Introduzione alle reti neurali convoluzionali
Un importante passo avanti nella creazione di modelli per la classificazione delle immagini è stato compiuto con la scoperta che una rete neurale convoluzionale (CNN) poteva essere utilizzata per estrarre progressivamente rappresentazioni di livello sempre più elevato dei contenuti delle immagini. Invece di pre-elaborare i dati per ricavare funzionalità come texture e forme, una CNN prende come input solo i dati non elaborati dei pixel dell'immagine e "impara" a estrarre queste funzionalità, per poi dedurre quale oggetto rappresentano.
Per iniziare, la CNN riceve una mappa di caratteristiche di input: una matrice tridimensionale in cui le dimensioni delle prime due dimensioni corrispondono alla lunghezza e alla larghezza delle immagini in pixel. La dimensione della terza dimensione è 3 (corrispondente ai 3 canali di un'immagine a colori: rosso, verde e blu). La CNN è costituita da un mucchio di moduli, ognuno dei quali esegue tre operazioni.
1. Convoluzione
Una convoluzione estrae riquadri della mappa di caratteristiche di input e vi applica filtri per calcolare nuove caratteristiche, producendo una mappa di caratteristiche di output o una caratteristica convulgata (che può avere dimensioni e profondità diverse rispetto alla mappa di caratteristiche di input). Le convoluzioni sono definite da due parametri:
- Dimensioni delle riquadri estratti (in genere 3 x 3 o 5 x 5 pixel).
- La profondità della mappa di caratteristiche in uscita, che corrisponde al numero di filtri applicati.
Durante una convezione, i filtri (matrici delle stesse dimensioni dei riquadri) scorrono efficacemente orizzontalmente e verticalmente sulla griglia della mappa di caratteristiche di input, un pixel alla volta, estraendo ogni riquadro corrispondente (vedi Figura 3).
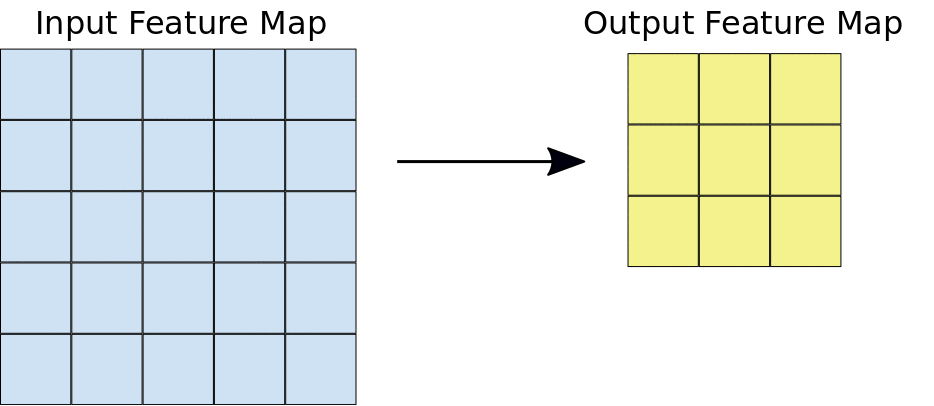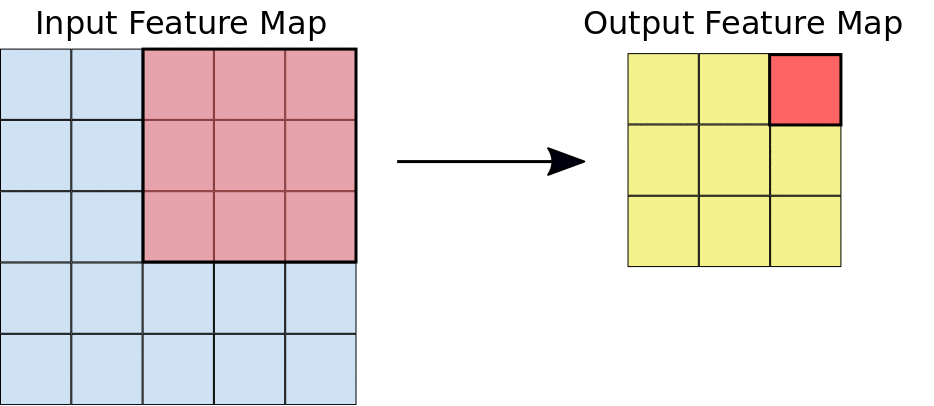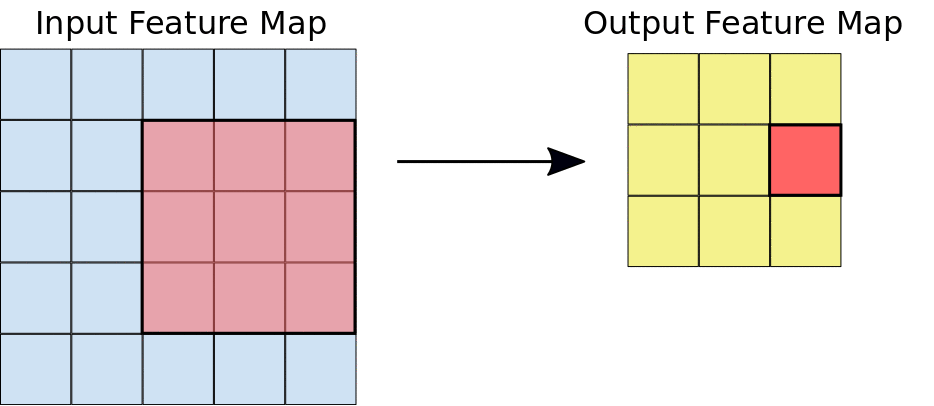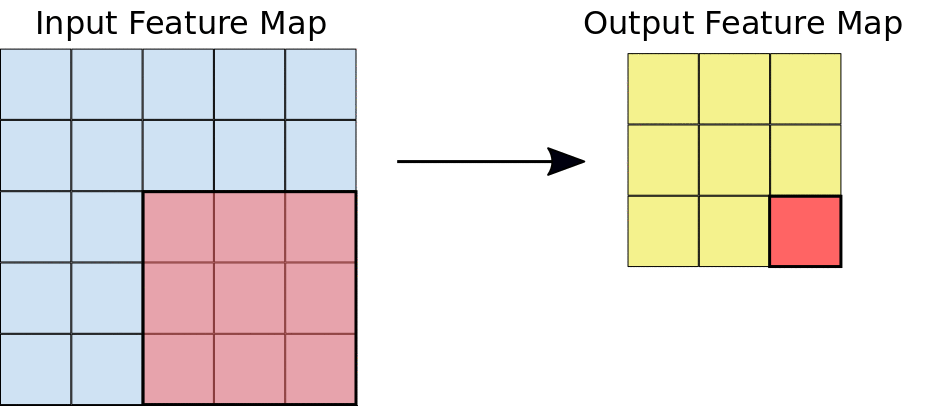 Figura 3. Una convezione 3x3 di profondità 1 eseguita su una mappa di funzionalità di input 5x5,
anche di profondità 1. Esistono nove possibili posizioni 3x3 per
estrarre riquadri dalla mappa di funzionalità 5x5, pertanto questa convergenza produce una mappa di funzionalità di output 3x3.
Figura 3. Una convezione 3x3 di profondità 1 eseguita su una mappa di funzionalità di input 5x5,
anche di profondità 1. Esistono nove possibili posizioni 3x3 per
estrarre riquadri dalla mappa di funzionalità 5x5, pertanto questa convergenza produce una mappa di funzionalità di output 3x3.
Per ogni coppia di filtri e riquadri, la CNN esegue la moltiplicazione elemento per elemento della matrice del filtro e della matrice del riquadro, quindi somma tutti gli elementi della matrice risultante per ottenere un singolo valore. Ciascuno di questi valori risultanti per ogni coppia di riquadri di filtro viene poi visualizzato nella matrice della funzionalità convoluta (vedi le figure 4a e 4b).
 Figura 4a. A sinistra: una mappa di caratteristiche di input 5x5 (profondità 1). Destra: una convoluzione 3x3 (profondità 1).
Figura 4a. A sinistra: una mappa di caratteristiche di input 5x5 (profondità 1). Destra: una convoluzione 3x3 (profondità 1).
Figura 4b. A sinistra: la convoluzione 3x3 viene eseguita sulla mappa di funzionalità di input 5x5. Destra: la funzionalità convoluta risultante. Fai clic su un valore nella mappa delle funzionalità di output per vedere come è stato calcolato.
Durante l'addestramento, la CNN "impara" i valori ottimali per le matrici di filtri che le consentono di estrarre caratteristiche significative (texture, bordi, forme) dalla mappa di caratteristiche di input. Con l'aumento del numero di filtri (profondità della mappa di caratteristiche in uscita) applicati all'input, aumenta anche il numero di caratteristiche che la CNN può estrarre. Tuttavia, il compromesso è che i filtri costituiscono la maggior parte delle risorse spese dalla CNN, pertanto il tempo di addestramento aumenta anche con l'aggiunta di altri filtri. Inoltre, ogni filtro aggiunto alla rete fornisce un valore incrementale inferiore rispetto al precedente, pertanto gli ingegneri mirano a creare reti che utilizzino il numero minimo di filtri necessari per estrarre le funzionalità necessarie per una classificazione accurata delle immagini.
2. ReLU
Dopo ogni operazione di convezione, la CNN applica una trasformazione dell'unità lineare rettificata (ReLU) alla funzionalità convoluta per introdurre la non linearità nel modello. La funzione ReLU, \(F(x)=max(0,x)\), restituisce x per tutti i valori di x > 0 e 0 per tutti i valori di x ≤ 0.
3. Pooling
Dopo ReLU viene eseguito un passaggio di pooling, in cui la CNN esegue il sottocampionamento della caratteristica convolta (per risparmiare tempo di elaborazione), riducendo il numero di dimensioni della mappa di caratteristiche, pur conservando le informazioni più importanti sulle caratteristiche. Un algoritmo comune utilizzato per questa procedura è chiamato max pooling.
La somma massima funziona in modo simile alla convezione. Scorri la mappa di elementi ed estrai riquadri di dimensioni specificate. Per ogni riquadro, il valore massimo viene visualizzato in una nuova mappa di funzionalità e tutti gli altri valori vengono ignorati. Le operazioni di pooling massimo accettano due parametri:
- Dimensioni del filtro max pooling (in genere 2 x 2 pixel)
- Stride: la distanza in pixel che separa ogni riquadro estratto. A differenza della convezione, in cui i filtri scorrono sulla mappa di caratteristiche pixel per pixel, nel pooling massimo lo stride determina le posizioni in cui viene estratto ogni riquadro. Per un filtro 2 x 2, uno stride di 2 specifica che l'operazione di pooling massimo estrae tutti i riquadri 2 x 2 non sovrapposti dalla mappa di funzionalità (vedi Figura 5).
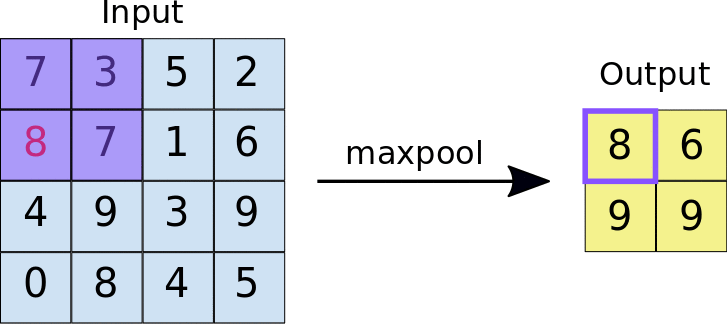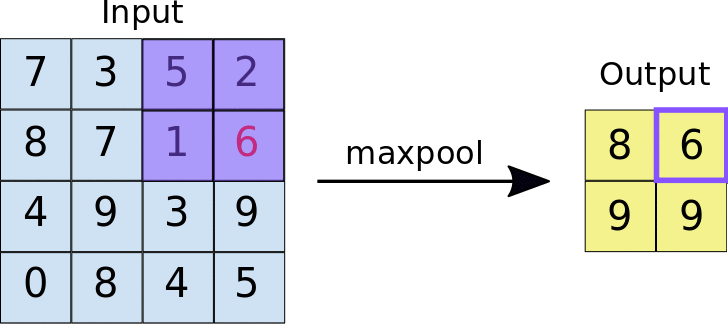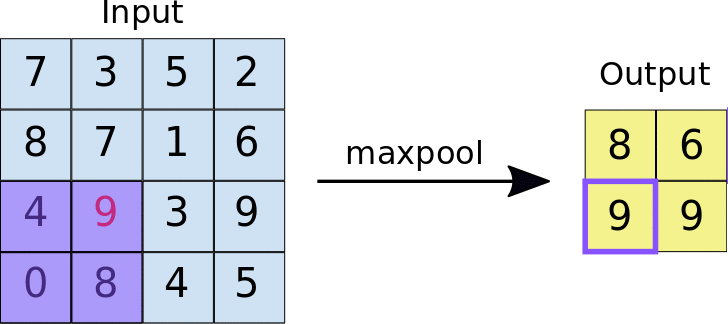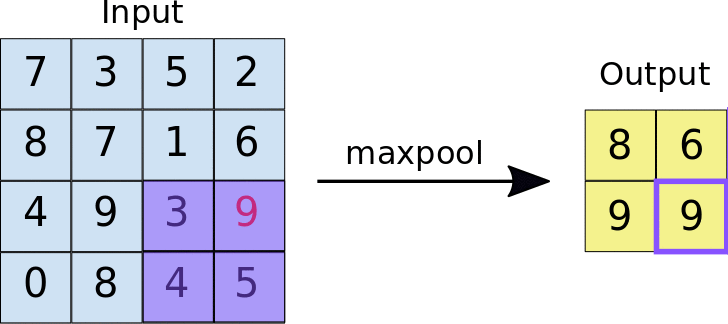
Figura 5. A sinistra: max pooling eseguito su una mappa di funzionalità 4x4 con un filtro 2x2 e uno stride di 2. Destra: l'output dell'operazione di pooling massimo. Tieni presente che la mappa di funzionalità risultante ora è 2x2 e conserva solo i valori massimi di ogni riquadro.
Livelli completamente connessi
Alla fine di una rete neurale convoluzionale sono presenti uno o più strati completamente collegati (quando due strati sono "completamente collegati", ogni nodo del primo strato è collegato a ogni nodo del secondo strato). Il loro compito è eseguire la classificazione in base alle caratteristiche estratte dalle convolute. In genere, il livello completamente connesso finale contiene una funzione di attivazione softmax, che restituisce un valore di probabilità compreso tra 0 e 1 per ciascuna delle etichette di classificazione che il modello sta cercando di prevedere.
La Figura 6 illustra la struttura end-to-end di una rete neurale convoluzionale.

Figura 6. La CNN mostrata qui contiene due moduli di convoluzione (convoluzione + ReLU + pooling) per l'estrazione di funzionalità e due livelli completamente connessi per la classificazione. Altre CNN possono contenere un numero maggiore o minore di moduli convoluzionali e un numero maggiore o minore di livelli completamente connessi. Gli ingegneri spesso fanno esperimenti per capire quale configurazione produce i risultati migliori per il loro modello.