. अगर डेटा समय-समय पर बदलता रहता है, तो लगातार और सटीक लेबल वाले गोल्डन डेटासेट पाना मुश्किल हो सकता है.
एक्सपेरिमेंट के दौरान इस तरह की समस्याओं का पता चलने से समय बचता है. उदाहरण के लिए, आपको सिर्फ़ यह जानने के लिए सबसे अच्छी सुविधाएं और मॉडल डेवलप नहीं करने हैं कि वे प्रोडक्शन में काम नहीं कर रहे हैं. इसलिए, जल्द से जल्द यह पुष्टि करने की कोशिश करें कि आपका समाधान, प्रोडक्शन एनवायरमेंट की सीमाओं के अंदर काम करेगा. किसी समाधान के काम करने की पुष्टि करने में समय लगाना बेहतर होता है. इससे आपको एक्सपेरिमेंट के चरण पर वापस नहीं जाना पड़ता, क्योंकि पाइपलाइन के चरण में ऐसी समस्याएं सामने आई हैं जिन्हें हल नहीं किया जा सकता.