ขอแนะนําโครงข่ายระบบประสาทเทียมแบบ Convolutional
ความก้าวหน้าในการสร้างโมเดลสําหรับการจัดประเภทรูปภาพเกิดขึ้นจากการค้นพบว่าเครือข่ายประสาทแบบConvolutive (CNN) สามารถใช้ดึงข้อมูลการนําเสนอเนื้อหารูปภาพในระดับที่สูงขึ้นได้อย่างต่อเนื่อง CNN จะใช้เฉพาะข้อมูลพิกเซลดิบของรูปภาพเป็นอินพุตและ "เรียนรู้" วิธีดึงข้อมูลฟีเจอร์เหล่านี้ แทนที่จะประมวลผลข้อมูลก่อนเพื่อให้ได้ฟีเจอร์ต่างๆ เช่น พื้นผิวและรูปร่าง และสุดท้ายจะอนุมานว่ารูปภาพประกอบไปด้วยวัตถุใด
ในการเริ่มต้น CNN จะได้รับแผนที่ฟีเจอร์อินพุต ซึ่งเป็นเมทริกซ์ 3 มิติที่ขนาดของ 2 มิติแรกสอดคล้องกับความยาวและความกว้างของรูปภาพเป็นพิกเซล ขนาดของมิติข้อมูลส่วนที่ 3 คือ 3 (สอดคล้องกับแชแนล 3 ช่องของรูปภาพสี ได้แก่ แดง เขียว และน้ำเงิน) CNN ประกอบด้วยชุดโมดูลที่แต่ละโมดูลจะดำเนินการ 3 รายการ
1. การกรอง
การกรองข้อมูลจะดึงข้อมูลไทล์ของแผนที่องค์ประกอบอินพุต และใช้ตัวกรองกับไทล์เหล่านั้นเพื่อคํานวณองค์ประกอบใหม่ ซึ่งจะสร้างแผนที่องค์ประกอบเอาต์พุตหรือองค์ประกอบที่กรองข้อมูล (ซึ่งอาจมีขนาดและความลึกแตกต่างจากแผนที่องค์ประกอบอินพุต) การฟัซชันจะกำหนดโดยพารามิเตอร์ 2 รายการ ได้แก่
- ขนาดของไทล์ที่ดึงข้อมูล (โดยทั่วไปคือ 3x3 หรือ 5x5 พิกเซล)
- ความลึกของแผนที่ฟีเจอร์เอาต์พุต ซึ่งสอดคล้องกับจํานวนฟิลเตอร์ที่ใช้
ในระหว่างการกรอง ฟิลเตอร์ (เมทริกซ์ที่มีขนาดเท่ากับขนาดไทล์) จะเลื่อนไปตามตารางกริดของแผนที่ฟีเจอร์อินพุตในแนวนอนและแนวตั้งทีละพิกเซลอย่างมีประสิทธิภาพ เพื่อดึงข้อมูลไทล์ที่เกี่ยวข้องแต่ละรายการ (ดูรูปที่ 3)
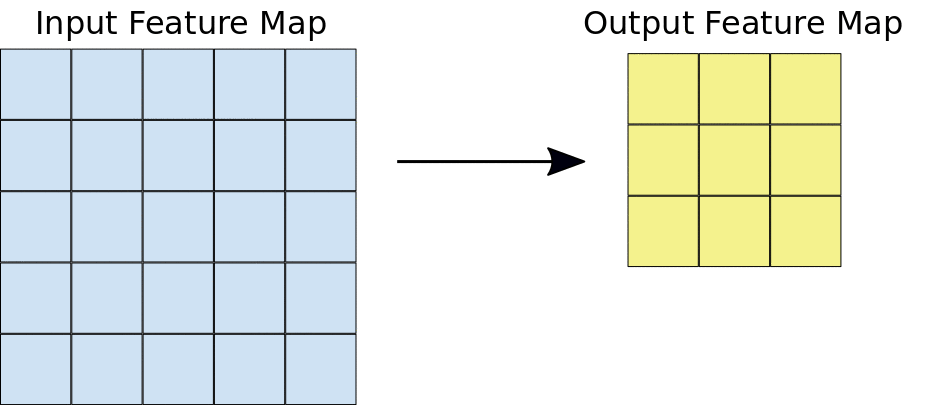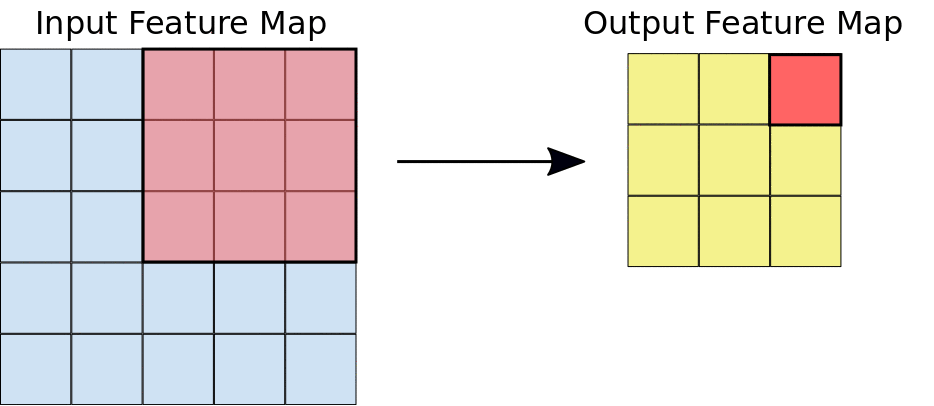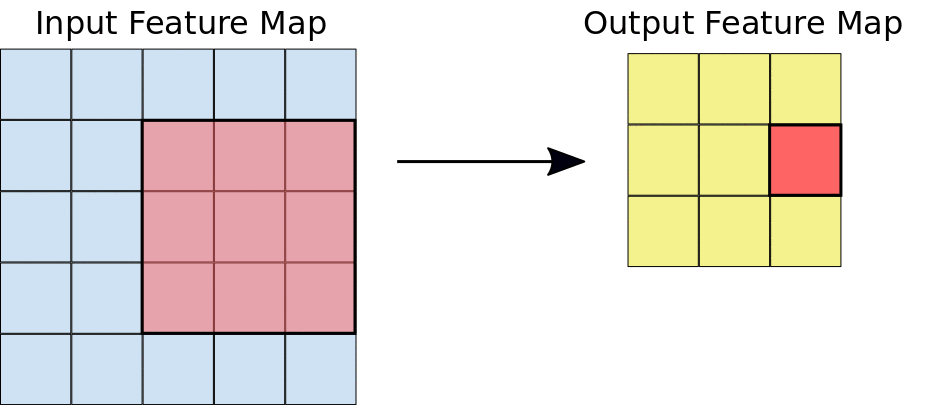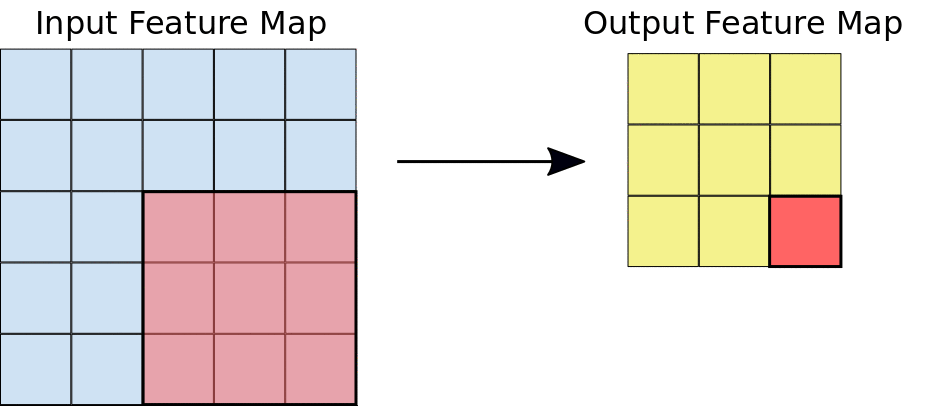 รูปที่ 3 การกรอง 3x3 ที่มีความลึก 1 ดำเนินการกับแผนที่ลักษณะ 5x5 ที่เป็นข้อมูลเข้าที่มีความลึก 1 เช่นกัน มีตำแหน่ง 3x3 ที่เป็นไปได้ 9 ตำแหน่งในการดึงข้อมูลไทล์จากแผนที่ลักษณะ 5x5 ดังนั้นการฟัซซิชันนี้จะสร้างแผนที่ลักษณะเอาต์พุต 3x3
รูปที่ 3 การกรอง 3x3 ที่มีความลึก 1 ดำเนินการกับแผนที่ลักษณะ 5x5 ที่เป็นข้อมูลเข้าที่มีความลึก 1 เช่นกัน มีตำแหน่ง 3x3 ที่เป็นไปได้ 9 ตำแหน่งในการดึงข้อมูลไทล์จากแผนที่ลักษณะ 5x5 ดังนั้นการฟัซซิชันนี้จะสร้างแผนที่ลักษณะเอาต์พุต 3x3
สําหรับคู่ตัวกรอง-ไทล์แต่ละคู่ CNN จะคูณเมทริกซ์ตัวกรองกับเมทริกซ์ไทล์ทีละองค์ประกอบ จากนั้นจะรวมองค์ประกอบทั้งหมดของเมทริกซ์ผลลัพธ์เพื่อให้ได้ค่าเดียว จากนั้นระบบจะแสดงผลค่าที่ได้แต่ละค่าสำหรับคู่ฟิลเตอร์และไทล์ทุกคู่ในเมทริกซ์องค์ประกอบที่ผสาน (ดูรูปที่ 4ก และ 4ข)
 รูปที่ 4ก. ซ้าย: แผนที่ฟีเจอร์อินพุต 5x5 (ความลึก 1) ขวา: การฟัซชัน 3x3 (ความลึก 1)
รูปที่ 4ก. ซ้าย: แผนที่ฟีเจอร์อินพุต 5x5 (ความลึก 1) ขวา: การฟัซชัน 3x3 (ความลึก 1)
รูปที่ 4ข. ซ้าย: การดำเนินการฟิวชัน 3x3 กับแผนที่ฟีเจอร์อินพุต 5x5 ขวา: ฟีเจอร์ที่เกิดจากการฟุ้ง คลิกค่าในแผนที่ฟีเจอร์เอาต์พุตเพื่อดูวิธีคํานวณ
ในระหว่างการฝึก CNN จะ "เรียนรู้" ค่าที่เหมาะสมที่สุดสำหรับเมทริกซ์ตัวกรอง ซึ่งช่วยให้ดึงข้อมูลลักษณะที่มีประโยชน์ (พื้นผิว ขอบ รูปร่าง) ออกจากแผนที่ลักษณะที่ปรากฏของอินพุตได้ เมื่อจำนวนตัวกรอง (ความลึกของแผนที่ลักษณะที่ปรากฏเอาต์พุต) ที่นําไปใช้กับอินพุตเพิ่มขึ้น จำนวนลักษณะที่ปรากฏที่ CNN ดึงข้อมูลได้ก็จะเพิ่มขึ้นด้วย อย่างไรก็ตาม ข้อเสียคือตัวกรองจะประกอบขึ้นจากทรัพยากรส่วนใหญ่ที่ CNN ใช้ในการประมวลผล ดังนั้นเวลาในการฝึกอบรมก็จะเพิ่มขึ้นด้วยเมื่อเพิ่มตัวกรองมากขึ้น นอกจากนี้ ตัวกรองแต่ละรายการที่เพิ่มลงในเครือข่ายจะให้ค่าที่เพิ่มขึ้นน้อยกว่าตัวกรองก่อนหน้า ดังนั้นวิศวกรจึงมุ่งสร้างเครือข่ายที่ใช้ตัวกรองจำนวนน้อยที่สุดที่จําเป็นในการดึงข้อมูลฟีเจอร์ที่จําเป็นสําหรับการจัดประเภทรูปภาพอย่างถูกต้อง
2. ReLU
หลังจากการดำเนินการฟิวชันข้อมูลแต่ละครั้ง CNN จะใช้การเปลี่ยนรูปแบบ Rectified Linear Unit (ReLU) กับฟีเจอร์ที่ฟิวชันข้อมูลเพื่อนำลักษณะการทำงานที่ไม่ใช่เชิงเส้นมาไว้ในโมเดล ฟังก์ชัน ReLU \(F(x)=max(0,x)\)จะแสดงผล x สำหรับค่าทั้งหมดของ x > 0 และจะแสดงผล 0 สำหรับค่าทั้งหมดของ x ≤ 0
3. การรวม
หลังจาก ReLU จะเป็นขั้นตอนการรวมกลุ่ม ซึ่ง CNN จะลดขนาดฟีเจอร์ที่ผสาน (เพื่อประหยัดเวลาในการประมวลผล) โดยลดจํานวนมิติข้อมูลของแผนที่ฟีเจอร์ ขณะเดียวกันก็ยังคงเก็บรักษาข้อมูลฟีเจอร์ที่สําคัญที่สุดไว้ อัลกอริทึมทั่วไปที่ใช้สำหรับกระบวนการนี้เรียกว่าการรวมกลุ่มสูงสุด
การรวมสูงสุดทํางานในลักษณะที่คล้ายกับการฟัซชัน เราจะเลื่อนไปบนแผนที่ฟีเจอร์และดึงข้อมูลไทล์ขนาดที่ระบุ ระบบจะแสดงค่าสูงสุดของไทล์แต่ละรายการไปยังแผนที่ฟีเจอร์ใหม่ และทิ้งค่าอื่นๆ ทั้งหมด การดำเนินการ Max pooling จะใช้พารามิเตอร์ 2 รายการ ได้แก่
- ขนาดของตัวกรอง Max-Pooling (โดยทั่วไปคือ 2x2 พิกเซล)
- Stride: ระยะห่างเป็นพิกเซลระหว่างแต่ละไทล์ที่ดึงข้อมูล ซึ่งแตกต่างจากการกรองแบบ Convolution ที่ตัวกรองจะเลื่อนไปบนแผนที่ลักษณะทีละพิกเซล แต่การรวมสูงสุดจะใช้ระยะการเลื่อนเพื่อกำหนดตำแหน่งที่จะดึงข้อมูลแต่ละไทล์ สําหรับตัวกรอง 2x2 ระยะห่าง 2 จะระบุว่าการดำเนินการการรวมสูงสุดจะดึงข้อมูลไทล์ 2x2 ที่ไม่ทับซ้อนกันทั้งหมดออกจากแผนที่ลักษณะ (ดูรูปที่ 5)
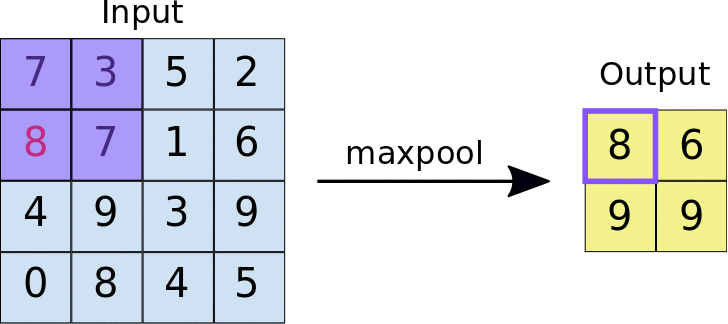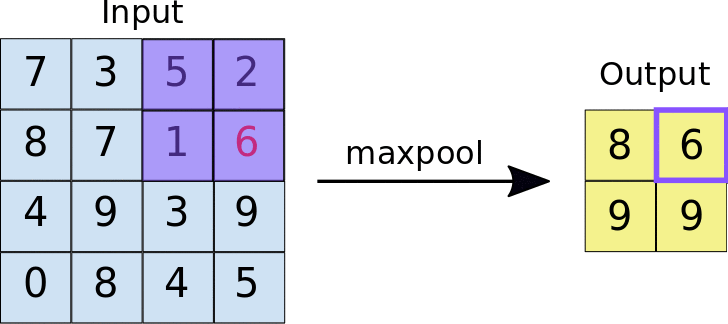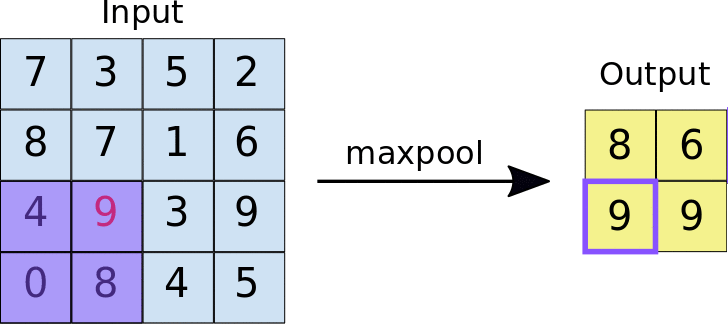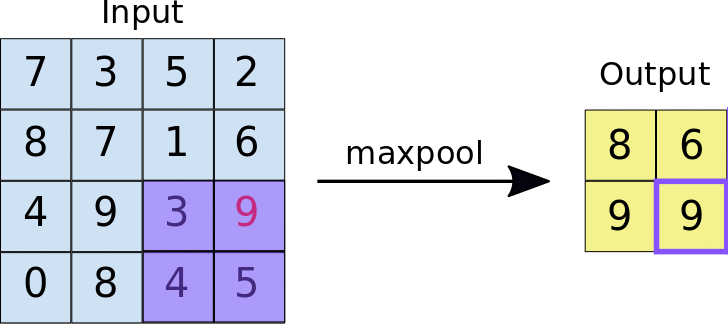
รูปที่ 5 ซ้าย: การรวมข้อมูลสูงสุดที่ดำเนินการกับแผนที่ลักษณะ 4x4 ด้วยตัวกรอง 2x2 และระยะ 2 ขวา: เอาต์พุตของการดำเนินการ Max Pooling โปรดทราบว่าแผนที่ฟีเจอร์ที่ได้จะเปลี่ยนเป็น 2x2 โดยเก็บเฉพาะค่าสูงสุดจากแต่ละไทล์
เลเยอร์แบบเชื่อมต่อทั้งหมด
ในตอนท้ายของเครือข่ายประสาทแบบ ConvNet จะมีชั้นที่เชื่อมต่อกันทั้งหมดอย่างน้อย 1 ชั้น (เมื่อ 2 ชั้น "เชื่อมต่อกันทั้งหมด" โหนดทุกโหนดในชั้นที่ 1 จะเชื่อมต่อกับโหนดทุกโหนดในชั้นที่ 2) หน้าที่ของโมเดลนี้คือการจัดประเภทตามลักษณะที่ดึงมาจากการดำเนินการ Conv โดยปกติแล้ว เลเยอร์แบบ Fully Connected สุดท้ายจะมีฟังก์ชันการเปิดใช้งาน Softmax ซึ่งจะแสดงผลค่าความน่าจะเป็นตั้งแต่ 0 ถึง 1 สําหรับป้ายกํากับการจัดประเภทแต่ละรายการที่โมเดลพยายามคาดการณ์
รูปที่ 6 แสดงโครงสร้างจากต้นทางถึงปลายทางของโครงข่ายประสาทแบบ Convolutive

รูปที่ 6 CNN ที่แสดงที่นี่ประกอบด้วยโมดูล Conv (Conv + ReLU + Pooling) 2 โมดูลสําหรับการดึงข้อมูลลักษณะ และชั้น Fully Connected 2 ชั้นสําหรับการจัดประเภท CNN อื่นๆ อาจมีโมดูล Conv มากกว่าหรือน้อยกว่า และอาจมีเลเยอร์แบบ Fully Connected มากกว่าหรือน้อยกว่า วิศวกรมักทดสอบเพื่อหาการกำหนดค่าที่ให้ผลลัพธ์ดีที่สุดสำหรับโมเดลของตน