Introdução às redes neurais convolucionais
Um avanço na criação de modelos para classificação de imagens veio com a descoberta de que uma rede neural convolucional (CNN) poderia ser usada para extrair progressivamente representações de nível mais alto e mais alto do conteúdo da imagem. Em vez de pré-processar os dados para extrair recursos como texturas e formas, uma CNN usa apenas os dados de pixel brutos da imagem como entrada e "aprende" como extrair esses recursos e, por fim, inferir qual objeto eles representam.
Para começar, a CNN recebe um mapa de elementos de entrada: uma matriz tridimensional em que o tamanho das duas primeiras dimensões corresponde ao comprimento e largura das imagens em pixels. O tamanho da terceira dimensão é 3 (corresponde aos 3 canais de uma imagem colorida: vermelho, verde e azul). A CNN compreende uma pilha de módulos, cada um deles executa três operações.
1. Convolução
Uma convolução extrai blocos do mapa de elementos de entrada e aplica filtros a eles para calcular novos elementos, produzindo um mapa de elementos de saída ou um elemento convolucionado (que pode ter um tamanho e uma profundidade diferentes do mapa de elementos de entrada). As convoluções são definidas por dois parâmetros:
- Tamanho dos blocos extraídos (normalmente 3 x 3 ou 5 x 5 pixels).
- A profundidade do mapa de elementos de saída, que corresponde ao número de filtros aplicados.
Durante uma convolução, os filtros (matrizes do mesmo tamanho do bloco) são deslizados horizontal e verticalmente sobre a grade do mapa de elementos de entrada, um pixel por vez, extraindo cada bloco correspondente (consulte a Figura 3).
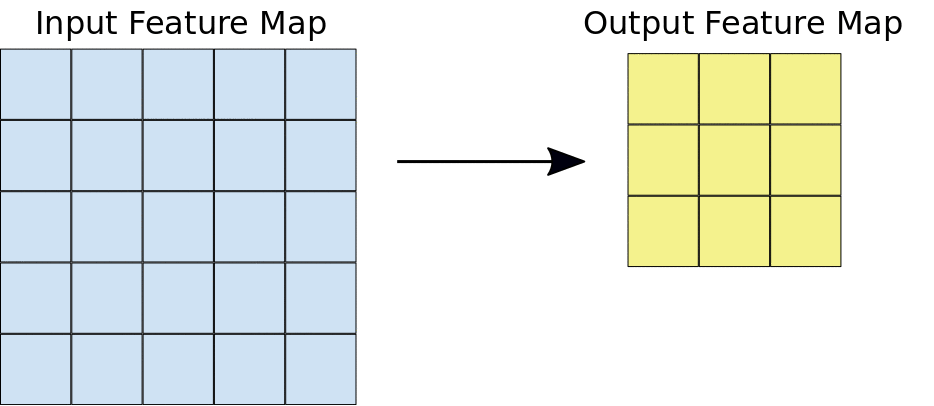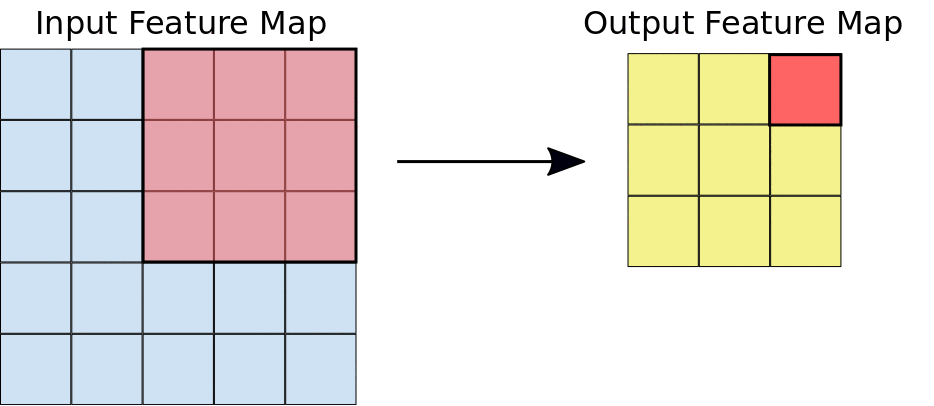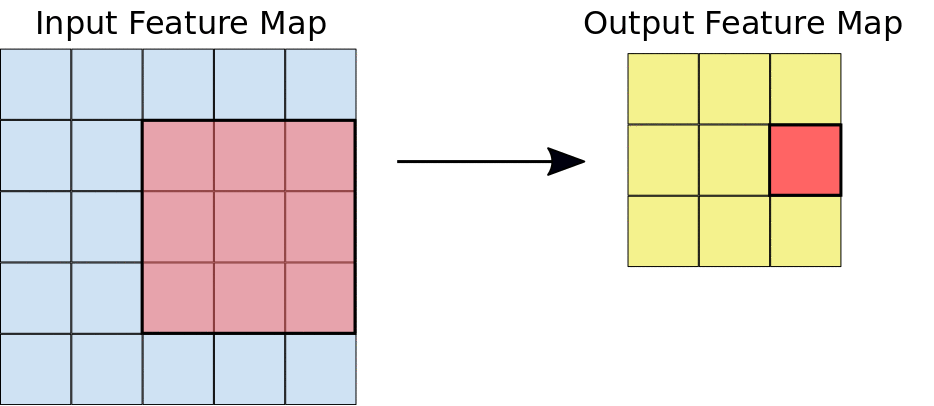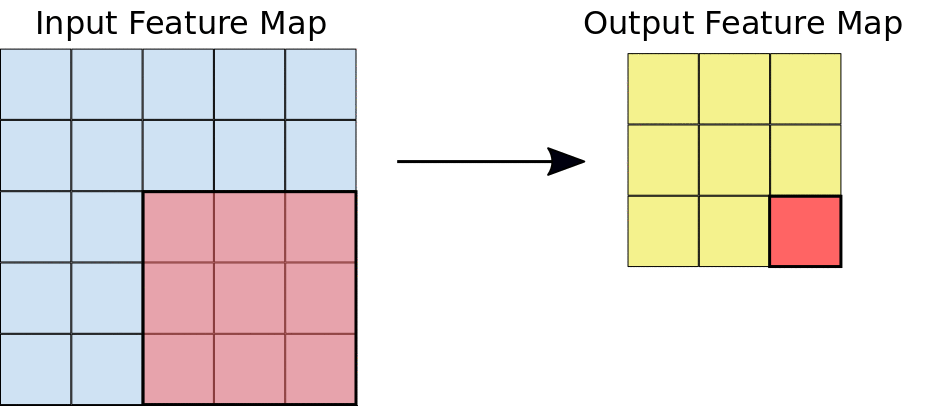 Figura 3. Uma convolução 3x3 de profundidade 1 realizada em um mapa de elementos de entrada 5x5, também de profundidade 1. Há nove locais 3x3 possíveis para
extrair blocos do mapa de elementos 5x5. Portanto, essa convolução produz um mapa de elementos de saída
3x3.
Figura 3. Uma convolução 3x3 de profundidade 1 realizada em um mapa de elementos de entrada 5x5, também de profundidade 1. Há nove locais 3x3 possíveis para
extrair blocos do mapa de elementos 5x5. Portanto, essa convolução produz um mapa de elementos de saída
3x3.
Para cada par de filtro-bloco, a CNN realiza a multiplicação elementar da matriz de filtro e da matriz de blocos e, em seguida, soma todos os elementos da matriz resultante para receber um único valor. Cada um desses valores resultantes para cada par de filtro-bloco é então gerado na matriz de recursos convoluídos (consulte as Figuras 4a e 4b).
 Figura 4a. Esquerda: um mapa de elementos de entrada 5x5 (profundidade 1). Certo: uma convolução 3x3 (profundidade 1).
Figura 4a. Esquerda: um mapa de elementos de entrada 5x5 (profundidade 1). Certo: uma convolução 3x3 (profundidade 1).
Figura 4b. Esquerda: a convolução 3x3 é realizada no mapa de elementos de entrada 5x5. Direita: o recurso convoluído resultante. Clique em um valor no mapa de elementos de saída para ver como ele foi calculado.
Durante o treinamento, a CNN "aprende" os valores ideais para as matrizes de filtro, que permitem extrair recursos significativos (texturas, bordas, formas) do mapa de recursos de entrada. À medida que o número de filtros (profundidade do mapa de elementos de saída) aplicados à entrada aumenta, o número de elementos que a CNN pode extrair também aumenta. No entanto, os filtros compõem a maioria dos recursos gastos pela CNN. Portanto, o tempo de treinamento também aumenta à medida que mais filtros são adicionados. Além disso, cada filtro adicionado à rede fornece menos valor incremental do que o anterior. Portanto, os engenheiros têm como objetivo construir redes que usem o número mínimo de filtros necessários para extrair os recursos necessários para uma classificação precisa de imagens.
2. ReLU
Após cada operação de convolução, a CNN aplica uma transformação de unidade linear retificada (ReLU, na sigla em inglês) ao recurso convolado para introduzir não linearidade no modelo. A função ReLU, \(F(x)=max(0,x)\), retorna x para todos os valores de x > 0 e retorna 0 para todos os valores de x ≤ 0.
3. Pooling
Depois do ReLU, há uma etapa de agregação, em que a CNN reduz a amostra da característica convoluída (para economizar no tempo de processamento), reduzindo o número de dimensões do mapa de características, preservando as informações mais importantes. Um algoritmo comum usado para esse processo é chamado de max pooling.
O pool máximo opera de maneira semelhante à convolução. Deslizamos sobre o mapa de elementos e extraímos blocos de um tamanho especificado. Para cada bloco, o valor máximo é enviado para um novo mapa de elementos, e todos os outros valores são descartados. As operações de agrupamento máximo usam dois parâmetros:
- Tamanho do filtro de max-pooling (normalmente 2 x 2 pixels)
- Stride: a distância, em pixels, que separa cada bloco extraído. Diferentemente da convolução, em que os filtros deslizam sobre o mapa de elementos pixel por pixel, no agrupamento máximo, o passo determina os locais em que cada bloco é extraído. Para um filtro 2x2, um passo de 2 especifica que a operação de agregação máxima extrai todos os blocos 2x2 não sobrepostos do mapa de elementos (consulte a Figura 5).
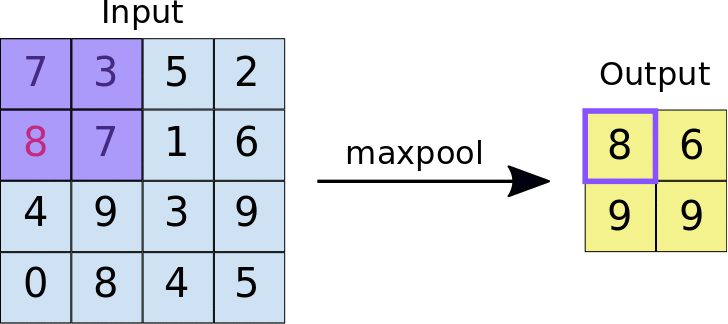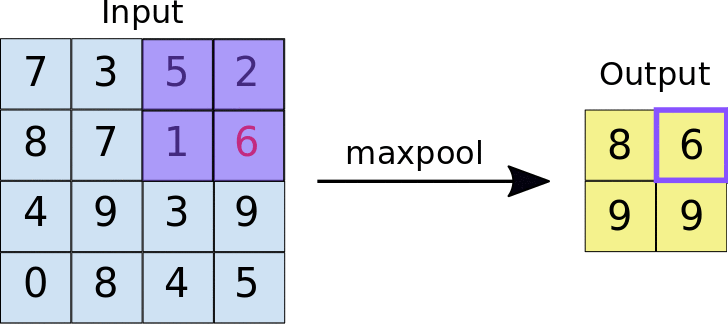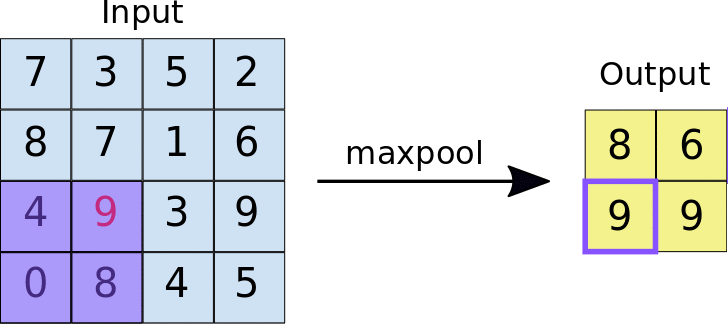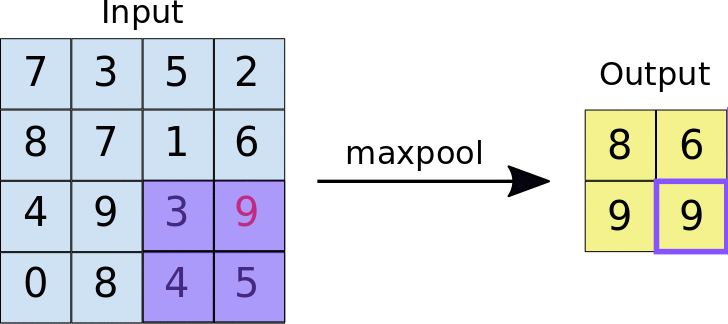
Figura 5. Esquerda: pool máximo realizado em um mapa de recursos 4x4 com um filtro 2x2 e um passo de 2. Direita: a saída da operação de max pooling. O mapa de elementos resultante agora é 2x2, preservando apenas os valores máximos de cada bloco.
Camadas totalmente conectadas
No final de uma rede neural convolucional, há uma ou mais camadas totalmente conectadas. Quando duas camadas estão "totalmente conectadas", cada nó na primeira camada está conectado a cada nó na segunda camada. A função deles é realizar a classificação com base nos recursos extraídos pelas convoluções. Normalmente, a camada final totalmente conectada contém uma função de ativação softmax, que exibe um valor de probabilidade de 0 a 1 para cada um dos rótulos de classificação que o modelo está tentando prever.
A Figura 6 ilustra a estrutura completa de uma rede neural convolucional.

Figura 6. A CNN mostrada aqui contém dois módulos de convolução (convolução + ReLU + agrupamento) para extração de recursos e duas camadas totalmente conectadas para classificação. Outras CNNs podem conter números maiores ou menores de módulos convolucionais e mais ou menos camadas totalmente conectadas. Os engenheiros muitas vezes fazem experimentos para descobrir a configuração que produz os melhores resultados para o modelo.