Einführung in Convolutional Neural Networks
Ein Durchbruch bei der Erstellung von Modellen für die Bildklassifizierung war die Entdeckung, dass mit einem Convolutional Neural Network (CNN) nach und nach immer höhere Darstellungsebenen des Bildinhalts extrahiert werden können. Anstatt die Daten vorzuverarbeiten, um Merkmale wie Texturen und Formen abzuleiten, nimmt ein CNN nur die Rohpixeldaten des Bildes als Eingabe und „lernt“, wie diese Merkmale extrahiert werden, um letztendlich zu schließen, welches Objekt sie darstellen.
Zuerst erhält das CNN eine Eingabe-Feature-Map: eine dreidimensionale Matrix, bei der die Größe der ersten beiden Dimensionen der Länge und Breite der Bilder in Pixeln entspricht. Die Größe der dritten Dimension ist 3 (entspricht den drei Kanälen eines Farbbilds: Rot, Grün und Blau). Die CNN besteht aus einem Stapel von Modulen, von denen jedes drei Vorgänge ausführt.
1. Faltung
Bei einer Konvolution werden Kacheln der Eingabe-Featurekarte extrahiert und Filter darauf angewendet, um neue Features zu berechnen. So entsteht eine Ausgabe-Featurekarte oder ein gefaltetes Feature, das eine andere Größe und Tiefe als die Eingabe-Featurekarte haben kann. Convolutionen werden durch zwei Parameter definiert:
- Größe der extrahierten Kacheln (in der Regel 3 × 3 oder 5 × 5 Pixel).
- Die Tiefe der Ausgabe-Featurekarte, die der Anzahl der angewendeten Filter entspricht.
Bei einer Convolution gleiten die Filter (Matrizen mit derselben Größe wie die Kachelgröße) horizontal und vertikal über das Raster der Eingabe-Feature-Map, jeweils ein Pixel, und extrahieren die entsprechenden Kacheln (siehe Abbildung 3).
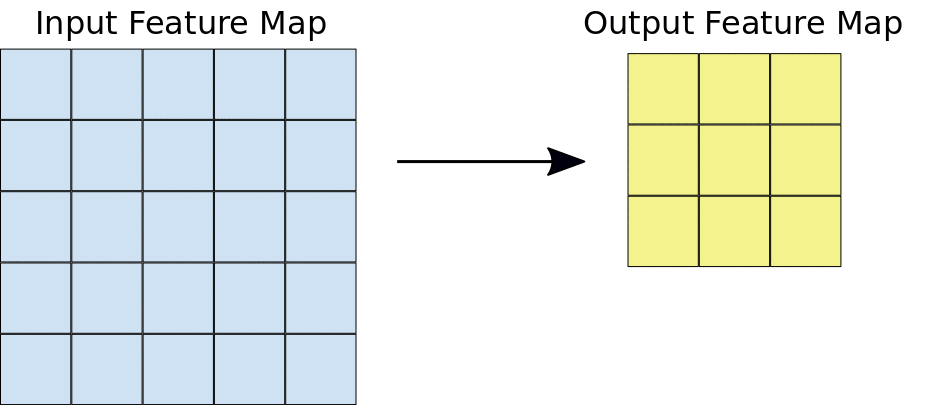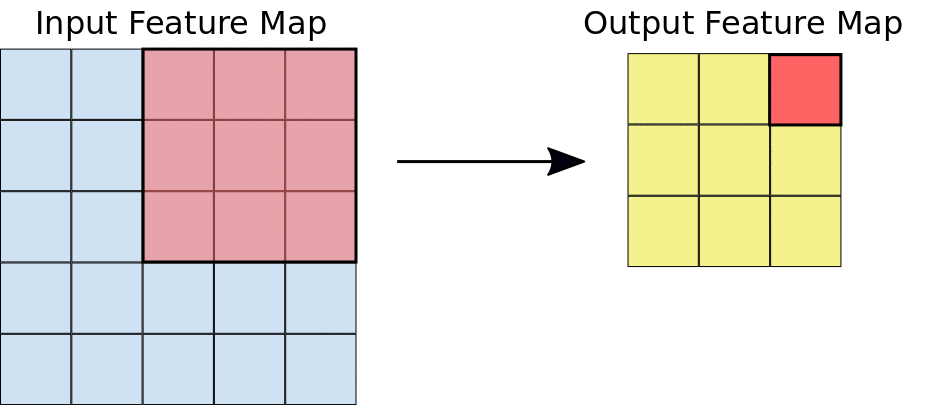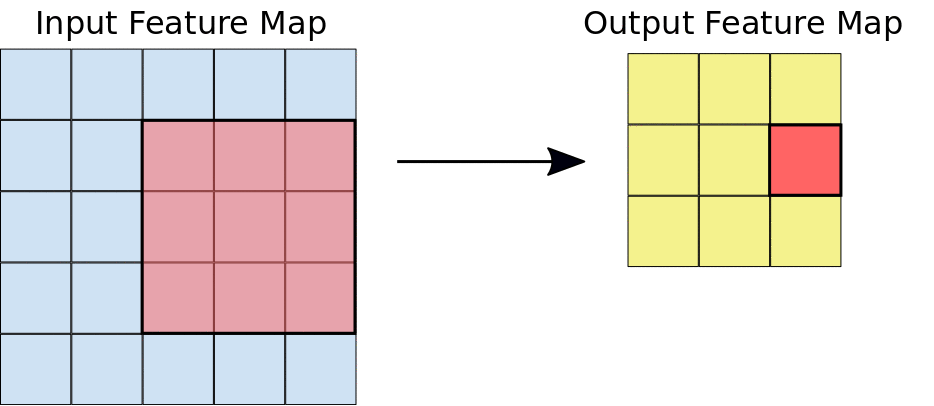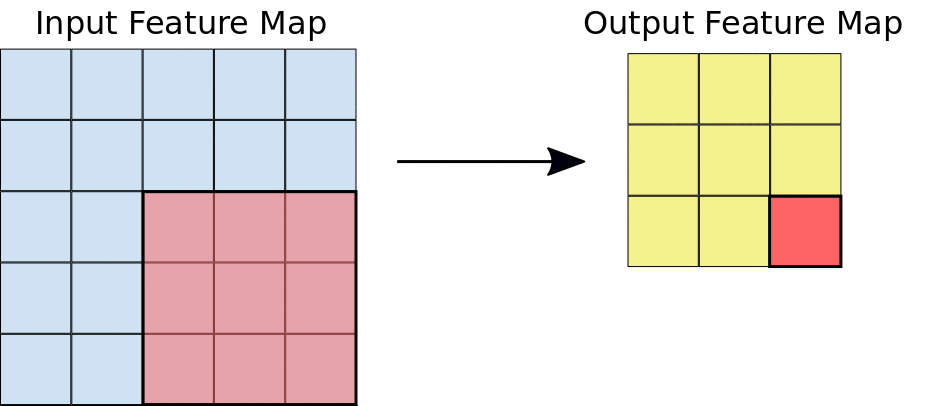 Abbildung 3. Eine 3 × 3-Faltung der Tiefe 1, die auf einer 5 × 5-Eingabe-Feature-Map der Tiefe 1 ausgeführt wird. Es gibt neun mögliche 3 × 3-Standorte, an denen Kacheln aus der 5 × 5-Ebenenkarte extrahiert werden können. Daher führt diese Convolution zu einer 3 × 3-Ebenenkarte.
Abbildung 3. Eine 3 × 3-Faltung der Tiefe 1, die auf einer 5 × 5-Eingabe-Feature-Map der Tiefe 1 ausgeführt wird. Es gibt neun mögliche 3 × 3-Standorte, an denen Kacheln aus der 5 × 5-Ebenenkarte extrahiert werden können. Daher führt diese Convolution zu einer 3 × 3-Ebenenkarte.
Für jedes Filter-/Kachelpaar führt die CNN eine elementweise Multiplikation der Filtermatrix und der Kachelmatrix durch und summiert dann alle Elemente der resultierenden Matrix, um einen einzelnen Wert zu erhalten. Jeder dieser resultierenden Werte für jedes Filter-Kachel-Paar wird dann in der Matrix für verschwommene Merkmale ausgegeben (siehe Abbildungen 4a und 4b).
 Abbildung 4a. Links: Eine 5 × 5 Pixel große Eingabe-Feature-Map (Tiefe 1). Rechts: eine 3 × 3 Mehrfachkonvolution (Tiefe 1).
Abbildung 4a. Links: Eine 5 × 5 Pixel große Eingabe-Feature-Map (Tiefe 1). Rechts: eine 3 × 3 Mehrfachkonvolution (Tiefe 1).
Abbildung 4b. Links: Die 3 × 3-Faltung wird auf der 5 × 5-Eingabe-Feature-Map ausgeführt. Rechts: das resultierende geconvolvierte Element. Klicken Sie auf einen Wert in der Ausgabe-Featurekarte, um zu sehen, wie er berechnet wurde.
Während des Trainings „lernt“ das CNN die optimalen Werte für die Filtermatrizen, mit denen aus der Eingabe-Feature-Map aussagekräftige Merkmale (Texturen, Kanten, Formen) extrahiert werden können. Je mehr Filter (Tiefe der Ausgabe-Feature-Map) auf die Eingabe angewendet werden, desto mehr Features kann die CNN extrahieren. Der Nachteil ist jedoch, dass die Filter den Großteil der von der CNN verbrauchten Ressourcen ausmachen. Daher erhöht sich die Trainingszeit auch, wenn mehr Filter hinzugefügt werden. Außerdem bietet jeder dem Netzwerk hinzugefügte Filter einen geringeren inkrementellen Wert als der vorherige. Daher versuchen Entwickler, Netzwerke zu erstellen, die die minimale Anzahl von Filtern verwenden, die zum Extrahieren der für eine genaue Bildklassifizierung erforderlichen Merkmale erforderlich sind.
2. ReLU
Nach jeder Convolutionsoperation wendet die CNN eine ReLU-Transformation (Rectified Linear Unit) auf das geconvolvierte Feature an, um dem Modell Nichtlinearität zu verleihen. Die ReLU-Funktion \(F(x)=max(0,x)\)gibt x für alle Werte von x > 0 zurück und 0 für alle Werte von x ≤ 0.
3. Pooling
Nach ReLU folgt ein Pooling-Schritt, bei dem die CNN das geconvolvierte Merkmal herunterskaliert (um die Verarbeitungszeit zu verkürzen), die Anzahl der Dimensionen der Merkmalskarte reduziert und gleichzeitig die wichtigsten Merkmalinformationen beibehält. Ein gängiger Algorithmus für diesen Prozess wird als Max-Pooling bezeichnet.
Max-Pooling funktioniert ähnlich wie die Convolution. Wir bewegen den Mauszeiger über die Featurekarte und extrahieren Kacheln einer bestimmten Größe. Für jede Kachel wird der Maximalwert in eine neue Featurekarte ausgegeben und alle anderen Werte werden verworfen. Max-Pooling-Vorgänge haben zwei Parameter:
- Größe des Max-Pooling-Filters (in der Regel 2 × 2 Pixel)
- Stride: Der Abstand in Pixeln zwischen den einzelnen extrahierten Kacheln. Im Gegensatz zur Convolution, bei der die Filter Pixel für Pixel über die Merkmalskarte gleiten, wird beim Max-Pooling durch den Schritt festgelegt, an welchen Stellen die einzelnen Kacheln extrahiert werden. Bei einem 2 × 2-Filter gibt ein Schritt von 2 an, dass bei der Max-Pooling-Operation alle nicht überlappenden Kacheln von 2 × 2 aus der Feature-Map extrahiert werden (siehe Abbildung 5).
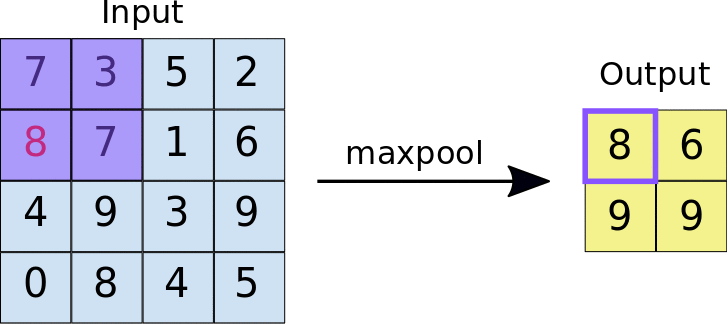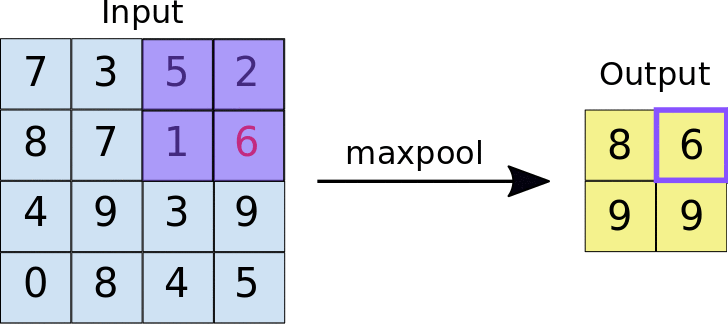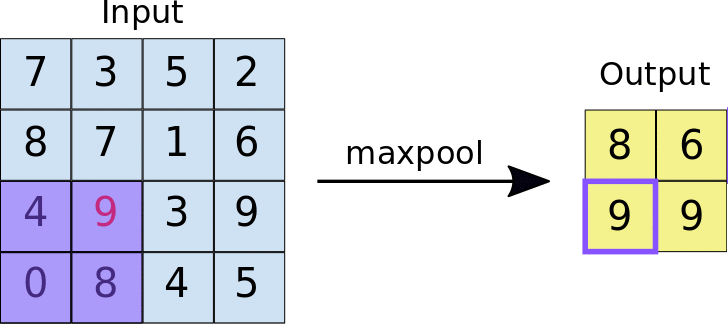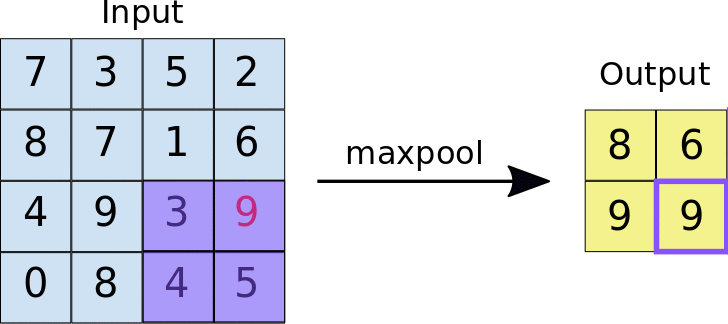
Abbildung 5. Links: Max-Pooling auf einer 4 × 4-Feature-Map mit einem 2 × 2-Filter und einem Schritt von 2. Right: Die Ausgabe des Max-Pooling-Vorgangs. Die resultierende Featurekarte ist jetzt 2 × 2 und enthält nur die Höchstwerte aus jeder Kachel.
Vollständig verbundene Ebenen
Am Ende eines Convolutional Neural Networks befinden sich eine oder mehrere vollständig verbundene Schichten. Wenn zwei Schichten „vollständig verbunden“ sind, ist jeder Knoten in der ersten Schicht mit jedem Knoten in der zweiten Schicht verbunden. Sie führen eine Klassifizierung anhand der durch die Convolutionen extrahierten Merkmale durch. Normalerweise enthält die letzte vollständig verbundene Schicht eine Softmax-Aktivierungsfunktion, die für jedes der Klassifizierungslabels, die das Modell vorhersagen soll, einen Wahrscheinlichkeitswert von 0 bis 1 ausgibt.
Abbildung 6 zeigt die End-to-End-Struktur eines Convolutional Neural Networks.

Abbildung 6. Die hier gezeigte CNN enthält zwei Convolutionsmodule (Convolution + ReLU + Pooling) zur Feature-Extraktion und zwei vollständig verbundene Schichten für die Klassifizierung. Andere CNNs können mehr oder weniger Convolutional-Module und mehr oder weniger voll verbundene Schichten enthalten. Entwickler führen oft Tests durch, um die Konfiguration zu ermitteln, die für ihr Modell die besten Ergebnisse liefert.