Memperkenalkan Jaringan Neural Konvolusional
Penemuan jaringan neural konvolusional (CNN) yang dapat digunakan untuk mengekstrak representasi konten gambar yang lebih tinggi dan lebih tinggi secara progresif merupakan terobosan dalam membuat model untuk klasifikasi gambar. Alih-alih memproses data terlebih dahulu untuk mendapatkan fitur seperti tekstur dan bentuk, CNN hanya mengambil data piksel mentah gambar sebagai input dan "mempelajari" cara mengekstrak fitur ini, dan pada akhirnya menyimpulkan objek yang membentuknya.
Untuk memulai, CNN menerima peta fitur input: matriks tiga dimensi dengan ukuran dua dimensi pertama sesuai dengan panjang dan lebar gambar dalam piksel. Ukuran dimensi ketiga adalah 3 (sesuai dengan 3 saluran gambar warna: merah, hijau, dan biru). CNN terdiri dari stack modul, yang masing-masing melakukan tiga operasi.
1. Konvolusi
Konvolusi mengekstrak ubin peta fitur input, dan menerapkan filter ke ubin tersebut untuk menghitung fitur baru, menghasilkan peta fitur output, atau fitur konvolusi (yang mungkin memiliki ukuran dan kedalaman yang berbeda dari peta fitur input). Konvolusi ditentukan oleh dua parameter:
- Ukuran ubin yang diekstrak (biasanya 3x3 atau 5x5 piksel).
- Kedalaman peta fitur output, yang sesuai dengan jumlah filter yang diterapkan.
Selama konvolusi, filter (matriks dengan ukuran yang sama dengan ukuran kartu) secara efektif bergeser di atas petak peta fitur input secara horizontal dan vertikal, satu piksel pada satu waktu, mengekstrak setiap kartu yang sesuai (lihat Gambar 3).
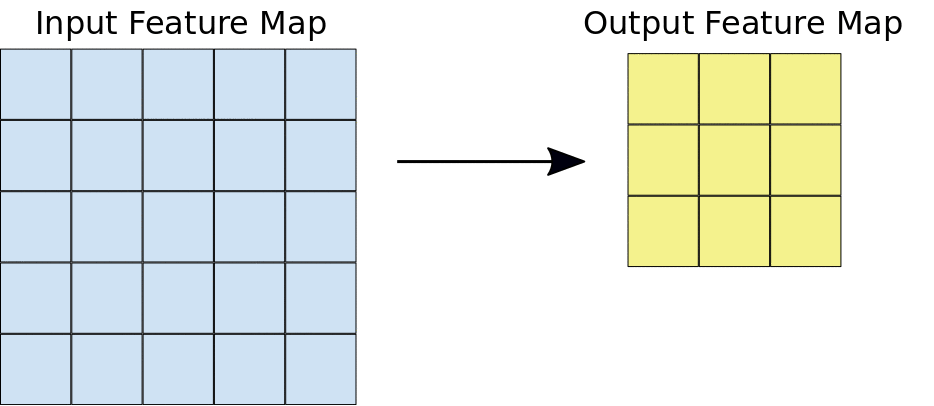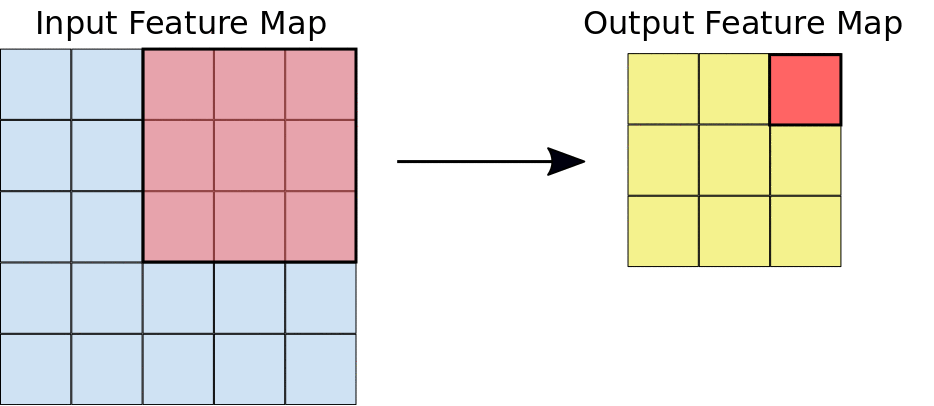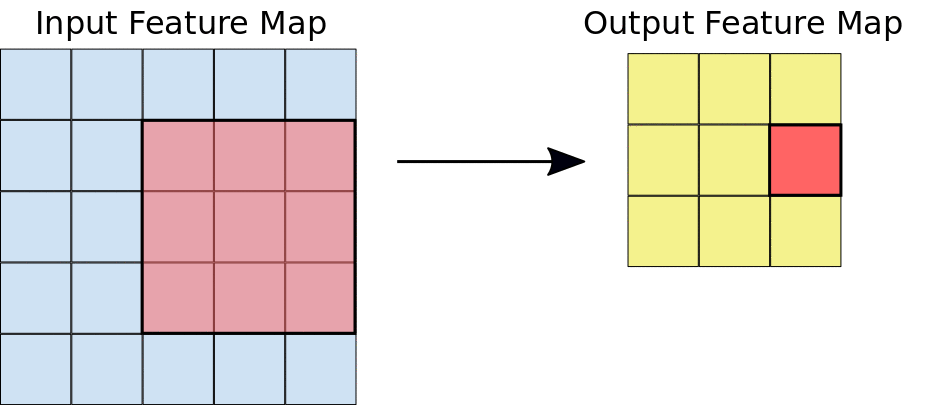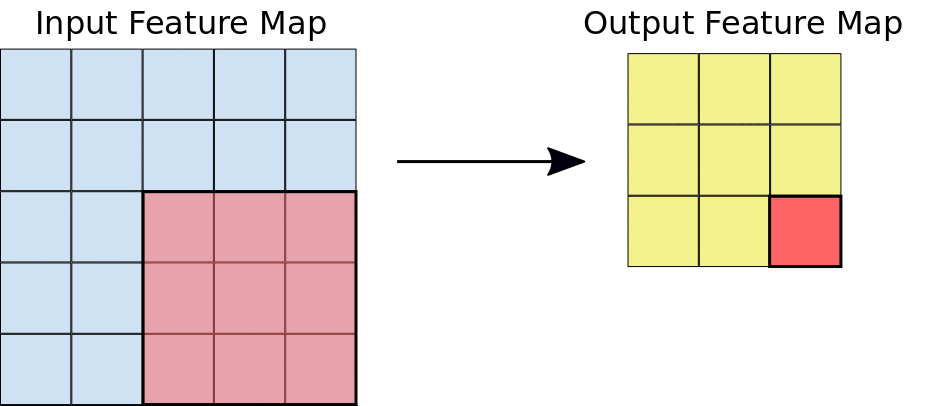 Gambar 3. Konvolusi 3x3 dengan kedalaman 1 yang dilakukan pada peta fitur input 5x5,
juga dengan kedalaman 1. Ada sembilan kemungkinan lokasi 3x3 untuk
mengekstrak ubin dari peta fitur 5x5, sehingga konvolusi ini menghasilkan peta fitur
output 3x3.
Gambar 3. Konvolusi 3x3 dengan kedalaman 1 yang dilakukan pada peta fitur input 5x5,
juga dengan kedalaman 1. Ada sembilan kemungkinan lokasi 3x3 untuk
mengekstrak ubin dari peta fitur 5x5, sehingga konvolusi ini menghasilkan peta fitur
output 3x3.
Untuk setiap pasangan filter-kartu, CNN melakukan perkalian elemen matriks filter dan matriks kartu, lalu menjumlahkan semua elemen matriks yang dihasilkan untuk mendapatkan satu nilai. Setiap nilai yang dihasilkan untuk setiap pasangan filter-ubin kemudian akan menghasilkan output dalam matriks fitur yang dikonvolusi (lihat Gambar 4a dan 4b).
 Gambar 4a. Kiri: Peta fitur input 5x5 (kedalaman 1). Kanan: konvolusi 3x3 (kedalaman 1).
Gambar 4a. Kiri: Peta fitur input 5x5 (kedalaman 1). Kanan: konvolusi 3x3 (kedalaman 1).
Gambar 4b. Kiri: Konvolusi 3x3 dilakukan pada peta fitur input 5x5. Kanan: fitur yang dikonvolusi. Klik nilai di peta fitur output untuk melihat cara penghitungannya.
Selama pelatihan, CNN "mempelajari" nilai optimal untuk matriks filter yang memungkinkannya mengekstrak fitur yang bermakna (tekstur, tepi, bentuk) dari peta fitur input. Seiring dengan meningkatnya jumlah filter (kedalaman peta fitur output) yang diterapkan ke input, jumlah fitur yang dapat diekstrak CNN juga akan meningkat. Namun, komprominya adalah filter menyusun sebagian besar resource yang digunakan oleh CNN, sehingga waktu pelatihan juga meningkat seiring dengan penambahan lebih banyak filter. Selain itu, setiap filter yang ditambahkan ke jaringan memberikan nilai inkremental yang lebih sedikit daripada filter sebelumnya, sehingga engineer bertujuan untuk membuat jaringan yang menggunakan jumlah minimum filter yang diperlukan untuk mengekstrak fitur yang diperlukan untuk klasifikasi gambar yang akurat.
2. ReLU
Setelah setiap operasi konvolusi, CNN menerapkan transformasi Unit Linear Terarah (ReLU) ke fitur yang dikonvolusi, untuk memasukkan nonlinearitas ke dalam model. Fungsi ReLU, \(F(x)=max(0,x)\), menampilkan x untuk semua nilai x > 0, dan menampilkan 0 untuk semua nilai x ≤ 0.
3. Penggabungan
Setelah ReLU, ada langkah penggabungan, di mana CNN mendownsample fitur yang dikonvolusi (untuk menghemat waktu pemrosesan), mengurangi jumlah dimensi peta fitur, sekaligus tetap mempertahankan informasi fitur yang paling penting. Algoritma umum yang digunakan untuk proses ini disebut max pooling.
Max pooling beroperasi dengan cara yang mirip dengan konvolusi. Kita menggeser peta fitur dan mengekstrak ubin dengan ukuran yang ditentukan. Untuk setiap ubin, nilai maksimum akan ditampilkan ke peta fitur baru, dan semua nilai lainnya akan dihapus. Operasi pooling maksimum menggunakan dua parameter:
- Ukuran filter max-pooling (biasanya 2x2 piksel)
- Stride: jarak, dalam piksel, yang memisahkan setiap ubin yang diekstrak. Tidak seperti konvolusi, yang filternya bergeser di atas peta fitur piksel demi piksel, dalam max pooling, stride menentukan lokasi tempat setiap ubin diekstrak. Untuk filter 2x2, langkah 2 menentukan bahwa operasi max pooling akan mengekstrak semua ubin 2x2 yang tidak tumpang-tindih dari peta fitur (lihat Gambar 5).
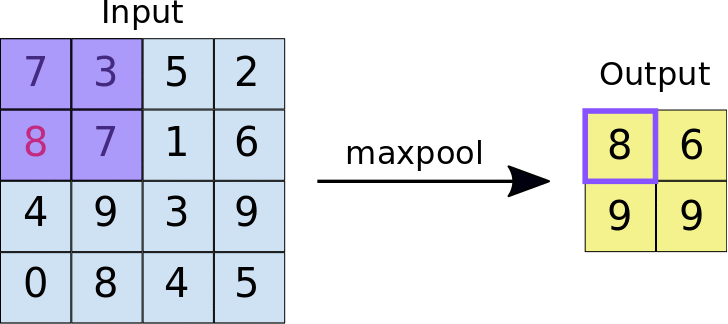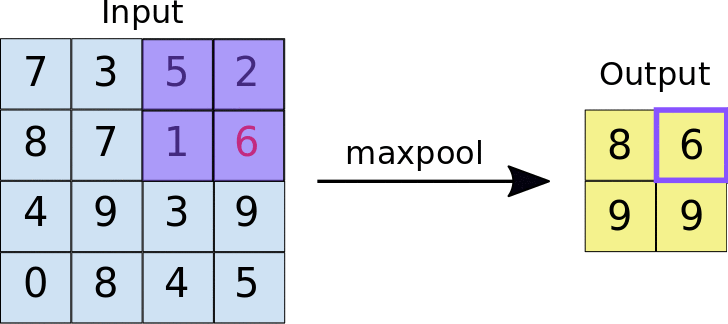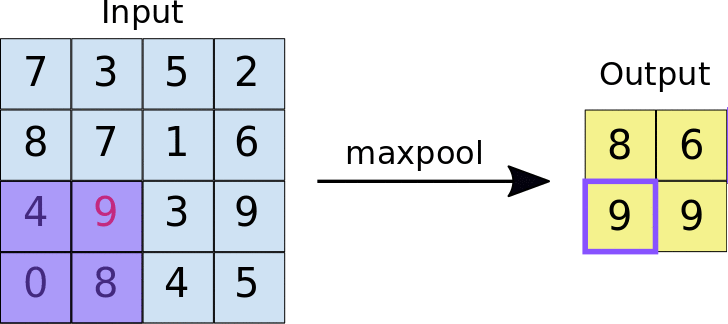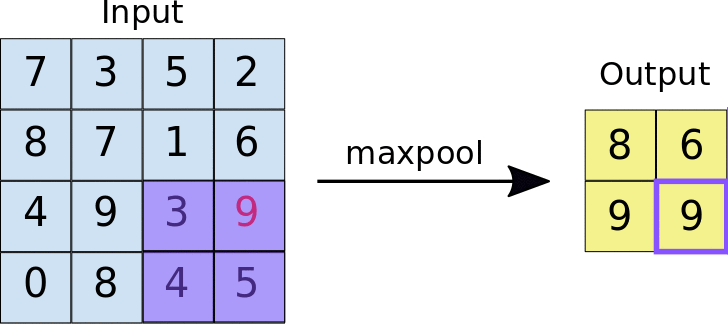
Gambar 5. Kiri: Max pooling dilakukan pada peta fitur 4x4 dengan filter 2x2 dan langkah 2. Kanan: output dari operasi max pooling. Perhatikan bahwa peta fitur yang dihasilkan kini berukuran 2x2, yang hanya mempertahankan nilai maksimum dari setiap ubin.
Lapisan yang Terhubung Sepenuhnya
Di akhir jaringan saraf konvolusi terdapat satu atau beberapa lapisan yang terhubung sepenuhnya (jika dua lapisan "terhubung sepenuhnya", setiap node di lapisan pertama terhubung ke setiap node di lapisan kedua). Tugasnya adalah melakukan klasifikasi berdasarkan fitur yang diekstrak oleh konvolusi. Biasanya, lapisan akhir yang terhubung sepenuhnya berisi fungsi aktivasi softmax, yang menghasilkan nilai probabilitas dari 0 hingga 1 untuk setiap label klasifikasi yang dicoba diprediksi oleh model.
Gambar 6 mengilustrasikan struktur menyeluruh jaringan saraf konvolusi.

Gambar 6. CNN yang ditampilkan di sini berisi dua modul konvolusi (konvolusi + ReLU + pooling) untuk ekstraksi fitur, dan dua lapisan terhubung sepenuhnya untuk klasifikasi. CNN lainnya mungkin berisi jumlah modul convolutional yang lebih besar atau lebih kecil, dan lapisan terhubung penuh yang lebih besar atau lebih sedikit. Engineer sering bereksperimen untuk mencari tahu konfigurasi yang menghasilkan hasil terbaik untuk model mereka.